期刊图片复现|Python绘制平行坐标轴图展示机器模型超参数优化结果
- 2026-07-01 05:03:55
期刊图片复现|Python绘制平行坐标轴图展示机器模型超参数优化结果

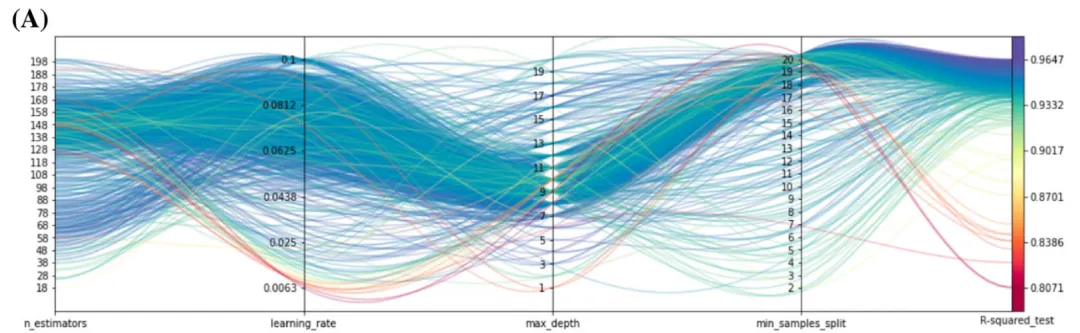
论文原图 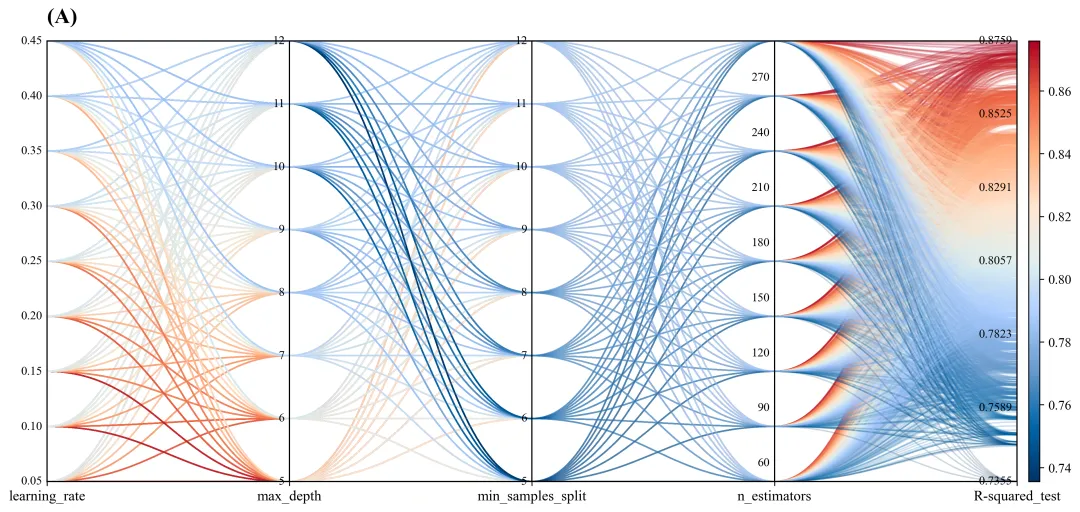
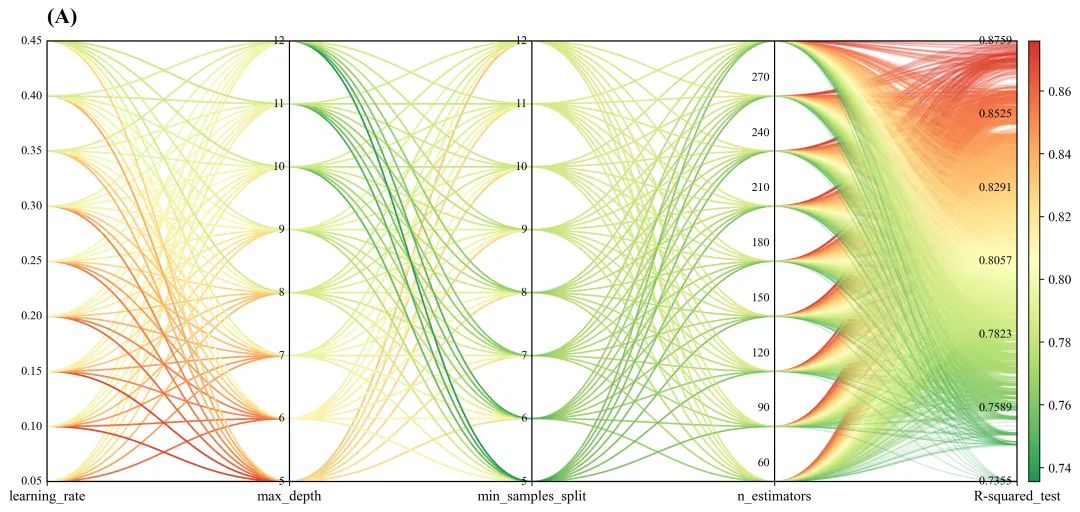
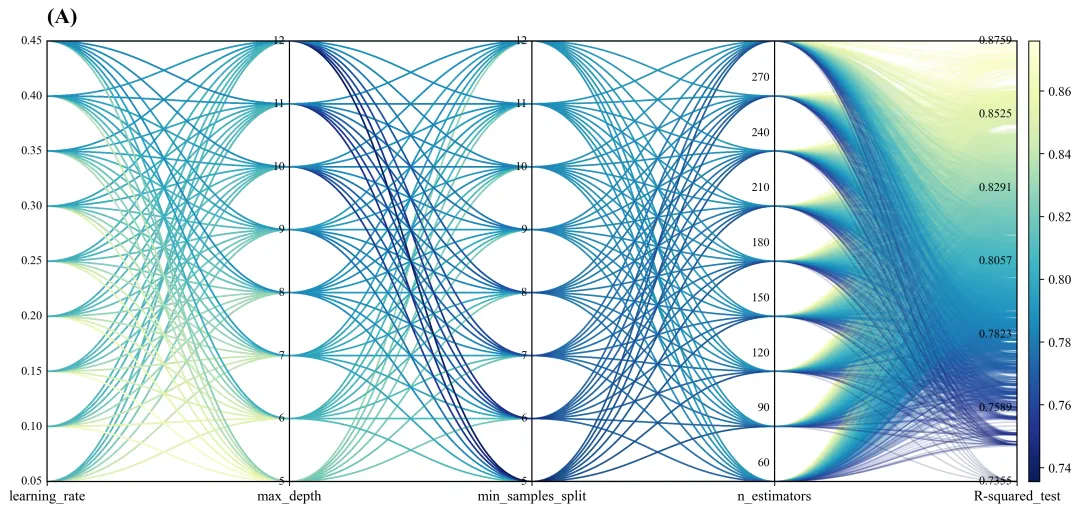
此图展示了机器学习模型的超参数组合与最终测试集决定系数之间的多维映射关系。图中最右侧的颜色条和纵轴表明,模型性能从低到高被分别映射为从深蓝色到深红色的渐变色,即红色线条代表具有高R2得分的模型配置。通过这些红色线条的轨迹可以明显观察到,取得最优性能的超参数组合通常倾向于选择较低的学习率 仿图 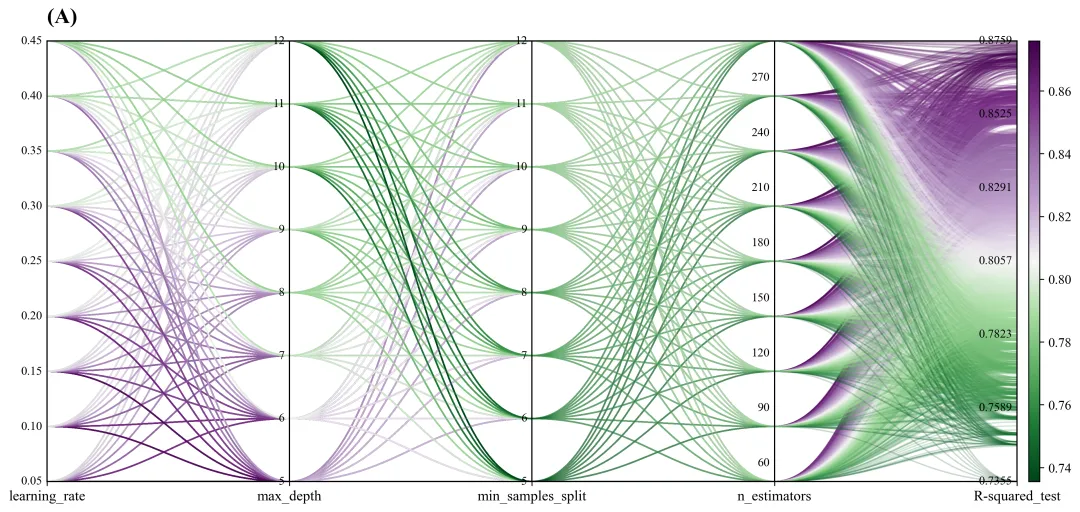
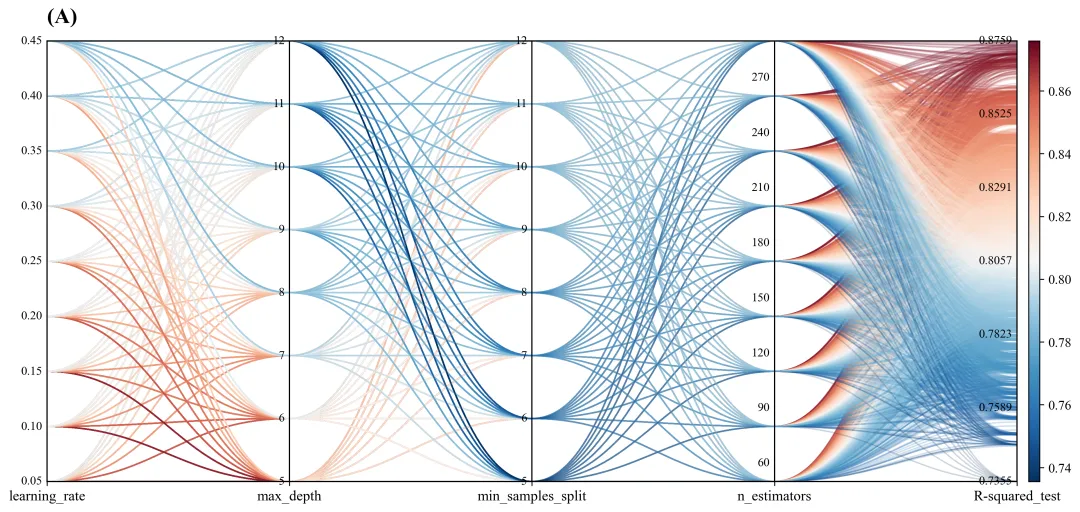
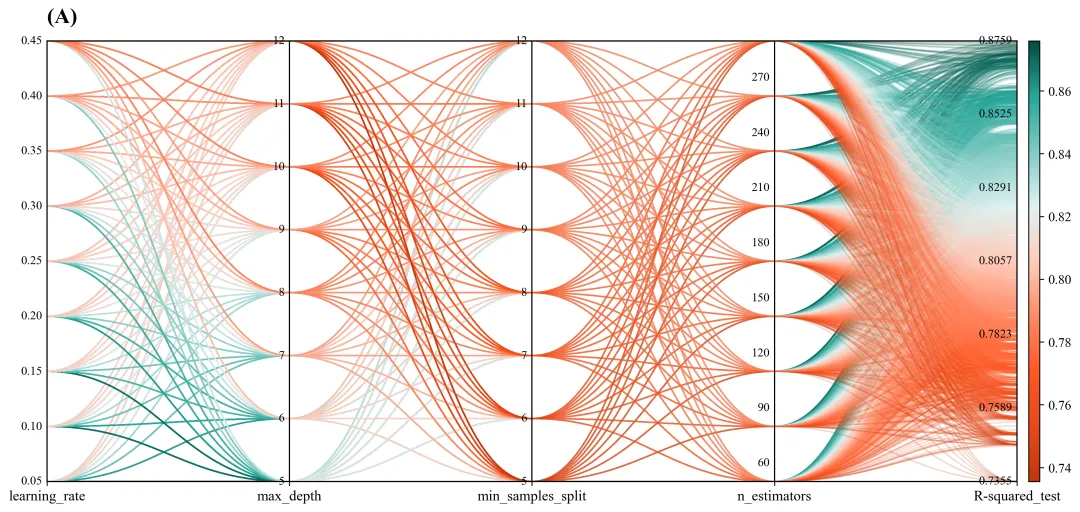
多种配色 



库的导入以及字体设置 

颜色库 

绘图函数:数据准备与画布创建 

绘图函数:绘制平滑连线 

绘图函数:绘制坐标轴、刻度线与文本标签 

绘图函数:刻度调整,边框设置,颜色条设置,绘图结果保存 

执行部分:读取数据,提取特征和目标变量。构建超参数网格字典。实例化并运行 



期刊图片复现|Python绘制二维偏依赖PDP图 期刊复现|python绘制基于SHAP分析和GAM模型拟合的单特征依赖图 期刊图片复现|python绘制带有渐变颜色shap特征重要性组合图(条形图+蜂巢图) 期刊复现|用Python绘制SHAP特征重要性总览图、依赖图、双特征交互效应SHAP图,解锁XGBoost模型的终极奥秘 期刊图片复现|Python绘制shap重要性蜂巢图+单特征依赖图+交互效应强度气泡图+交互效应依赖图(回归+二分类+分类) 

公众号中的所有所有的免费代码都已经下架了,都并入到付费部分里了,付费合集代码和数据的购买通道已经开通,全部合集100元,后续将会持续更新,决定购买请后台私信我,注意只会分享练习数据和代码文件,不会提供答疑服务,代码文件中已经包含了每行代码的完整注释,购买前请确保真的需要!!!
代码绘制成果展示
论文:Interpretable machine learning-assisted strategy for predicting the mechanical properties of hydroxyl-terminated polyether binders
learning_rate以及较浅的树深度max_depth;min_samples_split的取值分布相对宽泛,而n_estimators则多流向中高值以确保模型获得充分的拟合。这种方式为我们在后续缩小参数搜索空间、进行更精细的模型调优提供了非常明确且有价值的指导方向。代码解释
第一部分
# =========================================================================================# ====================================== 1. 环境设置 =======================================# =========================================================================================import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport matplotlib.path as mpathimport matplotlib.patches as mpatches
第二部分
# =========================================================================================# ======================================2.颜色库=======================================# =========================================================================================COLOR_SCHEMES = {1: ['#003366', '#0066AA', '#6699CC', '#AACCFF', '#E0F0F0', '#FFE5D0', '#FFB080', '#EE6644', '#AA0022'],}
第三部分
# =========================================================================================# ======================================3.绘图函数=======================================# =========================================================================================def plot_hyperparameter_optimization(df, scheme_id):df_norm = (df - df.min()) / (df.max() - df.min()) #归一化处理,统一映射在0到1的y轴空间上cols = df.columns #提取列名作为x轴的垂线x_coords = np.arange(len(cols)) #生成X轴坐标#创建画布fig, ax = plt.subplots(figsize=(14, 6))colors = COLOR_SCHEMES.get(scheme_id, COLOR_SCHEMES[1]) #提取配色方案custom_cmap = LinearSegmentedColormap.from_list('custom_scheme', colors) #创建渐变色norm = plt.Normalize(df['R-squared_test'].min(), df['R-squared_test'].max()) #映射
第四部分
#遍历每一次结果for i in range(len(df)):y_vals = df_norm.iloc[i].values # 提取超参数和结果color = custom_cmap(norm(df['R-squared_test'].iloc[i])) #获取具体的颜色verts = [] #贝塞尔曲线的顶点列表codes = [] #路径指令列表verts.append(p0) #添加最初起点坐标codes.append(mpath.Path.MOVETO) #移动画笔至此指令path = mpath.Path(verts, codes) #生成路径对象#创建曲线patch = mpatches.PathPatch(path,facecolor='none',edgecolor=color,lw=1.2,alpha=0.2)ax.add_patch(patch) #绘制在子图上
第五部分
#坐标轴刻度间隔step_dict = {'n_estimators': 30,'learning_rate': 0.05,'max_depth': 1,'min_samples_split': 1}else: #R2ticks_positions = np.linspace(0, 1, 7) #划分刻度位置ticks_values = np.linspace(min_val, max_val, 7) #划分刻度位置数值#遍历对应的Y轴相对高度与数值刻度for pos, val in zip(ticks_positions, ticks_values):#格式化处理刻度if col == 'learning_rate':label = f"{val:.2f}"elif col == 'R-squared_test':label = f"{val:.4f}"else:label = f"{int(np.round(val))}"#添加文本标注ax.text(i - 0.02, #xpos, #ylabel, #文本va='center', #水平ha='right', #垂直fontsize=10, #大小zorder=4) #层
第六部分
ax.set_xticks(x_coords) #X轴刻度ax.set_xticklabels(cols, fontsize=12) #X轴刻度标注ax.set_yticks([]) #y轴刻度ax.set_xlim(0, len(cols) - 1) #x轴范围ax.set_ylim(0, 1) #y轴范围#添加颜色条cbar = fig.colorbar(sm,ax=ax,pad=0.01,aspect=40)cbar.ax.tick_params(labelsize=11) #设置颜色条刻度标注#子图编号ax.set_title("(A)",#文本loc='left',#位置fontsize=18,#字体大小fontweight='bold',#加粗pad=15) #间隔
第七部分
GridSearchCV。提取每一次参数组合和其对应的测试得分,调用绘图函数进行绘图。# =========================================================================================# ======================================4.执行部分=======================================# =========================================================================================if __name__ == "__main__":df_raw = pd.read_excel(r'data.xlsx') #读取原始数据X = df_raw.drop(columns=['Target_ER']) #特征y = df_raw['Target_ER'] #目标#超参数param_grid = {'n_estimators': list(range(50, 300, 30)),'learning_rate': [0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45],'max_depth': list(range(5, 13, 1)),'min_samples_split': list(range(5, 13, 1))}#是否批量绘图plot_all = Trueif plot_all:for i in COLOR_SCHEMES.keys():plot_hyperparameter_optimization(df_results, scheme_id=i)else:target_scheme = 20plot_hyperparameter_optimization(df_results, scheme_id=target_scheme) #(注:您结尾的多余符号在此已修复)
如何应用到你自己的数据
1.设置原始数据的保存路径,执行部分:
df_raw = pd.read_excel(r'data.xlsx') #读取原始数据2.分离特征数据与目标数据,执行部分:
X = df_raw.drop(columns=['Target_ER']) #特征y = df_raw['Target_ER'] #目标
3.设置超参数,执行部分:
param_grid = {'n_estimators': list(range(50, 300, 30)),'learning_rate': [0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45],'max_depth': list(range(5, 13, 1)),'min_samples_split': list(range(5, 13, 1))}
4.设置是否进行批量绘图,执行部分:
plot_all = True5.设置绘图结果的保存地址,绘图函数部分:
plt.savefig(fr'results_{scheme_id}.png', dpi=300,bbox_inches='tight')推荐
获取方式
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python的requirements.txt你真的写对了吗?多人协作中的依赖地狱这样避
- Python小白成长记 · 第11课 | 文件组织与调试技巧(下)
- 22系列菲律宾比索PHP欣赏
- Java 近期资讯:OpenJDK、 Oracle 关键补丁更新、 Open Liberty、Testcontainers、IntelliJ IDEA
- 5月11日开课|Python数据可视化和项目实战培训:让数据呈现更直观
- 财务人学了Python对薪资提升有帮助吗?
- 【Python 代码分享】ABM 教学:Schelling 隔离模型竟如此简单
- 【python3.11.3】python3.11.3setup安装包获取python安装步骤与激活讲解
- 30个超有趣的python代码,让你从入门到上头!
- 社招|Python AI工程师岗,邀你破局起飞
