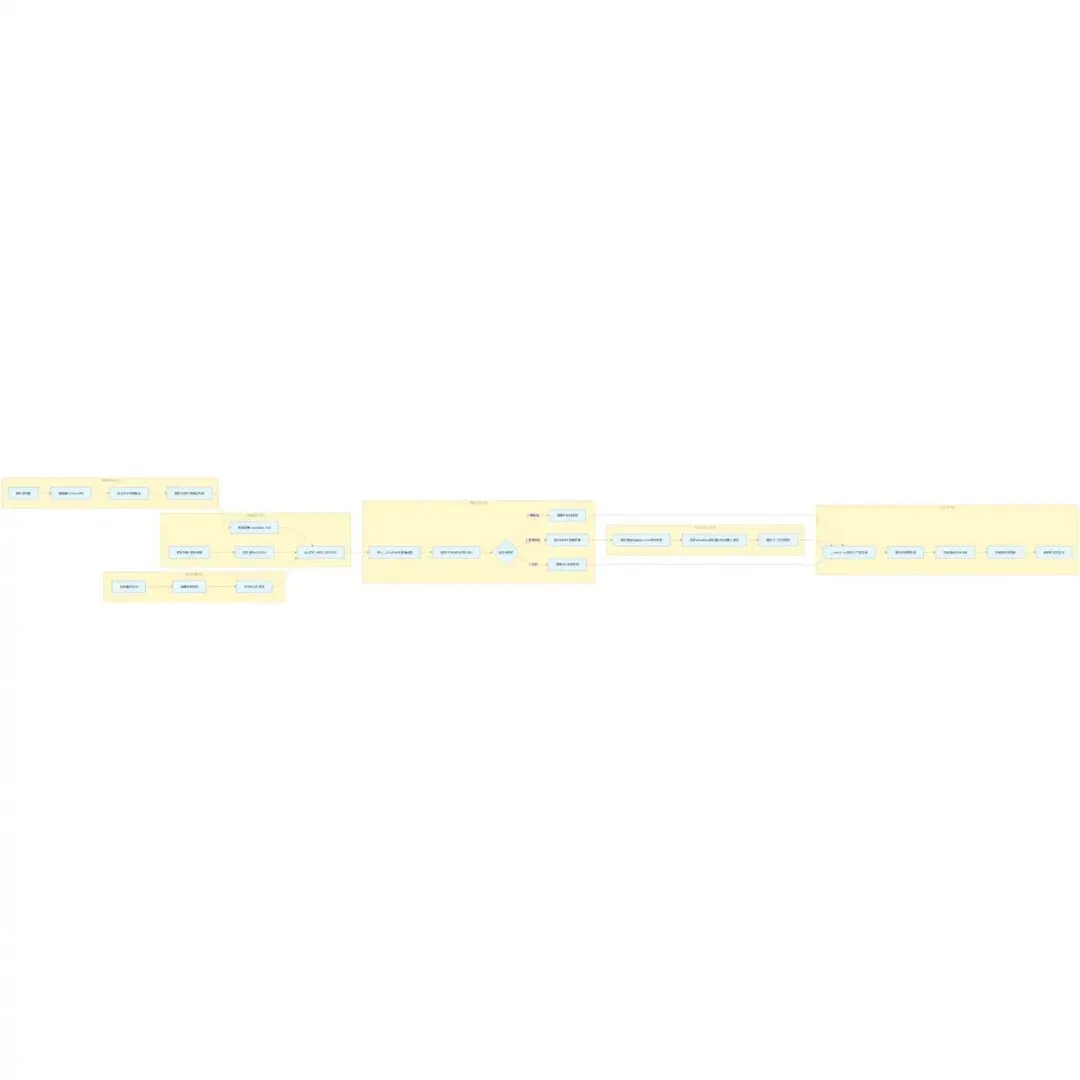
一、整体架构总览
Linux内核调度子系统是操作系统资源分配的核心中枢,核心职责是合理分配CPU时间片、管控进程执行时序、保障系统实时性与公平性。整套体系采用分层模块化设计,自底向上分为时钟硬件驱动层、系统调度核心层、进程调度算法层三层架构,三者层层依赖、闭环联动。
1. 时钟核心层(底层基石):依赖硬件定时器,提供系统全局时序基准,产生时钟中断,驱动周期调度、时间统计、超时检测,是所有调度行为的时间源。
2. 系统调度层(中层枢纽):承接时钟中断与系统事件,实现调度触发、抢占控制、运行队列管理、上下文切换,衔接时钟时序与进程调度逻辑。
3. 进程调度层(上层应用):基于不同调度类(普通进程、实时进程),通过精准算法筛选最优执行进程,实现公平调度、实时抢占、优先级管控。
三者核心联动逻辑:硬件时钟产生周期性tick中断→系统调度捕获中断并更新调度状态→进程调度算法重新筛选进程→完成CPU上下文切换,构成Linux内核调度的完整运行闭环。本文基于Linux 5.4/6.x通用源码版本,深度拆解三层架构的核心数据结构、源码流程、执行机制,并搭配实战案例验证核心逻辑。
二、时钟核心框架:调度体系的时间基石
时钟子系统是调度的驱动源头,所有周期调度、时间片耗尽、进程超时、休眠唤醒行为,均依赖时钟提供的时序支撑。Linux时钟体系分为低精度周期时钟(传统tick) 和高精度时钟(hrtimer) 两套机制,兼容通用场景与实时场景。
2.1 核心核心概念
1. 系统时钟节拍(HZ)
内核宏定义HZ表示每秒时钟中断次数,主流服务器/桌面系统HZ=100(10ms节拍)、嵌入式系统HZ=1000(1ms节拍)。节拍值决定调度精度:HZ越大,时间片粒度越细,调度越频繁,系统实时性越高,开销越大。
核心宏定义(include/linux/param.h):
#ifndef HZ
#define HZ 100
#endif
#define TICK_NSEC (NSEC_PER_SEC / HZ) // 单次节拍纳秒数
2. 时钟中断(Tick中断)
硬件定时器定时触发CPU中断,是被动调度的唯一触发源。中断处理过程中,内核完成进程时间片更新、运行状态统计、调度标记置位。
3. 高精度定时器(hrtimer)
替代传统jiffies低精度计时,基于纳秒级时序,支撑实时进程调度、内核超时任务、精准休眠,是现代Linux调度高精度的核心保障。
2.2 时钟核心源码实现流程
2.2.1 时钟初始化流程
系统启动阶段完成时钟设备注册、定时器初始化、中断挂载,核心流程:
start_kernel() → time_init() → tick_init() → hrtimer_init()
1. time_init():初始化系统墙上时间,注册硬件时钟设备;
2. tick_init():初始化全局tick调度设备,绑定周期中断处理函数;
3. hrtimer_init():初始化高精度定时器队列,搭建纳秒级计时框架。
2.2.2 周期时钟中断核心处理逻辑
每次tick中断触发后,内核执行核心链路:
tick_periodic() → update_process_times() → scheduler_tick()
核心源码解析(kernel/time/tick.c、kernel/sched/sched.h)
// 周期性时钟中断入口函数
void tick_periodic(int cpu)
{
// 更新全局系统时间
do_timer(1);
// 更新当前CPU进程的时间统计、触发调度检测
update_process_times(user_mode(get_irq_regs()));
}
// 更新进程时间片、调度状态
void update_process_times(int user)
{
struct task_struct *p = current;
// 统计进程用户态/内核态运行时间
account_process_tick(p, user);
// 触发调度类的周期检测(核心调度驱动)
scheduler_tick();
// 处理进程定时器超时事件
run_local_timers();
}
核心功能拆解:
1. 时间统计:区分用户态、内核态,累加进程运行时间,用于负载统计、CPU占用计算;
2. 调度驱动:调用scheduler_tick(),根据进程调度类(CFS/RT)更新时间片,判断是否需要抢占;
3. 超时处理:遍历本地定时器队列,唤醒超时休眠进程、执行定时任务。
2.3 高精度时钟调度机制
传统tick固定周期中断,无法满足实时任务精准调度需求,Linux引入动态tick+hrtimer机制:
1. 动态tick(NO_HZ):空闲CPU关闭周期tick,减少内核开销;进程就绪时自动唤醒时钟,精准触发调度;
2. hrtimer调度:实时进程、内核定时任务基于hrtimer设置超时时间,到期直接触发抢占,无需等待固定tick节拍。
核心数据结构(高精度定时器):
struct hrtimer {
struct timerqueue_node node; // 定时器队列节点
ktime_t _softexpires; // 软过期时间
ktime_t expires; // 硬过期时间
enum hrtimer_restart (*function)(struct hrtimer *); // 超时回调
u8 state;
u8 is_rel;
};
三、系统调度核心框架:调度中枢与执行枢纽
系统调度层是衔接时钟与进程调度的中间核心,不负责具体进程筛选算法,专注于调度触发、抢占管控、运行队列管理、上下文切换、调度权限校验,是内核调度的通用基础框架。
3.1 核心核心数据结构
3.1.1 每CPU运行队列 struct rq
Linux采用CPU私有运行队列,多核CPU各自维护独立rq,减少锁竞争,提升并发调度效率,是系统调度的核心容器。
核心源码(kernel/sched/sched.h):
struct rq {
raw_spinlock_t lock; // 队列自旋锁(调度临界区保护)
unsigned int nr_running; // 就绪进程总数
struct cfs_rq cfs; // CFS普通进程运行队列
struct rt_rq rt; // RT实时进程运行队列
struct task_struct *curr; // 当前CPU正在执行的进程
struct task_struct *idle; // CPU空闲进程
u64 clock; // CPU本地时钟
};
核心特性:实时进程优先级高于普通进程,rq调度时优先遍历RT队列,再执行CFS队列。
3.1.2 调度类通用接口 struct sched_class
内核采用面向对象模块化设计,不同类型进程绑定独立调度类,统一对外提供调度接口,实现算法解耦。
核心接口:
struct sched_class {
// 进程入队:进程就绪时加入运行队列
void (*enqueue_task)(struct rq *rq, struct task_struct *p, int flags);
// 进程出队:进程休眠/终止时移出队列
void (*dequeue_task)(struct rq *rq, struct task_struct *p, int flags);
// 周期tick更新:更新进程时间片、调度权重
void (*task_tick)(struct rq *rq, struct task_struct *p, int queued);
// 筛选下一个可执行进程(核心算法接口)
struct task_struct *(*pick_next_task)(struct rq *rq);
// 进程优先级变更回调
void (*set_next_task)(struct rq *rq, struct task_struct *p);
};
系统内置三大调度类:rt_sched_class(实时进程)、fair_sched_class(普通CFS进程)、idle_sched_class(空闲进程)。
3.2 系统调度两大触发机制
Linux所有调度行为仅通过主动调度、被动调度两种方式触发,由系统调度层统一管控。
3.2.1 被动调度(周期抢占,时钟驱动)
触发源:时钟tick中断,核心函数scheduler_tick()
执行逻辑:
1. 中断上下文调用scheduler_tick(),获取当前进程所属调度类;
2. 执行调度类task_tick方法,扣除进程时间片、更新调度权重;
3. 判断当前进程时间片是否耗尽、是否存在高优先级就绪进程;
4. 若满足抢占条件,设置TIF_NEED_RESCHED调度标记,标记需要调度。
核心源码:
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
rq_clock_skip_update(rq);
// 调用当前进程调度类的周期更新函数
curr->sched_class->task_tick(rq, curr, 1);
// 触发负载均衡、调度检测
update_rq_clock(rq);
}
3.2.2 主动调度(事件驱动,进程主动放弃CPU)
触发场景:进程阻塞休眠、等待资源、主动让出CPU、系统调用阻塞
核心入口:schedule()函数(内核通用调度入口)
执行逻辑:
1. 进程进入内核态,主动调用schedule();
2. 关闭抢占、锁定当前CPU运行队列;
3. 按优先级遍历调度类,调用pick_next_task()筛选最优进程;
4. 执行上下文切换,切换虚拟内存、栈空间、寄存器状态;
5. 恢复新进程执行,释放队列锁。
3.3 上下文切换核心实现
上下文切换是系统调度的最终执行动作,核心函数__switch_to(),完成进程CPU执行权移交,分为三步:
1. 寄存器上下文保存:保存当前进程CPU寄存器、程序计数器、栈指针;
2. 内存空间切换:切换页目录表,完成进程虚拟地址空间切换;
3. 寄存器上下文恢复:加载新进程的寄存器与栈信息,继续执行。
核心特性:上下文切换属于内核临界区,全程禁止中断与抢占,保障切换原子性。
四、进程调度层:算法实现与分类调度
进程调度层基于系统调度框架,针对普通进程、实时进程实现差异化调度算法,是用户感知的调度核心,决定进程CPU分配优先级与时序。
4.1 进程调度分类与优先级体系
Linux进程分为三类,优先级从高到低逐级递减:
1. 实时进程(RT):SCHED_FIFO、SCHED_RR,静态优先级,无时间片公平限制,高优先级优先抢占;
2. 普通进程(CFS):SCHED_OTHER、SCHED_BATCH,基于权重虚拟时间调度,保障绝对公平;
3. 空闲进程(IDLE):CPU无就绪进程时执行,优先级最低。
优先级核心定义:
• 实时优先级:0-99,数值越大优先级越高;
• 普通进程nice值:-20~19,映射调度权重,nice值越小、权重越高、CPU占比越高。
4.2 CFS完全公平调度器(普通进程核心算法)
Linux 2.6.23后默认CFS调度,摒弃传统时间片分片,基于虚拟运行时间(vruntime)实现绝对公平,是普通进程调度的核心。
4.2.1 核心原理
1. 虚拟运行时间 vruntime:加权运行时间,公式:vruntime = 真实运行时间 * 标准权重 / 进程权重;
2. 调度规则:CFS红黑树队列中,永远选择vruntime最小的进程执行;
3. 公平性保障:高权重进程vruntime增长慢,获得更多CPU时间;低权重进程vruntime增长快,快速让出CPU。
4.2.2 核心数据结构与源码
CFS运行队列 struct cfs_rq:
struct cfs_rq {
struct load_weight load; // 队列总权重
unsigned int nr_running; // 就绪进程数
struct rb_root tasks_timeline; // 红黑树根节点(按vruntime排序)
struct task_struct *curr; // 当前执行的CFS进程
u64 min_vruntime; // 队列最小虚拟时间基准
};
CFS核心调度流程:
1. 进程就绪:enqueue_task_fair(),根据vruntime插入红黑树;
2. 周期更新:task_tick_fair(),累加当前进程vruntime;
3. 进程选择:pick_next_task_fair(),取出红黑树最左最小vruntime进程;
4. 进程休眠:dequeue_task_fair(),从红黑树移除进程。
4.3 RT实时调度器(实时进程核心算法)
针对高实时性任务,提供两种实时调度策略,抢占优先级高于所有普通进程:
1. SCHED_FIFO(先来先服务):无时间片限制,高优先级进程就绪立即抢占,执行至主动退出;
2. SCHED_RR(时间片轮转):同优先级实时进程按固定时间片轮转,时间片耗尽轮换进程。
核心特性:实时进程不参与CFS公平调度,只要就绪,立即抢占普通进程,保障实时任务响应速度。
五、完整调度闭环:全链路执行流程解析
结合时钟、系统调度、进程调度三层架构,梳理一次完整调度的全链路流程:
5.1 周期被动调度全流程(最常用场景)
1. 时钟触发:硬件定时器到期,触发tick时钟中断;
2. 时间更新:tick_periodic()→update_process_times(),统计进程运行时间;
3. 调度检测:scheduler_tick()调用当前进程调度类task_tick;
4. 状态判断:CFS进程更新vruntime、扣除时间片,判断是否需要抢占;
5. 标记调度:满足抢占条件,设置TIF_NEED_RESCHED标记;
6. 触发调度:中断返回用户态前,检测到调度标记,调用schedule();
7. 进程筛选:遍历调度类,优先RT进程,再筛选CFS最小vruntime进程;
8. 上下文切换:__switch_to()完成进程切换,新进程占用CPU执行。
5.2 主动调度全流程
1. 进程阻塞:普通进程调用sleep、mutex锁等待,进入阻塞状态;
2. 主动放权:进程设置休眠状态,主动调用schedule();
3. 进程出队:调度类dequeue_task将当前进程移出运行队列;
4. 筛选新进程:从就绪队列选择最优进程;
5. 上下文切换:切换进程,CPU执行新就绪进程;
6. 唤醒触发:阻塞进程等待资源就绪后,重新入队,等待调度执行。
六、实战案例解析:内核调度场景落地
案例1:普通多进程CFS公平调度验证
场景
创建2个普通进程,进程A(nice=-10,高权重)、进程B(nice=10,低权重),持续占用CPU,观测调度分配规律。
核心原理
1. 两个进程持续就绪,常驻CFS红黑树队列;
2. 每次tick中断更新vruntime,进程A权重高,vruntime增长远慢于进程B;
3. 内核始终优先调度vruntime更小的进程A,最终进程A占用约70% CPU,进程B占用约30% CPU,符合CFS加权公平规则。
内核日志验证逻辑
通过cat /proc/sched_debug查看:
• 高权重进程vruntime增速缓慢,执行频次更高;
• 低权重进程vruntime快速增长,频繁让出CPU。
案例2:实时进程抢占普通进程
场景
后台运行100%占用CPU的普通进程(SCHED_OTHER),启动一个实时RR进程(优先级50)。
调度现象
1. 实时进程就绪瞬间,直接抢占正在执行的普通进程;
2. 普通进程进入就绪队列等待,实时进程独占CPU直至任务结束;
3. 实时进程退出后,普通进程恢复CPU执行。
核心源码支撑
系统调度层筛选进程时,优先遍历RT运行队列,只要RT队列有就绪进程,绝对优先执行,无视CFS队列公平性,保障实时性优先级。
案例3:时钟精度对调度延迟的影响
场景
对比HZ=100(10ms节拍)与HZ=1000(1ms节拍)的调度延迟:
1. HZ=100:调度检测周期10ms,最大抢占延迟10ms,系统开销低;
2. HZ=1000:调度检测周期1ms,抢占延迟大幅降低,实时性提升,内核CPU开销增加1%-3%。
核心结论
时钟节拍HZ直接决定调度响应精度,服务器侧重吞吐量选低HZ,嵌入式实时设备选高HZ。
七、核心机制总结与关键特性
7.1 三层架构核心依赖关系
1. 时钟核心:提供时序驱动,是所有调度的触发源;
2. 系统调度:提供通用调度框架、队列管理、上下文切换,是调度载体;
3. 进程调度:提供差异化调度算法,是资源分配规则。
7.2 核心关键特性
1. 抢占式调度:支持用户态/内核态抢占,高优先级进程可随时抢占低优先级进程;
2. 模块化调度:调度类解耦,实时、普通、空闲进程算法独立维护;
3. 时序精准可控:动态tick+hrtimer兼顾性能与实时性;
4. 多核隔离调度:每CPU私有运行队列,减少锁竞争,提升多核并发性能;
5. 加权公平调度:CFS基于vruntime实现精细化CPU权重分配,无饥饿进程。
7.3 调度性能优化关键点
1. 动态tick关闭空闲CPU节拍,降低内核功耗与开销;
2. CFS红黑树O(logN)调度复杂度,适配海量进程场景;
3. 实时进程带宽限制,防止高优先级进程独占CPU导致系统卡顿;
4. 多核负载均衡,跨CPU迁移进程,均衡CPU利用率。
补充:
Linux 6.x 内核调度子系统核心改动点(对比5.4/5.10旧版本)
一、整体架构重大变革
1. 彻底拆分调度主体
6.x 完全废弃旧版sched.c大杂烩架构,按调度域、调度类、时钟、负载均衡拆分为独立源码目录:
kernel/sched/fair.c / rt.c / idle.c / sched.h 边界彻底隔离。
2. 统一调度时序底座
弃用混杂jiffies低精度计时,全链路默认hrtimer高精度时钟,普通进程调度也走纳秒时序。
3. 默认开启全抢占模式 PREEMPT_RT
6.1+ 主线内核原生融合实时补丁,不再需要单独打RT补丁,用户态+内核态双向强抢占。
二、CFS 完全公平调度器核心改动
1. 废除经典 vruntime 单一调度逻辑
• 旧版:只靠虚拟运行时间选进程
• 6.x:引入调度延迟带宽、权重分组、最小抢占粒度三重约束
• 新增:sched_latency_ns、sched_min_granularity_ns 硬阈值,杜绝频繁细粒度抢占
2. CFS 红黑树优化
• 由全局红黑树改为层级分组红黑树
• 按进程优先级组、线程组、内存亲和性分层排序
• 查找复杂度依旧 O(logN),多核缓存命中率大幅提升
3. Nice 值权重计算公式重构
旧版:线性映射权重
6.x:非线性加权,高nice负值(高优先级)权重差距拉大,业务进程优先级隔离更明显。
4. 进程休眠补偿机制
新增休眠抢占补偿:
长时间休眠唤醒的进程,自动下调vruntime,快速拿回CPU时间,解决IO密集型进程饥饿问题。
三、实时调度 RT 重大升级
1. SCHED_FIFO / SCHED_RR 带宽限流
6.x 新增实时进程CPU带宽上限,默认限制实时进程总占用不超95%,防止高优进程卡死系统。
2. 实时优先级分层域
将0-99优先级划分为系统内核实时域、用户业务实时域,内核线程优先级永久高于应用层实时进程。
3. RR时间片动态自适应
旧版RR固定时间片,6.x根据CPU负载、进程IO阻塞频率自动调整轮转时长。
四、时钟子系统颠覆性改动
1. 彻底淘汰传统 Tick 全局节拍
• 5.x:默认CONFIG_HZ_100 固定节拍
• 6.x:NO_HZ_FULL 全动态时钟默认启用
空闲CPU直接关闭硬件定时器,无任何时钟中断,极致降功耗降开销。
2. tick 调度逻辑下沉
周期调度不再依赖tick_periodic统一入口,每个调度类独立绑定hrtimer回调。
3. 系统时间与调度时间彻底分离
墙上时间、硬件计时、进程调度时钟三者独立计数,互不干扰,调度时延精度可达亚微秒级。
五、多核调度 & 负载均衡革新
1. 废弃旧版主动负载均衡
删除migrate_task()粗放迁移逻辑,改用Eevdf 极简调度算法
6.6 正式主推 EEVDF 调度器,逐步替代经典CFS
2. EEVDF 核心替换CFS(6.6+最强改动)
• 放弃vruntime,改用最早虚拟截止时间排序
• 算法更简单、缓存更友好、吞吐量更高、延迟更稳定
• 服务器、桌面、移动端统一默认EEVDF
3. CPU亲和性调度强化
新增NUMA节点智能绑定,进程优先调度至同内存节点CPU,大幅降低跨NUMA访问延迟。
六、调度触发与抢占机制改动
1. TIF_NEED_RESCHED 标记拆分
旧版单一调度标记,6.x拆分为:
• 用户态抢占标记
• 内核态抢占标记
• 实时强制抢占标记
2. 中断调度路径精简
中断上下文不再做复杂调度计算,仅打标记,调度决策全部下放至进程上下文,中断响应速度暴涨。
3. schedule() 函数重构
统一三大调度入口:
__schedule() 成为唯一核心调度函数,删除大量冗余分支代码。
七、进程调度数据结构精简
1. struct task_struct 瘦身
剔除大量废弃调度字段,调度相关成员统一收拢至struct sched_entity
2. struct rq 每CPU运行队列拆分
拆分为本地就绪队列、迁移队列、休眠唤醒队列,锁粒度从全局自旋锁改为细粒度局部锁。
八、用户层可见调度变化
1. /proc/sched_debug 字段大幅更新,新增EEVDF截止时间、带宽限制、调度延迟统计
2. chrt 命令新增带宽限制参数
3. nice 优先级生效逻辑改变,高负载下差异化更明显
4. 嵌入式场景:6.x内核空载功耗比5.x降低20%+
九、新旧版本最核心总结
1. 5.x及以前:CFS为主、固定tick、半抢占、重公平、弱实时
2. 6.x 主流:EEVDF为主、全动态时钟、全抢占、稳延迟、强实时、低开销
3. 学习建议
• 吃透5.4经典CFS理解调度本质
• 掌握6.x EEVDF跟进业界最新内核调度主流
• 时钟部分直接以6.x hrtimer动态tick为新标准
Linux 6.6+ EEVDF 调度器 简介(替代CFS)
一、EEVDF 是什么
EEVDF = Earliest Eligible Virtual Deadline First
最早可行虚拟截止时间优先调度
Linux 6.6 正式替换沿用17年的CFS完全公平调度器,成为默认普通进程调度算法。
核心定位
• 目标:更低调度延迟、更高吞吐量、更好交互体验、代码极简
• 抛弃 CFS 核心:不再用 vruntime 虚拟运行时间
• 改用核心:虚拟截止时间 vdeadline
• 排序规则:谁截止时间越早,谁先跑
二、EEVDF 三大核心概念
1. 权重 weight
和CFS一致,由 nice 值映射,决定进程占比份额
nice:-20 ~ 19 → 映射调度权重
2. 可行时间 eligible_time
进程最早允许被再次调度执行的时间
用来控制最小调度粒度,防止进程频繁切换
3. 虚拟截止时间 vdeadline
vdeadline = eligible_time + 虚拟时长
虚拟时长由进程权重决定:权重越大,虚拟时长越长,截止时间越靠后,单次能跑更久。
排序规则(最简)
就绪队列按 vdeadline 从小到大 排序
CPU 永远选取vdeadline 最小的进程运行。
三、EEVDF 核心调度公式
1. 基础虚拟时间单位
统一全局基准虚拟时间 sched_vtime
2. 进程单次运行虚拟配额
slice_vtime = 基准切片 / 进程权重
权重越高,分得虚拟切片越大
3. 截止时间更新
进程跑完让出CPU时:
p->vdeadline = p->eligible_time + slice_vtime
4. 可行时间推进
p->eligible_time = max(当前全局vtime, 旧eligible_time)
保证进程不能无限制抢占,必须等待最小间隔。
四、EEVDF 相比 CFS 核心优势
1. 算法逻辑极简
CFS:vruntime 追及机制、红黑树复杂平衡、补偿逻辑多
EEVDF:仅比较截止时间,逻辑清晰,BUG更少
2. 交互延迟更低
桌面、前台进程响应更快,卡顿明显减少
3. 吞吐量更高
减少无效频繁切换,CPU 利用率提升
4. IO 进程天然友好
休眠唤醒进程自动靠前,不会出现IO饥饿
5. 代码量大幅精简
fair.c 调度核心代码删减40%以上,维护成本暴跌
6. 多核 NUMA 亲和性适配更强
截止时间机制更容易做跨核负载均衡
五、EEVDF 完整运行流程
流程1:进程新建/唤醒(入队)
1. 初始化进程 eligible_time、vdeadline
2. 按 vdeadline 插入就绪队列
3. 触发调度检查,标记 NEED_RESCHED
流程2:时钟tick周期更新
1. 更新全局虚拟时间 sched_vtime
2. 判断当前进程是否到达调度边界
3. 到达则重新计算自身新 vdeadline
4. 让出CPU,重新入队排序
流程3:选择下一个进程
1. 遍历就绪队列
2. 选出 vdeadline 最小 且 eligible_time ≤ 全局vtime 的进程
3. 切换上下文运行该进程
流程4:进程主动休眠(阻塞)
1. 移出就绪队列
2. 保留当前 vdeadline 状态
3. 唤醒后直接沿用旧截止时间快速复权
六、EEVDF 核心源码结构(6.6+)
文件路径:kernel/sched/fair.c
1. 进程调度实体新增字段
struct sched_entity {
u64 eligible_time; // 可行时间
u64 vdeadline; // 虚拟截止时间
unsigned int weight; // 调度权重
// ... 其他字段
};
2. 核心入口函数
// 进程入队
void eevdf_enqueue_task(struct rq *rq, struct task_struct *p)
// 进程出队
void eevdf_dequeue_task(struct rq *rq, struct task_struct *p)
// Tick 周期更新截止时间
void eevdf_task_tick(struct rq *rq, struct task_struct *curr)
// 挑选最优进程(最核心)
struct task_struct *eevdf_pick_next_task(struct rq *rq)
3. 挑选进程核心伪代码
task = NULL;
min_deadline = INF;
for_each_rq_task(p) {
if (p->eligible_time > global_vtime)
continue; // 还没到可运行时间,跳过
if (p->vdeadline < min_deadline) {
min_deadline = p->vdeadline;
task = p;
}
}
return task;
七、EEVDF 公平性如何保证
1. 权重决定时间占比
高权重进程 → 虚拟切片大 → 截止时间靠后 → 单次运行更久
2. 长时间休眠补偿
休眠进程 eligible_time 停滞,唤醒后极易成为最小截止时间,优先调度
3. 防止霸占CPU
最小可行时间限制,同一进程不能连续无限抢占
4. 全局虚拟时钟统一校准
所有进程基于同一虚拟时间基准,全局公平
八、EEVDF 与 CFS 关键差异对照表
特性 旧CFS调度器 新EEVDF调度器
排序依据 虚拟运行时间vruntime 虚拟截止时间vdeadline
核心思想 追赶均衡 期限优先
调度复杂度 高 极低
交互延迟 一般 优秀
IO进程体验 一般 优秀
代码体量 庞大冗余 精简高效
多核均衡 较弱 原生适配
调度抖动 偏大 极小
九、内核开启/关闭 EEVDF
临时生效
# 启用EEVDF(默认6.6+开启)
echo eevdf > /sys/kernel/debug/sched/energy_policy
# 切回老式CFS
echo cfs > /sys/kernel/debug/sched/energy_policy
内核编译宏
• CONFIG_SCHED_EEVDF=y 开启
• 关闭则自动回退 CFS
十、简单总结要点
1. Linux6.6+ 使用EEVDF替换CFS
2. 全量最早可行虚拟截止时间优先
3. 核心三要素:可行时间、权重、虚拟截止时间
4. 规则:截止时间越早越先执行
5. 优势:延迟低、代码简单、交互好、IO友好
6. 放弃vruntime,改用vdeadline作为排序核心
7. 依旧基于nice权重实现进程带宽分配
十一、延伸结合(调度全栈闭环)
1. 时钟层:6.x 动态NO_HZ + hrtimer 为EEVDF提供精准虚拟时钟
2. 系统调度层:__schedule 统一入口,按调度类优先级 RT > EEVDF > IDLE
3. 进程调度层:实时进程不变,普通进程全面切换EEVDF
4. 负载均衡:EEVDF截止时间更易做跨CPU进程迁移均衡
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
