Python多核终于有新路子了
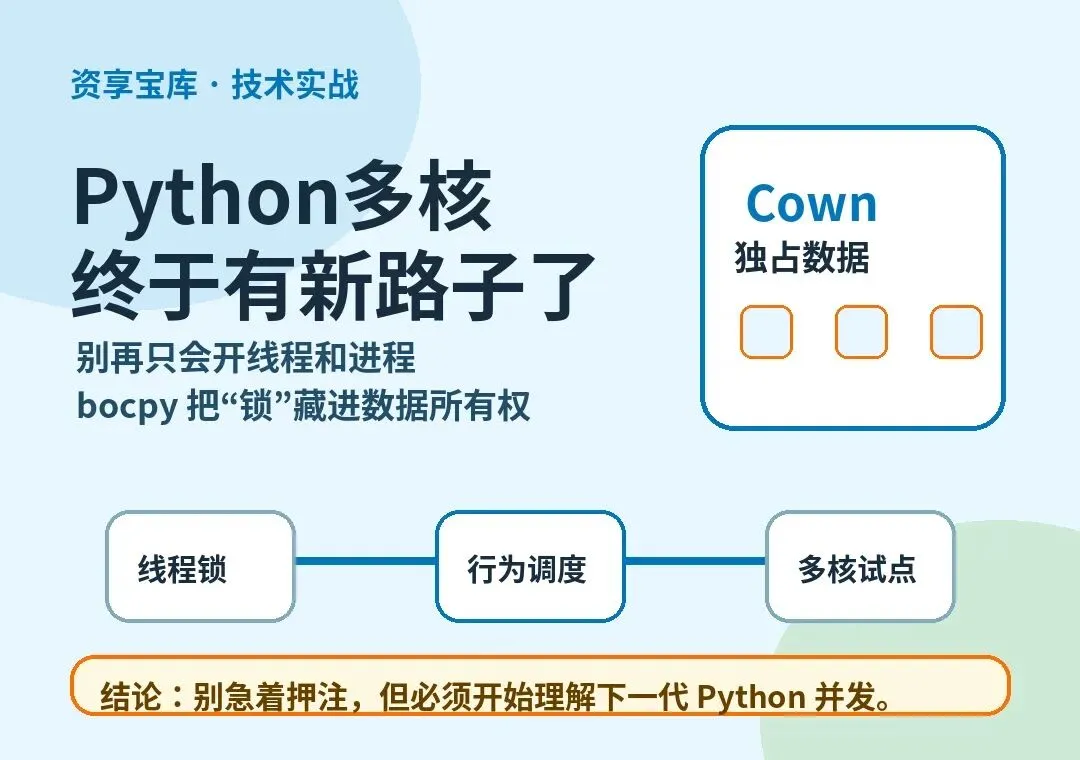
很多 Python 服务的性能瓶颈,根本不是“代码写得不够快”,而是团队一直在用错误的方式解决并发问题。
遇到 CPU 密集任务,大家第一反应往往是三件套:开线程、上进程、丢给队列。线程被全局解释器锁卡住,进程把对象复制和序列化成本放大,队列又把业务逻辑拆成一堆回调和状态机。代码跑起来了,但可维护性很快塌掉。真正可怕的不是慢,而是你不知道哪一把锁会在凌晨把服务拖死。
微软最近放出的 bocpy 值得认真看一眼。它不是又一个任务队列,也不是把 asyncio 换个名字包装一遍。它试图给 Python 并发换一个抽象:别让开发者手写锁,改成围绕“数据所有权”和“行为调度”组织程序。对象在某个时间片只归一个行为独占访问,运行时负责调度和加锁,开发者只描述“哪些数据一起参与这次操作”。
这篇文章不把它吹成银弹。恰恰相反,我的判断是:bocpy 现在更像一条很早期、但方向很硬的技术路线。它的仓库星标只有几十个,版本到 0.5.0,生态还远没成熟;但它踩中的问题,是 Python 后面几年绕不开的问题:多核机器越来越便宜,单解释器写法越来越贵,纯靠“多开几个进程”已经撑不住复杂业务。
并发的麻烦,从来不只是“跑得慢”
很多人讨论 Python 多核,只盯着全局解释器锁。这个视角太窄。
全局解释器锁确实让传统线程很难把 CPU 密集任务摊到多个核心上。但生产环境里更常见的痛点,是并发代码把业务逻辑污染了。一个本来很清楚的转账逻辑,写成线程版本后会突然多出锁顺序、条件变量、等待通知、异常释放、死锁规避。业务代码没变复杂,并发控制把它变复杂了。
拿“两个账户转账”举例。业务规则很简单:从 A 扣钱,给 B 加钱,前提是两边账户没有被冻结且余额足够。传统线程写法通常要做几件事:给两个账户对象加锁,保证锁顺序一致,处理余额不足,处理异常释放,还要避免另一个线程同时读到半更新状态。任何一步漏掉,都可能出现脏读、死锁或资金不一致。
bocpy 的思路是把账户包装成 Cown,也就是 concurrent-owned variable,可以理解为“被并发运行时托管所有权的对象”。然后把转账写成一个行为:
from bocpy import Cown, when, wait
class Account:
def __init__(self, name, balance, frozen=False):
self.name = name
self.balance = balance
self.frozen = frozen
def atomic_transfer(src: Cown[Account], dst: Cown[Account], amount: float):
@when(src, dst)
def do_transfer(src: Cown[Account], dst: Cown[Account]):
a = src.value
b = dst.value
if a.balance >= amount and not a.frozen and not b.frozen:
a.balance -= amount
b.balance += amount
alice = Cown(Account("Alice", 100))
bob = Cown(Account("Bob", 0))
atomic_transfer(alice, bob, 50)
wait()
关键不在语法糖,而在语义变化:@when(src, dst) 表示这个行为需要同时独占访问 src 和 dst。运行时会处理调度与互斥,行为内部看到的是一段普通同步代码。开发者不再直接管理锁,而是声明数据依赖。
这个抽象如果成立,意义很大。因为它把并发问题从“我怎么锁这个对象”改成“这段业务操作真正需要哪些对象”。前者是机制,后者是业务边界。工程上,能把机制藏起来,就能少掉一大类事故。

它和 asyncio 不是一个赛道
HN 上有人问:这和 asyncio 有什么区别?这是个好问题,因为很多 Python 团队已经把“并发”等同于 async/await。
asyncio 主要解决的是等待问题。网络请求、磁盘读写、数据库连接池,这些任务大部分时间在等外部系统返回,事件循环可以在等待期间切去做别的事。它提升的是 I/O 并发能力,不是让同一段 Python CPU 计算自动吃满多个核心。
bocpy 想解决的是共享可变状态下的并行问题。它关心的不是“这个协程何时让出控制权”,而是“这段行为运行时能否安全地独占一组数据”。这就把它放到了另一个坐标系里:更接近 actor 模型、软件事务内存、所有权类型系统、两阶段锁调度这些传统并发研究方向。
不过它也不是简单复制 actor 模型。actor 通常强调每个 actor 独占自己的状态,消息被一个 actor 处理。如果一个操作天然要同时修改多个 actor 的状态,比如银行转账、库存扣减加订单确认、多资源调度,就会变得麻烦。你要设计协议,要处理补偿,要接受最终一致性,或者把多个状态塞回一个 actor 里牺牲并发度。
bocpy 的反直觉点在这里:一个行为可以同时获取多个 Cown,在一个临界区里完成跨对象操作。这让它表达“多对象事务”更直接。官方文档里提到,它底层依赖两阶段锁和调度器来保证获取集合的安全性。开发者不用手写锁顺序,但也不是没有锁,只是锁被运行时接管了。
这也是我不愿意把它叫“更简单的 asyncio”的原因。asyncio 让等待变便宜,bocpy 让多对象互斥更可控。一个服务完全可能同时用两者:对外 I/O 用异步,内部某些 CPU 密集或共享状态更新用行为调度。但不要幻想把所有协程替换成 @when,那会把问题带偏。
真正的新信号,是 Python 3.12 之后的子解释器
bocpy 最值得关注的地方,不只是 API,而是它绑定了 Python 运行时正在发生的变化。
官方说明里有几个数字很关键:bocpy 支持 Python 3.10+,但只有在 3.12+ 上才有真正并行,因为 Python 3.12 引入了每个子解释器独立全局解释器锁的能力。也就是说,3.10 和 3.11 上你可以跑它的代码,但行为仍会被进程级全局解释器锁串行化;到了 3.12+,不同子解释器里的行为才可能跨核心并行。
这点很容易被忽略。很多库说“支持多版本”,读者就以为性能语义一样。不是。对 bocpy 这种并发库来说,版本不是兼容性细节,而是核心能力边界。
官方 README 还给了一个微基准:在 CPython 3.14 上,链环 workload 从 1 个 worker 扩到 8 个 worker,速度提升从 1.00x 到大约 7.54x,接近线性扩展。这个数字很漂亮,但必须谨慎解读。它测的是调度器、两阶段锁、消息队列、子解释器跨界等运行时路径,不代表你的业务代码直接就有 7 倍提升。
微基准有价值,因为它证明路线不是纯概念玩具;微基准也危险,因为它容易让人忽视真实业务的串行部分。真实系统有对象构造、数据拷贝、日志、网络、数据库、缓存、异常处理。只要串行部分比例上升,扩展曲线就会立刻弯下来。
这里可以给一个更稳的判断:bocpy 不是“把 Python 变成 Go”,它更像给 Python 打开了一个新的并发设计空间。以前很多 CPU 密集任务要么写 C 扩展,要么开多进程,要么把任务拆到外部服务。现在子解释器、多全局解释器锁、无全局解释器锁实验分支都在往前走,库作者开始有机会在 Python 内部重新设计多核抽象。
这件事对工程团队的影响,比一个新库本身更大。

上手模型:先把“资源”变成 Cown
如果把 bocpy 当成普通线程库学,会很别扭。正确的入门方式是先问:我的程序里哪些对象是并发争用资源?
在传统写法里,资源可能是账户、库存、订单、文件句柄、模型权重缓存、连接池、任务状态。你会给它们加锁,或者把它们藏到某个 worker 后面。bocpy 的写法是把这些资源包装成 Cown,然后让行为声明自己需要哪些资源。
一个库存扣减场景可以这样拆:
from bocpy import Cown, when, wait
class Inventory:
def __init__(self, sku, stock):
self.sku = sku
self.stock = stock
class Order:
def __init__(self, order_id):
self.order_id = order_id
self.status = "created"
def reserve(inv: Cown[Inventory], order: Cown[Order], qty: int):
@when(inv, order)
def do_reserve(inv: Cown[Inventory], order: Cown[Order]):
if inv.value.stock >= qty and order.value.status == "created":
inv.value.stock -= qty
order.value.status = "reserved"
else:
order.value.status = "failed"
sku_a = Cown(Inventory("A", 10))
order_1 = Cown(Order("O-1"))
order_2 = Cown(Order("O-2"))
reserve(sku_a, order_1, 3)
reserve(sku_a, order_2, 8)
wait()
这个例子故意简单。它说明的是三个设计要点。
第一,行为内部不要再开线程、等条件变量、手动获取锁。你应该把行为写成一段短小的同步逻辑。越短,运行时越容易调度,问题也越容易定位。
第二,把争用粒度拆对。上面的例子把每个 SKU 库存包装为一个 Cown,而不是把整个库存系统包装为一个大 Cown。如果你把全局库存对象锁住,所有商品都会串行;如果按 SKU 拆,互不相关的商品可以并行处理。并发性能很大程度取决于资源建模,不取决于 @when 写得多漂亮。
第三,不要在行为里做慢 I/O。行为一旦拿到多个 Cown,就占住了这些资源的时间片。如果你在里面请求外部支付接口、写远程数据库、调用大模型,其他需要同一资源的行为都会被拖住。正确做法是把慢 I/O 放到行为之外,或者拆成“准备数据 → 行为内快速提交状态 → 后续异步处理”。
这就是 bocpy 的核心使用纪律:行为应该像数据库事务一样短,资源粒度应该像锁设计一样细,外部副作用应该像事件驱动系统一样隔离。
什么时候该试,什么时候别碰
新并发抽象最容易被滥用。团队一看到“无锁”“多核”“死锁自由”,就想把现有服务重构一遍。千万别这么干。
bocpy 当前更适合三类场景。
一类是 CPU 密集且状态明确的任务。比如图计算、仿真、规则引擎、批量数据转换、内存状态机。这些任务里的共享对象边界比较清楚,行为执行时间可控,容易从多 worker 调度中获益。
一类是多对象一致性要求高的小事务。比如账户转账、库存预占、资源分配、任务抢占。传统 actor 写法要绕协议,传统锁写法容易出错,@when(a, b, c) 这种多资源声明能让代码更接近业务语义。
还有一类是研究型或平台型团队。你们本来就在跟 Python 3.12+、子解释器、无全局解释器锁分支打交道,有能力承受库早期带来的兼容性和调试成本。这类团队现在介入,能提前摸到下一代 Python 并发的边界。
不适合的场景也很明确。
Web API 里大部分等待数据库和网络的接口,不要为了追新把 asyncio 或线程池替换掉。那不是它的强项。
依赖大量 C 扩展、对象不可序列化、强绑定线程本地状态的业务,也要谨慎。bocpy 底层涉及子解释器和跨解释器数据,很多“在单解释器里没问题”的对象,跨边界后可能不成立。
低延迟交易、强实时系统、事故成本极高的核心链路,也不建议现在就上生产。版本 0.5.0、仓库星标几十个、打开 issue 虽然不多,但这并不代表成熟,而是代表使用者还少。早期库最大的问题不是 bug 数量,而是你踩到的坑没人踩过。
我的建议很简单:不要在主链路试,不要在 I/O 服务里硬套,不要为了多核改掉所有架构。挑一个离线任务或内部批处理,用真实 workload 跑一组小实验,比读十篇介绍都靠谱。

小实验应该怎么设计
要判断 bocpy 值不值得引入,别只跑官方 benchmark。你应该拿自己的业务形态做三个实验。
第一个实验测“争用粒度”。准备同样数量的任务,分别用大粒度 Cown 和小粒度 Cown 跑。比如库存系统里,一版把整个库存表当一个资源,一版按 SKU 拆资源。观察 worker 从 1 增加到 2、4、8 时,吞吐曲线是否继续上升。如果小粒度版本明显更好,说明你的业务有并行空间;如果两者差不多,瓶颈可能不在锁,而在串行逻辑或外部 I/O。
第二个实验测“行为时长”。把行为内部逻辑分成纯计算、内存状态更新、外部 I/O 三种版本。你会很快看到,外部 I/O 会把资源占用时间拉长,让并发收益消失。这个实验的目的不是证明库快,而是逼团队找出哪些代码不该放进行为。
第三个实验测“迁移成本”。找一段现有线程锁代码,统计改写前后的代码行数、锁数量、条件变量数量、测试用例变化、异常路径数量。并发库的价值不只在吞吐,也在可维护性。如果 bocpy 让关键路径少掉 50% 的锁相关代码,即使吞吐只提升 20%,它也可能值得继续研究。
可以用下面这个清单做评估:
| 维度 |
观察指标 |
判断方式 |
| 扩展性 |
1/2/4/8 worker 吞吐 |
是否接近线性,还是很快撞墙 |
| 争用 |
每个行为获取几个 Cown |
获取集合越大,冲突概率越高 |
| 行为时长 |
单个行为耗时分布 |
长尾行为会拖住资源 |
| 迁移成本 |
锁、条件变量、线程代码减少量 |
可维护性是否真的改善 |
| 兼容性 |
Python 版本、C 扩展、对象跨解释器 |
能否在目标环境稳定运行 |
这里面最重要的是行为时长。很多并发性能问题,表面看是锁,实际是临界区太大。你把一个慢接口调用塞进 @when,换什么并发模型都救不了。
别忽略安装和版本坑
我在本地验证资料时还踩到一个很典型的早期库问题:不是所有平台都能顺滑安装。官方说提供多数平台的预编译 wheel,但在 Linux ARM64、Python 3.13 环境里,pip install bocpy 尝试从源码构建时失败了,报错出现在 C 扩展编译阶段,提示缺少 compat.h。这不一定代表主流 x86 环境也会失败,但足以提醒团队:引入前必须把目标运行环境跑通,不要只看文档里的 pip install。
更稳的试点方式,是先固定三件事:CPU 架构、Python 小版本、镜像构建流程。比如在线下实验里使用 python:3.12 或 3.14 的 x86_64 镜像,确认 wheel 能安装,再进入业务 benchmark。不要在生产镜像里临时编译 C 扩展,也不要让 CI 每次从源码拉最新包。早期并发库一旦安装链路不稳定,会把性能实验变成环境排障。
还有一个容易误判的点:bocpy 在 3.10/3.11 上能运行,不等于值得在这些版本上评估吞吐。官方已经写得很清楚,3.10/3.11 仍受进程级全局解释器锁影响,行为会被串行化。你如果在 3.11 上跑出“没提升”,不能直接说模型不行;如果在 3.12+ 上跑出提升,也不能直接说线上能用。版本差异本身就是实验变量,必须写进报告。
我建议团队把试点报告拆成两张表。
一张是环境表:Python 版本、CPU 架构、操作系统、是否使用预编译 wheel、worker 数、容器限制、依赖 C 扩展。另一张是 workload 表:对象数量、行为数量、每个行为平均拿几个 Cown、行为内是否有 I/O、单行为 P50/P95/P99 耗时、总吞吐、错误数。
没有这两张表,所谓“快了”或“没快”都不可靠。
一段更贴近业务的改造思路
假设你有一个风控批处理任务:每天把用户交易、账户状态、设备指纹、规则配置读到内存里,然后对每个用户计算风险分。传统实现常见两种写法:单进程顺序跑,简单但慢;多进程切片跑,快一些,但共享规则、聚合统计、异常回收都要额外处理。
这类任务可以拿来试 bocpy,但不要一上来就把全部数据都包装成 Cown。更合理的切法是:把“会被多个行为同时修改”的状态包装起来,把只读规则留在普通对象里。比如用户风险状态、全局计数器、某些限额桶是 Cown;模型参数、规则表达式、地区映射表是只读数据,通过 noticeboard 或初始化上下文分发。
伪代码可以长这样:
from bocpy import Cown, when, wait
class RiskState:
def __init__(self):
self.score = 0
self.flags = []
class LimitBucket:
def __init__(self, capacity):
self.capacity = capacity
self.used = 0
def apply_rule(user_state: Cown[RiskState], bucket: Cown[LimitBucket], event):
@when(user_state, bucket)
def run(user_state: Cown[RiskState], bucket: Cown[LimitBucket]):
if event.amount > 10000:
user_state.value.score += 30
user_state.value.flags.append("large_amount")
if bucket.value.used < bucket.value.capacity:
bucket.value.used += 1
else:
user_state.value.score += 10
user_state.value.flags.append("bucket_overflow")
for event in events:
apply_rule(user_states[event.user_id], buckets[event.region], event)
wait()
这段代码的重点不是风控逻辑,而是资源关系:同一个用户的风险状态不能被两个行为同时乱改,同一个地区的限额桶也不能并发超扣;不同用户、不同地区之间却应该有并行空间。@when(user_state, bucket) 正好表达了这个边界。
这里也能看出它和进程池的差异。进程池通常先把数据切片,切完以后每个进程处理自己的分片,跨分片共享状态会变麻烦。bocpy 更像把共享状态留在一个受控运行时里,让调度器根据行为需要的资源集合决定哪些能并行。对于“完全无共享”的任务,进程池可能更简单;对于“有共享但共享边界清楚”的任务,Cown 模型才有发挥空间。
代码评审时要盯住四个红灯
如果团队真的开始写 bocpy,代码评审不能只看功能对不对,要专门盯并发语义。我会把四个红灯写进评审模板。
红灯一:行为里出现网络请求、数据库写入、大模型调用、文件大读写。只要出现这些操作,就要追问为什么不能拆出去。行为持有的是资源独占权,慢 I/O 会把独占权变成排队毒药。
红灯二:一个行为拿了太多 Cown。获取集合越大,可并行空间越小,调度冲突越高。很多时候,拿十个资源不是业务必需,而是开发者懒得拆状态。超过三个就应该解释理由,超过五个就要重新画资源图。
红灯三:Cown 粒度过粗。把整个系统状态包成一个 Cown,表面上省事,实际等于加了一把全局锁。试点阶段可以这样验证正确性,但性能实验必须拆粒度,否则结论没有意义。
红灯四:行为之间靠隐式顺序碰运气。如果 A 行为必须先于 B 行为执行,就要把依赖写清楚,或者通过状态机表达,不要指望提交顺序永远等于执行顺序。并发系统里,未声明的顺序就是潜在事故。
这四个红灯比 API 细节更重要。新库能不能用,取决于团队有没有建立新的工程纪律。没有纪律,@when 也会被写成另一种全局锁。
它背后的趋势,比库本身更值得看
bocpy 现在还是早期项目。GitHub 只有约 38 个星标,PyPI 最近一天下载量约 931,最近一周约 1019,最近一月约 2370。这些数字不能证明它已经流行,只能证明它刚开始被技术社区注意到。HN 帖子有 53 分和少量评论,讨论里也有人质疑它像 Erlang actor,也有人批评示例不够贴近现实。
这些质疑很正常,甚至是必要的。一个并发抽象如果只在论文里漂亮,不在真实业务里接受嘲讽,就不会成熟。
但我更关心另一个信号:Python 社区对多核的焦虑正在从“抱怨全局解释器锁”转向“重建并发抽象”。过去大家讨论的方案经常停在运行时层:去掉全局解释器锁、每解释器独立锁、子解释器 API。现在问题开始上浮到开发者模型:对象如何共享,任务如何声明数据依赖,跨对象一致性如何表达,调度器如何减少死锁风险。
这才是重点。
如果未来 Python 真进入多核友好阶段,旧代码不会自动变好。没有良好并发边界的业务,只会从“跑不满核心”变成“更快地暴露竞态”。无全局解释器锁不是免费午餐,它会让过去被全局锁遮住的数据竞争浮出来。那时候,像 Cown、所有权、行为调度这样的抽象,会变得越来越重要。
换句话说,bocpy 也许不会成为最终赢家,但它代表的问题一定会回来。
给团队的落地建议
如果你现在想试,建议按四步走。
第一步,只在 Python 3.12+ 环境里评估性能。3.10/3.11 可以验证 API,但别拿性能数字做判断。因为子解释器是否有独立全局解释器锁,直接决定它有没有真实并行空间。
第二步,选离线任务,不选在线主链路。比如报表计算、规则批处理、模拟器、内部数据校验。目标是用真实数据验证模型,不是挑战生产稳定性。
第三步,把资源图画出来。哪些对象会被多个行为访问?哪些操作需要同时拿多个资源?哪些资源可以拆小?如果资源图画不清,代码也写不清。
第四步,保留退出路线。早期库不要深度绑定业务协议。把 bocpy 封在内部模块里,对外暴露普通函数。实验失败时可以换回线程池、进程池或任务队列,不要让调用方感知底层并发模型。
我更推荐这样的封装:
class InventoryEngine:
def __init__(self, items):
self.items = {sku: Cown(Inventory(sku, stock)) for sku, stock in items.items()}
def reserve(self, sku, order, qty):
reserve(self.items[sku], order, qty)
def wait_all(self):
wait()
调用方只知道 reserve 和 wait_all,不知道内部用了 Cown。这叫技术试点,不叫把团队绑上新框架。
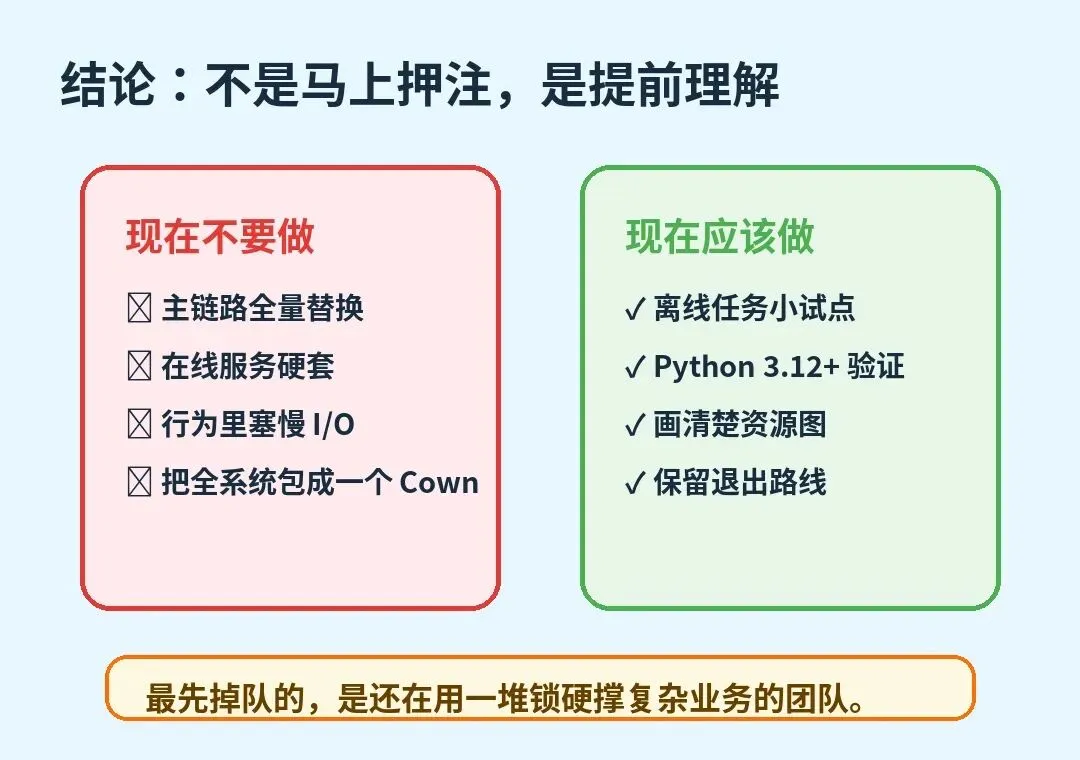
我的结论
bocpy 不是今天就该全量上生产的库。它太新,生态太小,跨解释器兼容性还有很多坑,文档示例也不够贴近复杂业务。把它当成熟框架推广,是不负责任的。
但它值得技术负责人花一个晚上读完文档,值得平台团队拿一个离线任务跑实验。因为它把 Python 并发问题从“怎么绕开全局解释器锁”推进到了“怎么重新组织共享状态”。这一步很关键。
未来几年,Python 多核路线不会只有一个答案。进程池还会存在,asyncio 还会处理 I/O,C 扩展还会负责热循环,无全局解释器锁也会继续推进。但在共享可变状态这块,手写锁一定会越来越不受欢迎。不是因为锁不专业,而是因为锁把太多底层机制暴露给业务开发者。
真正好的并发抽象,应该让代码更接近业务事实:这次操作需要这些资源,满足条件就执行,执行期间保持一致,结束后释放。bocpy 的价值,就在它把这个方向做成了一个可以动手试的 Python 库。
我的建议很明确:现在别急着押注,但要开始理解。等 Python 多核时代真的到来,最先掉队的不会是没换框架的团队,而是还在用一堆锁和条件变量硬撑复杂业务的团队。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
