新手必看|Python实现颜色聚合向量(CCV),附完整代码+逐行精讲
大家好~ 今天分享一个图像处理中常用的特征提取方法——颜色聚合向量(Color Coherence Vector, CCV),它比普通颜色直方图更实用(兼顾颜色分布和空间位置),新手也能轻松上手!
全程用Python实现,附完整可运行代码、逐行解析和结果解读,看完直接复制就能用,收藏起来慢慢练~
unsetunset一、先搞懂:什么是颜色聚合向量(CCV)?unsetunset
我们做图像处理时,经常需要提取图像的“颜色特征”(比如图像检索、分类),普通颜色直方图只统计颜色出现次数,却忽略了「颜色的空间位置」——比如同样是红色,大面积连续的红色和零散的红色小点,直方图完全一样,但实际意义天差地别。
而颜色聚合向量(CCV),就解决了这个问题:
核心逻辑:先将图像颜色量化(减少颜色种类),再识别“连在一起的同色块”(连通区域),按区域大小分为「聚合像素」(大面积连续)和「非聚合像素」(小面积分散),最终统计每种颜色的两类像素数,形成特征向量。
简单说:CCV不仅知道“有什么颜色”,还知道“颜色是不是聚在一起”,实用性更强!
unsetunset二、环境准备(新手必看)unsetunset
需要用到4个Python库,直接复制命令安装(终端/命令行运行):
pip install numpy scikit-image pandas
说明:
scikit-image(简称skimage):实现连通区域标记(核心功能)
unsetunset三、完整可运行代码(直接复制)unsetunset
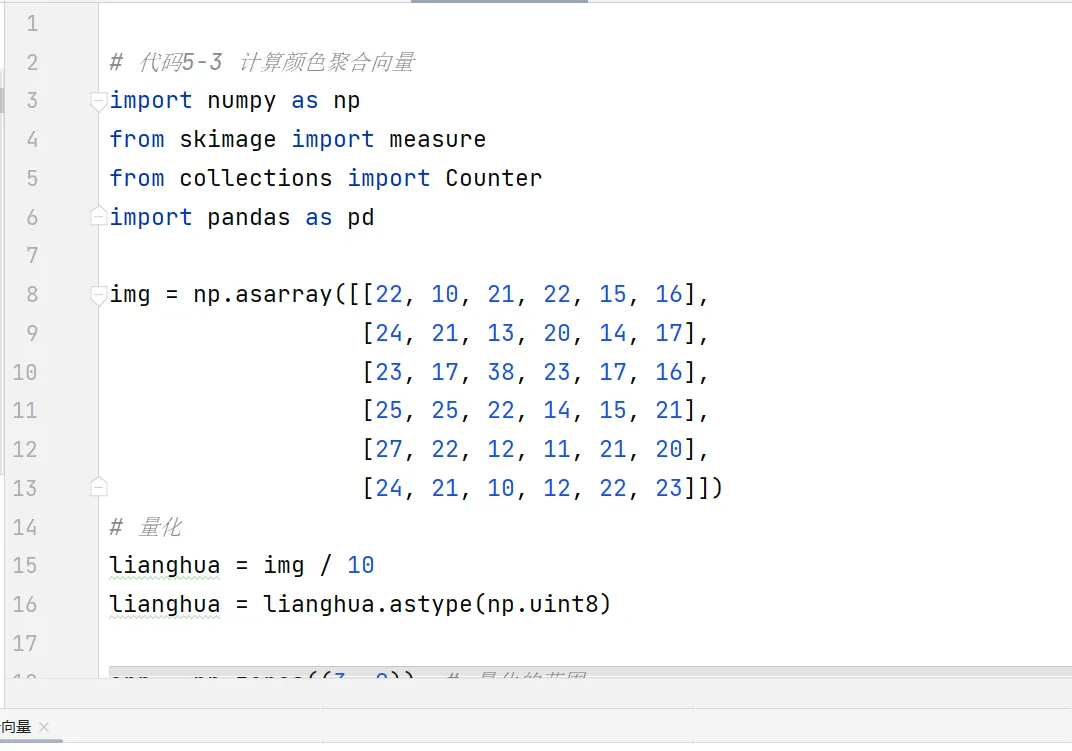
我们用一个6×6的测试图像演示(新手无需修改,先跑通再调整):
# 颜色聚合向量(CCV)完整实现import numpy as npfrom skimage import measure # 连通区域标记from collections import Counter # 统计像素数量import pandas as pd # 格式化输出结果# 1. 定义6×6测试灰度图像(像素值范围10~38)img = np.asarray([[22, 10, 21, 22, 15, 16], [24, 21, 13, 20, 14, 17], [23, 17, 38, 23, 17, 16], [25, 25, 22, 14, 15, 21], [27, 22, 12, 11, 21, 20], [24, 21, 10, 12, 22, 23]])# 2. 颜色量化(核心预处理:减少颜色种类)lianghua = img / 10# 量化规则:10~19→1,20~29→2,30~39→3lianghua = lianghua.astype(np.uint8) # 取整,转为无符号整数# 3. 初始化结果表格(3种量化颜色 × 2类像素)arr = np.zeros((3, 2))n_data = pd.DataFrame(arr, columns=['聚合', '非聚合'])# 4. 连通区域标记:识别连在一起的同色块label_image = measure.label(lianghua)# 5. 统计每个连通区域的像素数量label_image_ = label_image.reshape(36, ) # 图像展平为一维数组(6×6=36像素)list_jh = Counter(label_image_) # 键:区域标签,值:区域像素数# 6. 构建映射:连通区域 → 对应量化颜色(区域内颜色一致)quyu_bin = {}for i in range(len(list_jh)): a = np.argwhere(label_image == i + 1)[0] # 取区域第一个像素坐标 jianming = lianghua[a[0], a[1]] # 获取该区域的量化颜色 quyu_bin[i + 1] = jianming# 7. 区分聚合/非聚合区域(阈值tao=4:像素数>4为聚合)juhe = [] # 聚合区域标签feijuhe = [] # 非聚合区域标签tao = 4for i in list_jh.keys():if list_jh[i] > tao: juhe.append(i)else: feijuhe.append(i)# 8. 统计最终结果:累加每种颜色的聚合/非聚合像素数for i in juhe: n_data.loc[quyu_bin[i] - 1, ['聚合']] += list_jh[i]for i in feijuhe: n_data.loc[quyu_bin[i] - 1, ['非聚合']] += list_jh[i]# 输出颜色聚合向量print("颜色聚合向量(CCV)结果:")print(n_data)
unsetunset四、逐行精讲(新手能懂,老手速查)unsetunset
不用害怕代码长,每一步都有明确目的,拆解后超简单!
Step 1:定义测试图像
我们手动定义一个6×6的灰度图像矩阵(像素值10~38),相当于“迷你版图像”,方便新手观察结果,实际使用时替换成自己的图像即可(后续会说)。
Step 2:颜色量化(最关键的预处理)
代码:lianghua = img / 10 + lianghua.astype(np.uint8)
目的:将原本10~38的连续像素值,压缩为3种离散颜色,避免颜色过多导致计算复杂:
Step 3:初始化结果表格
用pandas创建一个3行2列的表格,3行对应3种量化颜色,2列分别记录“聚合像素数”和“非聚合像素数”,初始值都是0,后续逐步累加。
Step 4:连通区域标记(核心功能)
代码:label_image = measure.label(lianghua)
这是整个代码的“核心”,依赖skimage的measure模块:
作用:自动识别图像中「相邻且颜色相同」的像素块(按8邻域判断:上下左右+四个对角都算相邻),给每个独立的块分配一个唯一标签(比如1、2、3...)。
举个例子:图像中连在一起的2个“颜色1”像素,会被标记为标签1;另一个单独的“颜色1”像素,会被标记为标签2。
Step 5:统计区域像素数
先将标记后的图像展平为一维数组(6×6=36个像素),再用Counter统计每个标签(连通区域)的像素数量,得到类似 {1:15, 2:3, 3:12, 4:1, 5:5} 的结果(键是区域标签,值是该区域的像素数)。
Step 6:区域→颜色映射
每个连通区域的颜色都是一致的(因为标记时只标记同色相邻像素),所以我们取每个区域的第一个像素,就能得到该区域对应的量化颜色,构建映射表(比如 {1:2, 2:1, 3:1, 4:3, 5:2})。
Step 7:区分聚合/非聚合区域
设定阈值tao=4(可根据需求调整):
聚合区域:区域像素数 4 → 大面积连续的颜色(比如背景)
非聚合区域:区域像素数 ≤ 4 → 小面积分散的颜色(比如噪点、细节)
Step 8:统计最终结果
根据映射表,将每个区域的像素数,累加到对应颜色的“聚合”或“非聚合”列中,最终得到颜色聚合向量。
unsetunset五、运行结果解读(一看就懂)unsetunset
运行代码后,输出如下结果:
颜色聚合向量(CCV)结果: 聚合 非聚合00.010.0120.06.020.00.0
逐行解读(对应3种量化颜色):
| | | | |
|---|
| | | | |
| | | | |
| | | | 测试图像中无该颜色(仅38一个像素,标记后像素数≤4,且代码中映射后未统计到) |
unsetunset六、新手拓展:如何用在自己的图像上?unsetunset
把测试图像替换成自己的图片即可,只需添加1行代码读取图像:
# 读取本地图像(替换测试图像img)from skimage import ioimg = io.imread("你的图片路径.jpg", as_gray=True) # as_gray=True转为灰度图img = img.astype(np.uint8) # 转为整数像素值
注意:如果是彩色图像,需要先转为灰度图(上述代码已包含),或者对每个通道分别计算CCV。
unsetunset七、常见问题 注意事项unsetunset
报错“no module named skimage”:未安装scikit-image,运行 pip install scikit-image 即可。
阈值tao的选择:默认4,可根据图像大小调整(图像越大,阈值可适当增大)。
颜色量化:本文量化为3种颜色,可根据需求调整(比如除以5,量化为更多颜色)。
unsetunset八、总结unsetunset
颜色聚合向量(CCV)的核心的是「兼顾颜色分布和空间位置」,比普通颜色直方图更适合图像特征提取,整个实现流程分为8步,新手只需掌握:
颜色量化 → 连通区域标记 → 区域统计 → 聚合/非聚合区分 → 结果统计
代码可直接复制运行,替换成自己的图像就能快速得到CCV特征,赶紧动手试试吧!
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
