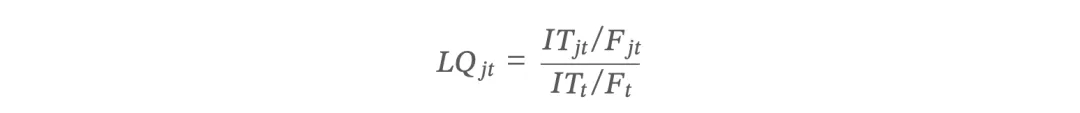由于借助 AI 工具学习编程已经变得非常容易了,因此之后的课程就不再默认进行视频讲解了,如果特别需要视频讲解也可以联系李老师预约讲解~讲义材料学习过程中遇到的问题也可以及时与李老师联系。
购买 RStata 名师讲堂会员即可参加该课程啦(之前的和未来的都可以参加)!
价格:2800/年 或者 4800/长期
购买会员可以从这里下单:https://rstata.duanshu.com/#/card/list/
名师讲堂会员权益:
- 参加平台上的其他 R 语言和 Stata 的课程;
- 以会员折扣价购买我们分享的数据资料(10 元/份);
* 如果发票可添加小编微信 r_stata2 (RStata 李老师)开具。如需数据资料,购买后可添加小编微信免费领取数据折扣卡。
更多关于 RStata 会员的更多信息可添加微信号 r_stata2 咨询:

课程主页(点击文末的阅读原文即可跳转):https://rstata.duanshu.com/#/brief/course/edab8a934b5f415a9fda38d80a326842
今天给大家分享使用 Python 测算各城市虚拟集聚度的方法。该方法参考自宋林等《虚拟集聚与城市经济韧性》,通过结合区位熵和空间距离权重来综合测度城市的虚拟集聚水平。
附件中提供了该参考文献的 PDF 文件,感兴趣的小伙伴可以阅读原文。
指标来源与计算原理
虚拟集聚度(Virtual Agglomeration)
虚拟集聚度是衡量城市在数字经济领域集聚程度的重要指标。与传统的地理集聚不同,虚拟集聚强调通过信息技术实现的空间联系和资源共享,反映了城市在信息传输、软件和信息技术服务业领域的相对优势。
虚拟集聚度的计算公式为:
区位熵(Location Quotient)
公式中方括号内的部分即为区位熵:
区位熵衡量某城市 IT 行业的专业化程度相对于全国的水平:
- 区位熵 > 1:该城市 IT 行业集聚度高于全国平均水平
距离权重
计算步骤概述
整个计算过程分为以下几个步骤:
- 存续企业计算:通过累计新增减去累计注销得到各城市各行业的存续企业数
- IT 行业筛选:提取"信息传输、软件和信息技术服务业"企业数据
- 距离矩阵计算:使用
geopandas 计算城市间的地理距离
使用 reticulate 创建与管理 Python 虚拟环境
在 R 中通过 reticulate 包来调用 Python,最好的实践是为项目创建一个专属的 Python 虚拟环境,将所需依赖隔离到独立空间,避免与系统 Python(如 Anaconda)发生版本冲突。
重要说明(避免"已初始化"报错):reticulate 在 R 会话中只能绑定一次 Python——一旦某个 {python} 代码块运行,Python 解释器就被锁定,之后再调用 use_virtualenv() 会报错:
ERROR: The requested version of Python cannot be used, as another version has already been initialized.因此,虚拟环境的激活必须在所有 {python} 代码块之前完成。本文档的解决方案是在 setup chunk 中通过 Sys.setenv(RETICULATE_PYTHON = ...) 提前锁定 Python 路径,这是 reticulate 选取 Python 的最高优先级入口。
安装 reticulate(仅首次)
# 设置 CRAN 镜像(knit 时 R 处于非交互模式,不会自动选择镜像)options(repos = c(CRAN = "https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))# 仅在尚未安装时才安装,避免每次 knit 都重装if (!requireNamespace("reticulate", quietly = TRUE)) { install.packages("reticulate") message("reticulate 安装完成!") message("reticulate 已安装,版本:", packageVersion("reticulate"))虚拟环境初始化原理(已在 setup chunk 中完成)
本文档的 setup chunk(隐藏运行)包含如下逻辑:
.venv_python <- virtualenv_python(.venv_name)if(!file.exists(.venv_python)){ virtualenv_create(.venv_name) .venv_python <- virtualenv_python(.venv_name)# 通过环境变量抢先锁定 Python(优先级最高,早于任何 {python} chunk)Sys.setenv(RETICULATE_PYTHON = .venv_python)use_virtualenv(.venv_name, required =TRUE)这样做的关键在于:knitr 在处理第一个 {python} chunk 时,reticulate 已经通过 RETICULATE_PYTHON 环境变量知道要使用 .venv,不会再去碰 Anaconda。
在虚拟环境中安装 Python 包(仅首次)
"numpy", "pandas", "geopandas", "shapely", "matplotlib"installed <- py_list_packages(".venv")$packageneed_install <- setdiff(py_pkgs, installed)if (length(need_install) > 0) { virtualenv_install(".venv", packages = need_install) message("已安装缺失的包:", paste(need_install, collapse = ", ")) message("所有 Python 包已就绪,无需安装")验证激活状态
# 验证当前绑定的 Python 路径(应指向 .venv 目录)查看已安装的包
pkgs <- py_list_packages(".venv")key_pkgs <- c("numpy", "pandas", "geopandas", "shapely", "matplotlib")pkgs[pkgs$package %in% key_pkgs, c("package", "version")]虚拟环境管理常用命令
# virtualenv_remove(".venv")# virtualenv_install(".venv", packages = "geopandas", ignore_installed = TRUE)
详细计算代码
数据读取
读取新增企业和注销企业数据:
# dtype=str:全部读为字符串,与 R 的 cols(.default = "c") 一致# 不设 keep_default_na=False,让空字符串自动转为 NaN(与 R 的 read_csv 默认行为一致)new_firms = pd.read_csv("新增企业数量.csv", dtype=str)print(f"新增数据: {len(new_firms)} 行")closed_firms = pd.read_csv("注销公司数量.csv", dtype=str)print(f"注销数据: {len(closed_firms)} 行")数据说明:
新增企业数量.csv:包含各城市各行业每年的新增注册企业数量注销公司数量.csv:包含各城市各行业每年的注销企业数量
上面代码中读取的两个 csv 文件分别来源于平台上的工商注册信息和注销信息:
use"1949~2023年各省市区县、行业新增企业数量统计.dta", clearexport delimited using "新增企业数量.csv", replaceuse"1970~2023年各年各省市区县、各行业注销公司数量面板数据.dta", clearexport delimited using "注销公司数量.csv", replace数据预处理——计算累计存续企业
计算每个城市各行业的累计存续企业数,需要考虑企业的进入(新增)和退出(注销):
new_firms_valid = new_firms.dropna(subset=["成立年份"]).copy()new_firms_valid["年份"] = new_firms_valid["成立年份"].astype(int)new_firms_valid["新增注册企业数量"] = pd.to_numeric( new_firms_valid["新增注册企业数量"], errors="coerce"# dropna=False:与 R 的 group_by 一致,将 NaN 作为一个分组 .groupby(["年份", "省份", "城市", "行业门类"], dropna=False) .agg(新增数量=("新增注册企业数量", "sum"))new_summary = new_summary.sort_values(["省份", "城市", "行业门类", "年份"])new_summary["累计新增"] = new_summary.groupby( ["省份", "城市", "行业门类"], dropna=Falseprint(f"新增汇总: {len(new_summary)} 行")closed_firms_valid = closed_firms.dropna(subset=["注销年份"]).copy()closed_firms_valid["年份"] = closed_firms_valid["注销年份"].astype(int)closed_firms_valid["注销数量"] = pd.to_numeric( closed_firms_valid["注销数量"], errors="coerce" .groupby(["年份", "省份", "城市", "行业门类"], dropna=False) .agg(注销数量=("注销数量", "sum"))closed_summary = closed_summary.sort_values(["省份", "城市", "行业门类", "年份"])closed_summary["累计注销"] = closed_summary.groupby( ["省份", "城市", "行业门类"], dropna=Falseprint(f"注销汇总: {len(closed_summary)} 行")关键函数说明:
cumsum():计算累计和,等价于 R 的 cumsum()groupby(dropna=False):将 NaN 作为一个分组,与 R 的 group_by 默认行为一致sort_values():按指定变量排序,等价于 R 的 arrange()
合并计算存续企业数
将新增和注销数据合并,计算最终的存续企业数量:
firms = new_summary.merge( closed_summary[["年份", "省份", "城市", "行业门类", "累计注销"]], on=["年份", "省份", "城市", "行业门类"],# fillna(0):等价于 R 的 coalesce(累计新增, 0)# np.maximum():等价于 R 的 pmax(),确保存续数量不为负数firms["累计新增"] = firms["累计新增"].fillna(0)firms["累计注销"] = firms["累计注销"].fillna(0)firms["存续数量"] = np.maximum(firms["累计新增"] - firms["累计注销"], 0)firms["年份"] = firms["年份"].astype(int)print(f"合并后数据: {len(firms)} 行, 年份范围: {int(firms['年份'].min())}-{int(firms['年份'].max())}")关键函数对照:
| | |
|---|
full_join() | merge(how="outer") | |
coalesce(x, 0) | fillna(0) | |
pmax(x, 0) | np.maximum(x, 0) | |
筛选 IT 行业并汇总
提取"信息传输、软件和信息技术服务业"数据,并按城市-年份汇总:
it_sector = "信息传输、软件和信息技术服务业"# dropna=False:与 R 的 group_by 一致,保留城市为 NaN 的行city_total = firms.groupby(["年份", "城市"], dropna=False)["存续数量"].sum().reset_index()city_total.columns = ["年份", "城市", "总企业数"]city_it = firms[firms["行业门类"] == it_sector].groupby( ["年份", "城市"], dropna=False)["存续数量"].sum().reset_index()city_it.columns = ["年份", "城市", "IT企业数"]city_data = city_total.merge(city_it, on=["年份", "城市"], how="left")city_data["IT企业数"] = city_data["IT企业数"].fillna(0)city_data = city_data[city_data["总企业数"] > 0]print(f"城市年度数据: {len(city_data)} 行, "f"城市数: {city_data['城市'].nunique()}, "f"年份数: {city_data['年份'].nunique()}")计算区位熵
区位熵衡量某城市 IT 行业的专业化程度相对于全国的水平:
区位熵解读:
- 区位熵 > 1:该城市 IT 行业集聚度高于全国平均水平
计算城市间距离矩阵
使用 geopandas 读取行政区划数据,计算城市质心间的距离:
shp_path = "2021行政区划/市.shp"shp = gpd.read_file(shp_path, encoding="utf-8")print(f"shp 数据: {len(shp)} 行")shp_centroid = shp.copy()shp_centroid["geometry"] = shp_centroid.geometry.centroidshp_centroid["城市"] = shp_centroid["市"]cities_in_data = set(city_data["城市"].unique())cities_in_shp = set(shp_centroid["城市"].unique())cities = sorted(cities_in_data & cities_in_shp)print(f"共同城市数: {len(cities)}")shp_common = shp_centroid[shp_centroid["城市"].isin(cities)].copy()shp_common = shp_common.set_index("城市").loc[cities].reset_index()接下来使用 haversine 公式计算城市间距离,与 R 的 sf::st_distance 测地距离结果高度一致:
from math import radians, sin, cos, sqrt, atan2defhaversine(lon1, lat1, lon2, lat2):"""计算两点间的 haversine 距离(公里)""" dlat = radians(lat2 - lat1) dlon = radians(lon2 - lon1) a = sin(dlat / 2) ** 2 + cos(radians(lat1)) * cos(radians(lat2)) * sin(dlon / 2) ** 2 c = 2 * atan2(sqrt(a), sqrt(1 - a))for _, row in shp_common.iterrows(): centroids[row["城市"]] = (point.x, point.y) # (lon, lat)dist_matrix = np.zeros((n, n)) lon1, lat1 = centroids[city_list[i]] lon2, lat2 = centroids[city_list[j]] dist_matrix[i, j] = haversine(lon1, lat1, lon2, lat2)# 计算距离倒数(对角线设为1,避免除以0,与 R 代码一致)with np.errstate(divide='ignore'): dist_inv_matrix = 1.0 / dist_matrixdist_inv_matrix[np.isinf(dist_inv_matrix)] = 1.0city_to_idx = {c: i for i, c inenumerate(city_list)}print(f"距离矩阵维度: {n} x {n}")距离计算说明:
- R 使用
sf::st_distance() 在 WGS84 坐标系下计算测地距离(geodesic distance) - Python 使用 haversine 公式计算大圆距离,两者结果高度一致
计算虚拟集聚度
结合区位熵和距离权重,计算每个城市的虚拟集聚度:
合并结果并保存
final_result = city_data.merge(vag_results, on=["年份", "城市"], how="left")final_result.to_csv("城市虚拟集聚度结果_python.csv", index=False)print("结果已保存到: 城市虚拟集聚度结果_python.csv")结果概览
summary = final_result.sort_values(["年份", "虚拟集聚度"], ascending=[False, False])print(summary[["年份", "城市", "总企业数", "IT企业数", "区位熵", "虚拟集聚度"]].head(20).to_string(index=False))print("\n=== 近5年 Top 10 ===")recent = final_result[final_result["年份"] >= 2019].copy()for year insorted(recent["年份"].unique(), reverse=True): yr = recent[recent["年份"] == year].nlargest(10, "虚拟集聚度")print(f"\n--- {year}年 Top 10 ---")print(yr[["城市", "总企业数", "IT企业数", "区位熵", "虚拟集聚度"]].to_string(index=False))
数据可视化
这部分使用 Python 的 matplotlib + geopandas 进行地图绘制,字体使用附件中的 LXGWWenKai-Regular.ttf。
使用 R 语言绘制地图课程汇总索引: https://mp.weixin.qq.com/s/lYyVFUzKWkzyBFRAInoZFg
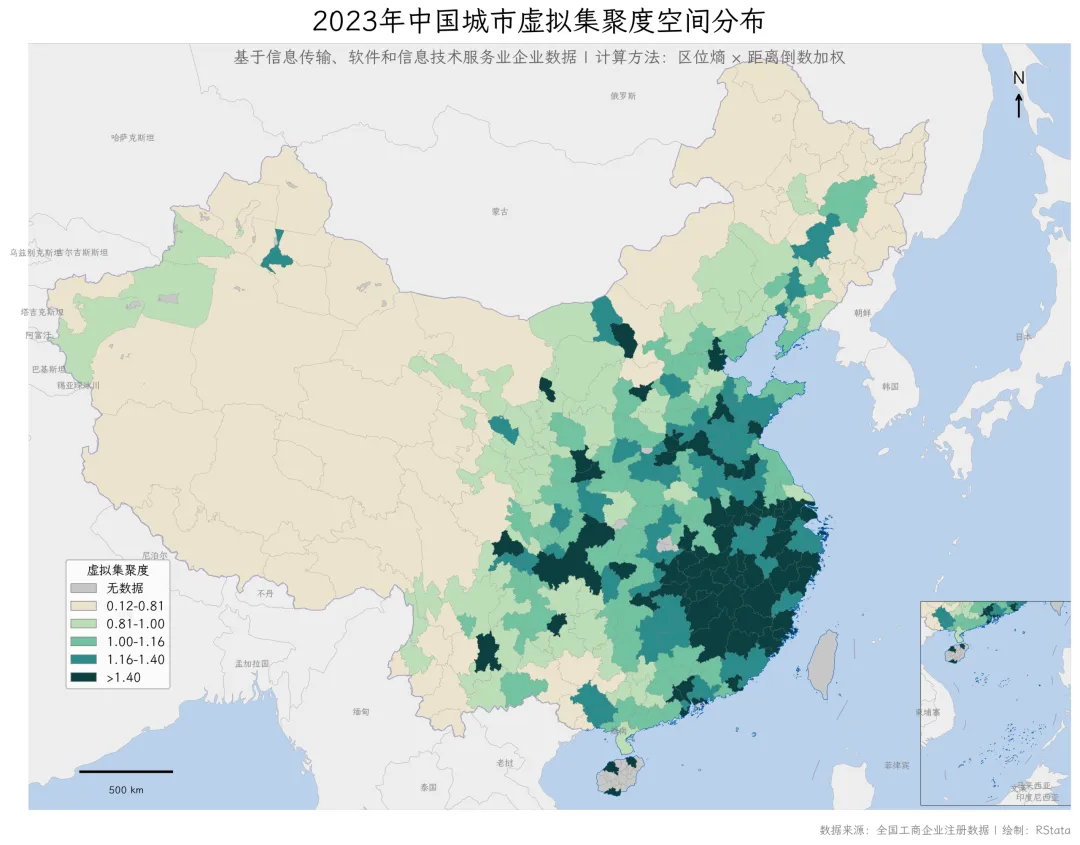
空间分布地图绘制
读取地图数据并合并
import matplotlib.pyplot as pltimport matplotlib.font_manager as fmfrom matplotlib.patches import FancyArrowPatchimport matplotlib.patches as mpatchesfrom matplotlib.colors import ListedColormapfont_path = "LXGWWenKai-Regular.ttf"cnfont = fm.FontProperties(fname=font_path)fm.fontManager.addfont(font_path)font_name = fm.FontProperties(fname=font_path).get_name()plt.rcParams['font.family'] = font_nameplt.rcParams['axes.unicode_minus'] = Falsevag_data = pd.read_csv("城市虚拟集聚度结果_python.csv")vag_2023 = vag_data[vag_data["年份"] == 2023][["城市", "虚拟集聚度", "区位熵", "IT企业数", "总企业数"]].copy()citymap = gpd.read_file("mapdata/chinacity2021mini/chinacity2021mini.shp", encoding="utf-8")citymap = citymap[citymap["省代码"].notna()].copy()linemap = gpd.read_file("mapdata/chinacity2021mini/chinacity2021mini_line.shp", encoding="utf-8")line_filtered = linemap[linemap["class"].isin(["九段线", "海岸线", "小地图框格"])].copy()neighboring = gpd.read_file("mapdata/china_neighboring/china_neighboring.shp", encoding="utf-8")citymap_data = citymap.merge(vag_2023, left_on="市", right_on="城市", how="left")citymap_data["虚拟集聚度"] = citymap_data["虚拟集聚度"].fillna(0)数据分组处理
vag_values = citymap_data.loc[citymap_data["虚拟集聚度"] > 0, "虚拟集聚度"]breaks = vag_values.quantile([0, 0.2, 0.4, 0.6, 0.8, 1.0]).valuesreturnf"{breaks[0]:.2f}-{breaks[1]:.2f}"returnf"{breaks[1]:.2f}-{breaks[2]:.2f}"returnf"{breaks[2]:.2f}-{breaks[3]:.2f}"returnf"{breaks[3]:.2f}-{breaks[4]:.2f}"returnf">{breaks[4]:.2f}"citymap_data["vag_group"] = citymap_data["虚拟集聚度"].apply(classify_vag)f"{breaks[0]:.2f}-{breaks[1]:.2f}",f"{breaks[1]:.2f}-{breaks[2]:.2f}",f"{breaks[2]:.2f}-{breaks[3]:.2f}",f"{breaks[3]:.2f}-{breaks[4]:.2f}",# 配色方案:与 R 的 scico "lipari" 调色板对应color_map = dict(zip(group_levels, colors_lipari))绘制地图
历年趋势折线图
vag_trend = vag_data[(vag_data["年份"] >= 1990) & (vag_data["年份"] <= 2023)][["城市", "年份", "虚拟集聚度"]].copy()fig, ax = plt.subplots(figsize=(12, 7))for city, grp in vag_trend.groupby("城市"):if city notin municipalities: ax.plot(grp["年份"], grp["虚拟集聚度"], color="#CCCCCC", alpha=0.3, linewidth=0.4)for city, color in municipalities.items(): city_data = vag_trend[vag_trend["城市"] == city] ax.plot(city_data["年份"], city_data["虚拟集聚度"], color=color, linewidth=0.8, alpha=0.7, label=city) last = city_data.sort_values("年份").iloc[-1] ax.text(last["年份"] + 0.5, last["虚拟集聚度"], city, fontsize=10, fontproperties=cnfont, color=color, va="center")ax.set_xticks(list(range(1990, 2025, 5)) + [2023])ax.set_yticks([i * 0.5for i inrange(0, 9)])fig.text(0.5, 0.97, "1990-2023年中国城市虚拟集聚度变化趋势", fontsize=20, fontweight="bold", fontproperties=cnfont,fig.text(0.5, 0.935, "突出显示四个直辖市 | 其他城市以灰色显示", fontsize=13, color="#666666", fontproperties=cnfont,ax.set_ylabel("虚拟集聚度", fontsize=12, fontproperties=cnfont)ax.text(1.0, -0.06, "数据来源:全国工商企业注册数据 | 绘制:RStata", transform=ax.transAxes, fontsize=9, color="#808080", ha="right", va="top", fontproperties=cnfont)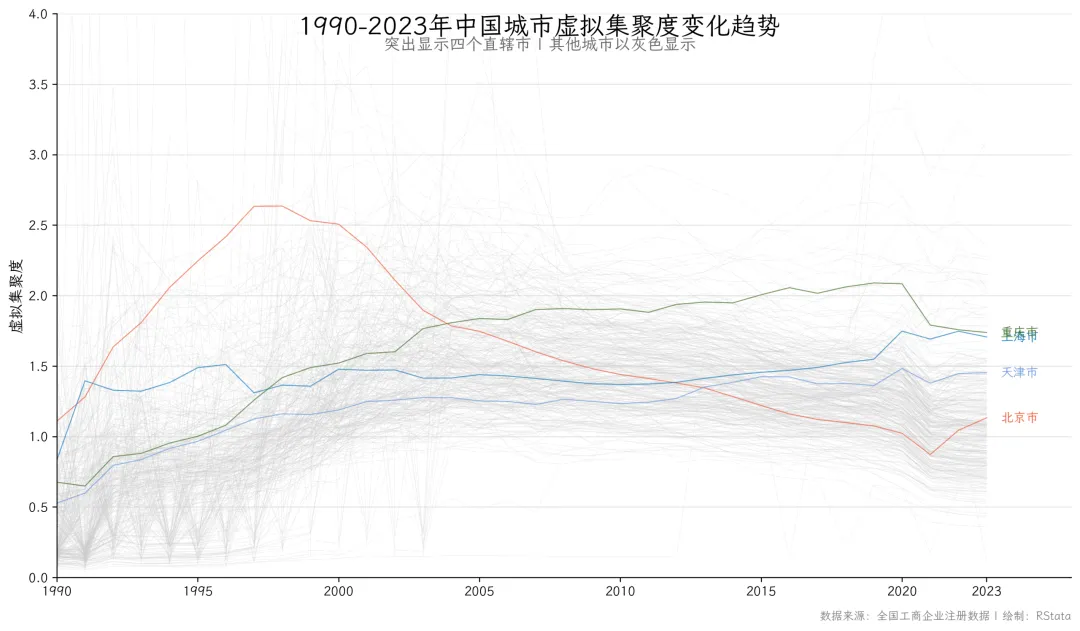
如何参加课程?
是不是感觉很硬核!欢迎报名 RStata 培训班获取全部课程和以会员价获取数据资料(10元/份)详情可阅读这篇推文:数据处理、图表绘制、效率分析与计量经济学如何学习~
详情可点击阅读原文进入 RStata 学院了解(从首页的会员卡专区即可查看和购买会员卡)。
更多关于 RStata 培训班的信息可添加微信号 r_stata2 咨询:

附件下载(点击文末的阅读原文即可跳转):
https://rstata.duanshu.com/#/brief/course/edab8a934b5f415a9fda38d80a326842