大家好,我是木木。
今天给大家分享一个强悍的 Python 库,sqlalchemy。
sqlalchemy
SQLAlchemy 是 Python 里绕不开的数据库工具。它不是只把表映射成类,也不是只帮你拼 SQL,而是同时提供 Core 和 ORM 两套能力:你可以用 Python 对象严谨地构造 SQL,也可以用模型类管理关系和事务。对需要长期维护、数据库复杂度逐渐上升的项目来说,它的可控性非常重要。
项目地址:https://github.com/sqlalchemy/sqlalchemy
官方文档:https://docs.sqlalchemy.org/en/20/
三大特点
表达强
Core 可以用 Python 构造 SQL 表达式,既避免字符串拼接,又保留对 SQL 的控制感。
ORM 成熟
Declarative、Session、relationship 和加载策略都很完整,适合复杂业务模型。
边界清楚
事务、连接、映射和查询都能显式管理,不会把数据库行为藏得太深。
最佳实践
安装方式:python -m pip install SQLAlchemy==2.0.49
功能一:用 Core 构造 SQL
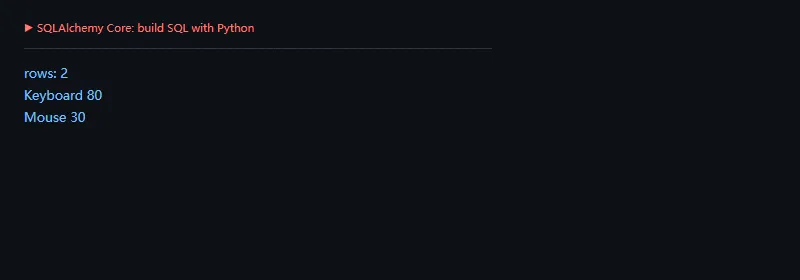
这段代码解决什么问题:不用手写 SQL 字符串,也能创建表、插入数据、构造查询条件和排序。Core 很适合数据脚本、报表任务和需要精确控制 SQL 的地方。
fromsqlalchemyimportColumn,Integer,MetaData,String,Table,create_engine,selectengine=create_engine("sqlite:///:memory:")metadata=MetaData()products=Table("products",metadata,Column("id",Integer,primary_key=True),Column("name",String),Column("price",Integer),Column("stock",Integer),)metadata.create_all(engine)withengine.begin()asconn:conn.execute(products.insert(),[{"name":"Keyboard","price":80,"stock":5},{"name":"Mouse","price":30,"stock":10},{"name":"Monitor","price":220,"stock":0},])stmt=select(products.c.name,products.c.price).where(products.c.stock>0).order_by(products.c.price.desc())rows=conn.execute(stmt).all()print("rows:",len(rows))forrowinrows:print(row.name,row.price)
Core 的价值在于“像写 SQL 一样清楚,但不用到处拼字符串”。当你关心 SQL 形态、性能和跨数据库兼容时,它会很顺手。
功能二:用 ORM 管理关系
这段代码解决什么问题:用声明式模型表达用户和订单的关系,并通过 selectinload 预加载订单,避免常见的 N+1 查询问题。
fromsqlalchemyimportForeignKey,String,create_engine,selectfromsqlalchemy.ormimportDeclarativeBase,Mapped,Session,mapped_column,relationship,selectinloadengine=create_engine("sqlite:///:memory:")classBase(DeclarativeBase):passclassUser(Base):__tablename__="users"id:Mapped[int]=mapped_column(primary_key=True)name:Mapped[str]=mapped_column(String(40))orders:Mapped[list["Order"]]=relationship(back_populates="user")classOrder(Base):__tablename__="orders"id:Mapped[int]=mapped_column(primary_key=True)user_id:Mapped[int]=mapped_column(ForeignKey("users.id"))amount:Mapped[int]user:Mapped[User]=relationship(back_populates="orders")Base.metadata.create_all(engine)withSession(engine)assession:session.add_all([User(name="Alice",orders=[Order(amount=120),Order(amount=80)]),User(name="Bob",orders=[Order(amount=60)]),])session.commit()stmt=select(User).options(selectinload(User.orders)).order_by(User.name)foruserinsession.scalars(stmt):print(user.name,sum(order.amountfororderinuser.orders))
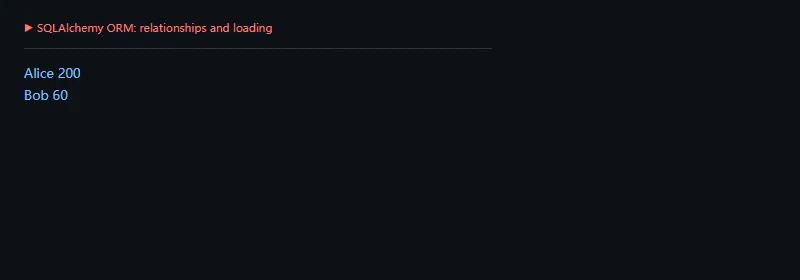
ORM 不是为了让你忘掉数据库,而是帮你把关系、生命周期和查询组织起来。加载策略要主动选择,别等线上慢了才回头看 SQL。
环境与版本信息
- Demo 环境:Windows 11,Python 3.11
- 本文安装的
SQLAlchemy 版本:2.0.49
高级功能
这段代码解决什么问题:用唯一约束触发写入失败,并确认事务回滚后只保留原始数据。真实业务里,事务边界和异常处理要比“能写入”更重要。
fromsqlalchemyimportString,UniqueConstraint,create_engine,func,selectfromsqlalchemy.excimportIntegrityErrorfromsqlalchemy.ormimportDeclarativeBase,Mapped,Session,mapped_columnengine=create_engine("sqlite:///:memory:")classBase(DeclarativeBase):passclassAccount(Base):__tablename__="accounts"__table_args__=(UniqueConstraint("name"),)id:Mapped[int]=mapped_column(primary_key=True)name:Mapped[str]=mapped_column(String(40))balance:Mapped[int]Base.metadata.create_all(engine)withSession(engine)assession:session.add(Account(name="alice",balance=100))session.commit()try:withsession.begin():session.add(Account(name="bob",balance=50))session.add(Account(name="alice",balance=200))exceptIntegrityErrorasexc:print("rollback:",exc.__class__.__name__)total=session.scalar(select(func.count()).select_from(Account))names=session.scalars(select(Account.name).order_by(Account.name)).all()print("accounts:",total)print("names:",", ".join(names))
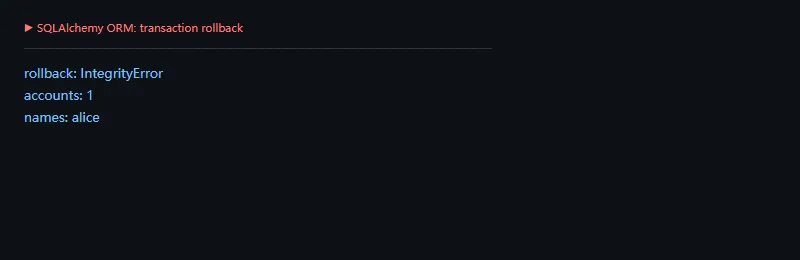
SQLAlchemy 的事务模型很明确:Session 管对象状态,事务管提交边界。写复杂业务时,把这两个概念分开理解,后面会少踩很多坑。
适用场景
- 你需要一个成熟、灵活、可控的 Python 数据库访问层。
- 你既想写 ORM,也希望必要时能精确控制 SQL。
- 项目模型关系复杂,需要事务、连接和加载策略都能细调。
不适用场景
- 你只做极小脚本,几个简单表读写,dataset 这类工具可能更轻。
- 团队不愿理解 Session、事务和加载策略,只想隐藏全部数据库细节。
- 项目已经被 Django 深度托管,直接使用 Django ORM 会更自然。
上线检查
- 打开 SQL 日志或慢查询,确认关键路径的真实 SQL。
- 给关系查询配置合适的
selectinload、joinedload 或显式 join。 - 明确 Session 生命周期,避免长事务和连接泄漏。
总结
SQLAlchemy 强在可控:你可以从 Core 到 ORM 逐层选择抽象级别。它学习曲线不算最低,但一旦项目的数据访问变复杂,它提供的表达力、事务边界和工程稳定性会很值。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
