做运维、干开发、管服务器,日常工作根本就离不开linux系统。但说句实在话,绝大多数人都只是死记硬背敲命令,根本不清楚每一条指令背后暗藏的风险。
平日里运行平稳的业务、状态稳定的服务器,往往就是随手敲错一条命令,直接搞崩集群、误删核心数据、打乱权限配置,全线服务瞬间瘫痪。
经常有人询问我,服务器突然弹出503报错找不到原因、清理完磁盘空间系统反而更卡顿、清空日志之后业务直接断线、修改完权限整个网站都无法访问……这些线上重大事故,归根结底都是基础操作不规范、风险意识薄弱导致的。
今天这篇纯干货文章,不讲晦涩原理,不说空洞理论,只盘点生产环境中最容易翻车、后果最严重、最容易让人背锅的linux高危操作。
认真看完,轻松避开90%线上运维事故,建议收藏保存,转发给身边同事,关键时刻能直接保命!
一、头号高危操作:rm -rf随意删除,运维行业头号杀手
这个命令毋庸置疑,是运维圈子公认最容易闯祸、最容易背锅的指令。
不少新手运维养成了随手清理文件的习惯,频繁执行以下命令:
表面看着平平无奇,实则暗藏巨大隐患,线上翻车案例每天都在上演:
笔者有一同事就踩过坑:前段时间执行rm -rf /data/app/*操作失误,误删当前目录全部文件,万幸的是此前程序之前做了备份,没有造成数据丢失,但是也导致了业务的中断。
生产环境安全规范删除方式
线上尽可能减少rm -rf强制删除文件,严格遵守三步走原则:
#1.提前预览确认文件,核对无误再操作ls /data/需清理文件#2.优先移动备份,不直接删除mv 目标文件名 /tmp/backup/#3.确认业务无异常后,再统一清理备份文件rm -rf /tmp/backup/*
服务器磁盘空间爆满时,很多人为了省事,直接执行命令清空日志:> access.log#或 rm -rf access.log
亦或是直接用文本工具手动清空日志内容。危险的不是清空,而是删除正在被进程打开的文件。当某些应用(如java、nginx)打开一个日志文件后,即使你用rm删除它,磁盘空间也不会立即释放,因为进程仍持有文件描述符。只有重启进程,空间才会释放。
操作翻车原因
日志运行进程持续占用文件句柄,即便肉眼看着日志清空,系统后台依旧占用存储空间,无法完成空间回收,极易引发磁盘卡死,程序异常。
运维通用标准清理方法
#方法一:精准清空日志,不影响业务truncate -s 0 access.log#方法二:简易安全清空方式echo "" > access.log#方法三:保留部分日志 tail -n 1000 access.log > access.log.tmp mv access.log.tmp access.log
操作简单零风险,不中断线上业务,还能快速释放磁盘空间。
三、第三高危操作:全局授予 777 最高权限
项目程序运行报错、文件访问权限不足,新手第一反应就是全局赋权:
这种操作绝非解决问题,而是直接埋下重大安全隐患!
三大致命负面影响
根据网络报道,某地一系统被黑,调查发现是运维为了方便,给上传目录设置了777权限。攻击者上传了webshell,最终导致整个公民数据库泄露。运维和直接领导均被追究相关责任。
企业统一标准权限配置
#普通目录标准权限chmod 755 目录名称#普通文件标准权限chmod 644 文件名称#运行脚本单独添加执行权限chmod +x 脚本文件名
线上环境坚决杜绝全局777权限,这是运维工作最基本的底线。
四、第四高危操作:随意修改 /etc/profile 系统配置
日常配置环境变量、搭建java、python 运行环境,大家都会编辑系统配置文件:
仅仅只是写错一行代码、遗漏一个符号、少打一对引号,就会导致整台服务器所有基础命令全部失效。就连ls、cd、systemctl这类常用指令都无法使用,直接陷入系统瘫痪困境。
老手通用安全修改流程
#第一步:修改前优先备份原配置文件cp /etc/profile /etc/profile.bak#第二步:修改完成后先本地测试生效source /etc/profile#第三步:无报错再正式使用,出现异常立刻还原配置cp /etc/profile.bak /etc/profile
修改系统核心配置不做备份,等同于裸机上线运行,风险极高。
那么如果/etc/profile损坏后如何紧急处理,参考下面命令
#紧急恢复方法#1.通过绝对路径执行命令/bin/cp /etc/profile.bak /etc/profile#2.或直接在ssh会话中执行export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin# 3. 然后立即修复source /etc/profile
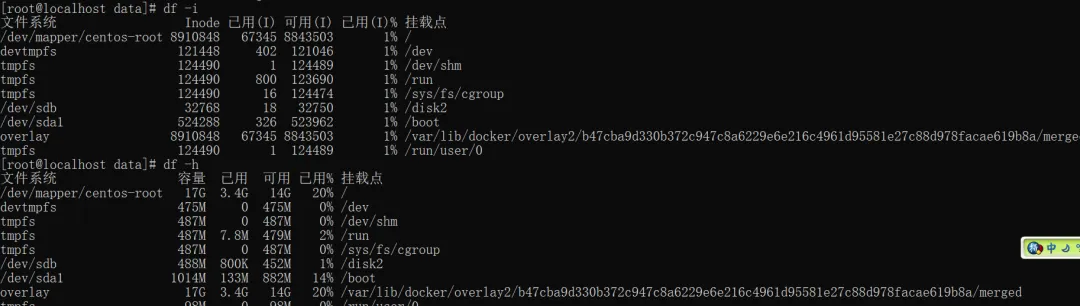
五、第五高危操作:只查磁盘空间,忽略inode占用
大部分运维日常排查磁盘问题,只执行单一命令查看空间:
明明磁盘剩余空间十分充足,线上业务却依旧频繁宕机报错。核心原因就是inode 节点存储空间爆满,系统无法新建任何文件,直接导致业务停滞。
日常磁盘巡检必备两条命令
#查看磁盘整体存储空间df -h#查看inode节点使用占用情况df -i
一旦发现 inode 使用率超过 90%,第一时间清理服务器内无用小文件,避免突发故障。查找清理小文件推荐使用以下命令:
#1.查找目录下文件数量(定位小文件集中地)find /path -type f | wc -l#2.清理大量小文件的特殊技巧#对于/tmp等目录,有时文件太多导致rm都报错rsync -a --delete /tmp/empty/ /tmp/junk/#3.查找小文件较多的目录 find / -xdev -type f 2>/dev/null -printf "%h\n" | sort | uniq -c | sort -rn | head -10#4.查找0字节文件find / -type f -size 0 2>/dev/null | wc -lfind / -type f -empty 2>/dev/null -delete
六、第六高危操作:直接关闭终端,终止后台运行程序
在服务器后台部署运行项目程序,操作完成后直接关闭终端窗口、断开远程连接。
后台运行的所有程序都会被系统强制终止,线上业务瞬间中断,造成不必要的损失。
企业稳定后台运行三种实用方式
#方式一:日常最常用 nohup 后台运行nohup java -jar app.jar &#方式二:screen终端神器,断开连接永不掉线screen -S app#方式三:企业正式环境首选 systemctl 服务托管systemctl start 自定义服务名当然也使用前面介绍的tmux
七、第七高危操作:直接解压压缩包,覆盖原有数据
本地做好程序安装包上传至服务器后,直接一键解压:
unzip app.ziptar -xvf app.tar.gz
压缩包内同名文件会直接强制覆盖服务器原有文件,旧项目代码、核心配置文件、重要业务数据悄无声息丢失,事后很难找回
安全解压流程,杜绝数据覆盖
#1.新建独立解压目录mkdir new_app#2.移动压缩包至新目录mv app.zip new_app/#3.预览压缩包内容,排查文件冲突unzip -l app.zip#4.进入目录解压,避免覆盖线上原有文件cd new_appunzip app.zip
八、运维从业保命 7 条铁律
- 磁盘巡检双维度排查,同时查看存储空间与 inode 节点
linux系统操作本身难度并不大,真正考验功底的是操作规范性、工作稳定性以及风险规避意识。
很多深耕运维行业多年的资深从业者,技术能力十分扎实,最后却栽在一条不起眼的错误命令上,不仅承担工作责任、被扣绩效奖金,还要通宵熬夜紧急抢修服务器。
真正的行业老手,从来不是敲击命令速度最快的人,而是懂得敬畏服务器、拒绝盲目随意操作的人。
linux给予root用户最高的权力,但这份权力对应的不是自由,而是责任。
每一次按下回车键前,都应该问自己三个问题:
1.我真的知道这个命令在做什么吗?
2.我有回滚方案吗?
3.最坏的结果是什么,我能承受吗?
记住:在运维的世界里,谨慎不是胆小,而是专业。
如果觉得文章对你的运维工作有帮助,记得点赞加关注。
#运维#linux运维#常用高危命令#运维避坑指南#服务器安全#线上事故排查



 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
