一、缘起
深秋,天气渐渐冷了,尤其是昨夜还下了一场小雨——豆豆出门之前特意穿上了厚厚的毛衣,不过骑着自行车还是有点凉丝丝的。
自行车道的地面上铺满了落叶,那些依然挂在枝头的叶子,经过雨水的洗礼,颜色变得更加浓郁,仿佛是大自然用画笔在它们身上精心涂抹了一层更深的秋意。金黄、橙红、深褐,这些色彩交织在一起,构成了一幅动人的秋日画卷。
豆豆想,如果我们真像《黑客帝国》中说的那样,生活在一个虚拟化的超级系统中,那这个系统的架构师该有怎样精密复杂的构思和“无微不至”的艺术鉴赏力呢?那可真的是“包罗万象”的系统啊!
到了马老师家,豆豆忍不住向马老师提出了这个问题。
马老师一听就笑了:“豆豆,你想象中的这个超级架构师,一定懂面向对象吧?我猜他一定会把实现的细节封装在组件或对象中,并交给不同的团队或者人员分工协作去实现的,这样才能解决个体的有限认知与软件的实现无限细节之间的矛盾——即使他是超级AI,也要受算力的限制啊。”
“……” 豆豆一时没理解马老师的话。
“没关系,咱们学完这节课就能帮助你理解我的意思了”,马老师说,“现在,把你的作业拿出来看看吧。”
二、豆豆的作业
豆豆把打开VSCode,把自己建好的数据库及SQL语句打开给马老师看:
-- 创建一个名为 students 的表,包含学号、姓名、性别、年龄、班级、出生日期、联系方式和地址等属性CREATE TABLE students ( student_id TEXT PRIMARY KEY, -- 学号,主键 name TEXT NOT NULL, -- 姓名 gender TEXT NOT NULL, -- 性别 age INTEGER NOT NULL, -- 年龄 class TEXT NOT NULL, -- 班级 birth_date DATE NOT NULL, -- 出生日期 contact_info TEXT, -- 联系方式 address TEXT -- 地址);-- 向 students 表中插入三条数据INSERT INTO students (student_id, name, gender, age, class, birth_date, contact_info, address) VALUES ('S001', '豆豆', '男', 20, '计算机科学与技术1班', '2004-05-01', '13800138000', '北京市海淀区');INSERT INTO students (student_id, name, gender, age, class, birth_date, contact_info, address) VALUES ('S002', '悠悠', '女', 19, '计算机科学与技术2班', '2005-06-15', '13900139000', '上海市浦东新区');INSERT INTO students (student_id, name, gender, age, class, birth_date, contact_info, address) VALUES ('S003', '乐乐', '男', 21, '软件工程1班', '2003-07-22', '13700137000', '广州市天河区');-- 查询 students 表中的所有信息SELECT * FROM students;-- 更新 students 表中名为乐乐的学生的年龄为21岁UPDATE students SET age = 21 WHERE name = '乐乐';-- 更新数据后再次查询 students 表中的所有信息SELECT * FROM students;-- 删除 students 表中名为悠悠的学生的记录DELETE FROM students WHERE name = '悠悠';-- 删除数据后再次查询 students 表中的所有信息SELECT * FROM students;
“很不错!” 马老师赞许地说,“看来上节课内容你基本都掌握了。我们再来讨论个细节,学生信息表的年龄属性是必须的吗?”
“是啊,这是您要求的啊” 豆豆说。
“是我要求的,我是说,可以不通过这个属性就得到年龄信息吗?”
“您是说……从生日来计算?”
“是的,我们在数据库中保存了出生日期属性,这也就是说,年龄是可以通过当前日期-出生日期的方式来计算的。否则的话你想想,今年入库的乐乐21岁,明年你再去查,还是21岁……”
“那怎么办啊?” 豆豆说,“我每次去查询数据都得计算吗?”
“是的,要想得到动态的年龄,你可以这么写查询语句——”
-- 查询 students 表中的所有信息,并计算年龄SELECT student_id, name, gender, class, birth_date, contact_info, address, ROUND((julianday('now') - julianday(birth_date)) / 365.25, 0) AS age -- 计算年龄FROM students;
“原来查询的数据可以是计算得到的啊!” 豆豆说,“这两个函数是什么意思啊?为什么还除以365.25?一年不是365天吗?”
“关于SELECT语句的语法细节多着呢,以后你掌握得越多就感觉它强大。” 马老师说,“SELECT后面可以直接用字段进行计算,也能套用SQLite内置的函数,计算的结果可以用 AS 字段名 形式作为一个新列展示出来。”
“这里的ROUND不用解释了吧,在SQLite中它也是用于四舍五入来保留一定小数位数的,而julianday这个函数是 SQLite 中用于将日期转换为儒略日(Julian Day Number,JDN)的。儒略日是一个连续的日计数,它从公元前4714年1月1日开始计算。这个计数包括所有的天数,无论是平年还是闰年。简单来说,我们用这种方式把当前日期和生日换成整数,再相减得到天数之差,除以365.25得到年,也就是年龄。这里之所以用365.25,是考虑到四年为一个闰年,平均下来一年是365.25天。”
“明白了,真麻烦呀。” 豆豆说,“没有其它办法吗?”
“其实这主要是因为SQLite的函数库不够丰富。你可以用这么个捷径——”
select *, date() - birth_date AS age from students;
“这回挺短的,” 豆豆说,“SELECT 后面的*是全部字段的意思我知道,不过这个date()函数应该是返回当前日期吗?两个日期直接相减会得到年?我觉得相减应该得到天吧”
“那你试试。”
豆豆试了一下,
student_id name gender class birth_date contact_info address ageS001 豆豆 男 计算机科学与技术1班 2004-05-01 13800138000 北京市海淀区 20S002 悠悠 女 计算机科学与技术2班 2005-06-15 13900139000 上海市浦东新区 19S003 乐乐 男 软件工程1班 2003-07-22 13700137000 广州市天河区 21
“这是为什么呢?” 豆豆觉得难以理解。
“其实,SQLite这个数据库毕竟是轻量型的,它对数据类型处理比较灵活。这里我们用字符串格式表示日期,计算它们的差时,其实相当于先把它们转换为数字再处理,比如'2024-5-1' - '2004-1-1' 实际是计算2024-2004,这只是利用了SQLite的处理逻辑,不是可靠的计算方法。要精确计算还是用上面的julianday更合适”
“其它数据库也是这样的吗?” 豆豆问。
“不是的,每种数据库对日期类型的处理都有自己的特殊之处,比如将来你用SQL Server,就可以用YEAR函数来获得日期数据年份,那就方便多了。现在,我们不用深究太多。”
“我们能不能还是保存年龄字段,只是每过一年更新一下数据库,把每一个人的年龄加一不就行了。” 豆豆灵机一动地说。
“说得好!” 马老师说,“其实数据库的设计是很有学问的,应该尽可能减少冗余,刚才我们想去掉年龄,按生日计算就是这个意思。但是反过来说,如果数据库的数据很多,我们想查询的时候方便,那完全可以设计一个冗余的年龄字段,每年更新一次就行——前提是你得接受年龄的误差。”
“这就是设计的精髓——没有最好的设计,只有最合适的设计,我们设计程序也好,数据库也好,都是在一定的限制条件下,寻求能够更好解决问题的方案,能解决问题的方案就是合适的,而不是某种技术或者手段就一定有优势。希望你以后在学习中能慢慢体会这一点。” 马老师说,“下面,咱们开始学习今天的内容吧!”
三、用Python操作数据
由于我们要完成的是“万卷书库”程序,所以还是要建立一个图书数据库的。相关的SQL语句示例如下:
-- 创建books表CREATE TABLE books ( id INTEGER PRIMARY KEY AUTOINCREMENT, -- 定义id为主键,自增 ISBN TEXT NOT NULL, -- ISBN号,非空 title TEXT NOT NULL, -- 书名,非空 author TEXT, -- 作者 category TEXT, -- 分类 purchase_date DATE, -- 购买日期 is_read BOOLEAN, -- 是否已读 completion_date DATE, -- 完成日期 notes TEXT -- 备注);-- 向表中插入数据INSERT INTO books (ISBN, title, author, category, purchase_date, is_read, completion_date, notes) VALUES ('978-3-16-148410-0', '三体', '刘慈欣', '科幻', '2024-01-01', 0, NULL, '我最喜欢的科幻小说'),('978-3-16-148410-1', '道德经', '老子', '哲学', '2024-02-01', 1, '2024-03-01', '博大精深');-- 修改表中数据UPDATE books SET is_read = 1, completion_date='2024-11-30'WHERE id = 1; -- 修改id为1的记录,变为已读-- 删除数据DELETE FROM books WHERE id = 2; -- 删除id为2的记录
这段SQL语句首先创建了一个名为 books 的表,包含了所需的字段。然后,向表中插入了两条数据。接着,更新了id为1的记录中的作者和分类字段。最后,删除了id为2的记录。这里有两点需要注意: - 图书的id属性是主键,这里我们增加了约束 AUTOINCREMENT,也就是你在向表中输入数据时不用管这个字段,它会每次在原来的id基础上增加1,也就是自动生成新的图书编号,避免我们再去查找表里的编号数据;其实这里的ISBN其实也是唯一的,每本书都有不同的ISBN号,这里为了操作方便没有用它当主键; - 插入数据的时候我们在VALUES后边写了两条用逗号分隔的数据,也就是可以一次性插入两本图书资料;
怎样用Python程序来完成数据的增删除改查操作呢?在上次课我们已经学到了怎样连接数据库、获得游标来执行SQL命令。现在我们先来实现建库、建表:
建立Python文件books.py,编写以下内容:
import sqlite3con = sqlite3.connect("books.db")cur = con.cursor()# 执行创建表和插入数据语句sql = """-- 创建books表CREATE TABLE books ( id INTEGER PRIMARY KEY AUTOINCREMENT, -- 定义id为主键,自增 ISBN TEXT NOT NULL, -- ISBN号,非空 title TEXT NOT NULL, -- 书名,非空 author TEXT, -- 作者 category TEXT, -- 分类 purchase_date DATE, -- 购买日期 is_read BOOLEAN, -- 是否已读 completion_date DATE, -- 完成日期 notes TEXT -- 备注);## 向表中插入数据INSERT INTO books (ISBN, title, author, category, purchase_date, is_read, completion_date, notes) VALUES ('978-3-16-148410-0', '三体', '刘慈欣', '科幻', '2024-01-01', 0, NULL, '我最喜欢的科幻小说'),('978-3-16-148410-1', '道德经', '老子', '哲学', '2024-02-01', 1, '2024-03-01', '博大精深');"""cur.executescript(sql)con.commit()con.close()
运行程序,系统建立books.db数据库,使用SQLite插件打开数据库和表,发现数据已经保存:
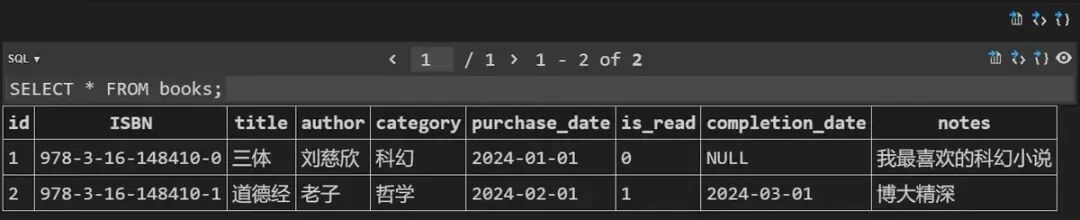
OK,我们迈出了第一步。不过这个脚本是一次性的,如果你再次运行,会得到下面的提示:
sqlite3.OperationalError: table books already exists
这是因为数据库中已经存在了名为books的表,再次执行时,由于数据库文件存在,Python不会再次创建数据库,而是连接现有的库,并在这个数据库建表,就与现有的表冲突了。而且,也无法支持我们实现手动输入图书信息、修改图书、删除图书等操作。
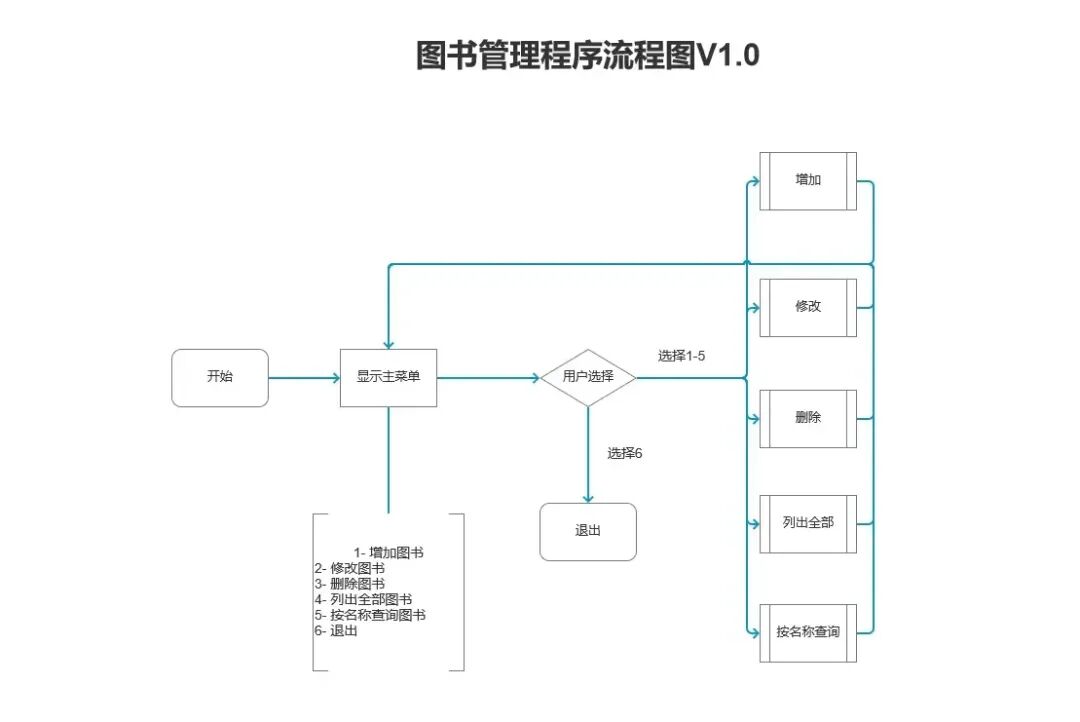
因此,这段程序用来测试可以,但要作为一个完整的图书管理程序运行,它的结构不合理。我们可以用模块化的思想重新设计这个程序,程序启动时显示一个数字菜单:
1- 增加图书 2- 修改图书 3- 删除图书 4- 列出全部 5- 按名称查询图书 6- 退出
用户运行程序时,要输入每个菜单前的数字来调用不同的模块来完成数据增删改查操作,完成操作后再次显示菜单,这样才是一个完整的图书管理系统。
可以用流程图表示我们的考虑:
基于上述设计,我们实现一个基本的程序框架:
import sqlite3# 连接数据库conn = sqlite3.connect("books.db")cursor = conn.cursor()# 创建表def create_table(): cursor.execute( """ CREATE TABLE IF NOT EXISTS books ( id INTEGER PRIMARY KEY AUTOINCREMENT, ISBN TEXT NOT NULL, title TEXT NOT NULL, author TEXT, category TEXT, purchase_date DATE, is_read BOOLEAN, completion_date DATE, notes TEXT ) """ ) conn.commit()# 增加图书def add_book(): print("图书添加成功!")# 修改图书def update_book(): print("图书信息更新成功!")# 删除图书def delete_book(): print("图书删除成功!")# 列出全部图书def list_books(): print("图书列表")# 按图书名称查询图书def search_book_by_title(): print("查询图书")# 主菜单def main_menu(): while True: print("\n1- 增加图书") print("2- 修改图书") print("3- 删除图书") print("4- 列出全部") print("5- 按名称查询图书") print("6- 退出") choice = input("请输入您的选择(1-6):") if choice == "1": add_book() elif choice == "2": update_book() elif choice == "3": delete_book() elif choice == "4": list_books() elif choice == "5": search_book_by_title() elif choice == "6": print("退出程序。") break else: print("无效的输入,请重新输入。")if __name__ == "__main__": create_table() main_menu() conn.close()
可以看出,这段代码我们把图书的增删改查都封装成了函数,在主程序中先调用create_table()函数创建表,再调用main_menu()函数显示菜单,并根据用户输入调用不同的函数(目前的函数都没有真正实现,只进行了模拟显示)。而且这段程序你可以反复运行不会出错!是不是有点奇怪?
细心的同学会发现,在建表语句中,CREATE TABLE和表名之间多了IF NOT EXISTS,变成了CREATE TABLE IF NOT EXISTS books...,这就是说,建表的时候如果发现数据库中已经有这张表,就不再创建,避免了命名冲突。
是不是很方便?不过这个IF NOT EXISTS关键字不是所有数据库系统都支持,我们如果使用别的数据库,需要先查阅它的手册,一般不支持这个关键字的数据库也会支持别的方法来判断表名是否存在。
现在,运行程序测试一下:
1- 增加图书2- 修改图书3- 删除图书4- 列出全部5- 按名称查询图书6- 退出请输入您的选择(1-6):1图书添加成功!1- 增加图书2- 修改图书3- 删除图书4- 列出全部5- 按名称查询图书6- 退出请输入您的选择(1-6):2图书信息更新成功!1- 增加图书2- 修改图书3- 删除图书4- 列出全部5- 按名称查询图书6- 退出请输入您的选择(1-6):3图书删除成功!1- 增加图书2- 修改图书3- 删除图书4- 列出全部5- 按名称查询图书6- 退出请输入您的选择(1-6):4图书列表1- 增加图书2- 修改图书3- 删除图书4- 列出全部5- 按名称查询图书6- 退出请输入您的选择(1-6):5查询图书1- 增加图书2- 修改图书3- 删除图书4- 列出全部5- 按名称查询图书6- 退出请输入您的选择(1-6):6退出程序。
这说明我们的程序总体结构可用,下面就是要补充各个函数的实现了。
1、增加图书
# 增加图书def add_book(): ISBN = input("请输入ISBN号:") title = input("请输入书名:") author = input("请输入作者:") category = input("请输入分类:") purchase_date = input("请输入购买日期(格式YYYY-MM-DD):") is_read = input("是否已读(1为已读,0为未读):") completion_date = input("完成日期(如果已读,请填写,否则留空):") notes = input("请输入备注:") query = ''' INSERT INTO books (ISBN, title, author, category, purchase_date, is_read, completion_date, notes) VALUES (?, ?, ?, ?, ?, ?, ?, ?) ''' cursor.execute(query, (ISBN, title, author, category, purchase_date, is_read, completion_date, notes)) conn.commit() print("图书添加成功!")。
* 这段代码中的函数要替换主程序框架中的同名函数,然后再运行,下同。
你会注意到这里的INSERT INTO语句和我们前面手动执行的时候不太一样,手动执行语句时,我们在VALUES后面输入了具体的值插入到表里,而上面的程序则是在VALUES后放了一系列的?,这是什么意思?
在SQL中,?是一个参数占位符,它用于在执行SQL命令时提供参数。我们在使用参数化查询时,会在 SQL 语句中放置一个或多个?占位符,然后在执行查询时传递一个参数列表。数据库接口会将这些参数安全地绑定到 SQL 语句中的相应位置。这样做一方面使代码更清晰,易于理解和维护;另一方面,这种方式让数据库预先对语句进行编译,可以提高语句执行性能;最重要的是防止SQL注入攻击,确保你的数据库安全。前面两个不用解释,最后这个注入攻击,我们后面的课程再来讲解,现在只需了解它能提升安全性即可。
在上面的代码中, ?占位符被用来表示将要插入的值的位置。在cursor.execute(query, (ISBN, title, author, category, purchase_date, is_read, completion_date, notes))这行代码中,(ISBN, title, author, category, purchase_date, is_read, completion_date, notes)是传递给 SQL 语句的实际参数,它们将分别替换 SQL 语句中的每个?。
运行程序,测试一下:
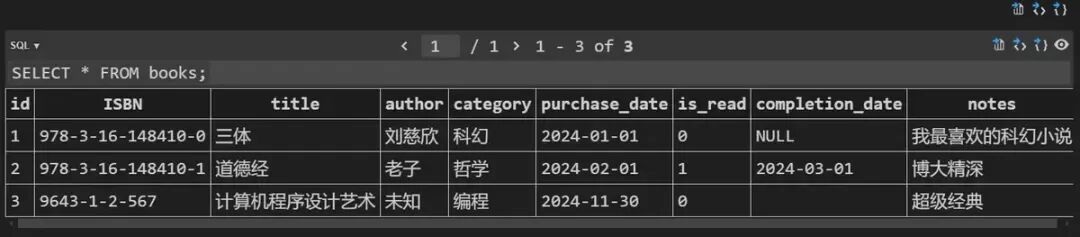
1- 增加图书2- 修改图书3- 删除图书4- 列出全部5- 按名称查询图书6- 退出请输入您的选择(1-6):1请输入ISBN号:9643-1-2-567请输入书名:计算机程序设计艺术请输入作者:未知请输入分类:编程请输入购买日期(格式YYYY-MM-DD):2024-11-30是否已读(1为已读,0为未读):0完成日期(如果已读,请填写,否则留空):请输入备注:超级经典图书添加成功!
使用插件查看数据,一切正常:
2、查询图书
为了方便观察数据,我们先把数据查询的两个函数实现。
# 列出全部图书def list_books(): query = 'SELECT * FROM books' cursor.execute(query) books = cursor.fetchall() for book in books: print(book)# 按图书名称查询图书def search_book_by_title(): title = input("请输入要查询的书名:") query = 'SELECT * FROM books WHERE title LIKE ?' cursor.execute(query, ('%' + title + '%',)) books = cursor.fetchall() if books: for book in books: print(book) else: print("没有找到匹配的图书。")
这里需要解释一下用游标cursor获取数据的方法,cursor我们已经了解,它是数据库连接对象的一个属性,游标允许我们在数据库上执行 SQL 命令。cursor 对象的fetchall()方法,用于检索 SQL 查询返回的所有行数据。当你执行一个SELECT语句时,fetchall()方法会返回一个列表,其中包含了查询结果中的所有行。books = cursor.fetchall()返回的是一个元组列表,其中每个元组代表查询结果中的一行,也就是一本书的信息。元组中的元素顺序与SELECT语句中指定的列的顺序相对应。
现在运行代码试试:
1- 增加图书2- 修改图书3- 删除图书4- 列出全部5- 按名称查询图书6- 退出请输入您的选择(1-6):4(1, '978-3-16-148410-0', '三体', '刘慈欣', '科幻', '2024-01-01', 0, None, '我最喜欢的科幻小说')(2, '978-3-16-148410-1', '道德经', '老子', '哲学', '2024-02-01', 1, '2024-03-01', '博大精深')(3, '9643-1-2-567', '计算机程序设计艺术', '未知', '编程', '2024-11-30', 0, '', '超级经典')1- 增加图书2- 修改图书3- 删除图书4- 列出全部5- 按名称查询图书6- 退出请输入您的选择(1-6):5请输入要查询的书名:三体(1, '978-3-16-148410-0', '三体', '刘慈欣', '科幻', '2024-01-01', 0, None, '我最喜欢的科幻小说')
可以看出,这里遍历数据库返回的books对象,打印出来的就是一个一个的元组。这里输出的效果并不是太理想,不过在终端中运行我们主要是为了学习数据库操作,先把界面优化的事向后放一放,它是PyQt5的任务。
3、修改图书
刚才填写图书信息的时候,我故意将作者填写成“未知”,现在需要实现修改:
def input_with_default(prompt, default): prompt += "(留空则不修改):" value = input(prompt) return value if value != "" else default# 修改图书def update_book(): book_id = int(input("请输入要修改的图书ID:")) query = "SELECT * FROM books WHERE id=?" cursor.execute(query, (int(book_id),)) book = cursor.fetchone() if not book: print("没有找到匹配的图书。") return _, ISBN, title, author, category, purchase_date, is_read, completion_date, notes = ( book ) new_ISBN = input_with_default("请输入新的ISBN号", ISBN) new_title = input_with_default("请输入新的书名", title) new_author = input_with_default("请输入新的作者", author) new_category = input_with_default("请输入新的分类", category) new_purchase_date = input_with_default("请输入新的购买日期", purchase_date) new_is_read = input_with_default("新的是否已读状态", is_read) new_completion_date = input_with_default("新的完成日期", completion_date) new_notes = input_with_default("请输入新的备注", notes) query = """ UPDATE books SET ISBN = ?,title = ?,author = ?,category = ?,purchase_date = ?, is_read = ?,completion_date = ?,notes = ? WHERE id = ? """ cursor.execute( query, ( new_ISBN,new_title,new_author,new_category,new_purchase_date, new_is_read,new_completion_datenew_notes,book_id, ), ) conn.commit() print("图书信息更新成功!")
这段代码可能是增删改查中最复杂的一段了,原因在于你不知道用户要修改哪个字段,所以要先把用户要修改的数据查询出来,一个字段一个字段地提示用户是否修改。如果修改就输入值,不修改用原来的字段值做默认值调用input_with_default()函数,这也是使用终端的无奈之处,如果是窗口的话我们就可以一次性获得用户的全部输入,不用这么麻烦了。
下面的代码使用参数化的UPDSTE查询来更新数据,就很容易理解了。
测试一下:
1- 增加图书2- 修改图书3- 删除图书4- 列出全部5- 按名称查询图书6- 退出请输入您的选择(1-6):2请输入要修改的图书ID:3请输入新的ISBN号(留空则不修改):请输入新的书名(留空则不修改):请输入新的作者(留空则不修改):高德纳请输入新的分类(留空则不修改):请输入新的购买日期(留空则不修改):新的是否已读状态(留空则不修改):新的完成日期(留空则不修改):请输入新的备注(留空则不修改):图书信息更新成功!1- 增加图书2- 修改图书3- 删除图书4- 列出全部5- 按名称查询图书6- 退出请输入您的选择(1-6):4(1, '978-3-16-148410-0', '三体', '刘慈欣', '科幻', '2024-01-01', 0, None, '我最喜欢的科幻小说')(2, '978-3-16-148410-1', '道德经', '老子', '哲学', '2024-02-01', 1, '2024-03-01', '博大精深')(3, '9643-1-2-567', '计算机程序设计艺术', '高德纳', '编程', '2024-11-30', 0, ' ', '超级经典')
修改功能完成。
4、删除图书
删除图书的函数可能是最简单的了。如下:
# 删除图书def delete_book(): book_id = int(input("请输入要删除的图书ID:")) query = "DELETE FROM books WHERE id = ?" cursor.execute(query, (book_id,)) conn.commit() print("图书删除成功!")
代码没有什么好说的,直接测试:
1-增加图书2-修改图书3-删除图书4-列出全部5-按名称查询图书6-退出请输入您的选择(1-6):4(1,'978-3-16-148410-0','三体','刘慈欣','科幻','2024-01-01',0,None,'我最喜欢的科幻小说')(2,'978-3-16-148410-1','道德经','老子','哲学','2024-02-01',1,'2024-03-01','博大精深')(3,'9643-1-2-567','计算机程序设计艺术','高德纳','编程','2024-11-30',0,' ','超级经典')1-增加图书2-修改图书3-删除图书4-列出全部5-按名称查询图书6-退出请输入您的选择(1-6):3请输入要删除的图书ID:2图书删除成功!1-增加图书2-修改图书3-删除图书4-列出全部5-按名称查询图书6-退出请输入您的选择(1-6):4(1,'978-3-16-148410-0','三体','刘慈欣','科幻','2024-01-01',0,None,'我最喜欢的科幻小说')(3,'9643-1-2-567','计算机程序设计艺术','高德纳','编程','2024-11-30',0,' ','超级经典')
测试删除了id为2的图书《道德经》,说明代码没问题。
到此,我们实现了一个完整的图书管理程序,包含增删改查基本功能。
四、专职的数据管理员
我们第一个版本的图书管理程序完整代码如下:
import sqlite3# 连接数据库conn = sqlite3.connect("books.db")cursor = conn.cursor()# 创建表def create_table(): cursor.execute( """ CREATE TABLE IF NOT EXISTS books ( id INTEGER PRIMARY KEY AUTOINCREMENT, ISBN TEXT NOT NULL, title TEXT NOT NULL, author TEXT, category TEXT, purchase_date DATE, is_read BOOLEAN, completion_date DATE, notes TEXT ) """ ) conn.commit()# 增加图书def add_book(): ISBN = input("请输入ISBN号:") title = input("请输入书名:") author = input("请输入作者:") category = input("请输入分类:") purchase_date = input("请输入购买日期(格式YYYY-MM-DD):") is_read = input("是否已读(1为已读,0为未读):") completion_date = input("完成日期(如果已读,请填写,否则留空):") notes = input("请输入备注:") query = """ INSERT INTO books (ISBN, title, author, category, purchase_date, is_read, completion_date, notes) VALUES (?, ?, ?, ?, ?, ?, ?, ?) """ cursor.execute( query, (ISBN, title, author, category, purchase_date, is_read, completion_date, notes), ) conn.commit() print("图书添加成功!")def input_with_default(prompt, default): prompt += "(留空则不修改):" value = input(prompt) return value if value != "" else default# 修改图书def update_book(): book_id = int(input("请输入要修改的图书ID:")) query = "SELECT * FROM books WHERE id=?" cursor.execute(query, (int(book_id),)) book = cursor.fetchone() if not book: print("没有找到匹配的图书。") return _, ISBN, title, author, category, purchase_date, is_read, completion_date, notes = ( book ) new_ISBN = input_with_default("请输入新的ISBN号", ISBN) new_title = input_with_default("请输入新的书名", title) new_author = input_with_default("请输入新的作者", author) new_category = input_with_default("请输入新的分类", category) new_purchase_date = input_with_default("请输入新的购买日期", purchase_date) new_is_read = input_with_default("新的是否已读状态", is_read) new_completion_date = input_with_default("新的完成日期", completion_date) new_notes = input_with_default("请输入新的备注", notes) query = """ UPDATE books SET ISBN = ?, title = ?, author = ?, category = ?, purchase_date = ?, is_read = ?, completion_date = ?, notes = ? WHERE id = ? """ cursor.execute( query, ( new_ISBN, new_title, new_author, new_category, new_purchase_date, new_is_read, new_completion_date, new_notes, book_id, ), ) conn.commit() print("图书信息更新成功!")# 删除图书def delete_book(): book_id = int(input("请输入要删除的图书ID:")) query = "DELETE FROM books WHERE id = ?" cursor.execute(query, (book_id,)) conn.commit() print("图书删除成功!")# 列出全部图书def list_books(): query = "SELECT * FROM books" cursor.execute(query) books = cursor.fetchall() for book in books: print(book)# 按图书名称查询图书def search_book_by_title(): title = input("请输入要查询的书名:") query = "SELECT * FROM books WHERE title LIKE ?" cursor.execute(query, ("%" + title + "%",)) books = cursor.fetchall() if books: for book in books: print(book) else: print("没有找到匹配的图书。")# 主菜单def main_menu(): while True: print("\n1- 增加图书") print("2- 修改图书") print("3- 删除图书") print("4- 列出全部") print("5- 按名称查询图书") print("6- 退出") choice = input("请输入您的选择(1-6):") if choice == "1": add_book() elif choice == "2": update_book() elif choice == "3": delete_book() elif choice == "4": list_books() elif choice == "5": search_book_by_title() elif choice == "6": print("退出程序。") break else: print("无效的输入,请重新输入。")if __name__ == "__main__": create_table() main_menu() conn.close()
这个程序运行正常,但如果仔细分析,它也有明显的缺点,那就是用户输入的代码和数据库操作的代码是混在一起的。如果我们接下来要使用PyQt5将它升级为Windows应用程序,就会相当麻烦。因为Windows中数据展示和输入和终端都是不一样的,这就要求我们把每个函数重新实现一遍。
有没有方法对这段程序进行重构(也就是修改代码以提高代码的可读性和可维护性,同时不改变其外部行为)呢?有,我们可以将数据库相关的操作提取到一个单独的BookDatabase类中,主程序只负责用户交互(输入数据、显示数据等),牵涉到数据库的操作,一律交给BookDatabase类处理就可以了。
我们可以这样调整代码:
import sqlite3class BookDatabase: def __init__(self, db_name): self.conn = sqlite3.connect(db_name) self.cursor = self.conn.cursor() self.create_table() def create_table(self): self.cursor.execute( """ CREATE TABLE IF NOT EXISTS books ( id INTEGER PRIMARY KEY AUTOINCREMENT, ISBN TEXT NOT NULL, title TEXT NOT NULL, author TEXT, category TEXT, purchase_date DATE, is_read BOOLEAN, completion_date DATE, notes TEXT ) """ ) self.conn.commit() def add_book( self, ISBN, title, author, category, purchase_date, is_read, completion_date, notes, ): query = """ INSERT INTO books (ISBN, title, author, category, purchase_date, is_read, completion_date, notes) VALUES (?, ?, ?, ?, ?, ?, ?, ?) """ self.cursor.execute( query, ( ISBN, title, author, category, purchase_date, is_read, completion_date, notes, ), ) self.conn.commit() print("图书添加成功!") def update_book( self, book_id, new_ISBN, new_title, new_author, new_category, new_purchase_date, new_is_read, new_completion_date, new_notes, ): query = """ UPDATE books SET ISBN = ?, title = ?, author = ?, category = ?, purchase_date = ?, is_read = ?, completion_date = ?, notes = ? WHERE id = ? """ self.cursor.execute( query, ( new_ISBN, new_title, new_author, new_category, new_purchase_date, new_is_read, new_completion_date, new_notes, book_id, ), ) self.conn.commit() print("图书信息更新成功!") def delete_book(self, book_id): query = "DELETE FROM books WHERE id = ?" self.cursor.execute(query, (book_id,)) self.conn.commit() print("图书删除成功!") def list_books(self): query = "SELECT * FROM books" self.cursor.execute(query) return self.cursor.fetchall() def search_book_by_title(self, title): query = "SELECT * FROM books WHERE title LIKE ?" self.cursor.execute(query, ("%" + title + "%",)) return self.cursor.fetchall() def search_book_by_id(self, book_id): query = "SELECT * FROM books WHERE id = ?" self.cursor.execute(query, (book_id,)) return self.cursor.fetchone() def close(self): self.conn.close()class BookManager: def __init__(self, db_name): self.db = BookDatabase(db_name) def input_with_default(self, prompt, default): prompt += "(留空则不修改):" value = input(prompt) return value if value != "" else default def add_book(self): ISBN = input("请输入ISBN号:") title = input("请输入书名:") author = input("请输入作者:") category = input("请输入分类:") purchase_date = input("请输入购买日期(格式YYYY-MM-DD):") is_read = input("是否已读(1为已读,0为未读):") completion_date = input("完成日期(如果已读,请填写,否则留空):") notes = input("请输入备注:") self.db.add_book( ISBN, title, author, category, purchase_date, is_read, completion_date, notes, ) def update_book(self): book_id = int(input("请输入要修改的图书ID:")) book = self.db.search_book_by_id(book_id) if not book: print("没有找到匹配的图书。") return ( _, ISBN, title, author, category, purchase_date, is_read, completion_date, notes, ) = book new_ISBN = self.input_with_default("请输入新的ISBN号", ISBN) new_title = self.input_with_default("请输入新的书名", title) new_author = self.input_with_default("请输入新的作者", author) new_category = self.input_with_default("请输入新的分类", category) new_purchase_date = self.input_with_default("请输入新的购买日期", purchase_date) new_is_read = self.input_with_default("新的是否已读状态", is_read) new_completion_date = self.input_with_default("新的完成日期", completion_date) new_notes = self.input_with_default("请输入新的备注", notes) self.db.update_book( book_id, new_ISBN, new_title, new_author, new_category, new_purchase_date, new_is_read, new_completion_date, new_notes, ) def delete_book(self): book_id = int(input("请输入要删除的图书ID:")) book = self.db.search_book_by_id(book_id) if not book: print("没有找到匹配的图书。") return self.db.delete_book(book_id) print("图书删除成功!") def search_book_by_title(self): title = input("请输入要查询的书名:") books = self.db.search_book_by_title(title) if books: for book in books: print(book) else: print("没有找到匹配的图书。") def list_books(self): books = self.db.list_books() for book in books: print(book) def close(self): self.db.close()def main_menu(manager): while True: print("\n1- 增加图书") print("2- 修改图书") print("3- 删除图书") print("4- 列出全部") print("5- 按名称查询图书") print("6- 退出") choice = input("请输入您的选择(1-6):") if choice == "1": manager.add_book() elif choice == "2": manager.update_book() elif choice == "3": manager.delete_book() elif choice == "4": manager.list_books() elif choice == "5": manager.search_book_by_title() elif choice == "6": print("退出程序。") manager.close() break else: print("无效的输入,请重新输入。")if __name__ == "__main__": manager = BookManager("books.db") main_menu(manager)
看上去代码相当长,实际上我们不过是将数据库操作封装成BookDatabase类,再把用户输入封装成BookManager类而已,主程序启动时先使用数据库的名称初始化BookManager类,它又会用这个名称初始化内部的BookDatabase类,由BookDataBase建立与数据库的连接并负责增删改查的实现。当程序要退出时,要调用BookManager类的close()方法,以便它通知内部的BookDatabase关闭数据库连接。
也就是说,原来由一段代码完成的工作,现在通过三段职责明确的代码分工协作来完成。这样做的好处前面已经说了,它便于程序的修改维护。BookDatabase就像一位专职的“数据库管理员”,它会忠实地执行数据层的工作,按交互层提交的命令进行增删改查操作,而不管交互层的程序是终端程序或者Windows程序,甚至是网页程序。这种分层架构设计是非常常见的,接下来我们很快就会用体会到它的用途。
五、总结
“怎么样,这次的代码有点长,是不是有点吃不消?”
“还可以啊”,豆豆兴奋地说,“虽然代码很多,可是我发现自己做的程序很实用,都感觉不到累了。”
“很好,孺子可教也!” 马老师说,“我也是只要一写程序就会忘记时间,搞得最后腰酸背痛的。还是得经常起来活动活动啊,这样对颈椎也好……”
“今天就到这,下课!”


