用Python搭建一个完整的量化回测框架:从零到可运行的30分钟实战
你不需要成为金融博士,也能用代码验证自己的交易想法
01 为什么你需要一个回测框架
你有没有过这样的经历:脑子里冒出一个交易想法,觉得"这个策略肯定能赚钱",然后就真金白银冲进去了?我见过太多人这样亏钱。而解决这个问题的最佳方式,不是让自己变聪明,而是用一个工具来验证每一个想法——在投入真钱之前。这个工具就是回测框架。
回测框架做的事情很简单:把你的交易策略用代码写出来,然后在历史数据上跑一遍,看看如果当年就用了这个策略,结果会怎么样。听起来简单,但90%的人做不到,因为他们觉得"写代码太难了"。今天这篇文章的目标,就是让你在30分钟内,用Python搭建一个能跑起来的回测框架。
核心观点:回测不是让你找到一个"完美策略",而是让你避免把钱浪费在"垃圾策略"上。回测的最大价值不是发现机会,而是排除噪音。一个经过回测验证的策略,胜率不一定高,但至少你不会在明显错误的方向上亏钱。
02 环境准备:三行代码搞定基础依赖
正式开始之前,先把工具准备好。你需要安装三个Python库:pandas用于数据处理,numpy用于数值计算,matplotlib用于画图。如果你已经有Python环境,打开终端输入:
pip install pandas numpy matplotlib
就这三行。没有复杂的依赖,没有需要注册的API,全部是开源免费的。只要你电脑上装了Python,这三行代码就是你进入量化世界的第一步。我强烈建议你使用Python 3.8以上的版本,因为一些新特性会让代码更简洁。如果你连Python都还没装,去python.org下载最新版,安装时记得勾选"Add Python to PATH"。这一步大概需要三分钟。
03 获取数据:用akshare轻松拿到A股历史行情
量化交易的第一个技术难题是数据。很多人卡在这里就放弃了。其实根本不需要去买昂贵的Wind或Bloomberg终端——akshare这个开源库可以免费获取A股几乎所有公开数据,包括日线行情、财务数据、指数成分股等等。先安装:
pip install akshare
然后写一个获取数据的函数。我们以科创50指数为例:
import akshare as ak
import pandas as pd
def get_index_data(symbol="000688", start_date="20230101", end_date="20260508"):
"""获取指数日线数据"""
df = ak.stock_zh_index_daily(symbol=f"sh{symbol}")
df["date"] = pd.to_datetime(df["date"])
df = df[(df["date"] >= start_date) & (df["date"] <= end_date)]
df = df.sort_values("date").reset_index(drop=True)
df["returns"] = df["close"].pct_change()
return df
# 获取科创50数据
df = get_index_data()
print(f"数据条数: {len(df)}")
print(f"日期范围: {df['date'].min()} 到 {df['date'].max()}")
print(df.tail())上面的代码做了几件事:用akshare获取上证科创50指数的日线数据,把日期字段转成datetime格式方便筛选,按日期排序,然后计算每天的收益率。最后几行是验证数据是否获取成功。如果你运行成功,应该能看到最近几个交易日的收盘价和收益率。
akshare的强大之处在于它封装了几乎所有中国金融市场的公开数据接口。指数、股票、基金、期货、外汇、宏观经济——用同一个库就能拿到。关键是免费的。对个人量化研究者来说,这可能是性价比最高的数据方案。
*Python量化框架的搭建,讲究的是"先跑通、再优化"。很多初学者一上来就追求完美的架构设计,结果三个月过去了一个因子都跑不出来。正确的姿势是先用最简单的代码实现核心逻辑,验证策略有效性,再逐步迭代优化。
04 策略引擎:用双均线交叉作为第一个测试策略
有了数据,接下来是策略的核心——信号生成。我们从最经典也最简单的双均线交叉策略开始。这个策略的逻辑谁都听得懂:当短期均线上穿长期均线时买入,下穿时卖出。简单到令人发指,但它作为回测框架的测试策略再合适不过。
import numpy as np
class DualMAStrategy:
"""双均线交叉策略"""
def __init__(self, short_window=5, long_window=20):
self.short_window = short_window
self.long_window = long_window
def generate_signals(self, df):
"""生成买卖信号"""
df = df.copy()
# 计算短期和长期均线
df["ma_short"] = df["close"].rolling(window=self.short_window).mean()
df["ma_long"] = df["close"].rolling(window=self.long_window).mean()
# 信号: 1=买入, -1=卖出, 0=持有
df["signal"] = 0
df.loc[df["ma_short"] > df["ma_long"], "signal"] = 1
df.loc[df["ma_short"] <= df["ma_long"], "signal"] = -1
# 生成交易信号(只在交叉发生时产生信号)
df["position"] = df["signal"].diff()
df["trade"] = 0
df.loc[df["position"] == 2, "trade"] = 1 # 金叉买入
df.loc[df["position"] == -2, "trade"] = -1 # 死叉卖出
return df
# 使用策略
strategy = DualMAStrategy(short_window=5, long_window=20)
df_signals = strategy.generate_signals(df)
print(f"买入信号次数: {(df_signals['trade']==1).sum()}")
print(f"卖出信号次数: {(df_signals['trade']==-1).sum()}")这段代码的巧妙之处在于用diff()来检测信号变化。均线上穿时,信号从-1变成1,diff()的值就是2;均线下穿时,信号从1变成-1,diff()的值就是-2。这样我们只在实际发生交叉的瞬间产生交易信号,而不是每天都重复同样信号。这是回测中非常重要的一个细节——如果你不处理这个问题,一次买入信号会变成连续N天的买入,导致重复计算。
小技巧:如果你想让策略更灵活,可以把参数写成配置文件而不是硬编码在代码里。这样修改参数时不需要改代码,只需要改配置文件,大大降低改出bug的风险。可以用一个简单的yaml或json文件来存储所有策略参数。
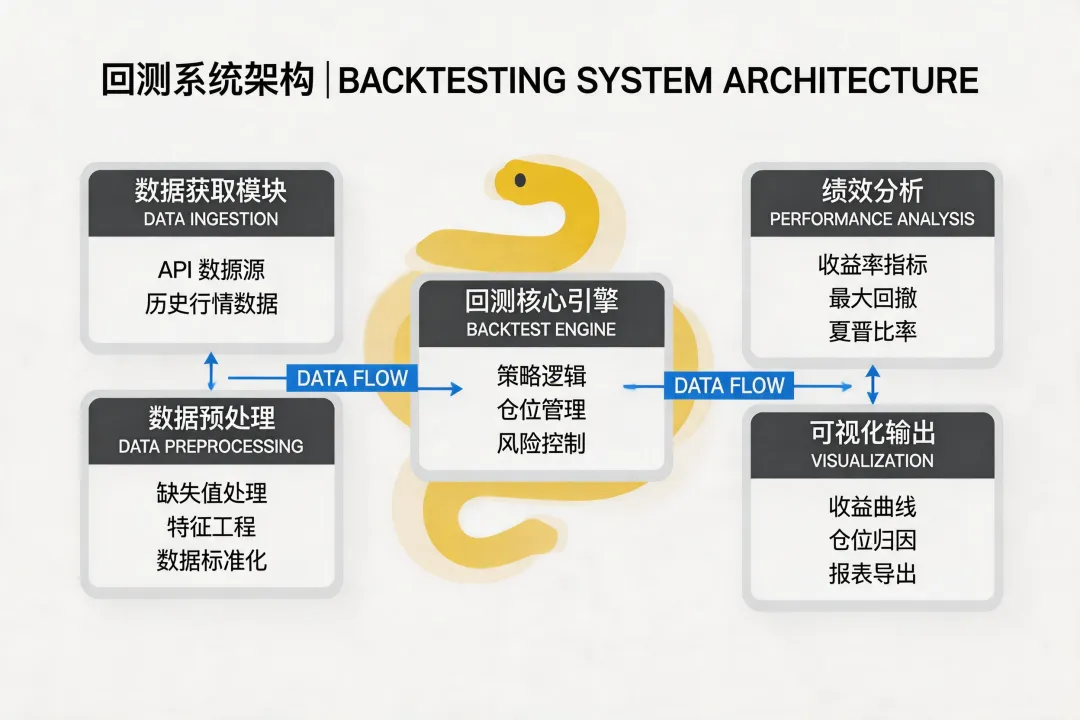
05 回测引擎:把信号变成真实的盈亏
信号只是信号,真正有意义的是信号带来的盈亏。回测引擎的核心任务就是把交易信号转化为持仓和收益序列。这里有很多细节需要注意,比如交易成本、滑点、信号延迟等等。我们一步步来。
class BacktestEngine:
"""回测引擎"""
def __init__(self, commission=0.0003, slippage=0.0001):
self.commission = commission # 交易费率(万三)
self.slippage = slippage # 滑点(万一)
def run(self, df, initial_capital=100000):
"""执行回测"""
df = df.copy()
# 初始化持仓和资金
df["holdings"] = 0 # 持仓市值
df["cash"] = initial_capital # 现金
df["total_value"] = initial_capital # 总资产
df["strategy_returns"] = 0 # 策略日收益率
position = 0 # 0=空仓, 1=满仓
for i in range(1, len(df)):
# 更新当天持仓价值
if position == 1:
df.loc[i, "holdings"] = df.loc[i-1, "holdings"] * (1 + df.loc[i, "returns"])
# 检查交易信号(用前一天的信号,避免未来数据泄露)
trade_signal = df.loc[i-1, "trade"]
if trade_signal == 1 and position == 0:
# 买入
cost = df.loc[i-1, "cash"] * (1 - self.commission - self.slippage)
df.loc[i, "holdings"] = cost
df.loc[i, "cash"] = df.loc[i-1, "cash"] - df.loc[i-1, "cash"]
position = 1
elif trade_signal == -1 and position == 1:
# 卖出
proceeds = df.loc[i-1, "holdings"] * (1 - self.commission - self.slippage)
df.loc[i, "cash"] = df.loc[i-1, "cash"] + proceeds
df.loc[i, "holdings"] = 0
position = 0
else:
# 持有,总资产跟随行情变化
df.loc[i, "cash"] = df.loc[i-1, "cash"]
if position == 0:
df.loc[i, "holdings"] = 0
# 计算总资产
df.loc[i, "total_value"] = df.loc[i, "cash"] + df.loc[i, "holdings"]
# 计算策略日收益率
df["strategy_returns"] = df["total_value"].pct_change()
return df
# 运行回测
engine = BacktestEngine()
df_result = engine.run(df_signals)
print(f"初始资金: 100,000")
print(f"最终资产: {df_result['total_value'].iloc[-1]:.2f}")
print(f"总收益率: {(df_result['total_value'].iloc[-1]/100000 - 1)*100:.2f}%")这里的回测引擎逻辑非常直观:每天检查是否产生交易信号,有信号就执行买卖,没有就继续持有。有几个关键设计值得注意:第一,交易信号用的是前一天的——这是为了避免"未来数据泄露",即用今天才知道的信息来做今天的决策。第二,每次交易都扣除了佣金和滑点——在A股市场,万三的佣金和万一的滑点是相对保守的假设,实盘中可能更高也可能更低。第三,持仓状态用一个简单的布尔变量来跟踪,避免了复杂的仓位管理逻辑,让代码更清晰。
未来数据泄露是回测中最常见也最致命的错误。很多人把当天的信号用来决定当天的交易,这在现实中是不可能的——你只能在收盘后看到当天的信号,但交易必须在收盘前执行。正确的做法永远是用T-1的信号来决定T日的交易。
06 绩效分析:夏普比率、最大回撤和胜率计算
回测跑完了,但怎么知道结果好坏?这就需要一套绩效指标。我见过太多人只盯着"总收益率"这一个数字,这是远远不够的。一个完整的绩效分析至少应该包含:年化收益率、年化波动率、夏普比率、最大回撤、胜率、盈亏比。我们一个个来。
class PerformanceAnalyzer:
"""绩效分析器"""
def __init__(self, df, risk_free_rate=0.03):
self.df = df
self.rf = risk_free_rate # 无风险利率(默认3%)
def annual_return(self):
"""年化收益率"""
total_return = self.df["total_value"].iloc[-1] / self.df["total_value"].iloc[0] - 1
years = len(self.df) / 252 # 假设一年252个交易日
return (1 + total_return) ** (1 / max(years, 0.1)) - 1
def annual_volatility(self):
"""年化波动率"""
return self.df["strategy_returns"].std() * np.sqrt(252)
def sharpe_ratio(self):
"""夏普比率"""
excess_return = self.annual_return() - self.rf
vol = self.annual_volatility()
return excess_return / vol if vol > 0 else 0
def max_drawdown(self):
"""最大回撤"""
cumulative = (1 + self.df["strategy_returns"].fillna(0)).cumprod()
peak = cumulative.expanding().max()
drawdown = (cumulative - peak) / peak
return drawdown.min()
def win_rate(self):
"""胜率(盈利交易日占比)"""
returns = self.df["strategy_returns"].dropna()
return (returns > 0).sum() / len(returns) if len(returns) > 0 else 0
def summary(self):
"""打印完整绩效报告"""
print("=" * 50)
print("策略回测绩效报告")
print("=" * 50)
print(f"年化收益率: {self.annual_return():.2%}")
print(f"年化波动率: {self.annual_volatility():.2%}")
print(f"夏普比率: {self.sharpe_ratio():.2f}")
print(f"最大回撤: {self.max_drawdown():.2%}")
print(f"胜率: {self.win_rate():.2%}")
print(f"数据量: {len(self.df)} 个交易日")
# 生成绩效报告
analyzer = PerformanceAnalyzer(df_result)
analyzer.summary()这里有几个细节值得展开。夏普比率的计算中,年化波动率是用日收益率的标准差乘以√252得到的,因为一年大约有252个交易日。最大回撤的计算用了expanding().max()——这是pandas中非常强大的一个方法,它可以计算"到当前为止的历史最大值",不需要循环。胜率的计算非常简单——就是盈利交易日占总交易日的比例,但要记住胜率高不等于收益高,高胜率低盈亏比可能还不如低胜率高盈亏比。

一个"好策略"的及格线:夏普比率 > 0.5(越高越好),最大回撤 < 30%(越小越好),年化波动率控制在25%以内。如果一个策略夏普比率低于0.2,说明你的收益几乎都是靠运气和风险换来的,不值得投入真金白银。
07 参数优化:用网格搜索找到最优参数组合
双均线策略有两个关键参数:短期窗口和长期窗口。什么样的参数组合最好?5日和20日?还是10日和30日?我们不能凭感觉来,要用数据说话。这就引出了参数优化的概念。
最常见的优化方法是网格搜索——把所有可能的参数组合都跑一遍,选出夏普比率最高的那组。但这里有巨大的陷阱。
from itertools import product
def grid_search(df, short_range, long_range):
"""网格搜索最优参数"""
results = []
for short_win, long_win in product(short_range, long_range):
if short_win >= long_win:
continue
# 运行策略
strategy = DualMAStrategy(short_win, long_win)
df_signals = strategy.generate_signals(df)
# 运行回测
engine = BacktestEngine()
df_result = engine.run(df_signals)
# 计算绩效
analyzer = PerformanceAnalyzer(df_result)
results.append({
"short_window": short_win,
"long_window": long_win,
"sharpe": analyzer.sharpe_ratio(),
"max_dd": analyzer.max_drawdown(),
"annual_ret": analyzer.annual_return()
})
return pd.DataFrame(results).sort_values("sharpe", ascending=False)
# 网格搜索
results = grid_search(df, range(3, 21), range(10, 61))
print("Top 5 参数组合:")
print(results.head())
print(f"\n共测试 {len(results)} 组参数")注意代码中的一个细节:我们跳过了短期窗口大于长期窗口的组合(if short_win >= long_win: continue)。这不是bug,而是有意为之——短期窗口必须小于长期窗口,否则"金叉"和"死叉"的概念就没有意义了。
过拟合警告:网格搜索最大的风险是过拟合。你测试了足够多的参数组合,总有一组在历史上表现特别好——但这只是巧合,不代表未来也能赚钱。解决方案是样本外测试:用一部分历史数据做优化,用另一部分做验证,看优化出的参数在验证集上是否依然有效。如果优化集和验证集的夏普比率差异超过30%,策略很可能过拟合了。
08 可视化:用一张图看懂策略的全部表现
数字固然重要,但一张好的图表胜过千言万语。把策略的资金曲线、回撤曲线画出来,一目了然。下面是一个完整的可视化函数:
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
def plot_backtest(df_result):
"""绘制回测结果"""
fig, axes = plt.subplots(3, 1, figsize=(14, 10))
# 子图1: 资金曲线 vs 基准
df_result["benchmark"] = 100000 * (1 + df_result["returns"].fillna(0)).cumprod()
axes[0].plot(df_result["date"], df_result["total_value"], label="策略", linewidth=1.5)
axes[0].plot(df_result["date"], df_result["benchmark"], label="买入持有",
alpha=0.5, linestyle="--")
axes[0].set_title("资金曲线对比", fontsize=14, fontweight="bold")
axes[0].legend()
axes[0].grid(True, alpha=0.3)
# 子图2: 回撤曲线
cumulative = (1 + df_result["strategy_returns"].fillna(0)).cumprod()
peak = cumulative.expanding().max()
drawdown = (cumulative - peak) / peak * 100
axes[1].fill_between(df_result["date"], 0, drawdown, alpha=0.3, color="red")
axes[1].plot(df_result["date"], drawdown, color="red", linewidth=1)
axes[1].set_title("回撤曲线 (%)", fontsize=14, fontweight="bold")
axes[1].grid(True, alpha=0.3)
# 子图3: 日收益率分布
axes[2].hist(df_result["strategy_returns"].dropna() * 100, bins=50,
alpha=0.7, color="steelblue", edgecolor="white")
axes[2].axvline(x=0, color="red", linestyle="--", alpha=0.5)
axes[2].set_title("日收益率分布 (%)", fontsize=14, fontweight="bold")
axes[2].grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig("backtest_result.png", dpi=150, bbox_inches="tight")
plt.show()
print("图表已保存为 backtest_result.png")
# 生成图表
plot_backtest(df_result)三张图分别展示了策略的核心维度:资金曲线告诉你赚没赚钱,回撤曲线告诉你经历过多大的痛苦,收益率分布告诉你盈利和亏损的形态。一个好的策略,资金曲线应该是稳步向上的,回撤曲线不应该有持续加深的趋势,收益率分布应该略微右偏——说明大多数日子是小赚小亏,偶尔有大赚。
最后想强调一个很多人忽略的细节:matplotlib的中文支持。如果你直接用默认配置,所有中文都会变成方框。上面代码中的两行matplotlib.rcParams设置就是解决这个问题的——SimHei是黑体字体,axes.unicode_minus解决负号显示问题。如果你电脑上没有SimHei字体,可以换成"Microsoft YaHei"或者其他已安装的中文字体。
09 完整代码整合:一个可以运行的量化回测系统
把上面所有代码整合在一起,你就拥有了一个完整的、可以运行的量化回测系统。下面是完整的main函数:
if __name__ == "__main__":
# 1. 获取数据
print("正在获取数据...")
df = get_index_data()
# 2. 参数优化(可选)
print("正在进行参数优化...")
results = grid_search(df, range(3, 21), range(10, 61))
best = results.iloc[0]
print(f"最优参数: 短期={best['short_window']}, 长期={best['long_window']}")
# 3. 运行最优策略
print("运行最优策略...")
strategy = DualMAStrategy(best["short_window"], best["long_window"])
df_signals = strategy.generate_signals(df)
# 4. 执行回测
engine = BacktestEngine()
df_result = engine.run(df_signals)
# 5. 绩效报告
print("\n")
analyzer = PerformanceAnalyzer(df_result)
analyzer.summary()
# 6. 可视化
print("\n正在生成图表...")
plot_backtest(df_result)
print("\n回测完成!")如果你把上面所有代码复制到一个Python文件中运行,你会看到完整的回测流程:数据获取、参数优化、策略执行、绩效报告、图表生成。整个过程从零开始,大约需要三到五分钟的数据下载时间,然后一切自动化。这就是量化交易的魅力——你只需要写一次代码,就可以反复验证无数个交易想法。
从这篇文章开始,你拥有了一个可以独立运行的量化回测系统。下一步可以做很多事情:替换策略逻辑(把双均线改成布林带、MACD、RSI任意一种),增加多资产支持(同时回测多只股票)、加入风险管理和仓位优化、接入实时行情做模拟盘。量化交易的乐趣在于无限的可能性,而你已经掌握了一把打开所有可能性的钥匙。
写代码的意义不在代码本身,而在于它让你每一次交易决策都有据可依。当你把一个想法变成代码,在历史数据上验证过之后,你就已经超过了90%凭感觉交易的散户。这30分钟的投资,值得。
本文代码仅供学习和研究使用,不构成任何投资建议。市场有风险,交易需谨慎。文中回测结果仅为示例,不代表未来收益。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
