写在前面的话
无敌马哥。写公众号四年,写出来的一些人和事,遭到当事方质问,删了不少文章。后来就张冠李戴,男的写成女的,亲戚写成路人,有时回看,我自己都分不清我写的是谁。但今天我写的马哥,是真人真姓,最近,和马哥合作一个小程序,马哥起初给我的感觉是人实在,三句话没谈,直接把订金转过来,最近我比较忙,马哥通宵研究前后端代码,研究好后发给我,让我参考,把我感动的不行。自助者天助,我1小时解决的事,马哥需要通宵研究代码,让我除了行动无话可说。最扎心的是:马哥是功成名就之人,他一年啥也不干,都有几十个w进账,人家还这么拼,我没理由说难。成功之人从来不找理由,遇到困难就死磕,想尽办法解决。所以,当我感觉某件事难,想放弃时,我肯定会想到马哥的努力,他绝对会像灯塔一样,照亮我前行的路,加油,追梦人!
[232+100]-------底部有张生活照 (头条号运营:大家想全托管上号的联系我哦,每天让你得个早餐钱,wx: qhz198607)
(头条号运营:大家想全托管上号的联系我哦,每天让你得个早餐钱,wx: qhz198607)
关键词:python、ragflow、es、同步索引数据
一、分批同步es索引数据(三级)
描述:现在新索引创建完毕,需要把旧索引中的数据同步过去,现在采用脚本的形式,写完接口,加定时任务来执行。
开工:
第一步:写接口(四级)
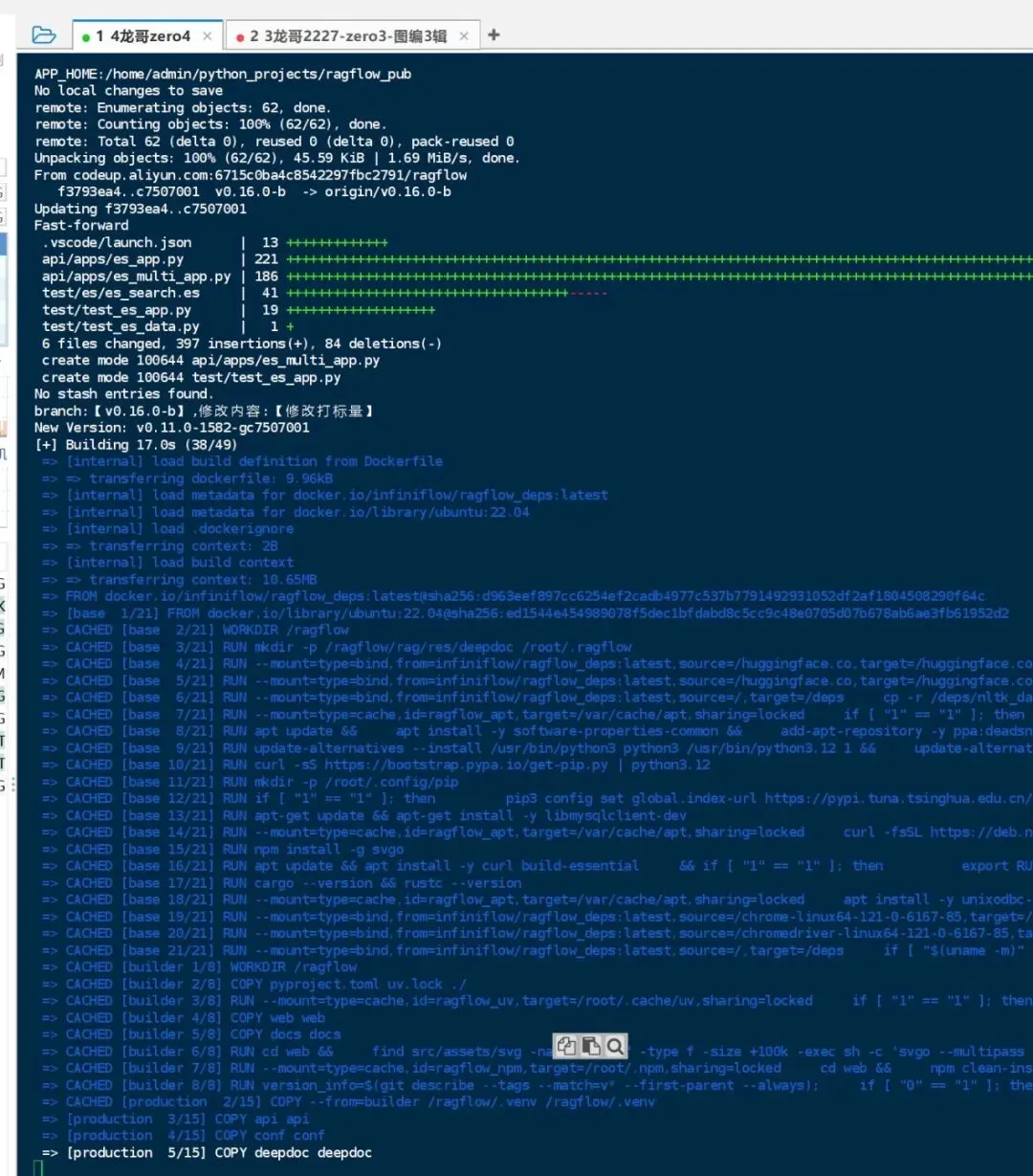
20250406周日时间段:02:10-03:00
接口写完了,现在执行一下,把错误处理一下。
先把服务器跑起来,现在程序能运行了,如下:
图3a-1
注:接下来,研究下怎么获取一个索引中文档的数量。
第二步:文档数量(四级)
20250406周日时间段:04:27-05:00
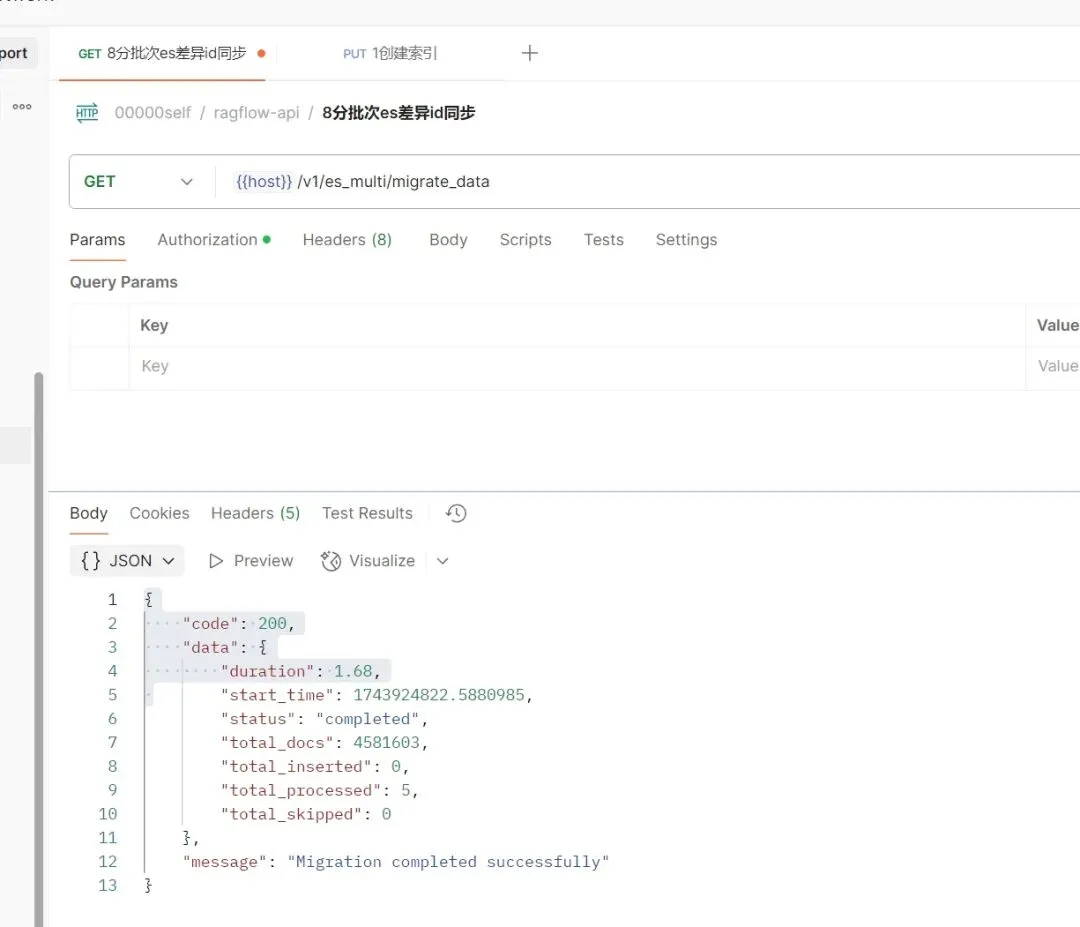
获取文档数量,如下:
//ragflow_7d19a176807611efb0f80242ac120006 索引中的文档数量 4581623//ragflow_7d19a176807611efb0f80242ac120006_new索引中的文档数量 3596000//ragflow_7d19a176807611efb0f80242ac120006_new2索引中的文档数量 1173768GET /ragflow_7d19a176807611efb0f80242ac120006/_countGET /ragflow_7d19a176807611efb0f80242ac120006_new/_countGET /ragflow_7d19a176807611efb0f80242ac120006_new2/_count
注:接下来,优化下接口程序,看下怎么处理这么多文档。
第三步:优化程序(四级)
20250406周日时间段:05:06-06:00
优化之后,测试如下:
预热测试:
# 先测试小批量数据curl -XPOST http://127.0.0.1:9380/v1/es/proceed_diff_ids -d'{"test_mode":true}'注:接下来,重写脚本。
第四步:重写脚本(四级)
20250406周日时间段:10:40-11:00
思路是这样:现在有一个es索引ragflow_7d19a176807611efb0f80242ac120006,2个分片,里面有4581623条数据。新建索引ragflow_7d19a176807611efb0f80242ac120006_new,24个分片,现在需要把ragflow_7d19a176807611efb0f80242ac120006中的数据分批次同步到ragflow_7d19a176807611efb0f80242ac120006_new中,要求如下:
1.每次查出5000条数据,条件是没有打标记的数据
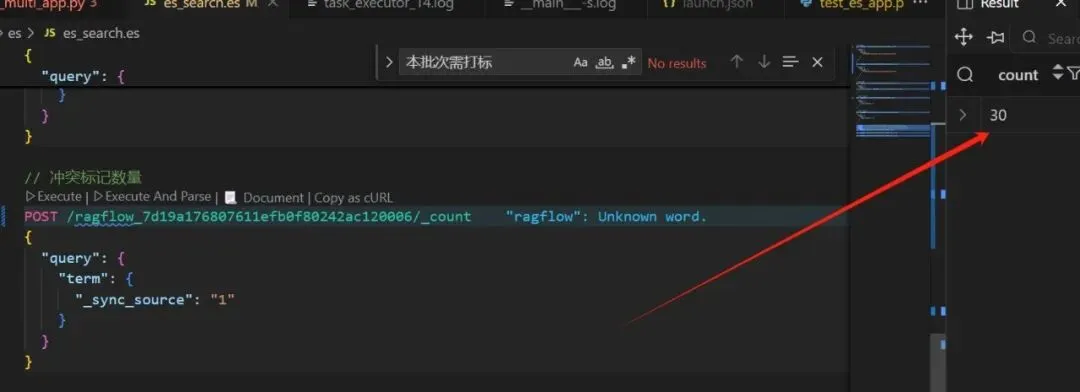
2.循环插入数据,插入前,给数据打标记,打标记如下:
_source._sync_source = 1
3.插入数据前验证数据是否在索引ragflow_7d19a176807611efb0f80242ac120006_new中存在,存在则不插入,不存在则存入
注:按上述要求写个python脚本
写脚本如下:
from elasticsearch import Elasticsearchfrom elasticsearch.helpers import scan, streaming_bulkimport time@manager.route('/proceed_diff_ids', methods=['POST'])def migrate_data(): es = Elasticsearch(["http://localhost:9200"]) # 修改为实际ES地址 old_index = "ragflow_7d19a176807611efb0f80242ac120006" new_index = "ragflow_7d19a176807611efb0f80242ac120006_new" batch_size = 5 # 每批处理量 # 查询未同步数据的DSL query = { "query": { "bool": { "must_not": {"exists": {"field": "_sync_source"}} } }, "size": batch_size } while True: try: # 获取本批次文档 documents = list(scan(es, index=old_index, query=query, scroll="5m", size=batch_size)) if not documents: print("所有数据迁移完成") break # 准备ID集合 doc_ids = [doc["_id"] for doc in documents] # 批量检查存在性 existing_ids = set() mget_body = {"docs": [{"_id": _id} for _id in doc_ids]} resp = es.mget(body=mget_body, index=new_index) for doc in resp["docs"]: if doc.get("found", False): existing_ids.add(doc["_id"]) # 构建插入操作(仅新增数据) bulk_actions = [ { "_op_type": "index", "_index": new_index, "_id": doc["_id"], "_source": doc["_source"] } for doc in documents if doc["_id"] not in existing_ids ] # 执行批量插入并收集成功ID success_ids = [] if bulk_actions: for ok, item in streaming_bulk(es, bulk_actions, raise_on_error=False): if ok: success_ids.append(item["index"]["_id"]) else: print(f"文档插入失败: {item}") print(f"新增插入成功: {len(success_ids)}条") # 合并需要打标的ID(已存在+新插入成功) marked_ids = list(existing_ids.union(success_ids)) print(f"本批次需打标: {len(marked_ids)}条") # 分批打标(避免超大查询) chunk_size = 500 # 每批打标量 for i in range(0, len(marked_ids), chunk_size): chunk = marked_ids[i:i+chunk_size] es.update_by_query( index=old_index, body={ "script": { "source": "ctx._source._sync_source = 1", "lang": "painless" }, "query": {"ids": {"values": chunk}} }, conflicts="proceed", refresh=True ) time.sleep(1) # 控制处理节奏 except Exception as e: print(f"处理异常: {str(e)}") time.sleep(5)注:接下来,对脚本进行测试。
第五步:测试脚本(四级)
20250406周日时间段:11:13-12:0020250406周日时间段:14:06-15:00
写个测试用例,测一下脚本接口,先用postman吧,test模块有错误。
找到错误,修改了,可以用testing写测试用例进行测试了。
先看下标记写没写到旧索引里面去,
ragflow_7d19a176807611efb0f80242ac120006_newsize: 325Gi (325Gi)docs: 3,596,000 (4,342,157)
先写测试用例吧,测试用例如下:
@pytest.fixturedef client(): app.config['TESTING'] = True client = app.test_client() return clientdef test_migrate_data(client): url = "/v1/api/test_migrate_data" response = client.get(url) print(f"\n\n response--local:{response} \n\n") json22=response.json() print(f"\n\n json22--onLine:{json22} \n\n")注:运行效果如下,没看出错误,接下来,进行打断点测试,如下:
图3a-2
注:测试效果如下:
图3a-3
注:看下写成功没。
第六步:验证打标签(四级)
20250406周日时间段:15:35-16:00
验证旧索引打标签,效果如下:
图3a-4
注:可以的,接下来,批量处理。代码上线一下,效果如下:
图3a-5
第七步:测试服务器(四级)
20250406周日时间段:15:47-16:00
接下来,在服务器上进行测试,看看效果怎么样。
奇怪,服务器竟然不行,截图如下:
图3a-6
注:在本地试试,看看哪里出问题,如下:
http://elastic:@116.204.8.110:1200/_cat/indices?vhttp://elastic:@116.204.8.110:1200/ragflow_7d19a176807611efb0f80242ac120006_newhttp://elastic:@116.204.8.110:1200/ragflow_7d19a176807611efb0f80242ac120006_new/_search?pretty统计信息:http://elastic:@116.204.8.110:1200/ragflow_7d19a176807611efb0f80242ac120006_new/_stats统计信息:http://elastic:@116.204.8.110:1200/ragflow_7d19a176807611efb0f80242ac120006/_count?q=_sync_source:1
注:现在有个问题,就是代码在服务器上跑不起来,不知道啥原因,把这个问题解决一下。
二、服务器上跑分批(三级)
描述:现在分批接口在本地能跑,在服务器上跑不起来,看下什么原因。
开工:
第一步:分析原因(四级)
20250406周日时间段:23:11-00:00
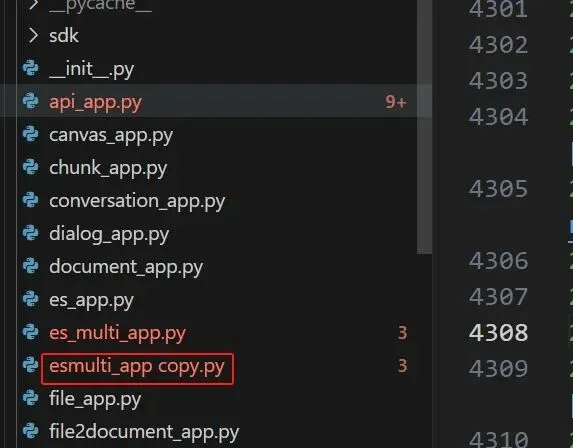
可能的原因是文件名命名有问题,现在命名的文件名是es_multi_app.py,其它的就一个下划线,这里两个,所以,先去掉一个,改为esmulti_app.py试试,改了之后,截图如下:
图3a-7
注:新增了一个文件,可以不影响现在的逻辑,上传,重启下服务器,测试下效果。
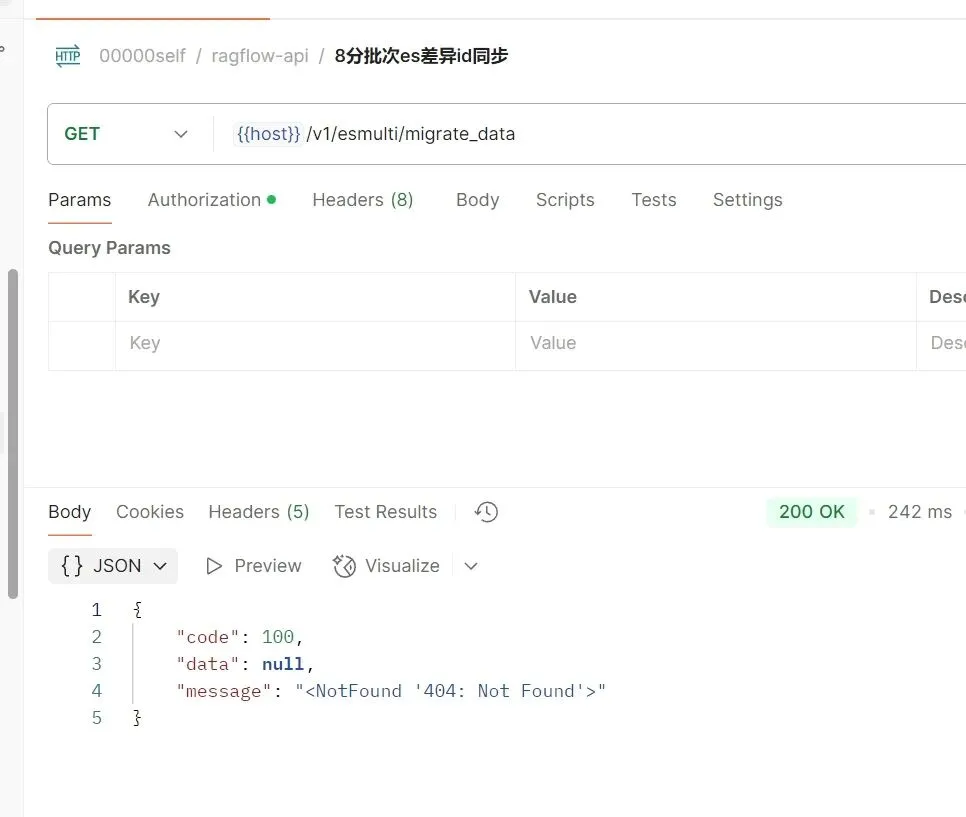
第二步:上传测试(四级)
20250406周日时间段:23:15-00:00
测试一下,看看效果,效果如下:
图3a-8
注:文件名写错了,看图3a-7发现,多了个copy。
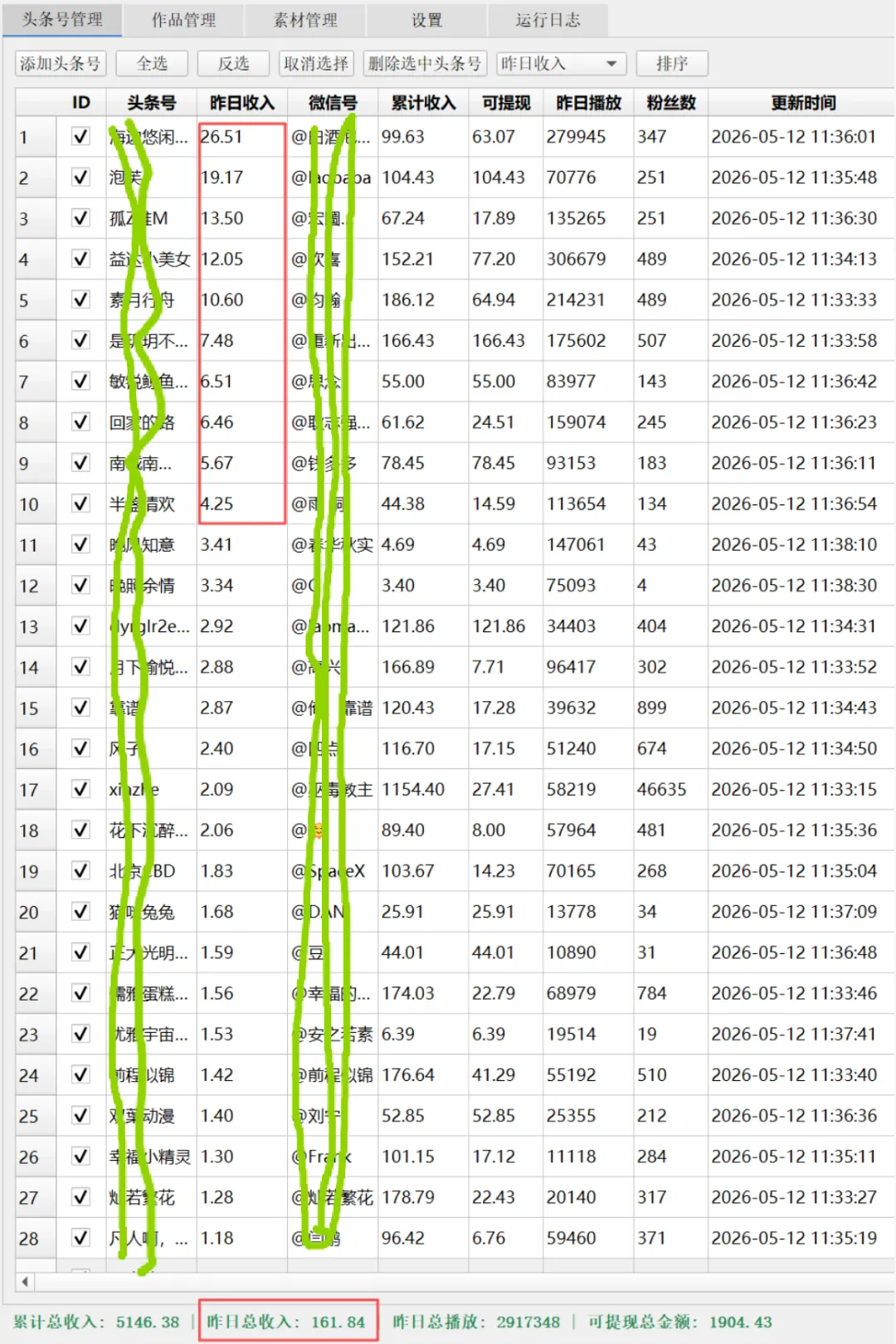
三、头条号战果汇报
昨日数据来啦,累计总收入:4984.54,昨日总收入:106.32,昨日总播放:244.5万,可提现总金额:1742.59。软件截图如下:
图3c-1
注:想要全脱管运营头条号的联系我,你出账号,我来运营,收益四六分成(你六我四),你当甩手掌柜,每天都能得几块零花钱,财富wx: 17701328814,也可以加群先了解一下。
图3c-2
四、生活照片(三级)
拍摄于2026年2月17日,20:02:56,带两个孩子去看灯拍的,当时大宝八岁两个月,二宝三岁五个月。我觉得马哥这样的人不成功天理不容,就拿我和马哥接触来说,人家做个小程序,把一切要准备的资料提前准备好,并且能随问随答,哪怕凌晨两三点问人家,人家嗖的一下出来。并且每次问我忙不忙的时候,如果我说不忙,立马开始沟通,如果我说忙,就自己整理资料,甚至是代码。而马哥只是初中文化,从没接触过编程,你说这样的经常通宵研究遇到的问题的人,把每件事都做的很充分,他不成功,谁成功。就像:一对小情侣,爱的死去活来,家人不同意,偷户口本出来,没车去县城,翻几座大山,经历各种艰难险阻,到婚姻登记处,人家正要关门,看着小情侣,满脸尘土,衣服都被树枝划破了,有的皮肤还流着血,大概率会破例为他们办结婚证。还让我想到张雪,也没啥文化,就是一根筋研究发动机,研究摩托车,就能做到世界第一,秒杀多少大厂。遇到马哥是我的幸运,让我浑身充满了激情,这个小程序,我一定会做好,不辜负马哥的期待,加油!
图3d-1
《本文完》


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
