在真实的工厂车间里,一台设备的异常报警可能意味着数十万的损失。而那条关键的错误日志,往往就是唯一的"案发现场还原"线索。
🏭 那些年,我们被日志坑过的经历
说真的,工控软件的日志问题,是我职业生涯里踩得最深的坑之一。
刚入行那会儿,我负责维护一套PLC通信程序。某天凌晨两点,产线突然停了。翻遍整个系统,日志文件里只有寥寥几行print("error")——连时间戳都没有。那一夜,我和同事对着设备发呆了三个小时,愣是没定位到根因。
这种痛,相信很多做工控、MES、SCADA系统的朋友都懂。
工业场景的日志需求,和普通Web应用完全不是一个量级:多线程并发写入、跨设备数据聚合、毫秒级时序追踪、海量数据的长期归档……随便拎出一条,都够折腾一阵子。
本文就从实战出发,带你搭一套真正能在工业环境里"扛造"的Python日志系统。代码全部可运行,架构可直接迁移到生产项目。
🔍 工业日志的特殊性:哪里和普通日志不一样?
先把问题说清楚,再谈方案。
普通应用的日志,核心诉求是记录和排错。但工业系统的日志,承担的职责要复杂得多——
时序精度要求极高。 一条焊接指令和一条质检结果,如果时间戳偏差超过50ms,数据关联就会失效。这不是"差不多"能过去的事。
多源并发是常态。 同一时刻,温控模块、运动控制模块、视觉检测模块可能同时在写日志。锁竞争、写入顺序错乱,是家常便饭。
日志本身就是业务数据。 工厂的质量追溯、工艺优化,全靠历史日志。这意味着日志不能丢、不能乱、还得方便查。
存储压力大。 一条产线一天可能产生几个GB的原始日志。怎么压缩、怎么分片、怎么归档,都得提前设计好。
带着这四个问题,咱们开始搭架子。
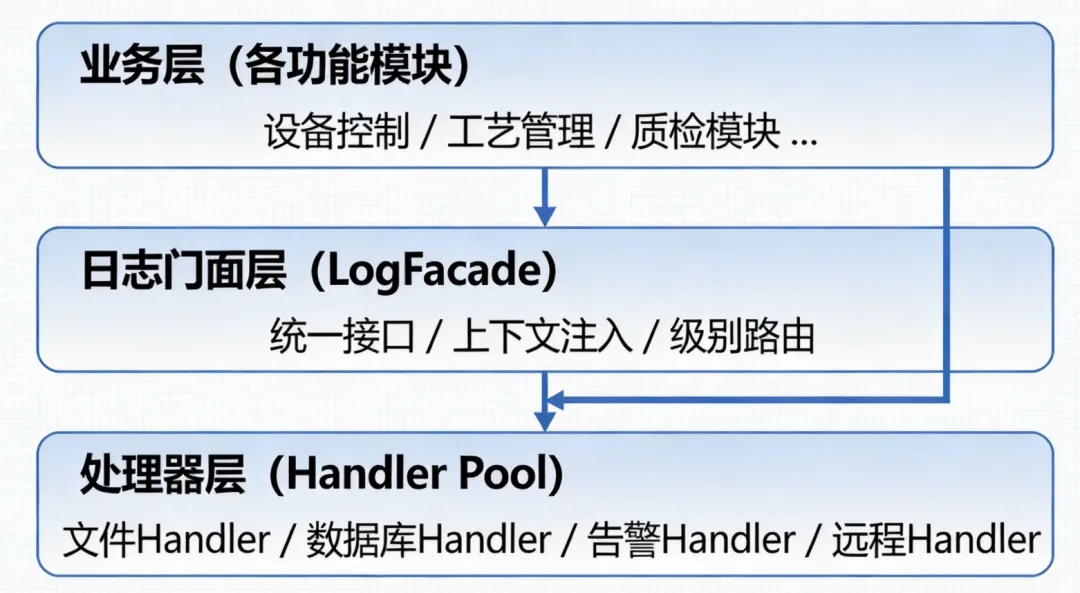
🏗️ 系统架构设计:分层才是王道
太多项目,把所有日志逻辑塞进一个utils.py,然后在几十个模块里import来import去。这玩意儿,短期看没问题,长期必然是一团乱麻。
工业日志系统,我建议采用三层架构:
业务层不关心日志怎么存、存哪里。门面层负责统一收口、注入设备ID/工单号等上下文。处理器层各司其职,互不干扰。
🚀 核心实现:从基础到进阶
第一步:构建线程安全的日志基础设施
Python标准库的logging模块本身是线程安全的——但很多人不知道,FileHandler在Windows下的多进程写入是有问题的。工控机上跑多进程采集的场景,必须用RotatingFileHandler配合文件锁,或者直接上队列方案。
python1import logging2import logging.handlers3import threading4import queue5from datetime import datetime6from pathlib import Path789class IndustrialLoggerFactory:10"""11 工业日志工厂类12 核心设计:单例 + 异步队列写入,避免IO阻塞业务线程13 """14 _instance = None15 _lock = threading.Lock()1617def __new__(cls):18if cls._instance is None:19with cls._lock:20if cls._instance is None:21 cls._instance = super().__new__(cls)22 cls._instance._initialized = False23return cls._instance2425def __init__(self):26if self._initialized:27return2829 self.log_dir = Path("logs")30 self.log_dir.mkdir(exist_ok=True)3132# 异步队列:业务线程只管往队列扔,IO线程负责实际写入33 self._log_queue = queue.Queue(maxsize=10000)34 self._setup_handlers()35 self._start_async_worker()36 self._initialized = True3738def _setup_handlers(self):39"""配置多目标Handler"""40 self.logger = logging.getLogger("industrial_system")41 self.logger.setLevel(logging.DEBUG)4243# 按日期滚动的文件Handler44 file_handler = logging.handlers.TimedRotatingFileHandler(45 filename=self.log_dir / "system.log",46 when="midnight", # 每天零点切割47 interval=1,48 backupCount=90, # 保留90天49 encoding="utf-8"50 )5152# 关键告警单独存一份,方便快速检索53 alarm_handler = logging.handlers.RotatingFileHandler(54 filename=self.log_dir / "alarm.log",55 maxBytes=50 * 1024 * 1024, # 50MB切割56 backupCount=20,57 encoding="utf-8"58 )59 alarm_handler.setLevel(logging.WARNING)6061 formatter = IndustrialFormatter()62 file_handler.setFormatter(formatter)63 alarm_handler.setFormatter(formatter)6465 self.logger.addHandler(file_handler)66 self.logger.addHandler(alarm_handler)6768def _start_async_worker(self):69"""启动后台IO线程,消费日志队列"""70 worker = threading.Thread(71 target=self._async_write_worker,72 daemon=True, # 随主进程退出,不阻塞关闭73 name="LogIOWorker"74 )75 worker.start()7677def _async_write_worker(self):78while True:79try:80 record = self._log_queue.get(timeout=1)81if record is None: # 优雅停止信号82break83 self.logger.handle(record)84except queue.Empty:85continue
这里有个细节值得注意:daemon=True让IO线程随主进程退出,但这意味着程序崩溃时队列里可能还有未写入的日志。生产环境里,建议在主程序的finally块里发送停止信号,等队列清空再退出。
第二步:自定义Formatter,注入工业上下文
标准的日志格式对工业系统来说信息量严重不足。我们需要在每条日志里自动带上设备编号、工单号、操作员ID这些关键字段。
python1import json2import traceback345class IndustrialFormatter(logging.Formatter):6"""7 结构化日志格式器8 输出JSON格式,方便后续用ELK或自研平台解析9 """1011# 线程本地存储:每个线程独立维护自己的上下文12 _context = threading.local()1314@classmethod15def set_context(cls, **kwargs):16"""在业务代码入口处设置上下文,后续日志自动携带"""17for key, value in kwargs.items():18setattr(cls._context, key, value)1920@classmethod21def clear_context(cls):22 cls._context.__dict__.clear()2324def format(self, record: logging.LogRecord) -> str:25# 基础字段26 log_entry = {27"timestamp": datetime.fromtimestamp(record.created).strftime(28"%Y-%m-%d %H:%M:%S.%f"29 )[:-3], # 精确到毫秒30"level": record.levelname,31"module": record.module,32"func": record.funcName,33"line": record.lineno,34"message": record.getMessage(),35# 从线程本地存储中读取业务上下文36"device_id": getattr(self._context, "device_id", "UNKNOWN"),37"work_order": getattr(self._context, "work_order", None),38"operator": getattr(self._context, "operator", None),39 }4041# 异常信息单独格式化,保留完整堆栈42if record.exc_info:43 log_entry["exception"] = {44"type": record.exc_info[0].__name__,45"message": str(record.exc_info[1]),46"traceback": traceback.format_exception(*record.exc_info)47 }4849# 过滤None值,减少存储冗余50 log_entry = {k: v for k, v in log_entry.items() if v is not None}5152return json.dumps(log_entry, ensure_ascii=False)
线程本地存储(threading.local())是这里的关键。 每个采集线程处理不同设备,上下文互不污染。在线程入口处调一次set_context(device_id="PLC_001"),后续这个线程产生的所有日志都会自动带上设备ID。
第三步:设备日志门面——业务代码的唯一入口
有了底层基础设施,再封装一个面向业务的门面类。让业务代码写日志时,不需要关心任何底层细节。
python1from contextlib import contextmanager2from functools import wraps3import time456class DeviceLogger:7"""8 设备日志门面9 业务模块统一通过这个类记录日志10 """1112def __init__(self, device_id: str, device_type: str = "GENERIC"):13 self.device_id = device_id14 self.device_type = device_type15 self._factory = IndustrialLoggerFactory()1617# 初始化时就把设备信息注入上下文18IndustrialFormatter.set_context(19 device_id=device_id,20 device_type=device_type21 )2223def info(self, message: str, **extra):24 self._log(logging.INFO, message, **extra)2526def warning(self, message: str, **extra):27 self._log(logging.WARNING, message, **extra)2829def error(self, message: str, exc_info=False, **extra):30 self._log(logging.ERROR, message, exc_info=exc_info, **extra)3132def critical(self, message: str, **extra):33 self._log(logging.CRITICAL, message, **extra)3435def _log(self, level: int, message: str, exc_info=False, **extra):36 record = logging.LogRecord(37 name="industrial_system",38 level=level,39 pathname="",40 lineno=0,41 msg=message,42 args=(),43 exc_info=logging.sys.exc_info() if exc_info else None44 )45# 把extra字段挂到record上,Formatter可以读取46for key, value in extra.items():47setattr(record, key, value)4849# 非阻塞放入队列50try:51 self._factory._log_queue.put_nowait(record)52except queue.Full:53# 队列满了,这条日志只能丢弃——但这本身也是个告警信号54print(f"[WARN] Log queue full, dropping: {message}")5556@contextmanager57def operation_trace(self, operation_name: str):58"""59 上下文管理器:自动记录操作耗时60 用法:with logger.operation_trace("焊接动作"):61 """62 start = time.perf_counter()63 self.info(f"[START] {operation_name}")64try:65yield66 elapsed = (time.perf_counter() - start) * 100067 self.info(f"[END] {operation_name} | 耗时: {elapsed:.2f}ms")68except Exception as e:69 elapsed = (time.perf_counter() - start) * 100070 self.error(71f"[FAILED] {operation_name} | 耗时: {elapsed:.2f}ms | 原因: {e}",72 exc_info=True73 )74raise # 异常继续向上传播,不在日志层吞掉757677def log_device_action(operation: str):78"""79 装饰器版本:给函数自动加上日志追踪80 适合那些每次调用都需要记录的设备操作函数81 """82def decorator(func):83@wraps(func)84def wrapper(self, *args, **kwargs):85# 假设self上有logger属性86 logger = getattr(self, 'logger', None)87if logger and hasattr(logger, 'operation_trace'):88with logger.operation_trace(operation):89return func(self, *args, **kwargs)90return func(self, *args, **kwargs)91return wrapper92return decorator
第四步:实战组装——模拟PLC通信场景
把上面这些拼起来,看看实际用起来是什么感觉:
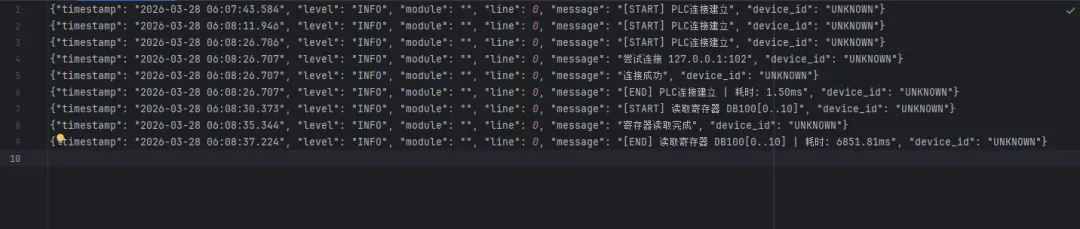
python1class PLCController:2"""PLC控制器示例:展示日志系统在真实业务中的用法"""34def __init__(self, plc_id: str):5 self.plc_id = plc_id6 self.logger = DeviceLogger(7 device_id=plc_id,8 device_type="SIEMENS_S7"9 )10 self.connected = False1112@log_device_action("PLC连接建立")13def connect(self, ip: str, port: int = 102):14"""建立PLC连接"""15 self.logger.info(f"尝试连接 {ip}:{port}")16# 模拟连接逻辑...17 self.connected = True18 self.logger.info("连接成功", ip=ip, port=port)1920def read_registers(self, start_addr: int, count: int) -> list:21"""读取寄存器数据"""22if not self.connected:23 self.logger.error("读取失败:设备未连接")24raise ConnectionError("PLC未连接")2526with self.logger.operation_trace(f"读取寄存器 DB{start_addr}[0..{count}]"):27# 实际项目里这里是snap7或pycomm3的调用28 data = [0] * count29 self.logger.info(30f"寄存器读取完成",31 start_addr=start_addr,32 count=count,33 sample_value=data[0] if data else None34 )35return data3637def write_coil(self, addr: int, value: bool):38"""写线圈——这类操作必须有完整的操作记录"""39IndustrialFormatter.set_context(40 device_id=self.plc_id,41 action_type="WRITE",42 target_addr=addr43 )44 self.logger.warning(45f"写入线圈 addr={addr}, value={value}",46 safety_level="MEDIUM"47 )484950# 使用示例51if __name__ == "__main__":52# 设置当前工单上下文53IndustrialFormatter.set_context(54 work_order="WO-20260318-001",55 operator="张工"56 )5758 plc = PLCController("PLC_LINE_A_01")59 plc.connect("192.168.1.100")6061 data = plc.read_registers(start_addr=100, count=10)62 plc.write_coil(addr=200, value=True)
运行后,logs/system.log里的每一行都是结构化JSON,长这样:
json1{2"timestamp": "2026-03-18 07:16:49.698",3"level": "INFO",4"module": "plc_controller",5"func": "connect",6"line": 28,7"message": "连接成功",8"device_id": "PLC_LINE_A_01",9"device_type": "SIEMENS_S7",10"work_order": "WO-20260318-001",11"operator": "张工",12"ip": "192.168.1.100",13"port": 10214}
⚠️ 踩坑预警:这几个地方最容易出问题
坑1:日志队列满了怎么办? 上面代码里用的是put_nowait,队列满直接丢弃。这在大多数场景是合理的——日志不能反过来阻塞业务。但如果你的场景要求日志绝对不丢,可以改成put(block=True, timeout=0.1),超时后写到应急文件。
坑2:Windows下的文件时间戳精度问题。datetime.now()在Windows上的精度只有约15ms,不足以区分高频操作。建议改用time.perf_counter()计算相对时间差,或者引入time.time_ns()。
坑3:JSON序列化遇到numpy类型。 工控采集数据里经常有numpy.float32、numpy.int64这类类型,直接json.dumps会报错。需要自定义一个JSONEncoder:
python1import numpy as np23class IndustrialJSONEncoder(json.JSONEncoder):4def default(self, obj):5if isinstance(obj, np.integer):6return int(obj)7if isinstance(obj, np.floating):8return float(obj)9if isinstance(obj, np.ndarray):10return obj.tolist()11return super().default(obj)1213# 使用时替换json.dumps的encoder参数14json.dumps(log_entry, cls=IndustrialJSONEncoder, ensure_ascii=False)
坑4:多进程场景下的Handler冲突。 如果你的系统是多进程架构(比如用multiprocessing跑多个设备采集进程),每个进程都有自己的FileHandler,同时写同一个文件会导致内容交错。标准解法是用QueueHandler + 独立的日志服务进程,或者每个进程写独
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
