写在前面的话
考验人性。昨天刷了一个视频,在东北某个小城,下着大雨,一位老师喝了酒。深夜开车回家,家很近,就没叫代驾,结果撞上了宝马车。后保险杠干稀碎,老师一下子惊醒,下了车跪下磕头,说千万别报警,要不然他的职教生涯全完了,我家里就我一个人挣钱,你说赔多少都行。宝马司机想着自己孩子也在上学,对老师应该客气一点。就看了下情况说,车撞成这样,赔5万块钱吧,我自己修。老师当场转了两万,后面写了欠条,说明天还清。第二天,宝马司机联系要钱,老师反水,说:不给,你这是敲诈,一个二手宝马能多钱,5000撑死了,再这样,我报警了。宝马司机很气愤,这变脸太快了,自己找三方做了鉴定,修车需要七万四,去报警,因为昨天下着大雨,再加上老师酒劲过了,让交警有点为难,后面的讨债就困难了。所以,别考验人性,遇到的不一定是啥人呢。
[233+100]--------底部有张生活照 (头条号运营:大家想全托管上号的联系我哦,每天让你得个早餐钱,wx: qhz198607)
(头条号运营:大家想全托管上号的联系我哦,每天让你得个早餐钱,wx: qhz198607)
【关键词】python、ragflow、同步数据、指定同步
一、同步索引数据(三级)
描述:现在新索引创建完毕,需要把旧索引中的数据同步过去,现在需要监控同步时间及同步过程中不出错。
开工:
第一步:查看同步日志(四级)
20250405周六时间段:16:10-17:00
看下怎么查看同步日志,这个要问下deepseek,并试试能不能看到。
同步数据冲突了,需要处理一下。
第二步:处理冲突(四级)
20250405周六时间段:19:52-20:00
a.终止当前任务(五级)
20250405周六时间段:19:54-20:00
命令如下:
POST _tasks/huw827OYQ1OHqgPbdCI9jw:67384/_cancel
注:完成了。
b.清理目标索引中的冲突文档(五级)
20250405周六时间段:19:55-20:00
# 查找冲突文档 ID(示例)
POST ragflow_7d19a176807611efb0f80242ac120006_new2/_search
{
"query": { "term": { "_index": "ragflow_7d19a176807611efb0f80242ac120006" } }
}
# 批量删除冲突文档
POST _delete_by_query
{
"index": "ragflow_7d19a176807611efb0f80242ac120006_new2",
"query": { "term": { "_index": "ragflow_7d19a176807611efb0f80242ac120006" } }
}
注:运行结果如下:
图2a-1
注:查下原因,原因如下:
你的 _delete_by_query 请求返回 "total": 0 和 "deleted": 0,说明 没有匹配到任何文档,但 took 值(执行时间)仍然变化。以下是原因和解决方案:
但 _index 是 Elasticsearch 的元数据字段,存储的是 当前文档所在的索引名(即 ragflow_7d19a176807611efb0f80242ac120006_new2),而非源索引名,因此无法匹配。
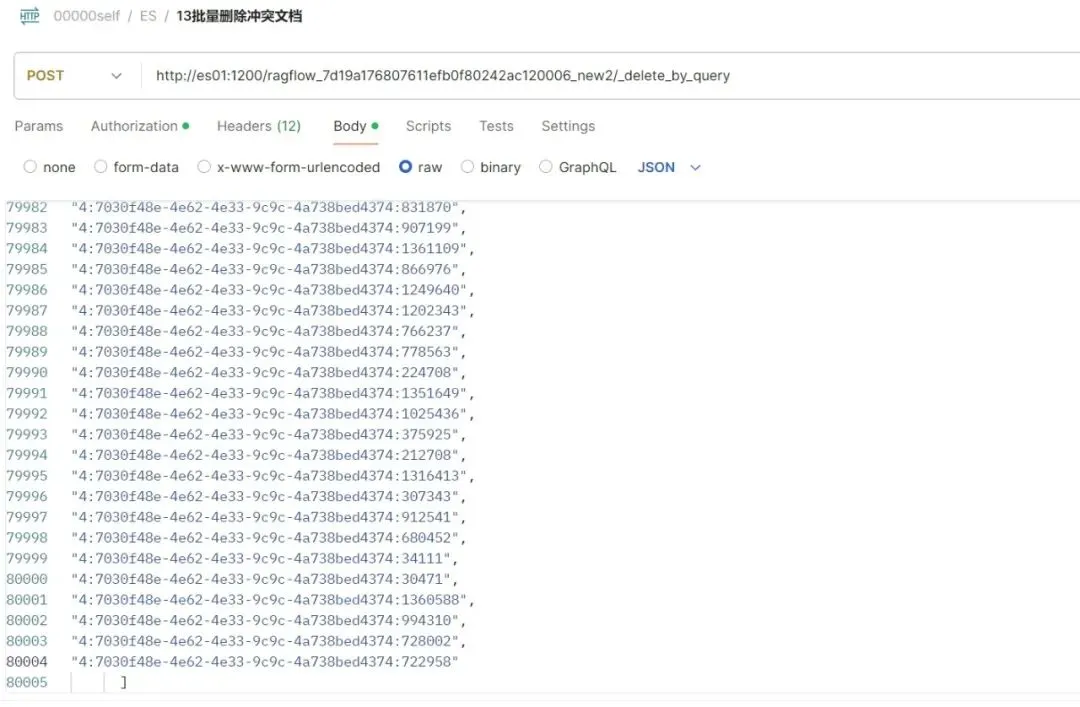
注:解决办法直接用id查,试了下是好使的,接下来,把id找出来,一共80万个。
第三步:找到id(四级)
20250405周六时间段:21:54-22:00
用如下的方法,需要两个小时标记完,方法如下:
(1) 在 reindex 时标记来源
POST _reindex
{
"source": { "index": "ragflow_7d19a176807611efb0f80242ac120006" },
"dest": { "index": "ragflow_7d19a176807611efb0f80242ac120006_new2" },
"script": {
"source": "ctx._source._sync_source = 'ragflow_7d19a176807611efb0f80242ac120006'"
}
}
注:一小时标记30万,需要两个小时40分钟。
(2) 按标记字段删除
POST /ragflow_7d19a176807611efb0f80242ac120006_new2/_delete_by_query
{
"query": {
"term": {
"_sync_source": "ragflow_7d19a176807611efb0f80242ac120006"
}
}
}
注:下面采用一种新的方法,就是从日志中找出80万个id.
第四步:新法找id(四级)
20250405周六时间段:21:58-22:00
代码如下:
import re
# 原始数据(假设是包含多个条目的列表)
error_data = [
{
"index": "ragflow_7d19a176807611efb0f80242ac120006_new2",
"id": "4:7030f48e-4e62-4e33-9c9c-4a738bed4374:1316413",
"cause": {
"type": "version_conflict_engine_exception",
"reason": "[4:7030f48e-4e62-4e33-9c9c-4a738bed4374:1316413]: version conflict, document already exists (current version )",
"index_uuid": "BiwvU9_sSzGvdYIe_oW44w",
"shard": "7",
"index": "ragflow_7d19a176807611efb0f80242ac120006_new2"
},
"status": 409
},
{
"index": "ragflow_7d19a176807611efb0f80242ac120006_new2",
"id": "4:7030f48e-4e62-4e33-9c9c-4a738bed4374:307343",
"cause": {
"type": "version_conflict_engine_exception",
"reason": "[4:7030f48e-4e62-4e33-9c9c-4a738bed4374:307343]: version conflict, document already exists (current version )",
"index_uuid": "BiwvU9_sSzGvdYIe_oW44w",
"shard": "22",
"index": "ragflow_7d19a176807611efb0f80242ac120006_new2"
},
"status": 409
}
]
# 通过正则表达式提取 reason 中的文档 ID
pattern = r'^$(.*?)$:' # 匹配方括号内的内容
conflict_ids = []
for entry in error_data:
if "cause" in entry and "reason" in entry["cause"]:
reason = entry["cause"]["reason"]
match = re.match(pattern, reason)
if match:
extracted_id = match.group(1)
# 可选:验证提取的 ID 是否与条目中的 id 字段一致
if extracted_id != entry["id"]:
print(f"警告: ID 不一致 - 条目ID: {entry['id']}, 提取ID: {extracted_id}")
conflict_ids.append(extracted_id)
# 输出结果
print("冲突的文档ID列表:")
for cid in conflict_ids:
print(f" - {cid}")
# 匹配特定 ID(例如 "4:7030f48e-...:307343")
target_id = "4:7030f48e-4e62-4e33-9c9c-4a738bed4374:307343"
if target_id in conflict_ids:
print(f"\n目标 ID {target_id} 存在冲突")
else:
print(f"\n目标 ID {target_id} 未找到冲突")
注:
代码说明:
•正则表达式提取•
使用 ^$(.*?)$: 匹配 reason 字段开头方括号内的内容,确保精准定位 ID。
•数据校验•
检查提取的 ID 是否与条目中的 id 字段一致,避免数据异常。
•结果输出•
输出所有冲突 ID,并支持单独检查目标 ID 是否存在。
注:接下来,运行下这个脚本,效果如下:
图2a-2
注:80万个id找到了,接下来,是从索引中删除这80万条数据。
删除效果如下:
图2a-3
注:发现一个小问题,就是删除一直在跑为什么不见数据减少,难道是之前的打标记没打完,进程锁定es了不让删除。
第五步:es打标记会不会锁住索引(四级)
20250405周六时间段:23:21-00:00
提问如下:
postman请求es打标记接口,采用post传输,接口如下:
http://es01:1200/_reindex
参数如下:
{
"source": {
"index": "ragflow_7d19a176807611efb0f80242ac120006"
},
"dest": {
"index": "ragflow_7d19a176807611efb0f80242ac120006_new2"
},
"script": {
"source": "ctx._source._sync_source = 'ragflow_7d19a176807611efb0f80242ac120006'"
}
}
注:这个打标记接口在执行过程中会不会锁住索引,不让其它删除索引数据的接口执行?
注:问下deepseek,问了发现不会锁。接下来,查下一共多少文档,对比下文档数量。还差哪些没同步过来,指定同步一下。
第六步:指定同步(四级)
20250406周日时间段:01:13-02:00
想办法,看看能不能做指定同步。接下来,写个程序,指定id进行同步,同步时,先检查一下,有没有这个id,没有的话,再进行同步,做之前,先搞一下,差多少id。
写个python程序,看下差多少id。先看下项目中有没有ES连接相关的接口,查找 如下:
def get_all_ids(index_name):
"""获取指定索引的所有文档ID"""
try:
query = {"query": {"match_all": {}}, "_source": False}
response = scan(es,
index=index_name,
query=query,
size=1000, # 每次scroll获取的数量
scroll='5m')
return {hit['_id'] for hit in response}
except Exception as e:
log.error(f"获取索引 {index_name} ID失败: {str(e)}")
raise
@manager.route('/sync_diff_ids', methods=['POST'])
def sync_diff_ids(source_index, target_index, diff_ids):
"""同步差异文档到目标索引"""
try:
actions = []
for doc_id in diff_ids:
# 获取原始文档内容
doc = es.get(index=source_index, id=doc_id)['_source']
# 构造bulk操作
actions.append({
"_op_type": "index",
"_index": target_index,
"_id": doc_id,
"_source": doc
})
# 批量处理(每500条执行一次)
if len(actions) >= 500:
bulk(es, actions)
actions = []
log.info(f"已批量同步500条文档")
# 处理剩余数据
if actions:
bulk(es, actions)
log.info(f"同步剩余 {len(actions)} 条文档")
except Exception as e:
log.error(f"同步文档失败: {str(e)}")
raise
def diff_ids_sync():
"""主函数"""
# 设置索引名称
# 定义索引名称
old_index = "ragflow_7d19a176807611efb0f80242ac120006"
new_index = "ragflow_7d19a176807611efb0f80242ac120006_new2"
try:
# 1. 获取两个索引的ID集合
log.info("开始获取旧索引ID...")
old_ids = get_all_ids(old_index)
log.info(f"旧索引共 {len(old_ids)} 条文档")
log.info("开始获取新索引ID...")
new_ids = get_all_ids(new_index)
log.info(f"新索引共 {len(new_ids)} 条文档")
# 2. 计算差异ID(存在旧索引但不在新索引中的ID)
diff_ids = old_ids - new_ids
log.info(f"发现差异文档数量: {len(diff_ids)}")
if not diff_ids:
log.info("没有需要同步的差异文档")
exit(0)
# 3. 同步差异文档
log.info("开始同步差异文档...")
sync_diff_ids(old_index, new_index, diff_ids)
log.info("同步完成!")
except Exception as e:
log.error(f"同步流程异常终止: {str(e)}")
注:接下来,对程序进行测试。
二、头条号战果汇报
昨日数据来啦,累计总收入:4984.54,昨日总收入:106.32,昨日总播放:244.5万,可提现总金额:1742.59。软件截图如下:
图2b-1
注:想要全脱管运营头条号的联系我,你出账号,我来运营,收益四六分成(你六我四),你当甩手掌柜,每天都能得几块零花钱,财富wx: 17701328814,也可以加群先了解一下。
图2b-2
三、生活照片
拍摄于2026年1月3日,14:23:42,老妈过生日拍的,当时老爸也在。老师酒驾撞车这个事怎么说呢,这个新闻之所以爆出,那是因为99%的老师都是好老师,极个别的老师像这样,才成为热点。如果这个老师积极赔付,估计就不会有这个新闻了,这个新闻爆出,为后续其他人酒驾撞车起了坏的示范作用,就拿我来说,如果别人撞了我,酒驾,我肯定就报警了,因为我看了这个视频,怕别人像这位老师一样事后反水。
图2b-1
《本文完》




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
