大家好,我是木木。
今天给大家分享一个稳妥的 Python 库,feedparser。
feedparser
做内容聚合、技术资讯、博客订阅或内部信息流时,RSS 和 Atom 仍然很有价值。问题是不同站点的 feed 格式、日期、字段和小错误都不完全一样。feedparser 的作用就是把这些差异收拢起来,让你用统一的 Python 对象读取订阅源。
项目地址:https://github.com/kurtmckee/feedparser
官方文档:https://feedparser.readthedocs.io
三大特点
格式稳妥
它能处理 RSS 0.9x、RSS 1.0、RSS 2.0、Atom 0.3、Atom 1.0 等常见订阅格式。
字段统一
feed 标题、文章标题、链接、发布时间、摘要等字段会被整理成相对一致的访问方式。
异常可见
遇到不规范 XML 或损坏 feed 时,可以通过 bozo 和异常对象发现问题,而不是静默导入脏数据。
最佳实践
安装方式:python -m pip install feedparser==6.0.12
建议先把订阅源解析、字段映射和异常处理单独写成一层,再接入数据库或消息队列。这样某个站点 feed 变形时,不会把整条内容流水线拖坏。
功能一:把 RSS 条目转成 Python 对象
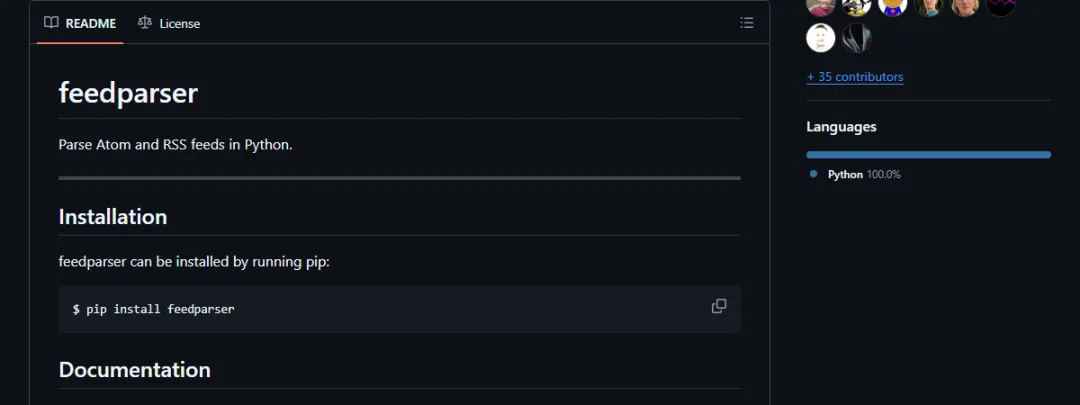
这段代码解决什么问题:用同一套访问方式读取 feed 元信息和文章条目。示例直接使用本地 RSS 字符串,不依赖外部网络。
importfeedparserrss="""<?xml version="1.0" encoding="utf-8"?><rss version="2.0"><channel><title>木木周刊</title><link>https://example.com</link><description>Python updates</description><item><title>feedparser 解析 RSS</title><link>https://example.com/rss</link><guid>rss-1</guid></item><item><title>Atom 也能统一读</title><link>https://example.com/atom</link><guid>rss-2</guid></item></channel></rss>"""feed=feedparser.parse(rss)print("订阅源:",feed.feed.title)print("文章数:",len(feed.entries))forentryinfeed.entries:print(f"{entry.title} -> {entry.link}")print("解析异常:",bool(feed.bozo))
实际接入时,不要假设每个条目都有完整字段。更稳的方式是用 entry.get("title")、entry.get("link") 做兜底,再把缺失字段记录到日志里。
功能二:读取 Atom 元信息和标准化日期
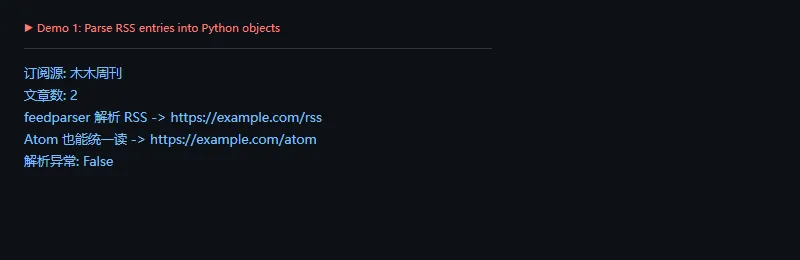
这段代码解决什么问题:不同 feed 对时间字段的写法不一样。feedparser 会把常见日期解析成 updated_parsed 这类结构,方便转成时间戳、入库时间或排序字段。
importcalendarimportfeedparseratom="""<?xml version="1.0" encoding="utf-8"?><feed xmlns="http://www.w3.org/2005/Atom"><title>Python 发布记录</title><updated>2026-05-03T12:30:00Z</updated><entry><title>版本更新</title><id>tag:example.com,2026:1</id><link href="https://example.com/release"/><updated>2026-05-03T12:30:00Z</updated></entry></feed>"""feed=feedparser.parse(atom)entry=feed.entries[0]updated_ts=calendar.timegm(entry.updated_parsed)print("类型:",feed.version)print("标题:",entry.title)print("链接:",entry.link)print("UTC 时间戳:",updated_ts)
内容聚合里,时间字段很容易影响排序和去重。我的习惯是:原始时间字符串保留一份,标准化时间再单独存一份,方便后面排查。
环境与版本信息
- Demo 环境:Windows 11,Python 3.11
- 本文安装的
feedparser 版本:6.0.12 - 支持格式:RSS 0.9x、RSS 1.0、RSS 2.0、Atom 0.3、Atom 1.0
- GitHub 最近一次推送时间:
2026-04-14T02:44:57Z
高级功能
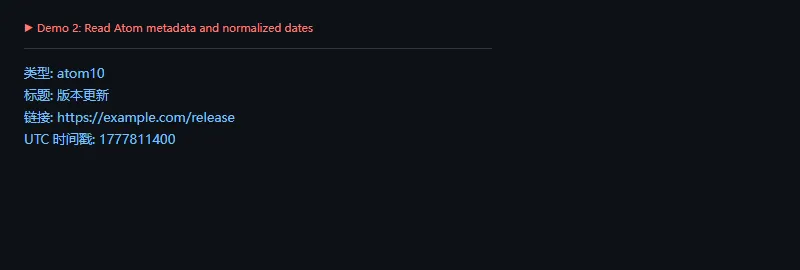
这段代码解决什么问题:真实世界的 feed 并不总是规范 XML。导入前检查 bozo,可以把损坏源、异常类型和可用条目数记录下来,避免把问题藏到下游。
importfeedparserbroken="<rss><channel><title>坏掉的订阅源</title><item><title>缺少闭合标签</title>"feed=feedparser.parse(broken)print("feed 标题:",feed.feed.get("title","未知"))print("解析异常:",bool(feed.bozo))iffeed.bozo:print("异常类型:",type(feed.bozo_exception).__name__)print("可用条目:",len(feed.entries))
如果某个订阅源经常报错,不要直接丢弃。可以先降级处理:保留源地址、最后成功时间、失败次数和异常摘要,后面再决定是否停用。
适用场景
- 你要聚合博客、新闻、版本发布、播客或内部公告订阅源
- 你希望用统一对象处理 RSS 和 Atom,而不是手写 XML 解析
不适用场景
- 业务对字段完整性要求极高,必须和站点方 API 做强约束对接
上线检查
- 给每个订阅源记录 URL、最后成功时间、失败次数和最近异常。
- 对
title、link、id、发布时间做空值兜底和去重策略。
总结
feedparser 是一个非常稳妥的订阅源解析库。它不负责抓整个网站,也不替你做内容清洗,但能把 RSS/Atom 这个入口处理得足够统一。做资讯聚合、发布监控和内容同步时,它很适合作为第一层解析器。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
