完整代码获取:回复“ CatBoost回归”即可获得通道
各位科研小伙伴们,大家好!
今天给大家分享一套Catboost回归建模+ SHAP+PDP二维可解释性分析10类科研图Python代码。这段代码具备一套比较完整的科研分析流程:读入数据 → 建立 CatBoost 回归模型 → 评价预测效果 → 用 SHAP 解释模型 → 分析主效应、交互效应、阈值效应 → 输出论文级图表。代码中默认读取 Excel 文件,第一列作为连续型因变量y,后面所有列作为多个自变量X ,并使用 CatBoost、SHAP、交互分析、PDP 等方法生成10类科研图。这个代码解决的科研问题是当我们手里有很多影响因素时,我们想知道这些因素能不能预测某一个结果,并且进一步想弄清楚,哪些因素最重要,它们是怎样影响结果的,它们之间有没有相互配合、相互增强或者相互削弱的关系。
代码会依次完成数据读取、训练集/测试集划分、CatBoost 模型训练、SHAP 主效应和交互效应计算,并输出图1到图10共10类图表。代码入口处的明确依次调用了数据准备、模型训练、SHAP计算以及10类图表绘制函数。
一、数据文件要求
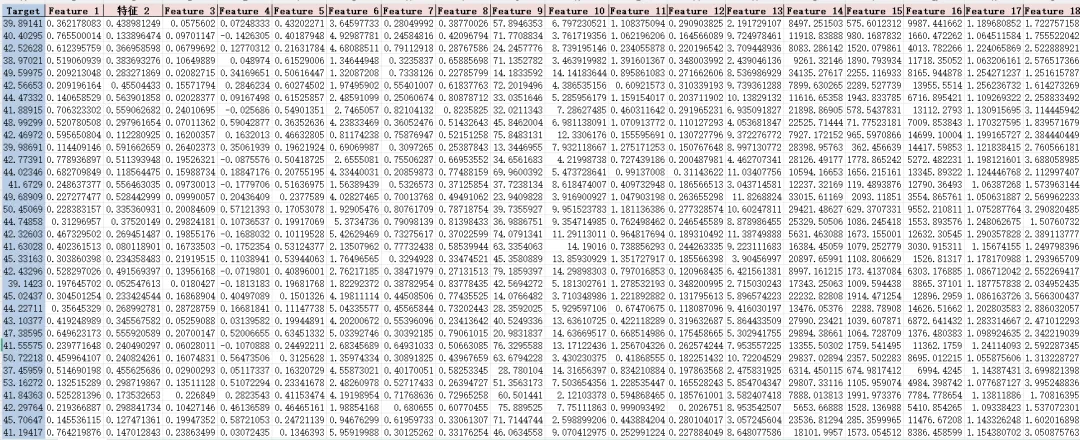
首先我们需要准备一个 Excel 表格,第一列放置目标变量(因变量y),其他列放置多列解释变量(自变量X)。第一行为各变量特征名称,其他行为对应特征的具体数值。样本量尽量多一些。
因变量 y 应该是连续数值型变量。可以理解为研究对象的最终表现,例如:作物产量、土壤有机碳含量、材料强度、污染物浓度、房价、疾病风险评分、能耗、碳排放量、经济发展指数、生态服务价值等。不适合直接用于二分类或多分类问题,比如“患病/不患病”“好/坏”“高风险/低风险”。如果要做分类,需要将CatBoostRegressor改成 CatBoostClassifier 和相应分类评价指标。
这里要特别注意一点:这段代码使用的是 CatBoost 回归模型,所以它适合处理连续型因变量。所谓连续型因变量,就是可以用具体数值表示的结果,比如污染物浓度是多少、产量是多少、材料强度是多少、评分是多少。如果你的结果是“是或否”“患病或不患病”“高风险或低风险”这种分类结果,那么这段代码就不能直接照搬,需要把回归模型改成分类模型。另外,自变量最好也是数值型数据。如果你的数据里有文字类型的变量,比如“水田、旱地、林地”或者“A组、B组、C组”,最好提前把它们转成数值编码。这样模型才能正常理解这些变量。
二、方法解读
1.数据清洗
首先,代码中设置了处理缺失值。现实科研数据中,缺失值很常见。比如某个样本少测了一个指标,某个地区缺少某个月的数据,某个实验样本有一个参数没有记录。代码使用中位数来填补缺失值。为什么不用平均数呢?因为中位数更稳健,不容易被极端值影响。比如一个变量大多数样本都在10左右,但有一个样本突然变成1000,平均数就会被明显拉高,而中位数会稳定很多。
然后,它会删除没有变化的变量。比如某一列所有样本都是同一个值,这个变量就没有任何区分能力。既然每个样本都一样,它就不可能帮助我们解释为什么有些样本结果高、有些样本结果低。所以这类变量会被剔除。完成这些基础处理后,开始下一步流程。
2.监督学习回归建模CatBoost
这段代码的主模型是 CatBoost 回归模型。CatBoost 是一种基于梯度提升树的机器学习模型,适合处理复杂非线性关系。我们可以把 CatBoost 理解为一种很擅长处理复杂关系的机器学习模型。传统线性回归更像是在数据中画一条直线,而 CatBoost 更像是通过很多棵决策树去共同判断变量和结果之间的关系。它不要求变量和结果之间一定是直线关系,因此更适合处理真实科研中常见的非线性问题。比如,一个变量可能不是越高越好,而是存在一个最佳范围;一个指标可能在低水平时影响不明显,但超过某个阈值后影响突然变强;两个变量单独看都不强,但组合起来却产生明显作用。这些复杂关系,正是 CatBoost 这类模型比较擅长捕捉的。代码中通过 RandomizedSearchCV 对 CatBoost 的迭代次数、树深度、学习率和 L2 正则化参数进行随机搜索,并用 5 折交叉验证选择最优模型。也可根据需求设置其他的参数。
3.模型可靠性
模型建好之后,我们不能马上相信它。科研中最重要的一步是验证这个模型到底有没有用?所以代码把数据分成70% 训练集和30% 测试集。训练集可以理解为平时练习题,模型通过训练集学习规律;测试集可以理解为考试题,用来检验模型能不能在没见过的数据上也表现良好。如果模型在训练集上表现很好,在测试集上也表现不错,说明模型可能真的学到了一些规律。如果模型在训练集上表现特别好,但在测试集上明显变差,那就说明模型可能只是记住了训练数据,而没有真正学会规律,这种情况叫过拟合。代码使用设置RandomizedSearchCV、cv=5、scoring='r2'为5折交叉验证随机搜索,把训练集分成5份,每次用其中4份训练、1份验证,循环5次,综合评价不同参数组合的表现。这样做的意义是避免模型只在某一次划分中表现好,以及提高参数选择的稳定性和让模型结果更具有可信度。
图1就是用来回答这个问题的。图1会展示真实值和预测值之间的关系。如果散点越接近对角线,说明预测值越接近真实值,模型越准确。图中还会显示 R²、RMSE 和 MAE 等指标。R²越接近1,说明模型解释能力越强;RMSE和MAE越小,说明预测误差越小。图1中还有一个很重要的部分,就是残差图。残差就是预测值减去真实值。如果残差大致围绕0随机分布,说明模型误差比较正常。如果残差呈现明显的弯曲、漏斗形或者分层现象,就提示模型可能还没有捕捉到某些规律,或者数据中存在更复杂的结构。
4.SHAP解释
当模型表现还不错之后,我们就要进一步解释模型为什么这样预测?这时候就要用到 SHAP。大家可以把 SHAP 理解成一种拆解预测结果的方法。一个模型给出某个样本的预测值,这个预测值并不是凭空来的,而是由很多变量共同推动形成的。SHAP 就是把这个预测值拆开,告诉我们每个变量到底贡献了多少,是把预测值推高了,还是把预测值拉低了。比如模型预测某个地区的污染物浓度较高,SHAP 可以告诉我们,是温度把它推高了,还是人口密度把它推高了,或者是降水把它拉低了。再比如模型预测某个患者风险较高,SHAP 可以告诉我们,是某个炎症因子贡献最大,还是年龄、血压、代谢指标在共同起作用。
三、十类图解读
图1:预测效果与残差评估图
图1判断 CatBoost 模型预测得准不准、稳不稳定、有没有明显偏差,这张图就像是给模型做一次考试。模型先根据自变量去预测因变量,然后我们把模型预测出来的结果和真实观测结果放在同一张图里比较。如果预测值和真实值很接近,说明模型学到的规律比较可靠;如果差距很大,就说明模型预测能力有限。
图1中间最大的散点图是最重要的部分。它的横轴通常是真实值,也就是数据里原本观察到的结果;纵轴是预测值,也就是 CatBoost 模型算出来的结果。每一个点代表一个样本。点越靠近对角线,说明这个样本预测得越准确;点离对角线越远,说明预测误差越大。代码中也确实分别绘制了训练集散点和测试集散点,并添加了 y=x 参考线和拟合线。图里的虚线一般是 y=x 线,也可以理解为完美预测线。如果一个点刚好落在这条线上,说明这个样本的预测值和真实值完全一致。真实科研中不可能所有点都完全落在线上,但如果大部分点都围绕这条线分布,说明模型总体预测效果比较好。
图中还有一条拟合线,它表示预测值和真实值之间的整体关系。如果拟合线和y=x 线非常接近,说明模型没有明显高估或低估。如果拟合线明显偏离 y=x 线,比如斜率过小,可能说明模型对高值样本预测不足、对低值样本预测偏高;如果斜率过大,则可能存在相反情况。图1还会显示训练集和测试集的评价指标,比如 R² 和 RMSE,代码中分别计算了训练集和测试集的 R²、RMSE,同时也计算了 MAE 和残差。R² 越接近 1,说明模型对目标变量变化的解释能力越强;RMSE 越小,说明模型预测误差越小;MAE 越小,说明平均预测偏差越小。如果训练集和测试集的 R² 都比较高,误差都比较低,说明模型不仅能拟合已有数据,也能较好预测新数据。如果训练集指标很好,但测试集指标明显变差,就要警惕过拟合,也就是模型可能只是背熟了训练集,但面对新样本时表现不稳定。
例图解读:
图1展示了CatBoost模型的预测性能及残差分布特征。图中横坐标为实测值,纵坐标为模型预测值,绿色散点和橙色散点分别表示训练集和测试集样本。黑色虚线为1:1参考线,表示预测值与实测值完全一致的理想状态;黑色实线为实测值与预测值之间的拟合线,用于反映模型预测结果的整体变化趋势。散点越接近1:1参考线,说明模型预测精度越高。
图中上方和右侧的边际柱状图及密度曲线分别表示实测值和预测值的分布特征,可用于比较训练集与测试集在数据分布上的一致性,并判断模型预测结果是否能够较好再现目标变量的整体分布。左上角给出的R2和RMSE用于评价模型解释能力和预测误差,其中训练集R2=0.89、RMSE=1.31,测试集R2=0.51、RMSE=2.67,表明模型在训练集上具有较高拟合精度,但在测试集上的泛化能力有所下降。下方残差图用于诊断模型预测误差的分布规律。残差定义为预测值与实测值之差,黑色水平线表示残差为0的理想状态。残差大于0说明模型高估样本值,残差小于0说明模型低估样本值。图中残差随实测值增大呈现由正向逐渐转为负向的趋势,说明模型对低值样本存在一定高估,对高值样本存在一定低估。右上角的MAE进一步表明,测试集平均绝对误差高于训练集,说明模型在独立样本上的预测稳定性仍有提升空间。
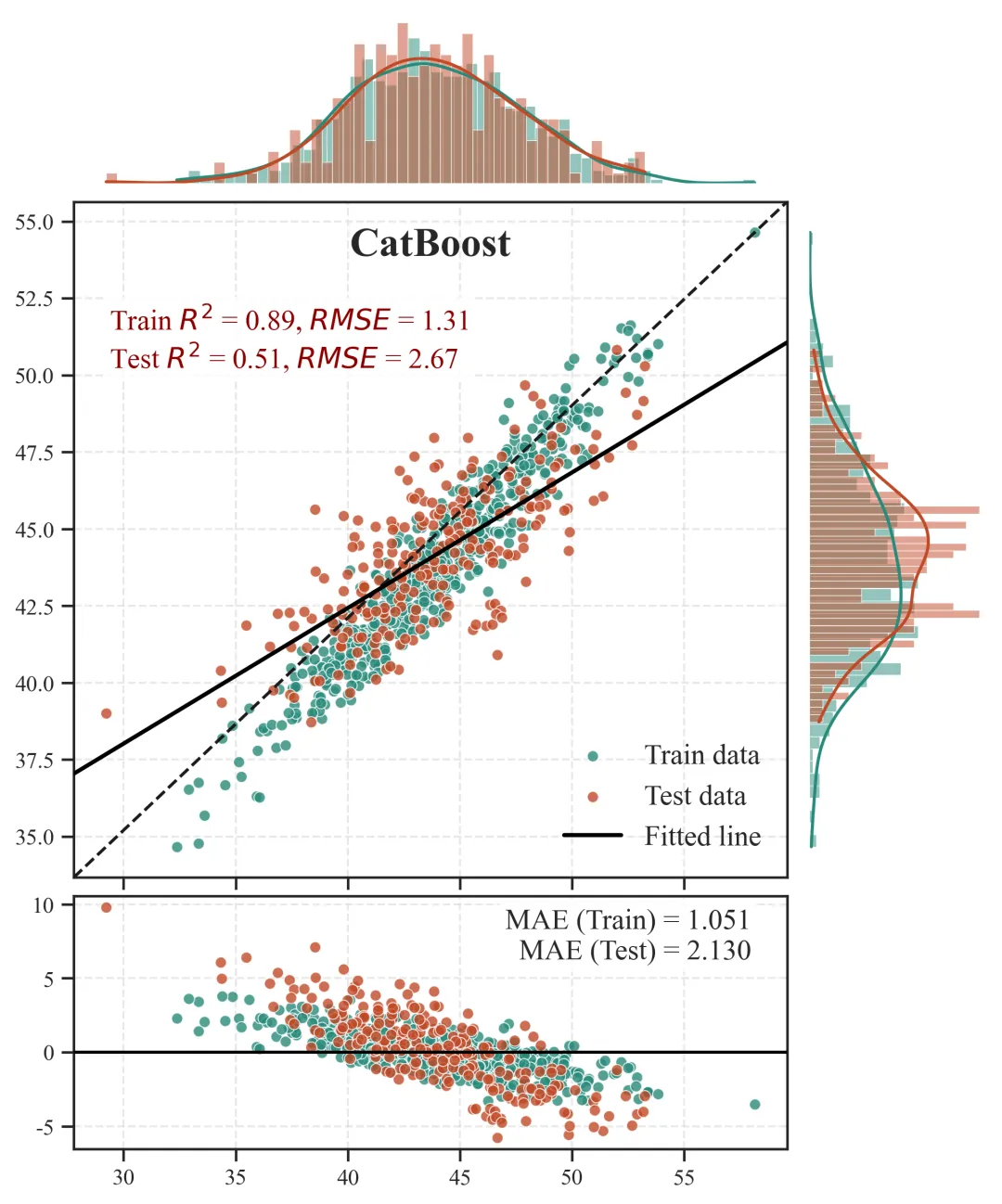
图1 CatBoost模型预测性能与残差分析。
图2:全局SHAP特征贡献图
图2为全局SHAP特征贡献图,用于解释CatBoost模型中各输入变量对模型预测结果的整体贡献程度。与传统机器学习中的特征重要性图不同,SHAP图不仅能够给出变量重要性排序,还能进一步显示每个变量在不同样本中的贡献方向和贡献强度。因此,该图不仅回答哪些变量重要,还进一步回答这些变量是倾向于提高预测值,还是降低预测值。
图2中的纵轴为模型输入特征,也就是参与CatBoost建模的各个自变量。变量通常按照平均绝对SHAP值进行排序,因此越靠近图中重要性较高位置的变量,对模型输出的整体影响越大。换句话说,排在前面的变量是模型预测过程中更关键的驱动因素。
图中的水平条形图表示每个变量的平均绝对SHAP值。条形越长,说明该变量对模型预测结果的整体贡献越大;条形越短,说明该变量对模型输出的平均影响较弱。这里需要注意,平均绝对SHAP值只反映贡献强度,并不表示正向或负向影响。也就是说,条形长只能说明该变量重要,不能说明该变量一定会提高或降低预测值。
图中叠加的散点表示每个样本中该变量对应的SHAP值。一个散点代表一个样本在该变量上的贡献值。散点在横轴右侧,说明该变量在该样本中对模型预测值产生正向贡献,即推动预测结果升高;散点在横轴左侧,说明该变量在该样本中对模型预测值产生负向贡献,即推动预测结果降低。散点距离0越远,说明该变量在该样本中的影响越强;散点越接近0,说明该变量对该样本预测结果的影响较弱。
图中的横轴为SHAP value,表示变量对模型输出的影响方向和影响大小。SHAP值大于0,说明该变量使模型预测值高于基准预测水平;SHAP值小于0,说明该变量使模型预测值低于基准预测水平。因此,横轴不仅反映变量贡献大小,也反映变量作用方向。
图中的颜色表示特征值大小。代码中将每个变量的原始取值归一化,并用颜色从低值到高值进行表示,色带标注为 Low 到 High。颜色越接近高值端,说明该样本在该变量上的取值越高;颜色越接近低值端,说明该样本在该变量上的取值越低。通过颜色和SHAP值位置的组合,可以判断变量取值升高时对预测结果的影响方向。代码中也专门设置了颜色条,并将其标注为 Feature value。
图中每个变量旁边的百分比表示该变量的相对贡献占比。代码中将单个变量的平均绝对SHAP值除以所有变量平均绝对SHAP值之和,从而得到该变量对总解释贡献的比例。百分比越高,说明该变量在模型整体解释中的贡献占比越大。
例图解读:
图2展示了CatBoost模型的全局SHAP特征贡献结果。由图可见,各输入变量对模型预测结果的贡献存在明显差异。其中,Feature 4的平均绝对SHAP值最高,相对贡献率为20.1%,是模型中最主要的影响因素;Feature 1的贡献率为15.8%,位居第二。二者合计贡献率达到35.9%,说明模型预测结果主要受这两个变量驱动。Feature 6、Feature 12、Feature 14、Feature 15、Feature 5、Feature 16、特征2和Feature 3的贡献率介于5.1%至7.0%之间,表明这些变量也对模型输出具有一定影响。相比之下,Feature 11、Feature 10和Feature 17的贡献率均低于1%,说明其在当前模型中的全局贡献相对较弱。
从变量作用方向来看,Feature 4表现出明显的正向影响特征,其高取值样本主要分布在SHAP正值区域,而低取值样本主要分布在SHAP负值区域,说明Feature 4取值升高通常会提高模型预测值。Feature 1则呈现相反趋势,其高取值样本主要位于SHAP负值区域,而低取值样本更多分布在SHAP正值区域,表明Feature 1取值升高倾向于降低模型预测结果。此外,Feature 6、Feature 14、Feature 15和Feature 5总体表现为正向贡献,而Feature 12、Feature 16、特征2和Feature 3则表现出较明显的负向贡献特征。
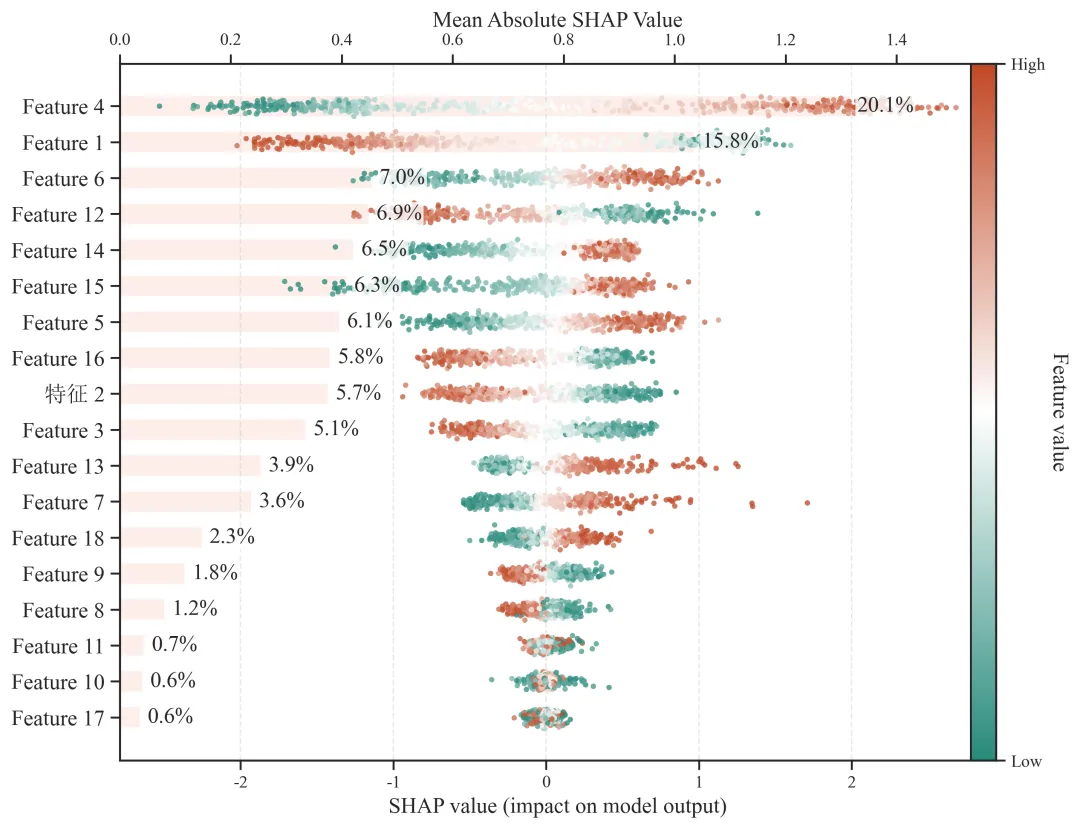
图3:全局SHAP特征贡献图
图3为 单特征SHAP依赖图,用于揭示单特征取值变化对CatBoost模型预测结果的影响方向、影响强度以及潜在阈值特征。该图横坐标为某一特征的特征取值,纵坐标为对应的SHAP值。SHAP值表示该变量在模型预测中的贡献方向和贡献大小:当SHAP值大于0时,说明某一特征在该取值范围内对模型预测结果具有正向贡献,即提高模型预测值;当SHAP值小于0时,说明某一特征对模型预测结果具有负向贡献,即降低模型预测值;当SHAP值接近0时,说明该变量对模型输出的影响接近平均水平。
图中的每一个散点代表一个样本。散点在横轴上的位置表示该样本单特征的实际取值,在纵轴上的位置表示某一特征对该样本模型预测值的SHAP贡献。散点距离0水平线越远,说明某一特征在该样本中的影响越强;散点越接近0水平线,说明其影响越弱。
右侧颜色条表示SHAP值大小,绿色代表较低SHAP值,红色代表较高SHAP值。因此,图中低特征值取值区域的散点多呈绿色,说明其对应SHAP贡献较低或为负;高特征取值区域的散点多呈红色,说明其对应SHAP贡献较高或为正。
图中的红色平滑曲线为LOWESS曲线,用于反映某一特征取值与SHAP值之间的整体变化趋势。LOWESS是一种局部加权平滑方法,不预设线性关系,因此能够较好展示变量影响的非线性变化特征。曲线周围的浅色带表示该趋势附近的波动范围,用于辅助观察样本点围绕总体趋势的离散程度。
图中的灰色水平虚线表示SHAP值为0的基准线。该线将某一特征的作用区域划分为正向贡献和负向贡献两个部分。位于该线下方的样本表示某一特征降低模型预测值,位于该线上方的样本表示某一特征提高模型预测值。
图中的红色竖向虚线标出了某一特征的关键阈值点,约为 0.20。该阈值对应LOWESS曲线与SHAP=0水平线的交点,表示某一特征对模型预测结果的作用方向在该位置附近发生转变。图中红色圆点进一步标示了该转折点。
图中浅绿色背景区域表示某一特征对模型输出的负向贡献区间,浅红色背景区域表示某一特征对模型输出的正向贡献区间。例如当某一特征取值低于约0.20时,该变量总体上降低模型预测值;当某一特征取值高于约0.20时,该变量总体上提高模型预测值。
例图解读:
图3展示了Feature 4的SHAP依赖关系,用于分析Feature 4取值变化对CatBoost模型预测结果的影响。图中横坐标为Feature 4的取值,纵坐标为Feature 4对应的SHAP值。SHAP值大于0表示该变量提高模型预测值,SHAP值小于0表示该变量降低模型预测值。红色LOWESS曲线反映Feature 4取值与SHAP贡献之间的总体变化趋势,灰色水平虚线表示SHAP=0的基准线,红色竖向虚线标示变量作用方向发生转变的阈值点。
由图可见,Feature 4与模型预测结果之间呈现显著的非线性正向关系。随着Feature 4取值升高,SHAP值由负值逐渐升高并转为正值,说明Feature 4取值增加总体上会提高模型预测结果。当Feature 4取值低于约0.20时,样本点主要位于SHAP=0以下,表明该变量在低取值区间对模型预测结果具有负向贡献;当Feature 4取值高于约0.20时,SHAP值转为正值,说明其对模型输出表现为正向贡献。因此,Feature 4约在0.20处存在明显阈值效应,该点可视为其由负向影响转为正向影响的临界值。此外,在Feature 4取值为0.20至0.45的区间内,LOWESS曲线快速上升,表明该区间内Feature 4对模型输出较为敏感;当Feature 4取值进一步升高后,SHAP值仍保持较高水平,但曲线上升趋势逐渐减缓,提示其正向贡献可能存在一定饱和效应。总体而言,Feature 4不仅是模型中的重要贡献变量,而且其影响具有明显的非线性和阈值特征,可为后续关键变量解释和作用机制分析提供依据。
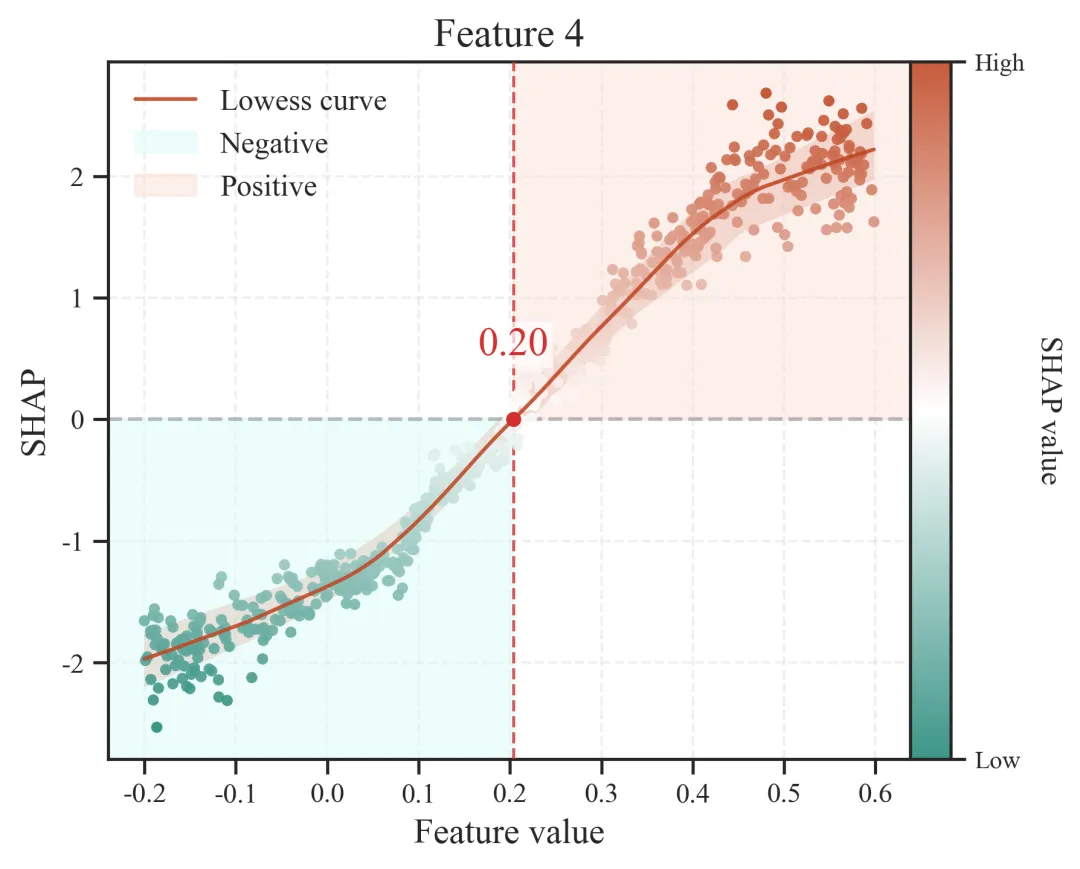
图4:主效应与交互效应对比图
图4为主效应与交互效应对比图,用于区分不同特征对模型预测结果的贡献主要来自变量自身,还是来自其与其他变量之间的交互作用。该图是对全局SHAP重要性分析的进一步深化,不仅关注“哪些变量重要”,还进一步回答“这些变量是独立发挥作用,还是通过与其他变量共同作用来影响模型输出”。
图中横坐标表示参与模型建模的各个输入特征。各特征并不是按照原始数据中的顺序排列,而是根据主效应与交互效应之和进行降序排列。因此,越靠近左侧的变量,总体影响越强;越靠近右侧的变量,总体影响相对较弱。代码中也明确先计算主效应和交互效应,再以二者之和作为总效应进行排序。
图中纵坐标表示效应强度,通常以平均绝对SHAP值表示。该数值越大,说明该变量对模型输出的影响越强。由于这里使用的是绝对值,因此图4反映的是影响强度,而不是影响方向。也就是说,图4不能直接说明某个变量是提高还是降低预测值,而是说明该变量对模型预测结果的影响有多大。
图中每个变量对应两根柱。第一根柱表示主效应,即该变量自身对模型预测结果的独立贡献。主效应越高,说明该变量即使不考虑与其他变量的联合作用,也能对模型输出产生较强影响。第二根柱表示交互效应,即该变量与其他所有变量共同作用时产生的综合贡献。交互效应越高,说明该变量的影响并不是孤立产生的,而是明显依赖于其他变量的取值背景。
图中的图例用于区分两类柱形。Main effect (Mean |SHAP|)表示变量自身的平均主效应,Interaction (sum over others)表示该变量与其他变量的交互效应总和。图中每根柱上方的数值标签表示对应效应的具体大小,便于比较不同变量之间以及同一变量内部主效应和交互效应的差异。
例图解读:
图4展示了CatBoost模型中各输入特征的主效应与交互效应分解结果。主效应表示变量自身对模型输出的独立贡献,交互效应表示该变量与其他变量共同作用产生的综合贡献。结果显示,各变量对模型预测结果的贡献存在明显差异,其中Feature 4和Feature 1表现出最强的总体贡献。Feature 4的主效应和交互效应分别为1.326和0.354,Feature 1分别为1.048和0.249,均显著高于其他变量,说明二者是模型预测结果中的核心影响因素。
从效应构成来看,大多数变量的主效应均高于交互效应,表明模型预测结果主要受变量自身独立作用驱动。其中,Feature 4和Feature 1不仅总体贡献最高,而且主效应占主导,提示其自身取值变化对模型输出具有较强直接影响。Feature 6、Feature 12、Feature 15、Feature 14、Feature 5、Feature 16、特征2和Feature 3等变量也表现出一定贡献,其主效应和交互效应均处于中等水平,说明这些变量既具有一定独立影响,也可能参与部分多因素交互过程。
值得注意的是,Feature 8、Feature 11、Feature 10和Feature 17虽然总体贡献较低,但其交互效应高于主效应,说明这些变量单独作用较弱,而更可能通过与其他变量共同作用影响模型预测结果。这提示在后续交互矩阵或两两交互分析中,可进一步关注这些变量是否在特定变量组合中发挥条件性作用。
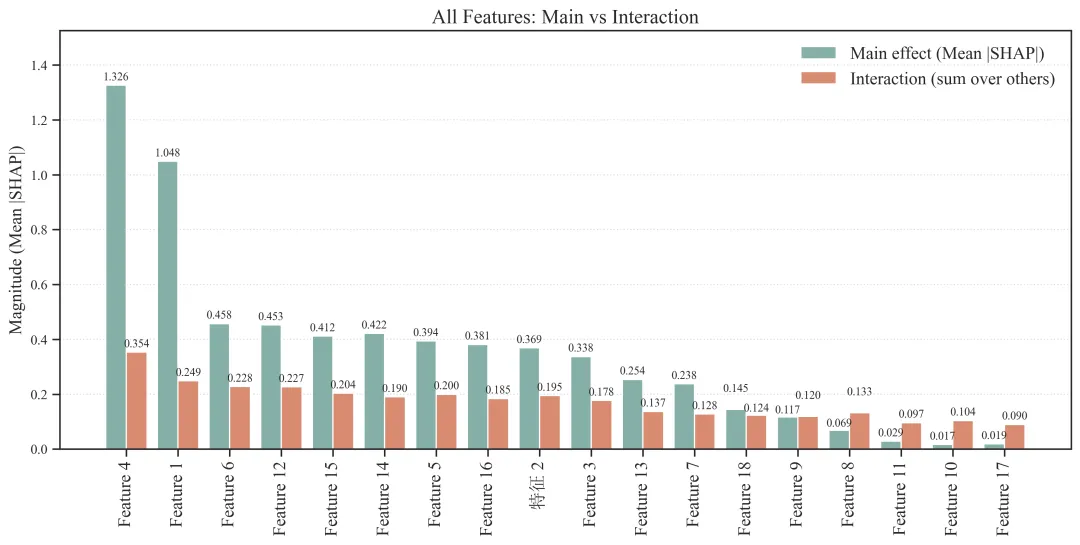
图5: SHAP交互复合矩阵图
图5为SHAP交互复合矩阵图,用于综合展示模型中重要变量之间的交互效应。与图2的全局SHAP特征贡献图不同,图5关注的不是单个变量“是否重要”,而是进一步回答:哪些变量之间存在较强交互作用,以及这种交互作用在样本层面如何分布。
图中的横轴和纵轴均表示模型输入特征。一般情况下,图5只展示前若干个重要变量,代码中默认最多展示18个特征,因此该图主要用于观察模型中核心变量之间的交互关系,而不是展示全部低贡献变量。矩阵中的每一个小格都对应一组变量关系:如果行变量和列变量相同,则表示该变量自身的主效应;如果行变量和列变量不同,则表示两个变量之间的交互效应。
图中的对角线区域表示单个变量的主效应,也就是某个变量自身对模型输出的贡献。对角线可以帮助判断哪些变量即使不考虑与其他变量的交互,也能对模型预测结果产生较强影响。若对角线上的点云分布范围较宽,说明该变量的主效应较强;若点云主要集中在0附近,则说明该变量自身贡献相对较弱。
图中的左下三角区域通常以热力图或数值形式展示两个变量之间的平均交互强度。每一个小格中的数值表示对应两个变量之间的平均绝对SHAP交互值。数值越大,说明这两个变量之间的交互效应越强;颜色越深,通常也表示交互强度越高。因此,左下三角主要用于快速识别哪些变量组合是模型中的关键交互对。
图中的右上三角区域以散点或蜂群式分布展示SHAP交互值的样本分布。它不仅告诉我们两个变量是否存在交互,还能进一步显示这种交互在不同样本中的离散程度。如果某一变量组合的散点分布范围较宽,说明这两个变量在不同样本中的交互贡献差异较大;如果散点集中在0附近,则说明该变量组合的交互贡献较弱。代码中右上三角采用了蜂窝抖动式散点分布,以提高点云的可读性,减少大量样本重叠造成的信息遮挡。
图中的颜色条表示特征值或交互强度的大小。右侧色带一般从 Low 到 High,表示变量取值或平均交互强度由低到高变化。颜色越接近高值端,说明对应样本的特征值或交互强度越高;颜色越接近低值端,说明对应值越低。代码中颜色条标签为 Raw feature value / Mean |Interaction|,说明图中颜色既服务于右上角散点的原始特征值表达,也服务于左下角热力图的平均交互强度表达。
图中标题 SHAP interaction value 表示整个矩阵围绕SHAP交互值展开。SHAP交互值可以理解为两个变量共同作用时对模型预测结果产生的额外贡献。它不同于单变量SHAP值,单变量SHAP值解释的是某个变量自身如何影响模型输出,而SHAP交互值解释的是两个变量联合变化时对模型输出的共同影响。
例图解读:
图5展示了CatBoost模型中主要输入特征之间的SHAP交互复合矩阵。矩阵对角线表示各特征的主效应分布,左下三角表示两两特征之间的平均绝对SHAP交互值,右上三角表示交互值在不同样本中的分布特征。结果显示,大多数变量对的平均绝对SHAP交互值较低,说明模型预测结果总体仍以主效应驱动为主,交互效应整体强度相对有限。从交互强度来看,Feature 4与多个变量之间存在较强交互,其中与Feature 12的交互值最高,为0.044;与Feature 14、Feature 6和Feature 15的交互值分别为0.037、0.030和0.030,表明Feature 4在模型的交互结构中处于核心位置。此外,Feature 1与Feature 14、Feature 15和Feature 5也表现出一定交互作用,说明Feature 1除独立贡献外,还参与多变量联合调节过程。右上三角的交互分布图进一步表明,强交互变量对通常具有更宽的点云分布,说明其交互效应在不同样本中存在明显异质性,提示变量间的联合作用具有一定条件依赖特征。相比之下,多数低交互变量对的分布集中于0附近,说明其联合贡献有限。
整体来看,图5表明CatBoost模型的预测结果既受到关键变量主效应的控制,也受到部分变量对交互效应的调节。其中,Feature 4是最重要的交互中心变量,其与Feature 12、Feature 14、Feature 6和Feature 15等变量的组合值得在后续交互分析和机制讨论中重点关注。

图6:两两特征交互散点图
图6为两两特征SHAP交互散点图,用于进一步分析两个特征之间的交互效应如何随主特征取值变化。相比图5的SHAP交互复合矩阵图,图5更侧重于从整体上筛选哪些变量组合具有较强交互,而图6则是对具体变量对进行放大分析,用于揭示某一对变量之间交互作用的方向、强度、非线性变化以及可能存在的阈值点。
图中的横坐标表示主特征的取值,即当前图中被作为横轴展示的变量。例如,当图题为 Feature 1 × Feature 3 时,横坐标通常表示Feature 1的实际取值。通过横坐标可以观察主特征从低值到高值变化时,其与另一个特征之间的交互效应如何发生变化。
纵坐标表示 SHAP Interaction Value,即两个特征之间的SHAP交互值。该值反映两个变量共同作用时对模型预测结果产生的额外贡献。当SHAP交互值大于0时,说明这两个变量的联合作用倾向于提高模型预测值;当SHAP交互值小于0时,说明二者的联合作用倾向于降低模型预测值;当SHAP交互值接近0时,说明这两个变量在该样本中的交互贡献较弱。
图中的每一个散点代表一个样本。散点在横轴上的位置表示该样本主特征的取值,在纵轴上的位置表示该样本中两个特征的交互贡献大小。散点距离0水平线越远,说明该样本中两个变量的交互作用越强;散点越接近0水平线,说明交互作用越弱。
图中的颜色表示另一个特征的取值水平。也就是说,如果横轴是Feature 1,颜色通常表示Feature 3的取值大小。颜色由低值到高值变化,可以帮助判断第二个变量是否会调节主变量的作用。如果高取值颜色的散点主要分布在SHAP交互值正值区域,说明第二个变量取值较高时可能增强二者的正向交互;如果高取值颜色的散点主要分布在负值区域,则说明第二个变量高取值可能增强负向交互。
图中的水平虚线通常表示 SHAP交互值为0 的基准线。它是判断正向交互和负向交互的重要参照。位于该线以上的点表示正向交互贡献,位于该线以下的点表示负向交互贡献。
如果图中出现竖向参考线,则通常表示交互效应方向发生变化的阈值点。也就是说,在该主特征取值附近,两个变量的交互作用可能由负向转为正向,或者由正向转为负向。这个位置在科研解释中非常重要,因为它提示变量间联合作用可能存在临界区间。
例图解读:
图6展示了Feature 1与Feature 3之间的SHAP交互散点关系。图中横坐标为Feature 1取值,纵坐标为Feature 1与Feature 3的SHAP交互值,散点颜色表示Feature 3取值水平。结果显示,两变量的交互值整体围绕0分布,多数样本集中于-0.05至0.05区间,提示二者之间存在一定但总体中等强度的交互作用。结合颜色分布可见,当Feature 1处于0.44至0.74区间时,高Feature 3样本更多位于正向交互区域,而低Feature 3样本更多位于负向交互区域,说明在该区间内Feature 3对Feature 1具有较明显的调节作用。相比之下,当Feature 1低于0.44时,交互作用整体较弱;当Feature 1高于0.74时,交互分布离散性增大,且部分高Feature 3样本转向负向交互区域,提示二者联合作用可能存在阈值效应和非线性变化。总体而言,Feature 1与Feature 3之间的交互关系具有明显的区间依赖性,Feature 1在约0.44和0.74附近可能是交互模式发生变化的重要转折点。
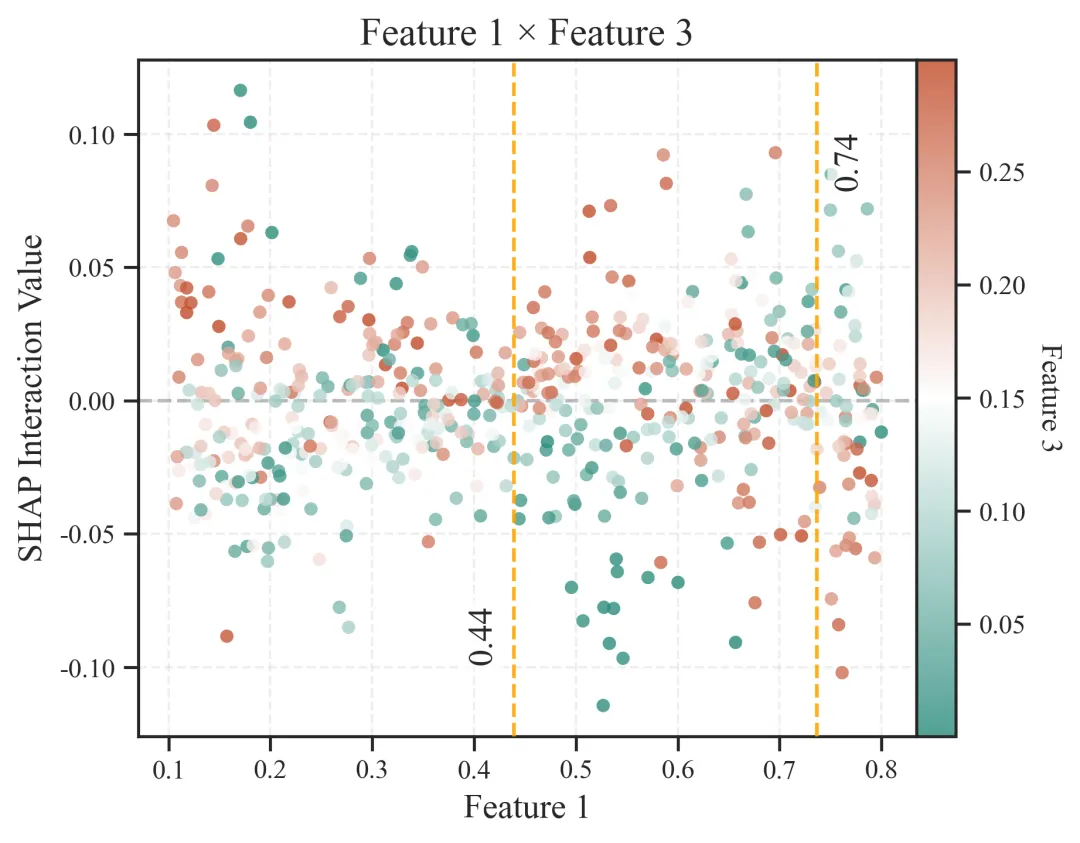
图7:特征重要性与交互网络图
图7为特征重要性与交互强度网络图,用于从网络结构角度展示模型中不同输入特征的重要性及其相互作用关系。与图2、图4、图5相比,图7的重点不是单独展示某个变量的贡献,也不是逐一列出变量对的交互值,而是把所有核心特征放入同一个网络系统中,直观呈现“哪些变量是核心节点,哪些变量之间交互更强”。
图中的每一个节点代表一个输入特征,例如 Feature 4、Feature 1、Feature 6、Feature 12 等。代码中默认展示前18个核心特征,因此图7主要反映模型中贡献较高的一组变量,而不是展示所有变量。节点的存在说明该变量被纳入了模型解释网络,是模型预测结果中的一个组成因素。
节点的大小表示该特征的全局重要性,通常由该变量的平均绝对SHAP值决定。节点越大,说明该变量对模型预测结果的总体贡献越强;节点越小,说明其全局贡献相对较弱。因此,图中较大的节点可以被理解为模型预测中的关键驱动变量。
节点的颜色深浅同样反映该变量的重要性强弱。颜色越深,表示该变量的SHAP贡献越高;颜色越浅,则表示该变量的贡献相对较低。节点大小和节点颜色共同用于突出模型中的核心特征。代码中也专门根据节点权重设置了节点大小和颜色映射。
图中的连线表示两个特征之间存在SHAP交互关系。每一条边连接两个变量,表示这两个变量在模型预测中存在一定的联合贡献。这里的连线不是简单相关性,而是基于SHAP交互值计算得到的模型层面交互强度。
连线的粗细表示两个变量之间交互效应的强弱。连线越粗,说明这两个变量之间的平均绝对SHAP交互值越大,二者在模型预测中共同作用越明显;连线越细,说明交互效应较弱。代码中将边权重归一化后映射为边宽,因此边越粗代表交互越强。
连线的颜色深浅也表示交互强度。颜色越深,说明两个变量之间的交互值越高;颜色越浅,说明二者交互较弱。图下方通常会有两个颜色条:一个表示节点重要性,即 Importance (Vimp);另一个表示交互强度,即 Interaction Intensity (Vint)。前者用于解释节点颜色,后者用于解释边颜色。
例图解读:
图7展示了CatBoost模型中各输入特征的重要性及其交互网络结构。图中每个节点代表一个输入特征,节点大小和颜色深浅表示该特征的全局重要性;节点越大、颜色越深,说明该变量对模型预测结果的贡献越高。节点之间的连线表示两两特征之间的SHAP交互关系,连线越粗、颜色越深,说明相应变量对之间的交互效应越强。由图7可见,Feature 4是网络中最突出的节点,具有最大的节点尺寸和最深的节点颜色,表明其在模型预测中具有最高的重要性。Feature 1节点也较为突出,说明其同样是模型输出的重要影响因素。Feature 6、Feature 12、Feature 14、Feature 15、Feature 5和Feature 16等变量表现为中等重要节点,而Feature 10、Feature 11和Feature 17等变量节点较小,提示其全局贡献相对较低。从交互网络结构来看,Feature 4与多个变量之间存在较明显连线,尤其与Feature 1、Feature 6、Feature 12和Feature 14等变量之间的连接相对较强,说明Feature 4不仅具有较强的独立贡献,也广泛参与多变量交互过程。Feature 1同样与多个重要变量存在交互关系,提示其在模型预测中既发挥主效应作用,也参与一定的交互调节。Feature 12、Feature 14、Feature 15和Feature 6等变量虽然重要性低于Feature 4和Feature 1,但在网络中具有一定连接作用,可能参与次级交互结构。
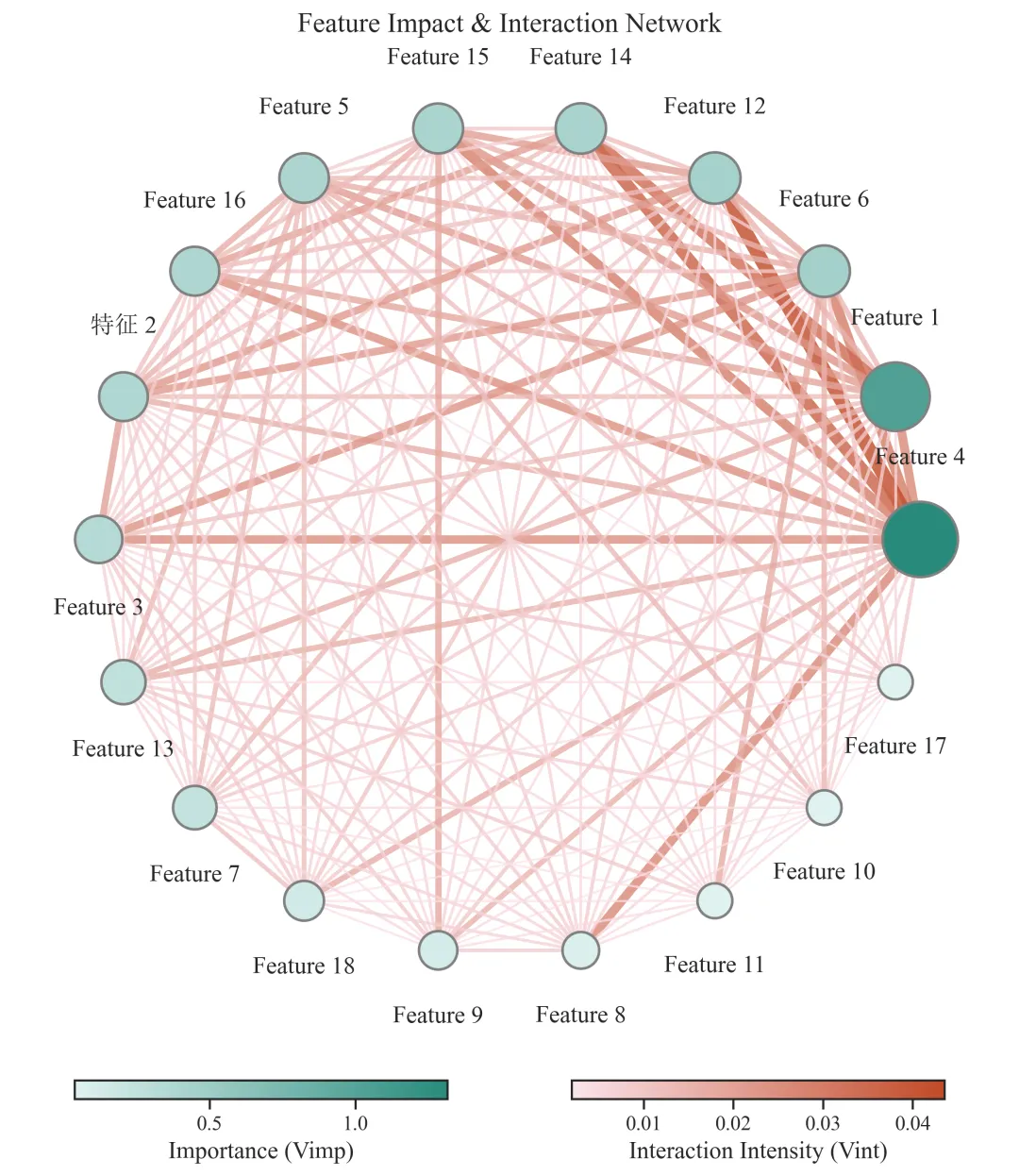
图8:SHAP特征热力图
图8为SHAP特征热力图,用于从样本层面展示不同特征对模型预测结果的贡献模式。与图2的全局SHAP特征贡献图不同,图2主要回答“哪些变量总体更重要”,而图8进一步回答“不同样本中,这些变量的贡献模式是否一致”。因此,图8更适合分析样本异质性、高预测值样本的驱动因素,以及不同特征在样本间的贡献差异。
图中的横向方向通常表示样本。每一列可以理解为一个样本,或者一个样本在SHAP排序后的显示位置。样本在图中并不一定按照原始数据顺序排列,而通常会根据模型输出值或SHAP贡献结构进行排序,因此相邻样本往往具有相似的预测贡献模式。
图中的纵向方向表示输入特征。每一行代表一个变量,例如Feature 4、Feature 1、Feature 6、Feature 12等。通常越靠上的特征,对模型输出的整体贡献越明显;越靠下的特征,贡献相对较弱。代码中图8的最大显示特征数设置为18,因此热力图重点展示模型中较重要的一组特征,而不是无限制显示所有变量。
图中的颜色表示SHAP值的方向和大小。一般来说,红色或暖色表示该变量在对应样本中对模型预测值具有正向贡献,也就是推动模型预测值升高;绿色或冷色表示该变量对模型预测值具有负向贡献,也就是降低模型预测值。颜色越深,说明该变量在该样本中的贡献越强;颜色越接近中间色,说明贡献越接近0,对该样本预测结果影响较弱。
图中的颜色块可以理解为“某一个样本中某一个变量对预测结果的贡献”。如果某一行在大多数样本中都呈现相似颜色,说明该变量对模型输出的作用方向较稳定;如果同一变量在不同样本中颜色变化明显,说明该变量的作用具有样本依赖性,可能受到其他变量背景或交互效应调节。图8主要用于判断不同样本中各变量贡献模式是否存在差异,并可用于识别样本异质性、高预测值样本驱动因素和低预测值样本限制因素。
例图解读:
图8展示了主要特征的SHAP热力图。图中横坐标表示不同样本,纵坐标表示输入特征,颜色表示各特征在对应样本中的SHAP贡献方向和贡献强度,其中橙红色表示正向贡献,绿色表示负向贡献,颜色越深代表贡献越强。图上方黑色曲线表示各样本的模型输出值 f(x),样本整体按预测输出大小规律排序;图右侧黑色条形表示各特征的整体贡献强度。结果显示,Feature 4和Feature 1具有最显著的样本层面贡献模式,且其整体贡献强度最高,是模型预测结果的主要驱动变量。具体而言,Feature 4在低预测值样本中多表现为负向贡献,而在中后段及高预测值样本中则表现出明显正向贡献;Feature 1同样具有较高重要性,但其贡献模式呈现更复杂的阶段性变化。Feature 6、Feature 12、Feature 14、Feature 15、Feature 5和Feature 16等变量表现为中等强度贡献,而Feature 18、Feature 9、Feature 8、Feature 11、Feature 10和Feature 17等变量整体贡献较弱。总体而言,图8表明模型预测结果主要由少数关键变量驱动,但不同样本中关键变量的贡献方向和贡献强度存在明显差异,提示模型预测过程具有较强的样本异质性。
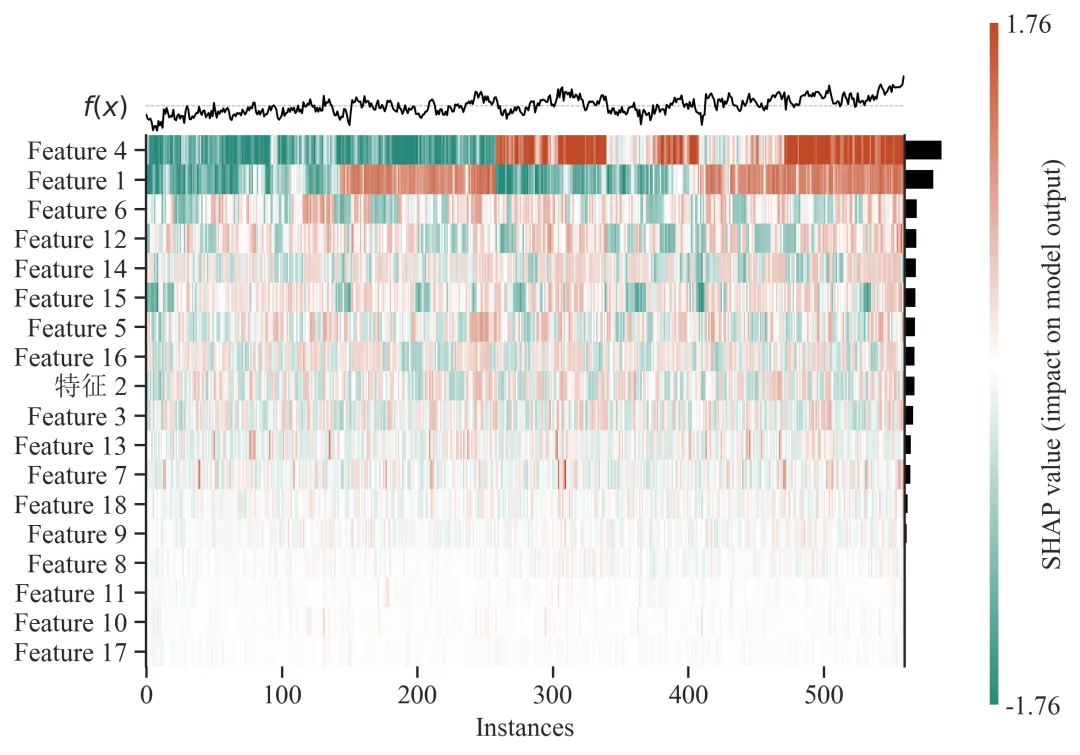
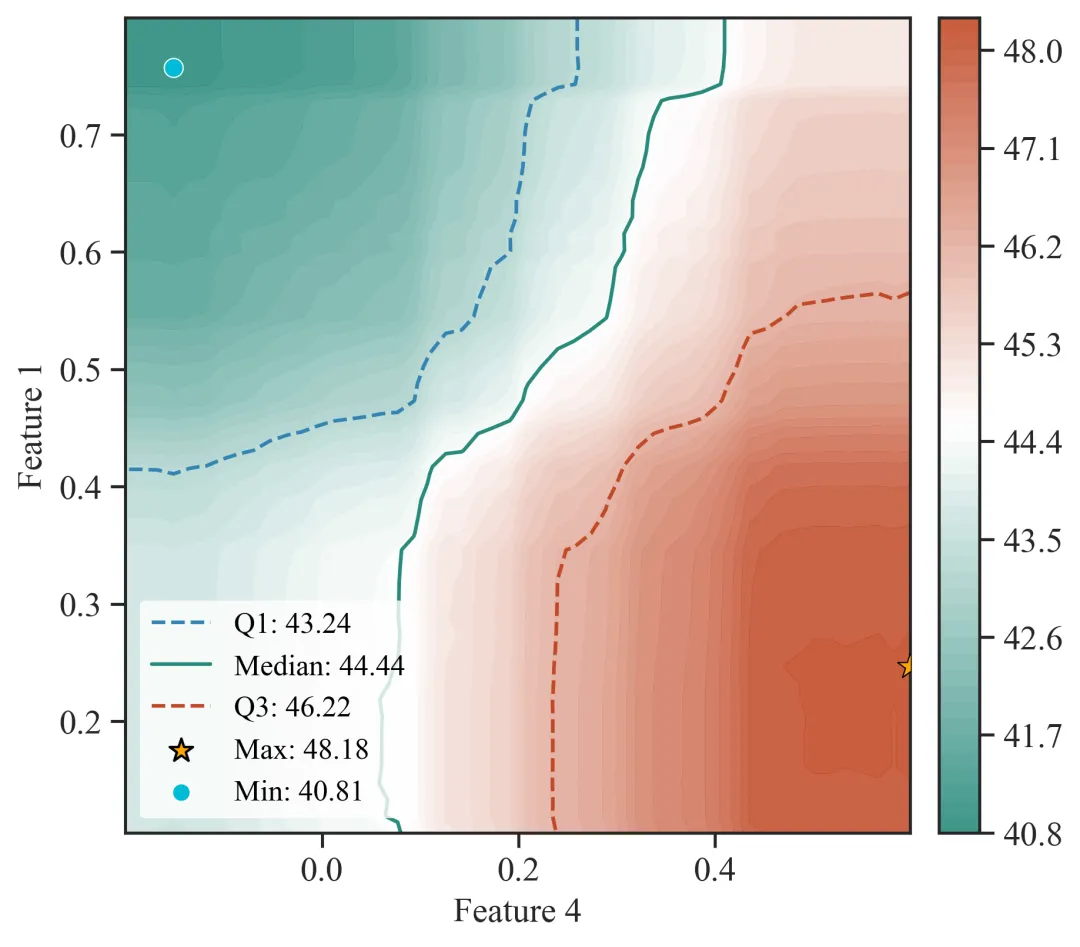
图9:个体样本SHAP力图
图9为个体样本SHAP力图,用于解释某一个具体样本的模型预测结果是如何由各输入特征共同推动形成的。与图2、图8等全局或样本群体层面的SHAP图不同,图9关注的是单个样本。它回答的问题不是“总体上哪些变量重要”,而是“对于这一个样本而言,哪些变量把预测值推高了,哪些变量把预测值拉低了”。
图中的 base value 或基准值表示模型在整体样本上的平均预测水平,也可以理解为模型在没有考虑该样本具体特征信息时的基础预测值。个体样本的最终预测值是在这个基准值的基础上,由各个特征的正向或负向SHAP贡献共同叠加得到的。
图中的 f(x) 表示该样本的最终模型预测值。它是CatBoost模型对该样本输出的预测结果。若某些特征对该样本产生正向贡献,f(x)会被推高;若某些特征产生负向贡献,f(x)会被拉低。因此,图9实际上展示的是从“模型平均水平”到“该样本最终预测值”的解释路径。
图中的正向贡献部分通常表示将预测值推高的特征。这些变量的SHAP值为正,说明在该样本中,它们使模型预测结果高于基准预测水平。贡献条越长,说明该变量对该样本预测值的正向推动越强。
图中的负向贡献部分表示将预测值拉低的特征。这些变量的SHAP值为负,说明在该样本中,它们使模型预测结果低于基准预测水平。贡献条越长,说明该变量对该样本预测值的负向拉低作用越强。
图中标注的变量名称和变量取值表示该样本在对应特征上的实际取值。例如图中可能显示 Feature 4 = 某一数值,这说明该样本的Feature 4取值为该数值,而这一取值对应的SHAP贡献决定了它是推高还是拉低预测结果。代码中在绘制图9时会提取每个样本的特征值,并将其保留三位小数后用于力图展示。
图中的箭头或色块宽度表示变量贡献大小。宽度越大,说明该变量对该样本预测结果的影响越强;宽度越小,说明其影响较弱。多个变量的贡献会共同决定最终预测值的位置。
例图解读:
图9展示了某一个体样本的SHAP力图,用于解释该样本模型预测值的形成过程。图中base value表示模型的基准预测水平,f(x)表示该样本的最终预测值。本样本的预测值为40.44,低于模型基准预测值,说明该样本整体预测水平偏低。从特征贡献方向来看,红色变量表示正向贡献,即推动模型预测值升高;绿色变量表示负向贡献,即降低模型预测值。结果显示,Feature 3和Feature 1对该样本预测值具有一定正向贡献,说明二者在该样本中起到提高模型输出的作用。然而,Feature 4、Feature 14、Feature 12、特征2、Feature 13、Feature 16、Feature 7、Feature 15和Feature 18等变量均表现为负向贡献,且其综合影响强于正向变量,因此最终使该样本预测值低于模型基准水平。其中,Feature 4在该样本中的取值为0.072,并表现出明显负向贡献。结合前述Feature 4的SHAP依赖关系可知,当Feature 4处于较低取值区间时,其对模型输出通常表现为负向作用。因此,该样本中Feature 4较低的取值是导致预测值下降的重要因素之一。此外,多个其他变量也共同拉低模型输出,说明该样本低预测值的形成具有多因素共同作用特征。
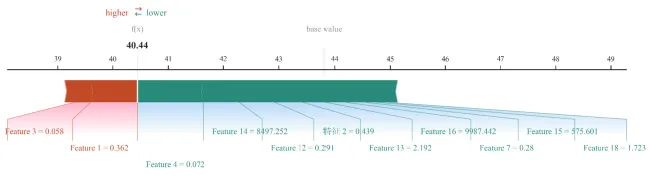
图10:二维PDP偏依赖图
图10为二维PDP偏依赖图,用于分析两个特征同时变化时,CatBoost模型预测结果的响应规律。与前面的单特征SHAP依赖图不同,单特征SHAP依赖图主要关注某一个变量对模型输出的影响,而二维PDP图进一步关注两个变量组合变化时模型预测值如何发生变化。因此,图10更适合用于分析变量之间的联合影响、最优组合区间、高值响应区和低值响应区。
图中横坐标表示第一个特征的取值,纵坐标表示第二个特征的取值。也就是说,图10将两个变量放在同一个二维平面中,通过改变这两个变量的取值,观察模型预测结果如何变化。可以把这张图理解为一张“模型预测响应面图”或者“预测结果地形图”。
图中的背景颜色表示模型预测值大小。颜色越接近高值端,说明在该变量组合条件下,模型预测结果越高;颜色越接近低值端,说明该变量组合下模型预测结果越低。也就是说,背景颜色直接反映了两个变量共同作用下目标变量的预测水平。
如果图中颜色从左下角向右上角逐渐增强,说明两个变量同时升高时模型预测值逐渐增加,提示二者可能具有协同促进关系。如果高值区域只出现在某一个局部范围,而不是随着变量增加持续升高,则说明这两个变量之间可能存在最优组合区间,并不是简单的“越高越好”。如果图中颜色变化呈现明显弯曲或分区,则说明两个变量对模型输出的影响具有非线性关系。
图中的等值线表示相同模型预测值的区域。也就是说,同一条等值线上的不同变量组合,对应的模型预测结果相近。等值线越密集,说明模型预测值在该区域变化越快;等值线越稀疏,说明模型预测值变化较平缓。如果等值线呈现明显弯曲,说明两个变量之间存在交互特征,即一个变量对预测值的影响会受到另一个变量取值水平的调节。
如果图中标注了最大值点或最小值点,那么最大值点表示在该二维变量组合范围内,模型预测值最高的位置;最小值点表示模型预测值最低的位置。最大值点可用于识别潜在的最优变量组合,最小值点则可用于识别低响应区或风险较低区。对于农业、环境、材料、医学等研究而言,这类点位具有一定的解释价值,可作为后续机制讨论、管理阈值确定或实验设计优化的参考。
如果图中标注了Q1、中位数或Q3等参考等值线,则这些线表示模型预测值在不同分位水平下的响应边界。Q1通常代表较低预测水平,中位数代表中等预测水平,Q3代表较高预测水平。通过这些分位线,可以更直观地判断哪些变量组合处于较低响应区、中等响应区或较高响应区。
例图解读:
图10展示了Feature 4与Feature 1的二维偏依赖关系,用于分析二者共同变化时CatBoost模型预测输出的响应特征。图中横坐标为Feature 4取值,纵坐标为Feature 1取值,背景颜色表示对应变量组合下的模型预测值。绿色区域表示较低预测值,橙红色区域表示较高预测值;蓝色虚线、绿色实线和红色虚线分别表示Q1、Median和Q3预测水平,黄色五角星和蓝色圆点分别表示预测最大值和最小值位置。由图可见,模型预测值随Feature 4升高而整体增加,表现出明显的正向响应趋势。低Feature 4区域主要对应低预测值,而高Feature 4区域则主要对应高预测值,说明Feature 4是影响模型输出的重要正向变量。Feature 1则表现出一定调节作用:当Feature 1较高且Feature 4较低时,模型预测值最低,最小值为40.81;而最大预测值48.18出现在Feature 4较高、Feature 1处于较低至中等水平的区域。等值线形态进一步表明,Feature 4与Feature 1之间存在一定非线性耦合关系。随着Feature 1升高,达到相同预测水平所需的Feature 4取值整体增加,提示较高Feature 1可能削弱Feature 4对模型输出的提升效应。因此,Feature 4与Feature 1对模型预测结果并非简单相加,而是存在明显的组合依赖关系。总体而言,图10说明Feature 4是提高模型预测值的主要驱动因素,而Feature 1对Feature 4的作用具有调节效应。高Feature 4与低至中等Feature 1的组合对应较高预测输出,而低Feature 4与高Feature 1的组合对应较低预测输出。该结果为解释二者之间的交互关系、识别高响应变量组合以及进一步开展机制讨论提供了依据。
四、代码使用说明
1.功能概述
本代码基于 CatBoost回归模型 和 SHAP可解释性分析方法 构建,主要完成以下功能:
首先,系统会读取用户准备好的 Excel 数据表,将第一列自动识别为目标变量,将其余列识别为输入特征。随后,系统对数据进行基础预处理,包括缺失值填补、零方差变量剔除等操作,并将数据划分为训练集和测试集。
在建模阶段,系统会调用 CatBoost 回归模型进行训练,并通过随机搜索和交叉验证自动优化模型参数。模型训练完成后,系统会输出预测性能评估图,用于展示训练集和测试集的预测准确性、误差水平和残差分布。
在解释分析阶段,系统会计算 SHAP值和SHAP交互值,用于解释不同变量对模型输出的贡献。最终,系统会自动生成一整套专业图表,包括模型预测效果图、全局SHAP特征贡献图、单特征SHAP依赖图、主效应与交互效应对比图、SHAP交互复合矩阵图、两两特征交互散点图、特征重要性与交互网络图、SHAP特征热力图、个体样本SHAP力图以及二维PDP偏依赖图。
2.运行前准备
在使用本代码前,用户需要准备两个部分:运行环境和输入数据。运行环境方面,建议用户使用 Python 环境运行本代码。代码依赖多个常用数据分析和机器学习库,包括 numpy、pandas、matplotlib、seaborn、shap、catboost、networkx、scikit-learn、statsmodels 和 openpyxl 等。
该 Excel 表格需要满足以下基本格式:第一列为目标变量,也就是需要预测和解释的结果变量;第二列及之后的所有列为输入特征,也就是用于解释目标变量变化的影响因素。例如,第一列可以是产量、浓度、强度、风险评分、生态指数、经济指标等连续型变量;后面的列可以是温度、降水、pH、临床指标、材料参数、环境因子、管理措施等解释变量。
需要注意的是,本代码使用的是回归模型,因此目标变量应为连续型数值变量。如果用户的数据是分类任务,例如“是/否”“高风险/低风险”“患病/未患病”,则需要将模型部分改为分类模型后再使用。
3.Python 和Python 编辑器安装(已安装过的可跳过)
Python 是本产品代码运行所需的基础环境,负责解释和执行Python脚本;Python编辑器是用于编写、查看和运行代码的软件工具,例如PyCharm、Visual Studio Code、Jupyter Notebook、Spyder、IDLE。用户需先安装 Python,再根据使用习惯选择合适的编辑器。编辑器本身不能替代 Python 运行环境,只有在正确配置 Python 解释器后,才能正常运行本产品代码。
Python安装
建议优先从 Python 官方网站下载安装包。Python 官网会根据不同系统提供对应版本,建议大家安装Python3.11~Python3.13版本,这个区间的版本比较稳定,报错少。官网支持 Windows、macOS、Linux/Unix 等系统下载。安装教程可自行查找网络资源。
Python官网下载地址:https://www.python.org/downloads/?utm_source=chatgpt.com
Python 编辑器安装
本代码运行推荐安装 Visual Studio Code 或 PyCharm。如果你主要做数据分析、画图、调试模型,也可以安装 Jupyter Notebook / JupyterLab。安装教程可自行对应查找相关教程
4.数据准备流程
在正式运行代码前,应先检查数据表是否符合要求。
第一步,确认 Excel 文件名称是否与代码配置一致。默认情况下,代码读取的是“示范数据.xlsx”。如果用户的数据文件名称不同,可以选择将数据文件重命名为“示范数据.xlsx”,也可以在代码配置参数中修改 data_file 对应的文件名。
第二步,确认第一列是否为目标变量。代码会默认将第一列作为因变量 y,因此用户需要确保第一列确实是研究中需要预测的结果变量。
第三步,确认第二列及之后的变量是否为输入特征。代码会自动将这些列作为自变量 X 进入模型训练和SHAP解释分析。
第四步,检查数据中是否存在非数值型变量。如果数据中包含文字型类别变量,例如“城市类型”“土地类型”“处理组别”等,建议用户提前将其转换为数值编码或哑变量,以保证模型能够正确识别。
第五步,检查数据缺失情况。代码会自动使用中位数填补缺失值,因此少量缺失值不会影响运行。但如果某一列缺失过多,建议用户在运行前进行数据质量检查,以免影响模型结果可靠性。
5.安装Python模型库
Python 本身只是一个基础运行环境,它能运行代码,但很多复杂功能并不是 Python 自带的。比如机器学习模型、SHAP解释分析、Excel读取、图表绘制、网络图绘制等功能,都需要依赖额外的第三方库。所以,Python模型库就相当于给 Python 增加“专业工具箱”。
本代码使用前需要安装相应的Python模型库。
运行前打开您的终端(Terminal)或命令提示符(CMD),直接复制并运行以下命令下载模型库:
pip install numpy pandas matplotlib seaborn shap catboost networkx scikit-learn statsmodels openpyxl
如果您使用的是国内网络环境,建议加上清华镜像源以加快下载速度:
pip install numpy pandas matplotlib seaborn shap catboost networkx scikit-learn statsmodels openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple
6.代码运行
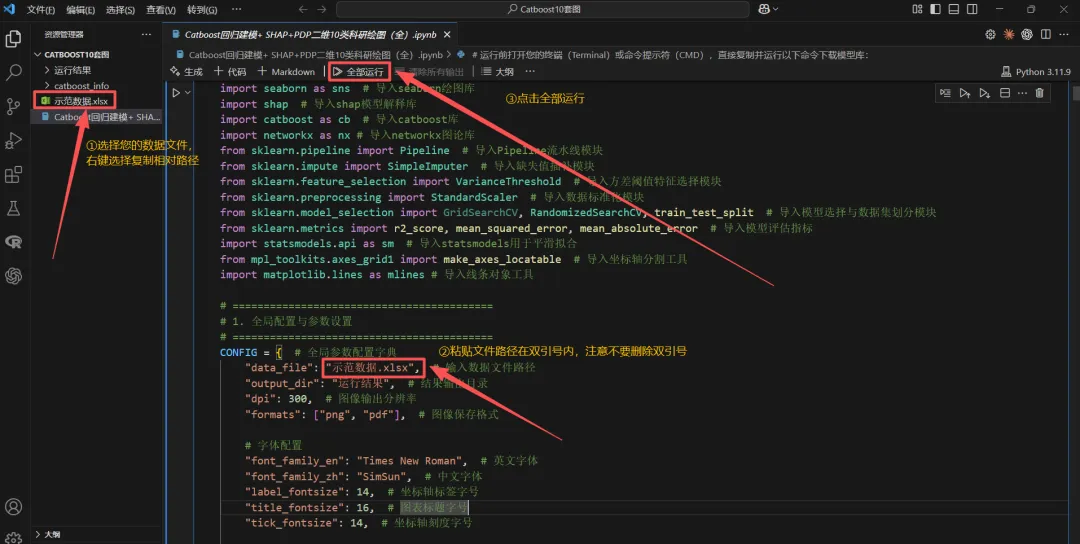
第一步:用 Visual Studio Code 或 PyCharm 或者其他Python编辑器运行。首先将下载的代码文件、数据文件放在同一个文件夹目录下。代码包含.ipynb和.py格式的两个文件。需要根据用户自己的Python编辑器选择合适的格式。PyCharm编辑器使用.py格式。VS Code 使用.ipynb格式。
第五步:不同编辑器操作不一样,建议查看入门教程后再使用。我这里以 Visual Studio Code 编辑器为例,
配置好Visual Studio Code 编辑器后,打开软件,选择文件——打开文件夹——选择您保存代码和Excel数据的文件。打开代码文件后,在软件右侧可以看到文件夹内容的Excel文件,替换您自己的Excel数据,点击运行。然后就是等待代码运行。操作如下:
注意:样本量很多,电脑性能不足的情况下,运行时间比较久,可能半天或者一天。
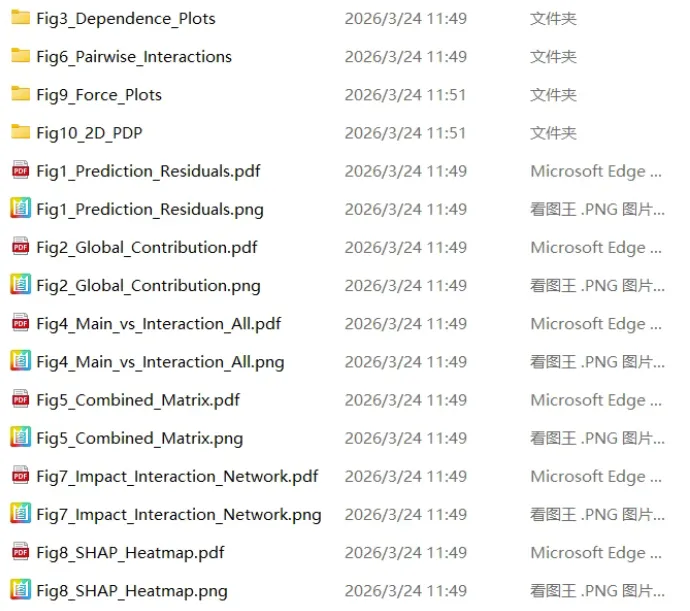
输出文件包含的内容:
★可以自定义修改的内容:
1.字体修改位置:

2.风格修改:

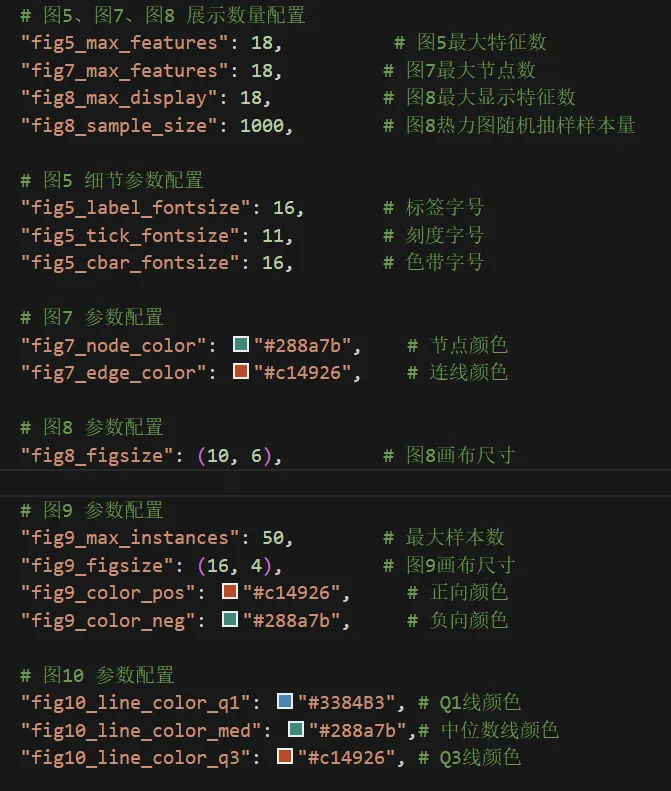

3.交叉验证修改的地方
4.如果您的数据 R²、RMSE 和 MAE 等指标比较差的话可以根据运行结果对catboost模型进行调参。
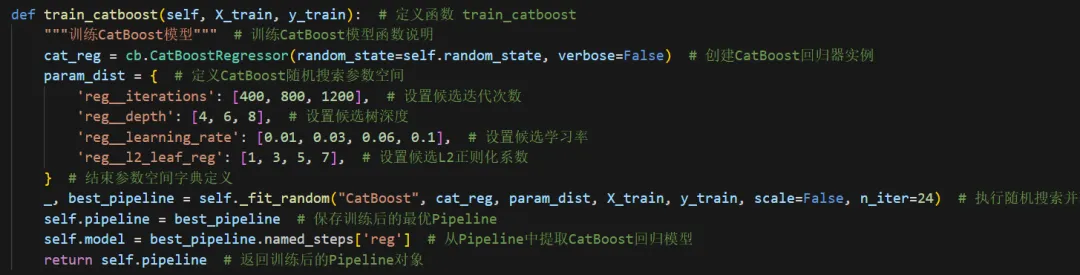
5.在这个代码里,训练集 / 测试集划分是在 prepare_data() 函数里面完成的,小伙伴可以根据自己的需求调整。

test_size=0.3 表示 30% 的数据作为测试集,剩下 70% 的数据作为训练集。
如果你想改成 80%训练集、20%测试集,就把这里改成:test_size=0.2
如果想改成 75%训练集、25%测试集,就改成:test_size=0.25
五、常见报错问题
1.报错:ModuleNotFoundError: No module named 'xxx'
常见形式包括:
ModuleNotFoundError: No module named 'pandas'
ModuleNotFoundError: No module named 'shap'
ModuleNotFoundError: No module named 'catboost'
ModuleNotFoundError: No module named 'openpyxl'
解决方案:这是最常见的环境问题,表示当前 Python 环境中缺少对应模型库。该代码开头导入了多个第三方库,包括 pandas、matplotlib、shap、catboost、networkx、scikit-learn、statsmodels 和 openpyxl 等,因此运行前必须先安装这些库。
解决方法是在终端或命令提示符中运行:
pip install numpy pandas matplotlib seaborn shap catboost networkx scikit-learn statsmodels openpyxl
2. 报错:FileNotFoundError: [Errno 2] No such file or directory: '示范数据.xlsx'
这个错误表示代码没有找到输入数据文件。代码默认读取的文件名是:"data_file": "示范数据.xlsx"。
因此,程序运行时会在当前代码所在目录下寻找 示范数据.xlsx。如果文件名不一致、文件不在同一个文件夹,或者后缀不是 .xlsx,就会报错。
解决方法有两种:第一种方法是把你的数据文件重命名为:示范数据.xlsx。并且放到 Python 代码文件同一个文件夹中。
第二种方法是修改代码配置区中的文件名,例如:"data_file": "你的数据文件名.xlsx"。如果数据文件在其他文件夹,需要写完整路径,例如:"data_file": r"D:\项目数据\示范数据.xlsx"
3.报错:ImportError: Missing optional dependency 'openpyxl'
这个错误通常出现在读取 Excel 文件时,代码使用:pd.read_excel(CONFIG["data_file"]),读取 .xlsx 文件,而 pandas 读取 Excel 通常需要 openpyxl 支持。
解决方法是安装 openpyxl,输入代码:pip install openpyxl进行安装。安装后重新运行代码即可。
4.报错:ValueError: Cannot use median strategy with non-numeric data
这个错误通常说明输入特征中存在文字型变量,例如“高/中/低”“A组/B组”“男/女”“城市/农村”等。代码中的预处理步骤使用了:SimpleImputer(strategy="median")。也就是用中位数填补缺失值。中位数只能用于数值型数据,如果某一列是文字,就会报错。
解决方法是在运行前把文字变量转换为数值变量。例如:
男 / 女 → 0 / 1
A组 / B组 / C组 → 0 / 1 / 2
土地类型 → 转换为哑变量
如果不想改代码,最简单的做法是:确保 Excel 表格中从第二列开始的所有自变量都是数值型。
5. 报错:ValueError: Input y contains NaN
这个错误表示目标变量,也就是 Excel 第一列中存在空值。代码使用self.y = df.iloc[:, 0]
self.X = df.iloc[:, 1:]
也就是说,第一列是因变量,第二列及以后是自变量。代码会对自变量做缺失值填补,但不会自动填补因变量 y 的缺失值。
解决方法:是打开 Excel,检查第一列是否存在空白单元格。如果有,需要删除这些样本行,或者根据研究设计合理填补目标变量。建议优先删除目标变量缺失的样本,因为目标变量是模型学习的“答案”,缺失后模型无法训练。
6. 报错:ValueError: With n_samples=..., test_size=0.3...
这个错误一般和样本量过少有关。代码中使用:train_test_split(self.X, self.y, test_size=0.3, random_state=self.random_state)。表示 30% 数据作为测试集,70% 数据作为训练集。
如果样本量太少,划分后训练集或测试集样本不足,就可能报错,或者后续模型训练、交叉验证出错。
解决方法是增加样本量。若只是测试代码流程,可以临时减少测试集比例,例如把:test_size=0.3改为test_size=0.2。如果你希望代码保持不变,则建议至少准备较充足样本,避免训练集过小。
7. 报错:Cannot have number of splits n_splits=5 greater than the number of samples
这个错误与 5 折交叉验证有关。代码中设置了:self.cv = 5,并在随机搜索中使用:RandomizedSearchCV(..., cv=self.cv)。这表示训练集会被分成5份进行交叉验证。如果训练集样本数少于5,或者某些情况下有效样本不足,就会报错。
解决方法是增加样本量。如果只是测试流程,也可以把:self.cv = 5改成self.cv = 3。但用于正式分析时,建议优先增加样本,而不是简单降低交叉验证折数。
8. 报错:ValueError: Shape of passed values is ..., indices imply ...
这个错误可能出现在 SHAP 计算阶段,尤其是在代码执行到:self.X_train_processed = pd.DataFrame(X_train_transformed, columns=self.feature_names)附近。代码预处理步骤中包含:VarianceThreshold(threshold=0.0)。它会删除零方差变量,也就是所有样本取值都一样的变量。问题在于:如果有变量被删除,预处理后的数据列数会减少,但代码仍然使用原始 feature_names 作为列名,就可能导致“数据列数”和“列名数量”不一致。
解决方法是在运行前检查 Excel 数据,删除所有没有变化的列。例如某一列所有样本都是同一个值,就应提前删除。
9. 报错:ValueError: Input X contains infinity or a value too large
这个错误说明数据中可能存在无穷值、异常大值或非法数值。常见原因包括:Excel 中存在 inf、-inf、
某些公式计算结果异常、某些列单位错误导致数值极大、数据中混入特殊符号。
解决方法是在 Excel 中检查数据,尤其是特别大、特别小或显示异常的单元格。建议将异常值处理为合理范围内的数值,或删除明显错误样本。
10. 报错:CatBoostError 或模型训练失败
如果出现 CatBoostError,通常与输入数据格式、目标变量格式或特征中存在异常值有关。常见原因包括:目标变量不是数值型、自变量中存在无法识别的字符串、数据中存在异常空值、样本量太少、特征数量过多而样本太少。
解决方法是先检查 Excel 表格:第一列必须是连续型数值变量;第二列及以后最好全部是数值型特征;不要包含中文文本、单位符号、百分号、空格或特殊字符。
11. 报错或警告:字体缺失、中文显示为方框
代码中默认字体设置为:"font_family_en": "Times New Roman"、"font_family_zh": "SimSun"。并且会检查系统字体是否存在。如果系统缺失字体,代码会输出警告。
常见表现是:警告:系统缺失中文字体 'SimSun',中文可能无法正常显示。或者图片中文字显示为方框。
解决方法是把代码中的中文字体改为当前系统已有字体。
Windows 通常可以用:"font_family_zh": "SimSun"
macOS 可以尝试:"font_family_zh": "Songti SC"
Linux 可以安装中文字体,或者改成系统中已有的中文字体。
如果只是运行分析,不影响模型计算;但如果用于论文出图,建议处理字体问题。
12. 报错:PermissionError: [Errno 13] Permission denied
这个错误通常出现在保存图片或读取文件时。
常见原因有三种。
第一,输出文件夹或图片文件正在被其他软件占用。例如 PDF 正在被浏览器或 Adobe 打开。
第二,代码所在文件夹没有写入权限。例如放在系统目录、只读目录或云同步目录中。
第三,Excel 文件正在被占用,或者没有读取权限。
解决方法是关闭已打开的图片、PDF 或 Excel 文件;把代码和数据移动到普通文件夹,例如桌面项目文件夹;重新运行代码。
13. 报错:运行到 SHAP 交互值计算时非常慢或卡住
代码中会计算:self.shap_interaction_values = self.explainer.shap_interaction_values(self.X_train_processed)
SHAP交互值计算比普通SHAP值更耗时,尤其当样本量多、特征数量多时,运行时间会显著增加。代码也在提示中说明“交互作用计算较耗时”。然后长时间没有输出。
解决方法是耐心等待,尤其是第一次运行。如果样本和变量很多,建议先用较小数据集测试流程。
如果允许优化代码,可以减少样本量、减少特征数,或者只对重要变量计算交互。
14.报错:内存不足,程序突然退出
如果样本量较大、特征数量较多,图5交互矩阵、图6两两交互散点图、图9个体力图、图10二维PDP会生成大量图像,可能造成运行时间长、内存占用高。代码中图5、图7、图8最多展示18个特征,图9最多绘制50个样本,但图6会遍历所有两两特征组合,特征数较多时图片数量会迅速增加。完整流程由 run_all() 依次调用图1到图10的绘图函数。
解决方法是减少输入特征数量,优先保留科研上重要的变量。如果只是测试代码是否正常运行,可以先使用较少列的数据。
如果允许改代码,可以降低:
"fig5_max_features": 18
"fig7_max_features": 18
"fig8_max_display": 18
"fig9_max_instances": 50
例如改成 10 或 20 以下,降低计算和绘图压力。
15.报错:ValueError: zero-size array to reduction operation maximum which has no identity
这个错误通常说明用于绘图或计算的数据为空。可能原因包括:Excel 表格为空、自变量列全部被删除、训练集为空、特征数量不足、方差筛选后没有可用特征。
解决方法是检查数据表是否至少包含:1列目标变量、至少1列有效自变量、足够样本行。同时检查是否有某些变量全为空、全为同一个值,或全部为无法识别的字符。
16.报错:ValueError: x and y must have same first dimension
这个错误一般出现在绘图阶段,说明横坐标和纵坐标长度不一致。
在本代码中,常见原因仍然是数据预处理后列数或样本数发生变化,但后续绘图仍使用原始变量名或原始索引。
解决方法是检查是否存在零方差列、异常列、空列或混合类型列。建议在运行前删除全空列、常数列和非数值列。
17.警告:R^2 score is not well-defined with less than two samples
这个不是严格报错,但说明测试集或训练集样本太少,导致 R² 无法可靠计算。
解决方法是增加样本量,避免测试集样本过少。如果总样本量本身很少,不建议使用复杂机器学习模型进行正式结论分析。
18.报错:IndexError 或某些图没有生成
如果图2、图3、图5、图6、图7、图8、图9、图10中某些图没有生成,常见原因包括:特征数量太少、某些特征被预处理删除、某些图需要至少两个特征、SHAP交互值计算失败、保存路径异常
例如,图10是二维PDP图,需要至少两个有效特征;图6是两两特征交互图,也需要至少两个特征。
解决方法是检查输入数据是否至少包含两个有效自变量,并确认所有自变量均为数值型。
出现其他运行问题可添加微信详细咨询:zhouysh001(八宝粥加油)
完整代码获取:回复“ Catboost回归 ”即可获得通道
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
