搞懂 Linux 假死现象,才算真正吃透内核级运维排障
- 2026-07-02 16:47:21

大家好,我是蟹老板~
服务器又没反应了——别急着重启,你可能遇到的是假死
干了十年开发,我遇到过太多次这种“薛定谔的死机”——你说它死了吧,硬盘灯还在一闪一闪;你说它活着吧,敲键盘跟敲在棉花上似的,一点反应都没有。这就是传说中的假死。
一、认识Linux假死现象
简单来说,Linux 假死指的是系统或进程处于一种看似 “存活”,但实际上却毫无响应的诡异状态。这种状态下,进程可被命令检测到,使用ps命令能够看到进程的相关信息,验证其 PID 也是有效的,然而,当你试图使用kill -15(SIGTERM)或kill -9(SIGKILL)等信号去终止进程时,却发现进程完全无动于衷,对这些信号置若罔闻。不仅如此,通过系统监控工具查看进程的 CPU、内存占用情况,会发现其长期处于极低水平,仿佛进程陷入了一种 “沉睡” 状态,但又无法被正常唤醒。
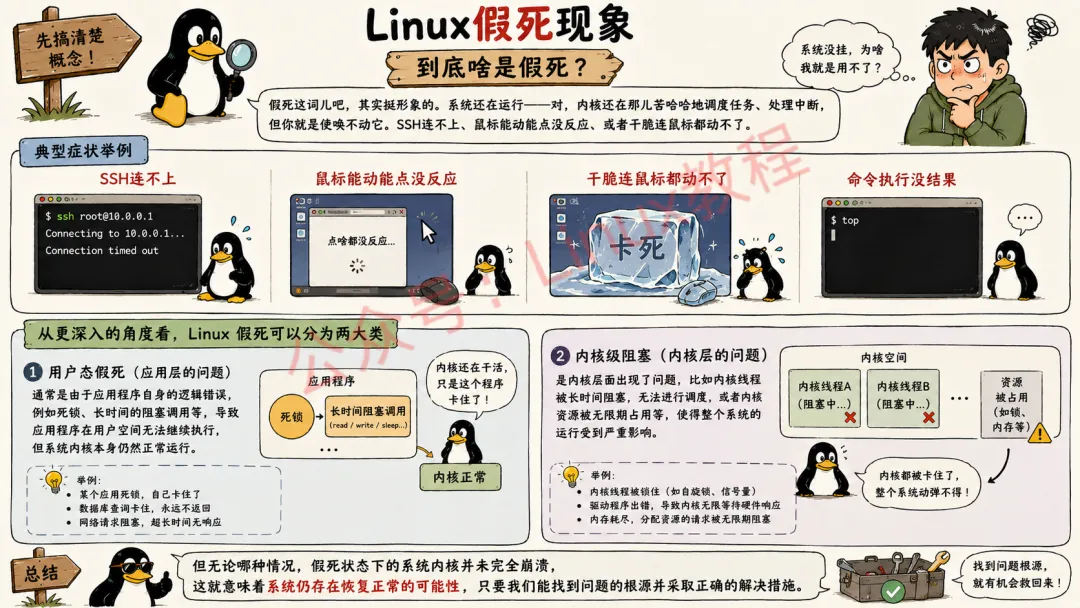
从更深入的角度来看,Linux 假死还可以细分为 “用户态假死” 与 “内核级阻塞”。“用户态假死” 通常是由于应用程序自身的逻辑错误,例如死锁、长时间的阻塞调用等,导致应用程序在用户空间无法继续执行,但系统内核本身仍然正常运行。而 “内核级阻塞” 则是内核层面出现了问题,比如内核线程被长时间阻塞,无法进行调度,或者内核资源被无限期占用等,使得整个系统的运行受到严重影响。
但无论哪种情况,假死状态下的系统内核并未完全崩溃,这就意味着系统仍存在恢复正常的可能性,只要我们能找到问题的根源并采取正确的解决措施。
二、Linux假死现象的典型症状
先从最直观的症状说起——你遇到假死时,到底会看到啥?
2.1 命令行与 SSH:操作无响应、无法登录、键入无回显
在命令行界面,假死的迹象十分明显。当你在终端中键入指令,按下回车键后,却没有任何回显,仿佛输入的命令石沉大海,没有激起一丝涟漪。比如,尝试执行简单的ls命令,本应列出当前目录下的文件和文件夹,此时却毫无动静,屏幕一片寂静。更糟糕的是,像ps、top等用于查看系统进程和性能状态的基础命令也无法执行,系统对这些关键指令充耳不闻。

SSH 连接方面同样问题重重。当你尝试通过 SSH 连接到假死的 Linux 服务器时,可能会遭遇连接超时的情况,长时间等待后,只得到一个连接失败的提示。即使幸运地建立了连接,在输入命令后,也如同在命令行界面一样,没有任何响应,就像与服务器之间的通信被无形的屏障阻断了。
为了准确判断是服务假死还是网络链路故障,我们可以使用ping命令来验证进程的存活状态。ping命令通过向目标主机发送 ICMP(Internet Control Message Protocol)回显请求报文,来测试网络的连通性。如果ping目标主机的 IP 地址能够成功收到响应,说明网络链路基本正常,问题更可能出在服务器的服务假死上;反之,如果ping不通,则需要进一步排查网络链路,如检查网线是否插好、路由器配置是否正确等。
2.2 图形界面:鼠标可动 / 不可动、窗口僵死、桌面环境冻结
在图形界面下,Linux 假死的症状表现得更为直观,用户体验也会受到极大影响,可大致分为两种场景。

第一种场景是鼠标指针可移动,但却无法点击窗口,点击菜单也毫无响应。这通常是桌面进程,如gnome-shell、kwin等在用户态卡死导致的。这些桌面进程负责管理图形界面的交互操作,一旦它们出现问题,就会导致用户虽然能够移动鼠标,但无法与窗口、菜单等进行正常的交互。例如,当你试图打开一个应用程序时,点击应用图标后,程序却没有任何启动的迹象,仿佛被冻结在了那一刻。
第二种场景则更为严重,鼠标完全无法移动,屏幕画面也静止不动,整个桌面环境就像被定格了一样。这种情况可能涉及到 GPU 驱动挂起或内核图形子系统阻塞。GPU(Graphics Processing Unit)负责图形的渲染和处理,当 GPU 驱动出现问题时,就无法正常驱动显卡工作,导致图形界面无法更新。此时,我们可以结合dmesg命令查看显卡相关日志,dmesg会记录系统启动和运行过程中的各种内核消息,通过查看其中关于显卡的信息,如是否有驱动错误提示、硬件故障信息等,来判断问题的根源。
2.3 网络行为:能 ping 通但服务全停、完全断网的不同场景
在网络行为上,Linux 假死也有两种常见的场景。
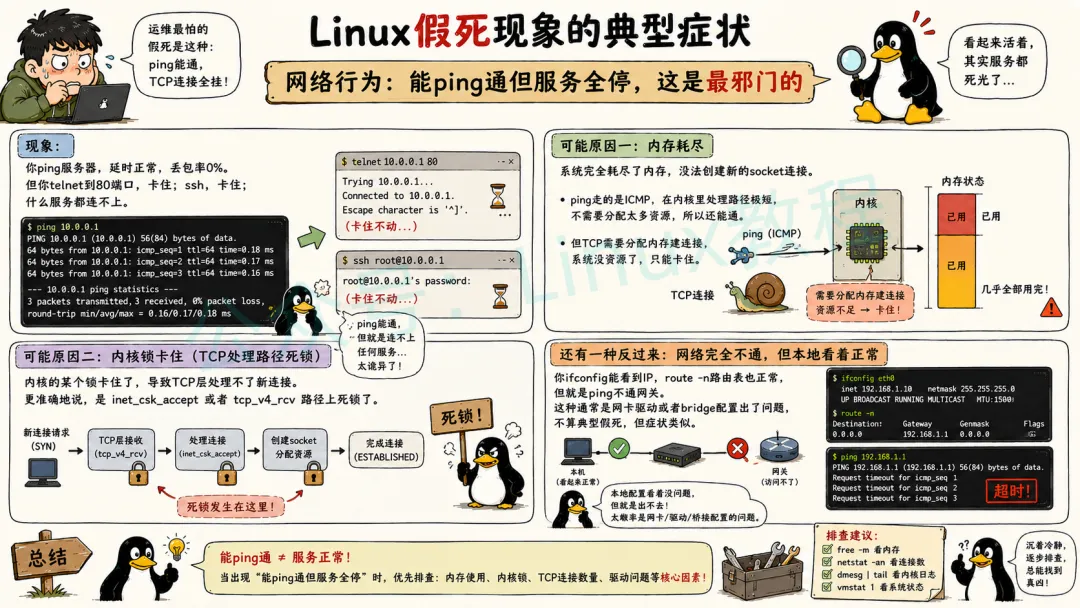
第一种场景是主机的 IP 地址可以正常ping通,但诸如HTTP、SSH等服务却无法访问。这种情况的原因多为用户态服务进程假死或端口监听异常。例如,HTTP服务对应的nginx或apache进程可能由于程序漏洞、资源耗尽等原因陷入假死状态,虽然服务器的网络连接正常,但HTTP服务却无法响应客户端的请求,导致网页无法打开。又或者服务进程正常运行,但端口监听出现问题,如端口被其他进程占用,使得服务无法在正确的端口上提供服务。
第二种场景是完全无法ping通目标主机,这大概率是内核网络栈阻塞、网卡驱动故障或防火墙规则异常导致的。内核网络栈负责处理网络数据包的收发和路由,如果它出现阻塞,就无法正常处理网络请求。网卡驱动是操作系统与网卡硬件之间的桥梁,当网卡驱动出现故障时,网卡无法正常工作,网络连接也就中断了。防火墙则用于保护系统的网络安全,但如果防火墙规则配置错误,将正常的网络通信也拦截了,就会导致无法ping通。此时,我们可以通过ip route命令(若可执行)查看路由表,检查网络路由是否正确,或者尝试重启网络服务,看是否能恢复网络连接。
2.4 系统指示灯与硬件反馈:硬盘灯常亮、风扇异常、SysRq 有 / 无反应
从系统指示灯和硬件反馈方面,也能获取到关于 Linux 假死的重要线索。
当硬盘灯持续常亮时,这往往指向磁盘 I/O 阻塞或文件系统元数据操作卡死。磁盘 I/O 操作,如读取和写入文件,需要磁盘控制器和文件系统的协同工作。如果在这个过程中出现问题,如磁盘出现坏道、文件系统损坏等,就会导致 I/O 操作无法正常完成,硬盘灯就会一直亮着,显示磁盘处于忙碌状态。
风扇转速异常飙升也是一个重要的信号,这可能是 CPU 陷入死循环或硬件温度失控导致的。当 CPU 陷入死循环时,会持续进行无意义的计算,导致 CPU 使用率急剧上升,产生大量的热量。为了散热,风扇会自动提高转速,试图降低 CPU 的温度。同样,当硬件温度失控时,如散热系统故障,也会导致风扇转速异常升高。
此外,SysRq组合键(如Alt+SysRq+<key>)也能帮助我们判断系统的状态。SysRq键是一个特殊的功能键,它可以在系统出现异常时执行一些紧急操作。当按下SysRq组合键后,如果系统有响应,说明内核仍可调度,系统可能只是出现了一些较轻的问题;反之,如果没有任何反应,则可能是硬锁定或中断被完全关闭,系统陷入了较为严重的故障状态。
三、内核视角的假死机制
说完了症状,既然咱们是程序员,不聊聊内核,那这文章不是白写了?O(∩_∩)O
3.1 软锁定 (soft lockup)

这是最常见的内核假死原因之一,属于轻量级可恢复内核异常,开启中断的前提下,内核代码长时间死循环、占用 CPU 不放,调度器无法切换任务,一般仅单颗 CPU 卡死,其他核心正常运行,系统不会直接崩溃。
内核自带软锁检测机制,看门狗线程定时巡检,默认超时无任务切换就打印告警日志;可通过内核参数设置触发软锁时是否直接宕机,根据日志能快速定位卡死进程与代码。
常见触发原因,比如长时间持有自旋锁、关闭抢占的代码段执行过久、大规模 RCU 同步抢占大量算力,可查看中断相关日志定位阻塞点。
3.2 硬锁定 (hard lockup)

比软锁定严重得多,属于致命卡死,内核直接关闭所有中断陷入死循环,连硬件级不可屏蔽中断都无法响应,这意味着内核在一个中断上下文里死循环,或者干脆陷入了固件层的处理(比如SMI中断太久)。这时候系统真的是彻底失去了响应,整机彻底冻结无任何操作反应,依靠 NMI 硬件看门狗监测,超时判定硬锁后自动生成崩溃日志并重启系统。
硬锁定的触发通常与硬件驱动或固件的兼容性问题密切相关,以下是一些常见的原因:
• 长时间关中断:在某些情况下,内核代码可能会因为需要保护关键资源或者执行特定的操作而长时间关闭中断。如果关中断的时间超过了 NMI 看门狗的检测周期,就可能导致 CPU 无法响应 NMI 信号,从而引发硬锁定。例如,在一些设备驱动程序中,为了保证对硬件设备的独占访问,可能会在一段较长的时间内关闭中断,这就增加了硬锁定的风险。 • 死循环在中断上下文:中断上下文是指在处理中断时的内核执行环境。如果在中断处理程序中出现死循环,就会导致 CPU 一直处于中断处理状态,无法响应其他中断和 NMI 信号,进而引发硬锁定。这种情况通常是由于驱动程序的编写错误或者硬件设备的异常导致的。 • 固件 / SMM 停留:BIOS 固件或 SMM(系统管理模式)在执行某些操作时,可能会占用 CPU 过长时间,导致 NMI 看门狗超时。例如,在系统启动过程中,如果 BIOS 固件在初始化硬件设备时出现问题,长时间占用 CPU,就可能引发硬锁定。SMM 是一种特殊的处理器运行模式,主要用于系统管理和电源管理等功能,如果 SMM 中的代码出现错误,也可能导致硬锁定的发生。
3.3 任务挂起与 D 状态泛滥
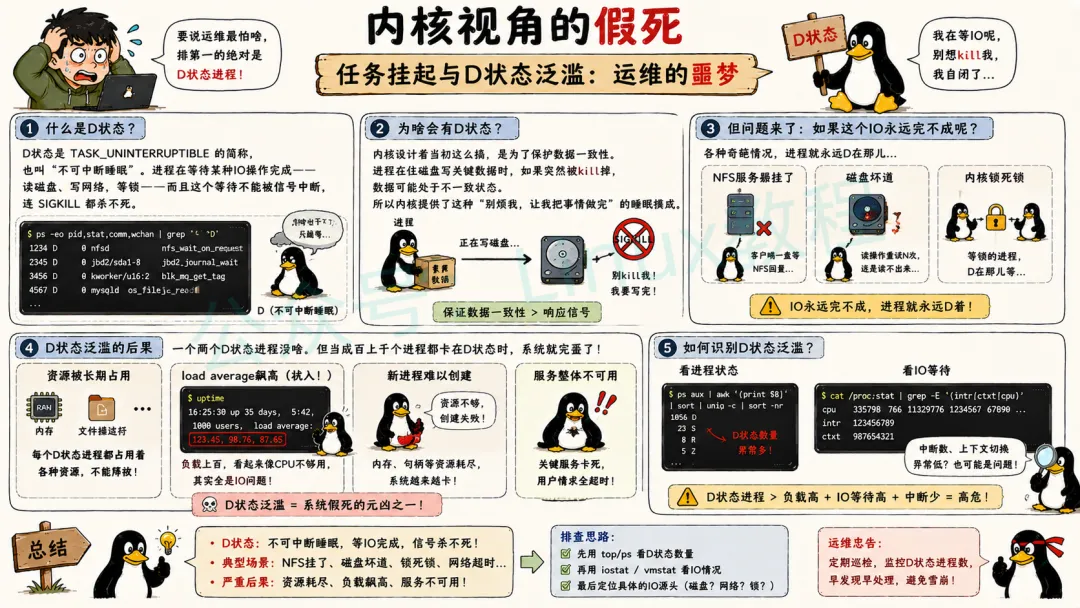
D 状态即不可中断休眠态,进程等待磁盘 IO、网络资源等硬件响应时进入该状态,无法被任何信号杀死。
一旦大量进程因 IO 阻塞扎堆进入 D 状态,就会爆发 D 状态风暴,系统负载飙升、调度失效,直观表现为系统假死,可通过命令筛选统计 D 态进程,排查磁盘、网络 IO 阻塞问题。
3.4 内存耗尽与 OOM 的伪假死
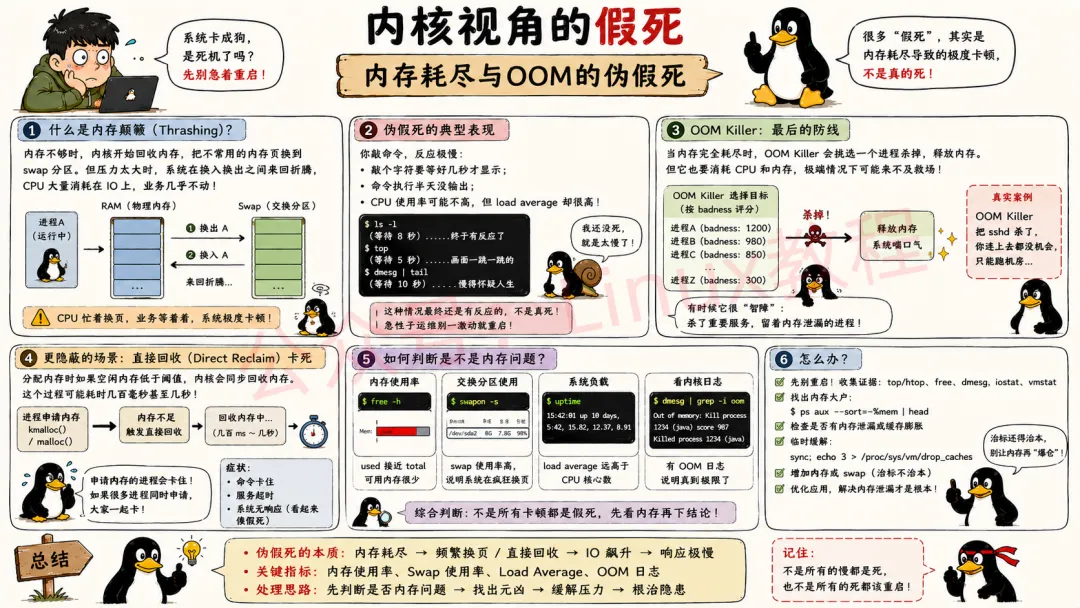
物理内存用尽后,内核会频繁执行内存回收、分区内存交换,占用大量系统资源,整机卡顿迟缓,看着像卡死,实则系统仍在正常运行。
系统内置 OOM 内存查杀机制,内存濒临耗尽时自动终止高内存占用进程释放资源;若机制未能及时生效,会造成全局冻结。日常可调整进程优先级,避免核心业务进程被误杀。
3.5 死锁与活锁
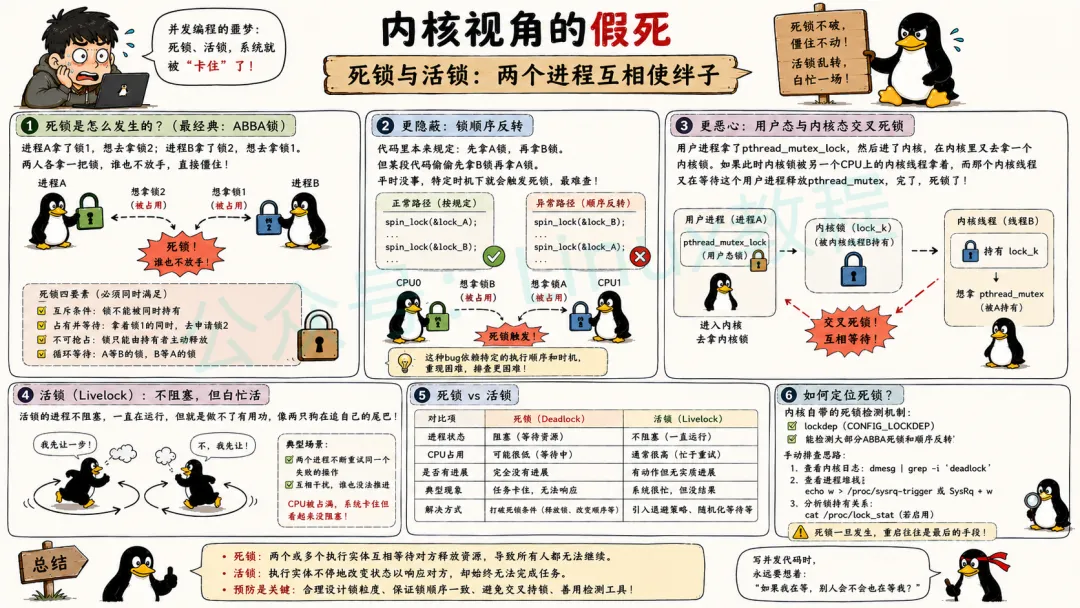
死锁这事儿,任何并发系统都躲不开,Linux内核也不例外。
内核死锁最常见的是ABBA锁。进程A拿了锁1,想去拿锁2;进程B拿了锁2,想去拿锁1。两人各拿一把锁,谁也不放手,直接僵住。这就是著名的“死锁四要素”之一——循环等待。
更隐蔽的是锁顺序反转。代码里本来规定先拿A锁再拿B锁,但某段代码偷偷先拿B锁再拿A锁。平时没事,但特定时机下就会触发死锁。这种bug最难查,因为它依赖特定的执行顺序。
用户态与内核态交叉死锁就更恶心了,举个例子:用户进程拿了pthread_mutex_lock,然后进了内核,在内核里又去拿一个内核锁。如果此时内核锁被另一个CPU上的内核线程拿着,而那个内核线程又在等待这个用户进程释放pthread_mutex,完了,死锁了。
活锁比死锁稍微好一点,但也好不到哪去。活锁的进程不阻塞,它们一直在运行,但就是做不了有用功,像两只狗在追自己的尾巴。比如两个进程都在不断重试同一个失败的操作,互相干扰,谁也没法推进。活锁同样会导致系统卡住,因为CPU全被这些没进展的任务占满了。
四、Linux假死的核心成因
前面内核机制聊了假死是怎么发生的,这一节咱们从更高维度,按问题领域来归类这些原因。
4.1 存储与文件系统
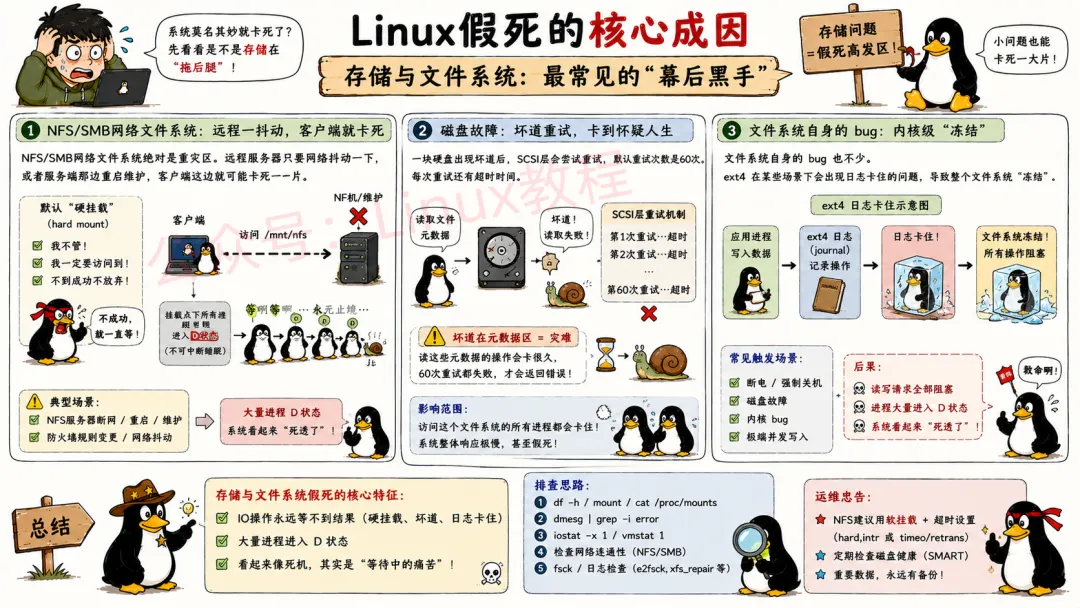
4.1.1 NFS/SMB 挂载超时与不可达
NFS(Network File System)和 SMB(Server Message Block)是常用的网络文件系统,用于实现不同主机之间的文件共享。但是当 NFS/SMB 服务端出现宕机、网络连接中断或配置不当等时,客户端在挂载这些网络文件系统时就可能遭遇超时与不可达的情况,进而引发系统假死。
当 NFS 服务端宕机或网络中断时,如果客户端在挂载 NFS 文件系统时未配置可中断(intr)、软挂载(soft)和超时参数,客户端进程就会因为等待 I/O 响应而陷入不可中断睡眠(D 状态)。这是因为在默认的硬挂载(hard)模式下,客户端会持续等待服务端的响应,即使服务端已经无法提供服务,客户端也不会放弃等待,从而导致大量进程阻塞,最终引发系统假死。例如,在一个分布式存储系统中,多个客户端挂载了同一个 NFS 共享目录,如果 NFS 服务端突然宕机,而客户端又未配置合理的挂载参数,那么这些客户端上的进程就会因为等待 NFS 服务端的响应而陷入 D 状态,导致整个系统无法正常工作。
为了避免这种情况的发生,我们在挂载 NFS 文件系统时,可以使用以下命令并合理配置参数:
mount -t nfs -o intr,soft,timeo=60 192.168.1.100:/shared /mnt/nfs其中,intr参数表示允许通过信号中断挂载操作,soft参数表示采用软挂载模式,当 I/O 操作超时时,客户端不会一直等待,而是返回错误,timeo=60表示 I/O 操作的超时时间为 60 秒。通过这样的配置,可以有效降低因 NFS 挂载问题导致系统假死的风险。
对于 SMB 文件系统,同样存在类似的问题。当 SMB 服务端出现故障或网络连接不稳定时,客户端在挂载 SMB 共享目录时也可能出现长时间等待的情况。为了解决这个问题,我们可以在挂载 SMB 共享目录时,使用vers参数指定 SMB 协议版本,并设置合理的timeo参数来控制超时时间。例如:
mount -t cifs -o vers=3.0,timeo=30 //192.168.1.101/shared /mnt/smb这样,当 SMB 服务端出现问题时,客户端能够在指定的超时时间内返回错误,而不是一直等待,从而避免系统假死。
4.1.2 磁盘故障、坏道导致的 IO 重试阻塞
磁盘作为 Linux 系统中存储数据的重要硬件设备,当磁盘出现故障,如机械硬盘出现坏道、固态硬盘出现磨损、RAID 阵列出现故障等,就会导致磁盘 I/O 请求无法正常完成,进而引发系统假死。
机械硬盘在长期使用过程中,可能会出现物理坏道。当文件系统尝试读取或写入坏道上的数据时,磁盘控制器会不断重试 I/O 操作完成数据传输,如果坏道问题严重,I/O 操作会持续失败,导致进程陷入不可中断睡眠(D 状态)。例如,当一个进程需要读取位于坏道上的文件时,磁盘控制器会不断尝试读取数据,但由于坏道的存在,读取操作始终无法成功,进程就会一直处于等待状态,最终导致系统假死。
固态硬盘虽然没有机械部件,但也会因为闪存芯片的磨损、主控芯片的故障等原因出现性能下降或故障。当固态硬盘出现问题时,同样会导致 I/O 请求的延迟或失败,引发系统假死。此外,如果 RAID 阵列中的某个磁盘出现故障,或者 RAID 控制器出现问题,也会导致整个阵列的 I/O 性能下降,甚至出现数据丢失的情况,进而引发系统假死。
4.1.3 文件系统日志 / 元数据操作卡死
文件系统是 Linux 系统中用于管理文件和目录的软件层,它负责将数据存储到磁盘上,并提供对文件和目录的访问接口。在文件系统中,日志和元数据操作是非常重要的组成部分,它们用于保证文件系统的一致性和可靠性。然而,当文件系统在执行日志 / 元数据操作时出现故障,如 ext4、XFS 等日志型文件系统在执行元数据(如目录创建、权限修改)操作时,若遭遇断电或磁盘故障,就可能导致日志回放失败,文件系统进入冻结状态,进而引发系统假死。
以 ext4 文件系统为例,当系统在执行文件创建、删除、重命名等操作时,ext4 会将这些操作记录到日志中,以便在系统出现故障时能够通过回放日志来恢复文件系统的一致性。然而,如果在日志写入过程中遭遇断电或磁盘故障,日志可能会出现损坏或不完整的情况,导致日志回放失败。此时,ext4 文件系统会进入一种保护模式,即冻结状态,以防止数据进一步损坏。在冻结状态下,文件系统无法进行任何读写操作,进程会因为无法访问文件系统而陷入不可中断睡眠(D 状态),最终导致系统假死。
4.2 内存与换页:慢性毒药
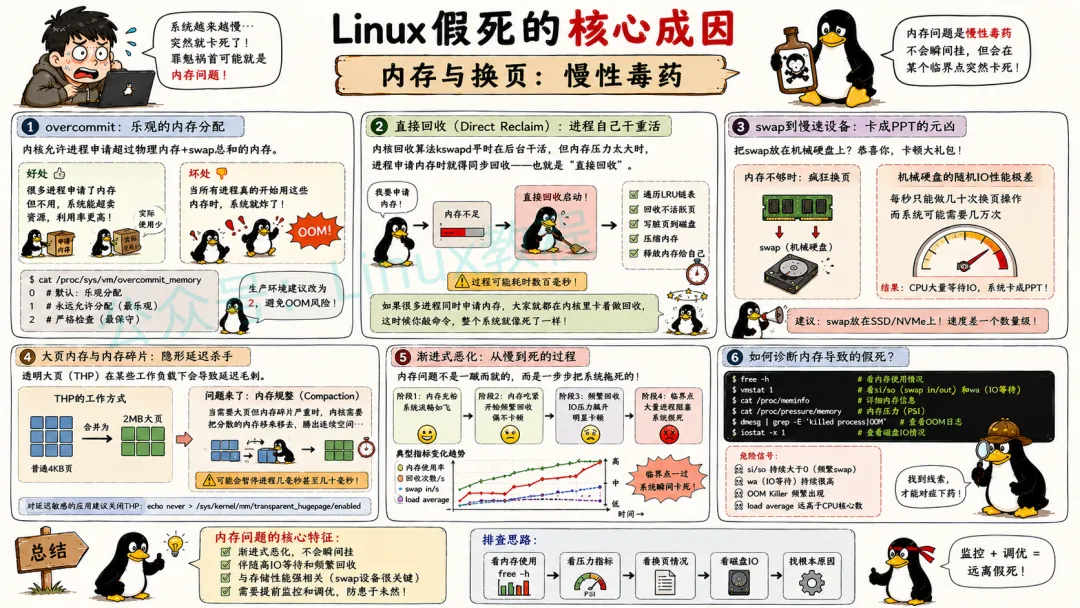
内存问题导致的假死是“渐进式”的,不会瞬间挂,但会在某个临界点突然卡死。
overcommit 是Linux内存管理的一个特色。默认配置下,内核允许进程申请超过物理内存+swap总和的内存——这叫“乐观的”内存分配策略。好处是很多进程申请了内存但不用,系统能超卖资源。坏处是,当所有进程真的开始用这些内存时,系统就炸了。
内存过量提交后,系统会进入直接回收模式。内存回收算法kswapd平时在后台干这活,但当内存压力太大时,进程申请内存时就得同步回收——也就是“直接回收”。直接回收会遍历LRU链表、写脏页到磁盘、压缩内存等等。这个过程可能耗时数百毫秒。
如果很多进程同时申请内存,大家就都在内核里卡着做回收。这时候你敲命令,整个系统就像死了一样。
swap到慢速设备的问题更现实。很多人图省事,把swap放在机械硬盘上。内存不够时,系统疯狂换页,机械硬盘的随机IO性能极差,每秒只能做几十次换页操作,而系统可能需要几万次。结果就是CPU大量等待IO,系统卡成PPT。
这时候你vmstat 1能看到si和so(swap in/out)列的数字很大,wa(IO等待)也很高。这就是典型的swap颠簸。
大页内存和内存碎片也是坑。透明大页(THP)在某些工作负载下会导致延迟毛刺。Hadoop、Redis这些对延迟敏感的应用,官网都建议关掉THP。因为THP在后台做内存规整时,可能会暂停进程几毫秒甚至几十毫秒。
4.3 内核同步与调度:互锁陷阱
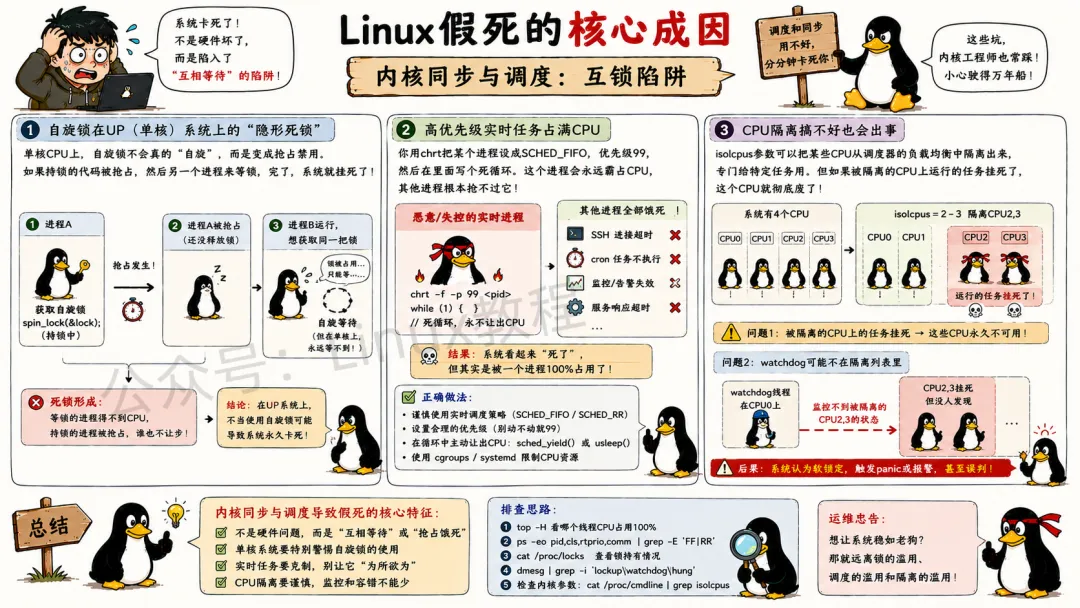
死锁前面聊过,不再重复,但有个场景值得单独说:自旋锁在UP(单核)系统上的行为。单核CPU上,自旋锁不会真的“自旋”,而是变成抢占禁用。如果持锁的代码被抢占,然后另一个进程来等锁,完了,系统就挂死了。因为在单核上,等锁的进程永远得不到CPU,拿锁的进程也被抢占了。这就是典型的“死锁”。
高优先级实时任务占满CPU也常出现。你用chrt把某个进程设成SCHED_FIFO,优先级99,然后在里面写个死循环。这个进程会永远霸占CPU,即使是root用户的其他进程也抢不过它。如果这个实时任务不主动让出CPU,系统里其他任务就永远得不到执行。SSH、cron、监控,全挂。
业内有个著名案例:某公司运维为了方便管理,把监控agent的优先级调高了。结果agent有内存泄漏,触发了频繁的GC,GC会暂停所有业务线程。因为agent优先级最高,GC期间其他线程都抢不到CPU,业务服务器周期性假死,每次持续几秒钟。
CPU隔离搞不好也会导致出事,isolcpus参数可以把某些CPU从调度器的负载均衡中隔离出来,专门给特定任务用。但如果被隔离的CPU上运行的任务挂死了,这个CPU就彻底废了。而且watchdog线程可能不在隔离列表里,导致系统认为这个CPU软锁定,触发panic或者报警。
4.4 驱动与硬件:黑盒问题
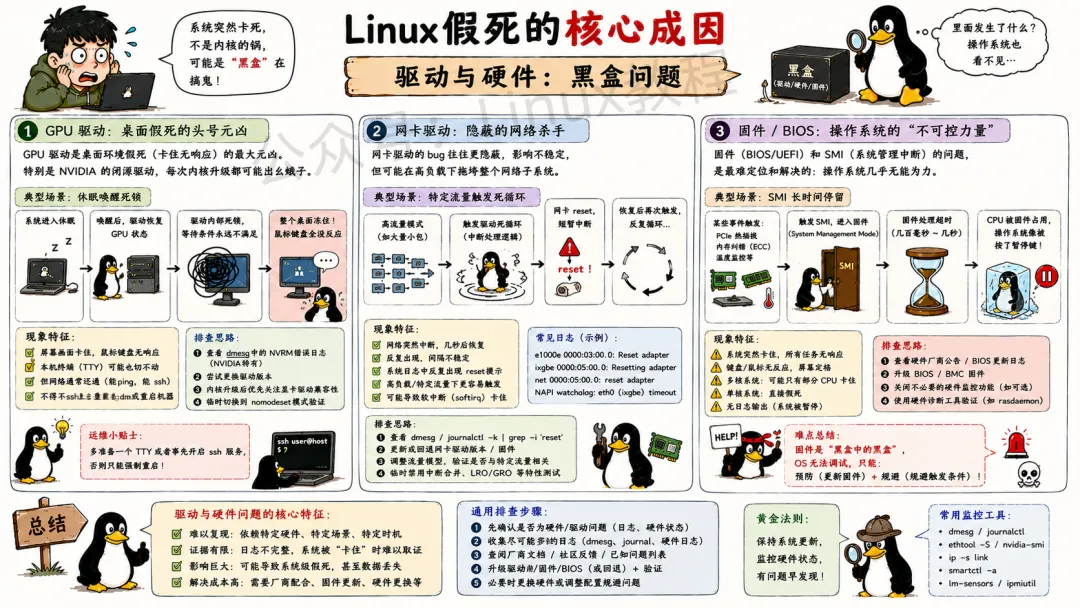
驱动代码跑在内核态,出bug就是系统级灾难。
GPU驱动是桌面假死的最大元凶。特别是NVIDIA的闭源驱动,每次内核升级都可能出幺蛾子。我遇到过显卡驱动在休眠唤醒时死锁,整个桌面冻住,鼠标键盘全没反应,但机器的网络还是通的。最后只能ssh上去重启gdm。
网卡驱动的bug更隐蔽。某个品牌的万兆网卡,在特定流量模式下会触发驱动里的一个死循环。现象是网络突然中断,然后很快恢复,但系统日志里全是reset的提示。反复reset过程中,中断处理逻辑可能卡住,连累整个网络子系统。
固件和BIOS问题最头疼。SMI(系统管理中断)这东西运行在固件层面,操作系统根本控制不了。某些服务器的BIOS在PCIe热插拔处理、内存纠错等场景下,会进入SMI长时间停留。几百毫秒甚至几秒的时间里,CPU被固件占用,操作系统像是被按了暂停键。多核系统还好,单核的话就直接假死了。
4.5 用户空间怪象:看似内核,其实不是
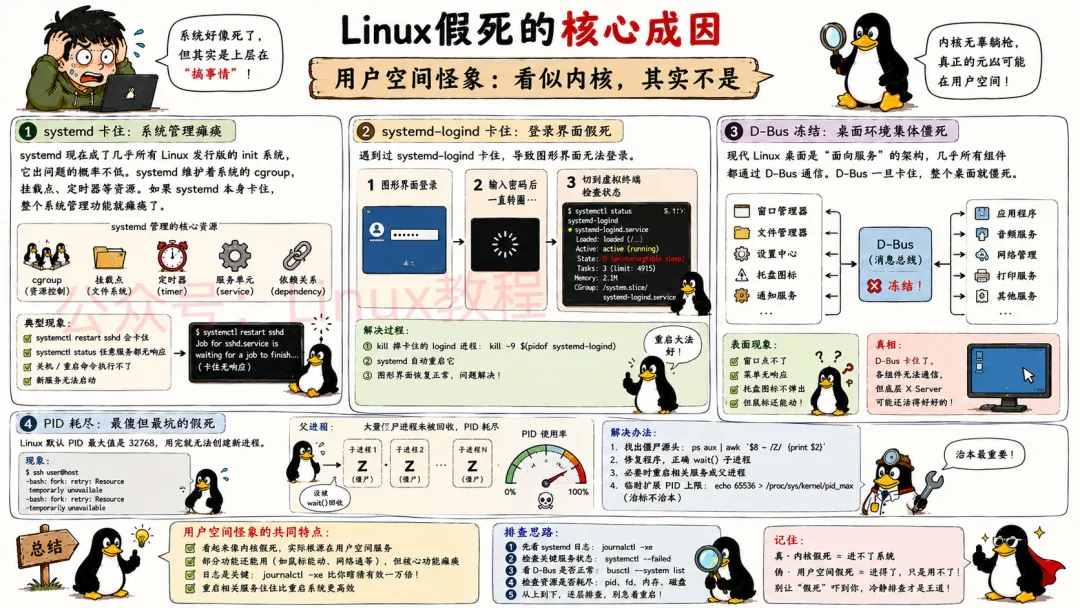
最后这些伪假死,锅在内核但根源在上层。
systemd现在成了几乎所有Linux发行版的init系统,它出问题的概率不低。systemd维护着系统的cgroup、挂载点、定时器等资源。如果systemd本身卡住(比如某个单元启动超时),整个系统管理功能就瘫痪了。你systemctl restart sshd会卡住,甚至关机都关不了。
我遇到过systemd-logind卡住,导致图形界面无法登录。鼠标能动,点用户图标也有反应,但输完密码后一直转圈。切到虚拟终端一看,systemctl status systemd-logind显示进程在D状态。最后kill掉logind进程,让systemd自动重启它,问题解决。
D-Bus冻结在桌面环境里尤其常见。现代Linux桌面是“面向服务”的架构,几乎所有组件都通过D-Bus通信。D-Bus一旦卡住,你的窗口管理器、文件管理器、托盘图标全部僵死。但底层X Server可能还活得好好的——这就解释了为啥鼠标能动但点不了任何窗口。
PID耗尽是种很傻的假死。Linux默认PID最大值是32768,用完就无法创建新进程。你ssh上去,shell都启动不了,因为ssh需要fork新进程。提示是-bash: fork: retry: Resource temporarily unavailable。这通常是大量僵尸进程没被父进程回收导致的。
五、常见假死场景解决方案与实操案例
理论说完了,该来点干货了,说实话, 真正线上故障处理时,核心就一句: 先保命,再定位,最后再谈优雅。
5.1 资源耗尽类假死
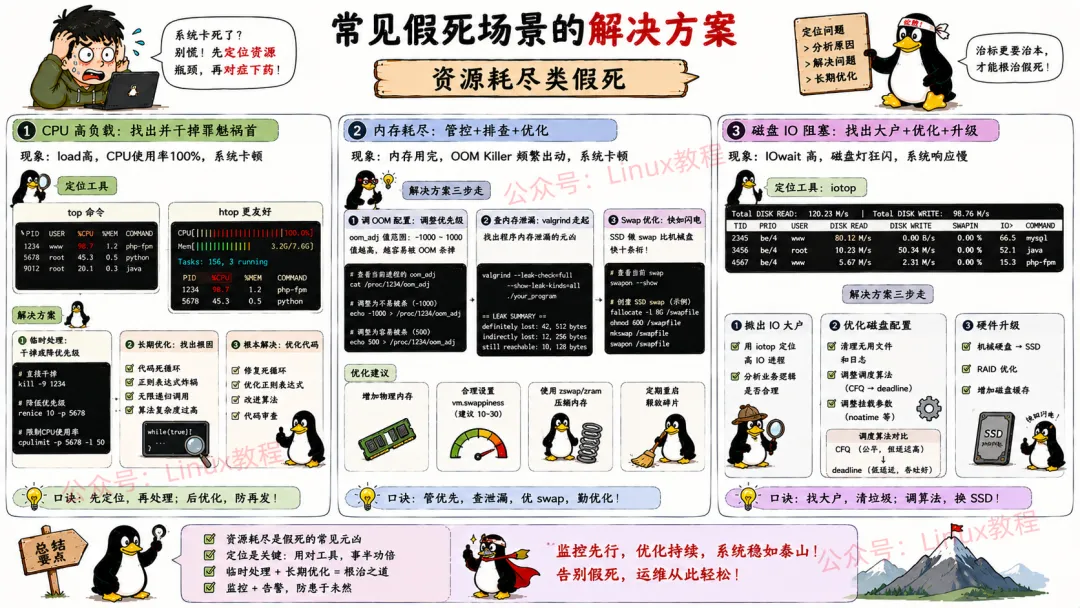
CPU高负载假死
现象识别:top或者htop里看到某个进程CPU占用100%,系统load average飙升,其他进程响应缓慢。
救火步骤:
1. 能ssh进去的话,先用 top找出问题进程。按P键按CPU排序。2. 如果是普通用户进程, kill -9直接干掉:
# 找到PIDtop -b -n 1 | head -20# 杀掉kill -9 12345# 如果进程杀不掉(D状态),检查是不是IO问题ps aux | awk '$8=="D" {print}'3. 如果CPU被内核线程占用, perf top看看热点在哪:
perf top -g# 看到spin_lock、mutex_lock之类的符号,八成是锁竞争4. 临时降低进程优先级,别让它饿死别人:
# renice 19是最低优先级renice 19 -p 12345长期优化:
• 代码层面优化算法,减少CPU消耗 • 使用CPU亲和性绑定,避免频繁迁移 • 考虑CPU隔离,把关键业务和干扰进程分开 • 配置cgroup的CPU限制,防止单个进程吃满所有核
# cgroup v2示例echo "500000 1000000" > /sys/fs/cgroup/cpu.max # 限制50%的CPU内存耗尽假死
现象识别:free -h看到内存用尽,swap用满,vmstat里si、so有数值。
紧急抢救:
1. 触发OOM Killer主动杀进程:
# 先看看当前OOM分数cat /proc/*/oom_score | sort -nr | head -10# 手动触发OOM(慎用!会随机杀进程)echo f > /proc/sysrq-trigger2. 杀掉内存大户:
# 找出用内存最多的进程ps aux --sort=-%mem | head -10# 杀掉kill -9 PID3. 赶紧关掉swap,起码别再换入了:
swapoff -a# 注意:这会强制把swap里的数据换回内存,可能更卡4. 如果系统卡得命令都敲不动,用SysRq:
Alt+SysRq+F# 这会触发OOM Killer,杀一个进程释放内存长期优化:
• 调整 vm.swappiness,减少swap倾向。默认60,对服务器建议10:
echo 10 > /proc/sys/vm/swappiness# 永久生效写/etc/sysctl.conf• 启用内存压缩(zswap或zram),对swap做压缩:
# 启用zswap(内核参数)echo 1 > /sys/module/zswap/parameters/enabled• 设置cgroup内存限制,防止单进程吃光所有内存:
# 限制进程组最多用1G内存cgcreate -g memory:/limitedecho 1G > /sys/fs/cgroup/memory/limited/memory.limit_in_bytescgclassify -g memory:/limited PID• 部署内存监控,提前预警。我习惯用 prometheus + node_exporter,内存用到80%就报警。
磁盘I/O阻塞假死
现象识别:iostat -x 1看到%util接近100%,await很高(几十毫秒甚至秒级),队列长度avgqu-sz很大。
紧急处理:
1. 先看看哪些进程在IO上等待:
ps aux | awk '$8=="D" {print}'# 或者用ps的-o wchan(等待通道)ps -eo pid,stat,wchan,comm | grep "D"2. 如果是NFS/网络存储问题,强制卸载:
# 查看哪些进程在使用这个挂载点lsof | grep /mnt/nfs# 强制卸载(即使busy)umount -l /mnt/nfs3. 本地磁盘的话,可以尝试重新挂载为只读,起码能dd数据出来:
mount -o remount,ro /dev/sda1 /mnt长期优化:
• 更换SSD,机械硬盘不适合做高并发读写。这钱别省。 • 调整IO调度器。NVMe SSD用 none或mq-deadline,机械盘用bfq:
# 查看当前调度器cat /sys/block/sda/queue/scheduler# 修改echo mq-deadline > /sys/block/sda/queue/scheduler• 文件系统层面调优。ext4的 noatime挂载选项能减少很多写操作:
/dev/sda1 /data ext4 defaults,noatime,nodiratime 0 1• 应用层面做IO限流。数据库的 sync_binlog、innodb_flush_log_at_trx_commit这些参数可以调整,牺牲持久性换性能。
5.2 进程异常类假死

死锁解决
识别死锁:用gdb的thread apply all bt看所有线程堆栈,或者用pstack:
pstack PID看到多个线程在等pthread_mutex_lock,或者内核里卡在futex,就是死锁。
临时救火:
1. 最暴力:kill掉死锁进程 2. 如果进程不能杀,可以尝试 gdbattach上去,强制修改锁变量。但风险极高,生产环境不建议。
gdb -p PID(gdb) call pthread_mutex_unlock(&mutex)长期修复:
• 代码审查,确保锁顺序一致 • 使用 clang的线程安全注解(Thread Safety Analysis)• 引入超时机制,不用阻塞锁:
// pthread_mutex_trylockif (pthread_mutex_trylock(&mutex) == 0) { // 拿到锁了} else { // 没拿到,做点别的,别死等}僵尸进程清理
现象:ps aux看到很多Z状态的进程,PID逐渐耗尽。
原理:子进程退出后变成僵尸,父进程需要调用wait()来收尸。父进程忘了收,僵尸就留下了。
清理方法:
1. 找到父进程,杀掉它。僵尸进程的父进程被kill后,僵尸会被init进程接管并回收:
# 找僵尸进程ps -eo pid,stat,comm | grep Z# 找到父进程PIDcat /proc/12345/status | grep PPid# 杀父进程kill -9 父进程PID2. 如果父进程是关键服务不能杀,那就只能写脚本定期清理:
#!/bin/bash# 找所有僵尸进程,发送SIGCHLD给父进程,让父进程回收for pid in $(ps -eo pid,stat | awk '$2=="Z" {print $1}'); do ppid=$(cat /proc/$pid/status | grep PPid | awk '{print $2}') kill -CHLD $ppid 2>/dev/nulldone预防:
• 编程时正确处理 SIGCHLD信号• 用 wait()或waitpid()回收子进程• 用systemd管理的服务,它会自动清理僵尸
5.3 内核与驱动类假死
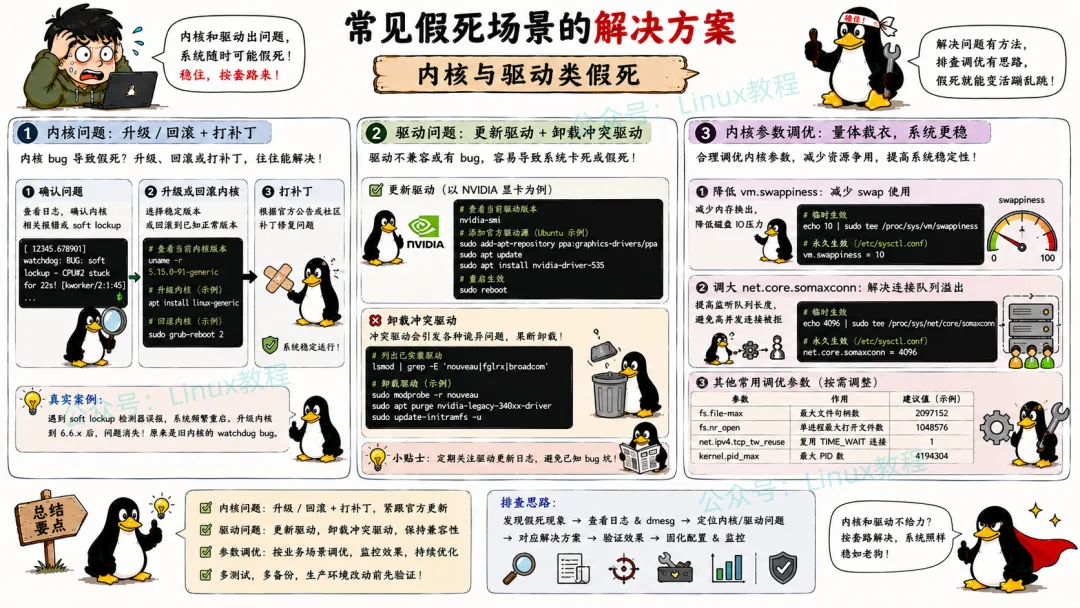
这类问题最麻烦,因为内核一挂,你的调试手段就少了很多。
内核升级/回滚
如果内核崩溃了,先记下panic信息。有kdump配置的话,分析vmcore:
crash /usr/lib/debug/lib/modules/$(uname -r)/vmlinux /var/crash/vmcore但很多时候,没配置kdump。那就只能靠经验判断了。
内核回归测试:升级内核后假死,大概率是新内核的bug。回滚到旧内核:
1. 开机进GRUB菜单,选旧内核启动 2. 卸载新内核: yum remove kernel-新版本3. 报告bug给内核社区或发行版厂商
内核参数调优:有时候不用升级,改参数就能绕过问题。
比如内存回收导致的假死,可以调高vm.min_free_kbytes:
# 保留更多空闲内存echo 1048576 > /proc/sys/vm/min_free_kbytes # 1GB比如lockup detector太敏感,可以放宽阈值:
# soft lockup从20秒放宽到60秒echo 60 > /proc/sys/kernel/watchdog_thresh驱动更新
显卡驱动出问题,Xorg日志是关键:
cat /var/log/Xorg.0.log | grep EE如果是NVIDIA驱动,试试开源驱动:
# 卸载nvidia驱动yum remove nvidia-*# 安装nouveau(注意:性能差)yum install xorg-x11-drv-nouveau网卡驱动升级:
# 先看当前驱动ethtool -i eth0# 去官网下载新驱动,编译安装make && make installmodprobe -r 旧驱动modprobe 新驱动关键sysctl参数:
这些是我踩坑总结的,直接贴出来:
# /etc/sysctl.conf# 减少内存回收压力vm.vfs_cache_pressure=50vm.dirty_ratio=30vm.dirty_background_ratio=5# 避免TCP内存耗尽net.core.rmem_max=134217728net.core.wmem_max=134217728net.ipv4.tcp_rmem=4096 87380 134217728net.ipv4.tcp_wmem=4096 65536 134217728# 加快TCP回收(慎用,NAT环境可能有问题)net.ipv4.tcp_tw_reuse=1net.ipv4.tcp_fin_timeout=30# 避免ARP攻击导致的假死net.ipv4.conf.all.arp_ignore=1net.ipv4.conf.all.arp_announce=2# 系统整体容忍度kernel.panic=3 # panic后3秒自动重启kernel.panic_on_oops=1kernel.softlockup_panic=0 # soft lockup别panic,报警就行六、经典假死案例实战复盘
这一部分,我尽量讲真实一点, 因为很多人学 Linux,总觉得命令会背就够了,真到线上,不是那回事,线上故障处理特别像刑,很多时候只有碎片,你得拼。
6.1 案例一:NFS 服务端宕机引发大量 D 状态进程
背景:公司核心业务系统跑了台NFS服务器,存的是用户上传的图片。三台Web服务器通过NFS共享这些图片。NFS挂载选项用的是默认的hard,intr。
现象:下午两点半,监控系统炸了。三台Web服务器的load average突然飙升到100+,SSH连上去要等一分钟才能输密码,输完还得等。ping能通,HTTP服务完全无响应。
我当时的表情:😱

诊断过程:
第一步,排除网络问题。从另一台正常机器ping NFS服务器,不通。完了,NFS服务器挂了。
第二步,看Web服务器上的进程状态:
# 等了好久才出来ps aux | awk '$8=="D" {print $0}' | wc -l# 输出:847847个D状态进程!大部分是nginx和php-fpm的worker。
第三步,用SysRq看哪些进程卡住了:
# 先得打开SysRqecho 1 > /proc/sys/kernel/sysrq# 打印所有进程的调用栈echo w > /proc/sysrq-triggerdmesg里看到一堆这样的信息:
nginx D 0 1234 1 0x00000000Call Trace: [<ffffffffa003b0a0>] nfs_wait_on_requests+0x10/0x20 [nfs] [<ffffffffa003c0a0>] nfs_page_async_flush+0x30/0x40 [nfs] ...所有卡住的进程都在等NFS操作完成。
解决方案:
紧急措施:
# 强制卸载NFS(虽然很多进程卡着)umount -l /mnt/nfs_pics# 现在卡住的进程会收到IO错误,退回到用户空间# 大部分会退出,没退出的直接kill -9恢复NFS服务器后,发现问题很傻:磁盘满了,NFS服务异常但进程没退出。重启NFS服务:
# 清点磁盘空间,删掉过期数据df -hrm -rf /data/nfs_export/temp/*# 重启NFS服务systemctl restart nfs-server根本修复:
1. 修改NFS挂载选项,把 hard改成soft,减少重试:
mount -t nfs -o soft,timeo=100,retrans=3 nfs-server:/export /mnt/nfs2. 部署NFS服务端监控,磁盘空间、服务状态、网络连通性全监控 3. 应用层增加降级逻辑:NFS不可用时,先把图片存本地,之后再同步
这一课教会我:网络存储的假死,永远比网络存储本身的故障更可怕。
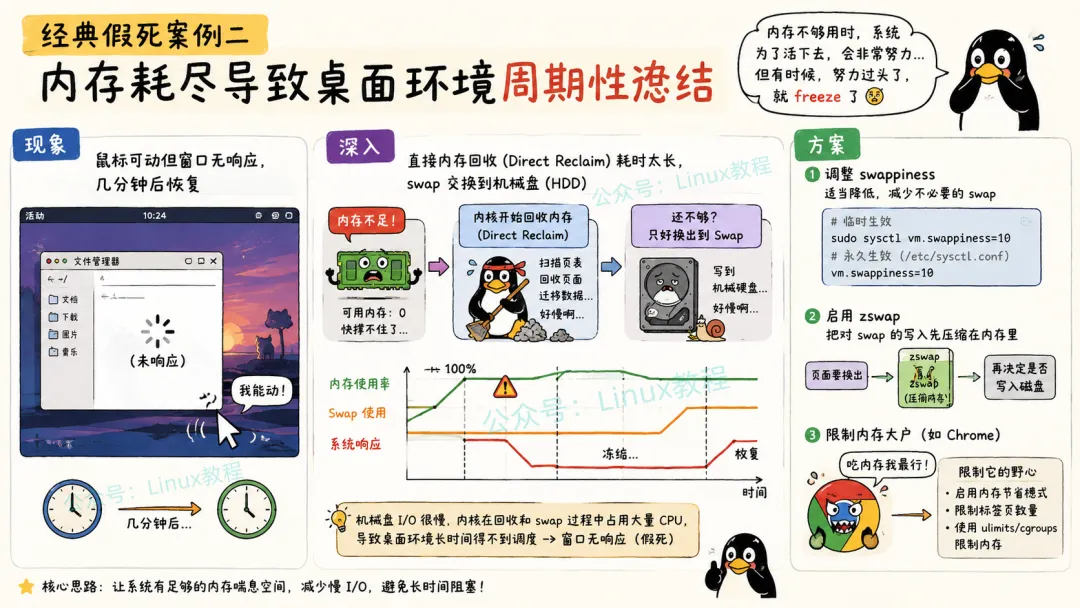
6.2 案例二:内存耗尽导致桌面环境周期性格冻结
背景:公司的机器是32GB内存的ThinkStation,跑Ubuntu 18.04。
现象:Chrome开十几个标签页,再跑个PyCharm,训练个小模型。半小时后,桌面开始抽风:鼠标还能动,但点任何窗口都没反应。等个一两分钟,又恢复了。过一会儿又来一次,周期性的。
深入诊断:
看系统日志:
journalctl -f看到大量这样的消息:
kernel: chrome invoked oom-killer: gfp_mask=0x...kernel: Mem-Info:kernel: active_anon:2045840 inactive_anon:318820 isolated_anon:0kernel: active_file:320 isolated_file:0 inactive_file:484kernel: unevictable:0 dirty:0 writeback:0 unstable:0kernel: slab_reclaimable:11068 slab_unreclaimable:22048kernel: mapped:1240 shmem:120 pagetables:580 bounce:0kernel: free:155000 free_pcp:800 free_cma:0内存快用完了,OOM Killer在频繁触发。
用vmstat 1观察:
vmstat 1procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 3 4194304 102400 1024 2048000 400 1200 1500 2500 2000 3000 15 10 60 15 0si和so(swap in/out)都有数值,说明在换页。wa(IO等待)15%,不算高但也不低。
关键问题:我的swap分区在机械硬盘上!Ubuntu安装时默认的分区,系统盘是SSD,但swap却在机械盘上。
解决方案:
临时救命:
# 关掉swap(先得确认内存够用)swapoff -a# 如果内存不够,把swap换到SSD# 创建一个swap文件在SSD上dd if=/dev/zero of=/swapfile bs=1M count=16384 # 16GBchmod 600 /swapfilemkswap /swapfileswapon /swapfile重启后桌面流畅多了。
长期优化:
1. 调低swap倾向,默认60太高了:
echo 10 > /proc/sys/vm/swappiness2. 启用zswap,对swap数据做压缩:
# 内核启动参数加zswap.enabled=1 zswap.compressor=lz43. 限制Chrome的内存使用:Chrome的 --max_old_space_size参数可以限制V8堆大小。4. 换了32GB内存还不够?写了个脚本,定期检查内存大户:
#!/bin/bash# 如果可用内存低于2GB,杀掉最占内存的Chrome标签页available=$(free -m | awk 'NR==2{print $7}')if [ $available -lt 2048 ]; then ps aux --sort=-%mem | grep chrome | head -1 | awk '{print $2}' | xargs kill -9 notify-send "内存不足" "杀掉了一个Chrome标签页"fi这个案例让我意识到:内存导致的假死,往往不是内存绝对不够,而是换页到慢速设备。
6.3 案例三:spinlock 死锁触发 hard lockup
背景:为客户做性能优化,客户有一批服务器跑定制内核,装了个第三方网卡驱动。
现象:服务器运行不定时假死,键盘鼠标全没反应,NumLock灯都不亮。过一会儿(配置了hardlockup_panic)自动重启。dmesg能看到hard lockup信息。
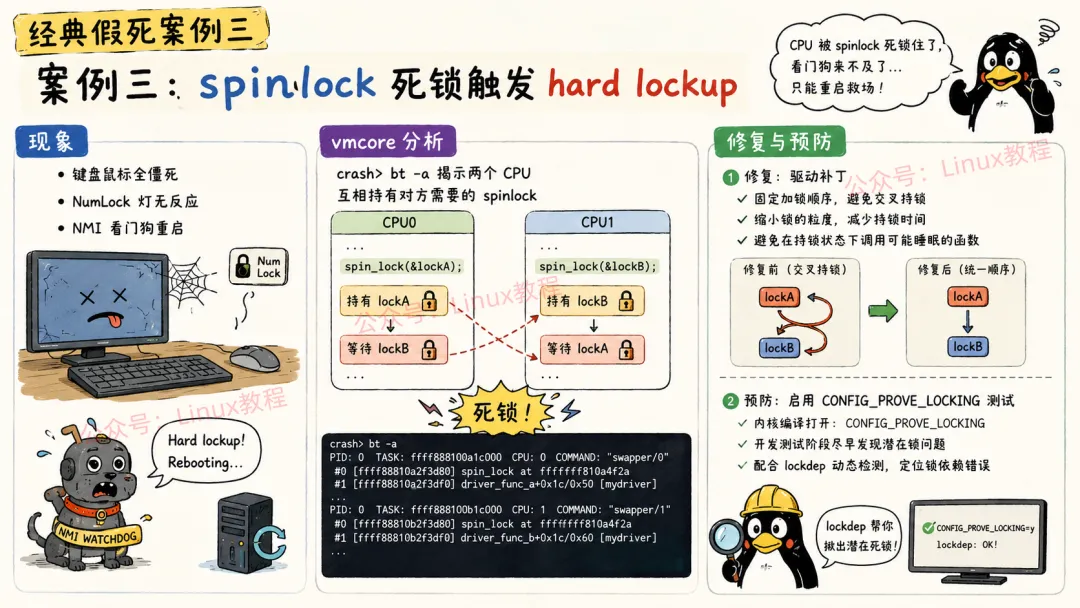
vcmcore分析(幸好客户配置了kdump):
crash /usr/lib/debug/lib/modules/$(uname -r)/vmlinux /var/crash/vmcore-xxx进入crash后:
crash> bt -aPID: 0 TASK: ffffffff81c0a000 CPU: 0 COMMAND: "swapper/0" #0 [ffffffff81803e70] machine_kexec at ffffffff8103c0a0 #1 [ffffffff81803ec0] __crash_kexec at ffffffff810a50b0 #2 [ffffffff81803f90] panic at ffffffff8172b0a0 #3 [ffffffff81803fe0] watchdog_overflow_callback at ffffffff8112c0a0 ...PID: 1234 TASK: ffff88007a4310c0 CPU: 1 COMMAND: "irq/49-eth0" #0 [ffff88007a437c90] _raw_spin_lock at ffffffff8172a0a0 #1 [ffff88007a437ca0] ixgbe_clean_rx_irq at ffffffffa003b0a0 [ixgbe] #2 [ffff88007a437d00] ixgbe_poll at ffffffffa003c0a0 [ixgbe] ...PID: 5678 TASK: ffff88007b4310c0 CPU: 2 COMMAND: "kworker/2:1" #0 [ffff88007b437c90] _raw_spin_lock at ffffffff8172a0a0 #1 [ffff88007b437ca0] ixgbe_clean_tx_irq at ffffffffa003d0a0 [ixgbe] ...看到了吗?CPU 1拿了一个锁在收包,CPU 2拿了另一个锁在发包,互相在等对方的锁?不对,仔细看,都是_raw_spin_lock,等的是同一个锁!
crash> bt 1 | grep spin#0 [ffff88007a437c90] _raw_spin_lock+0x10/0x20#1 [ffff88007a437ca0] ixgbe_clean_rx_irq+0x30/0x400 [ixgbe]crash> bt 2 | grep spin#0 [ffff88007b437c90] _raw_spin_lock+0x10/0x20#1 [ffff88007b437ca0] ixgbe_clean_tx_irq+0x20/0x300 [ixgbe]crash> struct ixgbe_q_vector 0xffff88007c001000 rx_ring = 0xffff88007c002000, tx_ring = 0xffff88007c003000, lock = { raw_lock = { slock = 0x1 } }等等,rx_ring和tx_ring都是同一个队列向量的?这个驱动把rx和tx的中断绑定到了同一个CPU,用的还是同一个自旋锁!收包时拿了锁,发包时也要拿同一个锁,如果两个CPU同时操作,就死锁了。
修复方法:
临时方案:绑定中断到不同CPU
# 查看网卡中断号cat /proc/interrupts | grep eth0# 设置中断亲和性,收包中断绑CPU0,发包绑CPU1echo 1 > /proc/irq/123/smp_affinityecho 2 > /proc/irq/124/smp_affinity但根治还是要驱动作者改代码:收包和发包用不同的锁。
预防措施:
1. 开启内核的lockdep:
# 内核启动参数加lockdep=12. 测试驱动时用 CONFIG_PROVE_LOCKING运行:
# 这会检测潜在的死锁make menuconfig -> Kernel hacking -> Lock Debugging -> Prove locking correctness3. 新驱动上线前,必须跑压力测试。我们用 netperf跑了48小时才敢上线。
这个案例的教训:第三方驱动是假死的高发区,测试不充分别上生产。
6.4 案例四:systemd服务循环重启导致PID耗尽假死
现象:Ubuntu 20.04服务器,跑了二十多个容器。某天突然ssh不上去了,能ping通,但ssh连接时卡在debug1: pledge: network阶段。
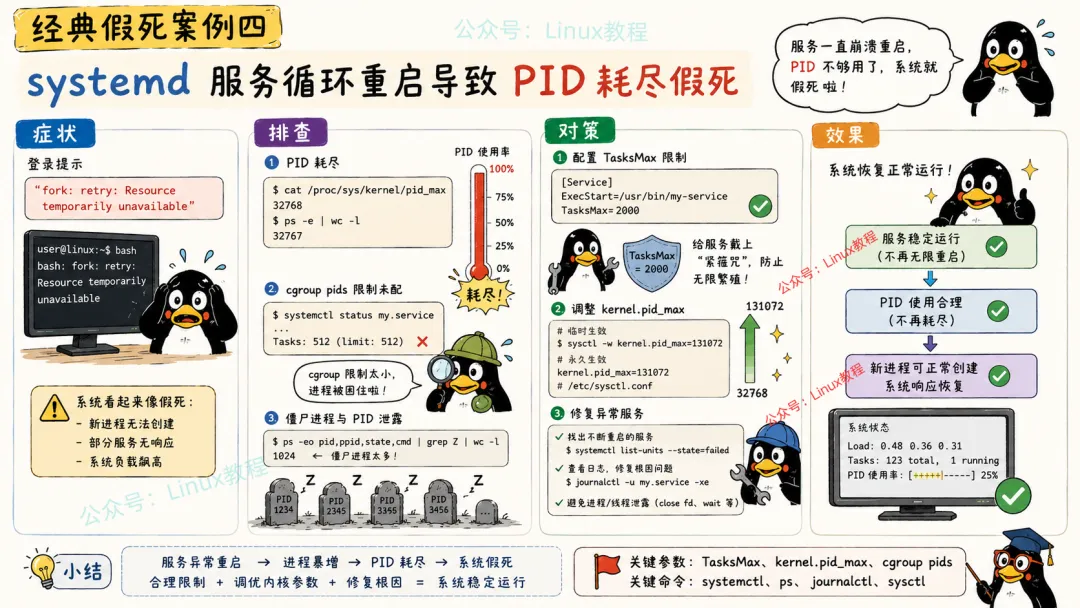
排查过程:
既然ssh不行,用带外管理进系统。登录进去了(还好有iDRAC),敲任何命令都提示:
-bash: fork: retry: Resource temporarily unavailable-bash: fork: retry: Resource temporarily unavailable-bash: fork: retry: Resource temporarily unavailable-bash: fork: retry: Resource temporarily unavailable-bash: fork: Resource temporarily unavailable连ls都执行不了。
检查PID使用情况:
# 还好/proc还能访问ls -1 /proc | grep -E '^[0-9]+$' | wc -l# 输出:32766PID用满了!Linux默认的pid_max是32768。
看进程列表:
# 用xargs避免forkls /proc | grep -E '^[0-9]+$' | xargs -r -n 1 cat /proc/... 2>/dev/null | head但这样太慢,换个方式:
ps aux --no-headers 2>/dev/null | wc -l# 不行,ps需要fork# 直接读/procfind /proc -maxdepth 1 -name '[0-9]*' -type d | wc -l看到了很多docker-containerd-shim进程。
用strace跟踪一个正在fork的进程(虽然慢):
strace -p 1234 2>&1 | head# 看到很多clone调用返回EAGAIN根本原因:
有个systemd服务配置错了,Restart=always,但启动脚本里有个bug导致立即退出。systemd看到服务退出,又马上重启。这样来回循环,每分钟fork几十次。跑了几天后,PID终于用完了。
更坑的是,这个服务还忘了设置PIDFile,systemd不知道它退出后,旧的进程信息还在cgroup里,导致僵尸进程残留。
解决方案:
紧急措施:
# 先扩大pid_max,起码能让人登录echo 65536 > /proc/sys/kernel/pid_max然后找到那个疯狂重启的服务:
systemctl list-units --state=failed# 看到foo.service状态是failedsystemctl status foo.service# 显示start limit hitsystemctl stop foo.servicesystemctl disable foo.service清理僵尸进程和残留的cgroup:
# 重启systemd让cgroup清理systemctl daemon-reexec长期修复:
1. 修复服务脚本里的bug,确保启动后保持运行 2. systemd配置优化:
# /etc/systemd/system/foo.service[Service]Restart=on-failure # 别用alwaysRestartSec=30 # 重启间隔30秒StartLimitBurst=3 # 10秒内最多重启3次StartLimitInterval=10TasksMax=50 # 限制最多50个进程3. 调整系统级PID限制:
# /etc/sysctl.confkernel.pid_max = 131072kernel.threads-max = 1310724. 部署监控,检测PID使用率:
#!/bin/bash# 每天检查一次PID使用率used=$(ls /proc | grep -cE '^[0-9]+$')max=$(cat /proc/sys/kernel/pid_max)rate=$((used * 100 / max))if [ $rate -gt 85 ]; then echo "PID usage high: $rate%" | mail -s "Alert" admin@example.comfi这个案例让我印象深刻:再小的配置错误,乘上时间都会变成灾难。
写了这么多,回头一看快两万字了。不知道你有没有发现,这些假死案例有个共同点:大部分都不是真的死,而是卡在某个资源上不肯出来。
我跟很多新手说,遇到假死别慌。先问问自己几个问题:
• 能ping通吗?能ping说明网络协议栈还在 • 键盘的NumLock灯能切换吗?能切换说明键盘中断还能处理 • SysRq有反应吗?有反应说明内核还活着
只要有一个回答“是”,就还有救。
最后分享一个我用了十年的“假死急救包”:
# 当系统卡住时,试试这个顺序(前提是能进shell或者有带外管理)# 1. 先看负载和IOcat /proc/loadavgiostat -x 1# 2. 看看哪些进程在等IOps aux | awk '$8=="D" {print}'# 3. 触发SysRq收集信息echo t > /proc/sysrq-trigger # 打印所有进程状态echo w > /proc/sysrq-trigger # 打印阻塞的任务echo m > /proc/sysrq-trigger # 打印内存信息# 4. 如果只是某个服务卡住,重启它systemctl restart 服务名# 5. 实在不行,安全重启(不是硬重启!)echo s > /proc/sysrq-trigger # 同步文件系统echo u > /proc/sysrq-trigger # 重新挂载只读echo b > /proc/sysrq-trigger # 重启七、真正有经验的人,排查假死时都在看什么
很多新人排障时习惯上来就是一个top,然后就没了。
其实Linux假死最麻烦的地方在于,很多关键数据稍纵即逝,机器一重启,现场全没了。所以真正有经验的人,第一反应永远是“保现场”,而不是“重启试试”。
如果能SSH进去,先别急着乱kill,优先采集数据。uptime看一眼负载,vmstat 1和iostat -xz 1盯着IO,sar -n DEV 1看看网络。然后跑一下ps -eo state,pid,wchan:32,cmd,重点关注D状态进程。很多人忽略wchan(等待通道)这列,其实它价值极高——看到futex_wait、nfs_wait、io_schedule这些关键字,线程卡在哪类资源上一目了然。
SysRq是线上救命技能,真的。不会这个,很多事故只能靠瞎猜。最常用的几个:echo w > /proc/sysrq-trigger打印阻塞的任务,echo t > /proc/sysrq-trigger打印所有线程的调用栈,echo m > /proc/sysrq-trigger看内存状态,echo s > /proc/sysrq-trigger紧急同步文件系统。有时候SSH连不上,但串口console还活着——这就是为什么大型生产环境里IPMI、iDRAC、iLO这些带外管理手段特别重要。
另外,hung task日志别多看几眼,很多人看到“blocked for more than 120 seconds”就觉得是噪音,其实这玩意儿经常是破案入口,尤其调用栈里出现jbd2、xfsaild、nfsd、futex_wait_queue这些函数名,问题马脚一下就出来了。
至于crash和vmcore,真的值得大家花时间学,我以前也觉得“这太内核了”,后来发现真正复杂的hard lockup,没有vmcore基本没法查。建议生产环境开启kdump,很多公司嫌占内存不开,等真出lockup只能瞎猜,特别亏。crash常用命令就那么几个:bt、bt -a、ps、kmem、files、log,够用很久了。
八、我自己的假死排障思路
写到这里差不多了,不过我还是想聊点偏主观的东西。
这些年线上事故处理下来,我最大的感受其实不是技术,而是Linux假死特别考验人的心理素质。它不像panic那样明确——panic至少会告诉你“我挂了”;而假死会给你一种“好像还能救”的错觉,于是你开始重试SSH、疯狂敲回车、反复top、重启服务,最后把现场彻底污染。
我现在一般会这么干:
第一步,判断机器还有多少活性——ping是否正常、SSH是否能进、SysRq是否有效、串口是否有输出。
第二步,优先抓现场——日志、调用栈、vmstat、D状态进程,别急着reboot。
第三步,区分问题类型——CPU、IO、内存、锁、驱动、网络,别一上来就说“系统卡了”,太笼统。
第四步,判断是否需要保vmcore,尤其是hard lockup,真的很难复现。
第五步,再考虑恢复业务。
很多年轻同学容易反过来:先重启,再找原因,结果永远查不出来,同一个问题隔三个月再炸一次,人直接崩溃。
初入行时,我深信“完美调优=不出问题”。但现实是:复杂系统必然故障,区别只在于你能否从混乱中找到线索。Linux假死尤其如此。

