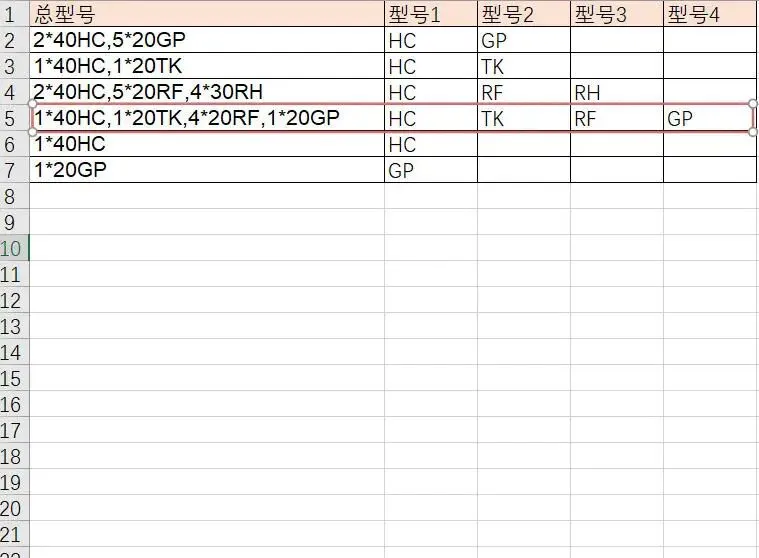
一个网友的问题:‘总型号’列包含很多子型号的数据(个数不定),将子型号都提取出来并不在不同的列:从上图能看出来,总型号为有数字、符号和大写字母的组合,型号为大写字母,如果要提取肯定绕不开正则表达式,VBA和高阶函数都能写,VBA写完后,需要单独定义数组封装,函数写完后需要下拉,对于列数不固定的数据不是很方便,而使用Python-apply(lambda x: )直接将数据分组则简单很多。首先定义正则表达式:r'(\d+[A-Z]{2,3})'提取文本中大写英文字母2-3个字符;然后将提取的数据装入列表:apply(lambda x: [re.search(r'[A-Z]{2,3}$', item).group() for item in x] models_series = df['总型号'].str.findall(r'(\d+[A-Z]{2,3})').apply(
lambda x: [re.search(r'[A-Z]{2,3}$', item).group() for item in x] )
第二步 将提取出来的数据放入不同的列:
首先确定列表中型号最大的计数:
max_models = models_series.apply(len).max()
然后根据最大的计数增加型号列:
for i in range(max_models):
result[f'型号{i+1}'] = models_series.apply(
lambda x: x[i] if i < len(x) else ''
)
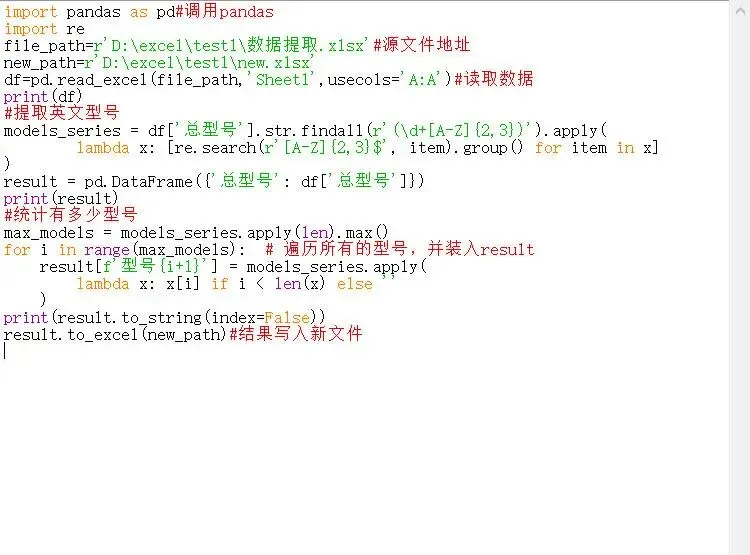
完整的代码如下:
看下效果:
数据完整的提取到不同的列中,如遇到几万行的数据Python将大大提高效率。