用户态的抢占很简单:时钟中断到了,标记一下 TIF_NEED_RESCHED,等进程从内核返回用户态的时候检查一下,需要调度就切走。
但内核态就麻烦了。进程正在改链表、持着自旋锁、操作硬件寄存器,这时候被打断,数据结构就是坏掉的。
所以内核面临一个根本问题:怎么区分"可以安全打断的地方"和"不能打断的地方"?
这就是 preempt_count 要解决的事。
preempt_count 的设计哲学
Linux 用一个整数 preempt_count 来表示"当前有多不安全":
/* include/linux/preempt.h */
#define preempt_count() (current_thread_info()->preempt_count)
这个整数是个位域计数器,不同位段记录不同类型的"不安全状态":
Bit 0-7 : preempt_disable() 计数(显式禁抢)
Bit 8-15 : softirq 计数(正在处理软中断)
Bit 16-27 : hardirq 计数(正在处理硬中断)
Bit 28 : PREEMPT_ACTIVE 标志(正在执行抢占调度)
判断规则只有一个:
#define preemptible() \
(preempt_count() == 0 && !irqs_disabled())
preempt_count == 0 且没关中断,才能抢占。就这么简单。
preempt_enable 的完整路径
每次 preempt_enable() 都会检查是否需要抢占:
/* include/linux/preempt.h */
#define preempt_enable() \
do { \
barrier(); /* 编译屏障,防止重排 */ \
preempt_count_dec(); /* 计数减 1 */ \
if (unlikely(preempt_count() == 0 && need_resched())) \
__preempt_schedule(); /* 触发抢占 */ \
} while (0)
注意这个逻辑:只在 preempt_count 恰好归零的那一瞬间才检查 need_resched。如果嵌套了三层 preempt_disable(),只有最后一层 enable 会检查。这是对的——你不可能在别人说"别抢我"的时候去抢。
来看一个实际例子:
$ cat /proc/self/status | grep -i preempt
Preempt_depth: 0
preempt_depth 为 0 说明当前可以安全抢占。如果进程在内核态持着自旋锁,你会看到它大于 0。
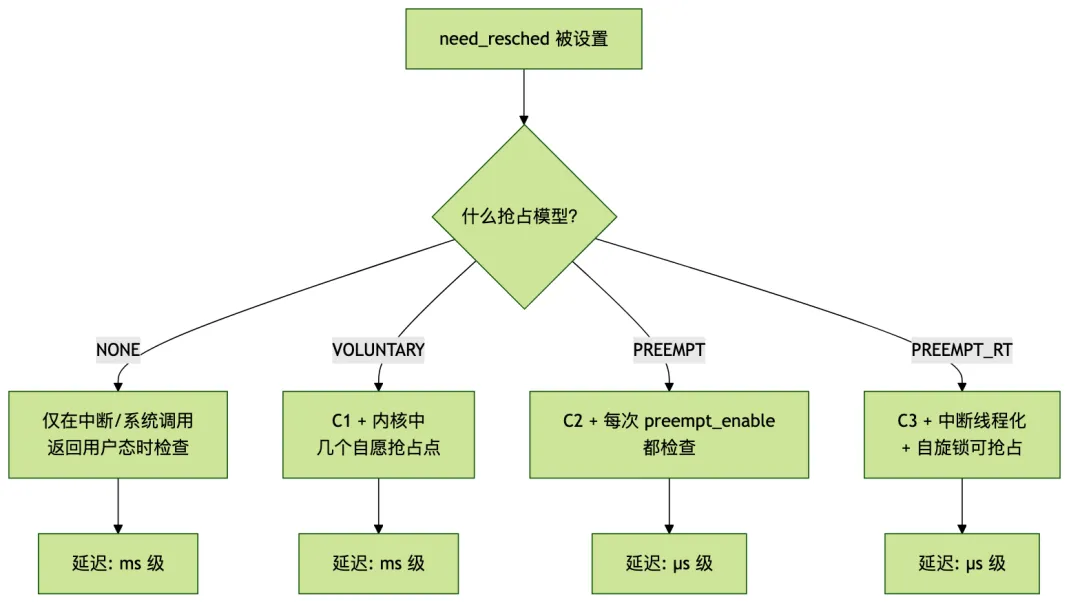
四种抢占模型的本质
很多人把 PREEMPT_NONE、PREEMPT_VOLUNTARY、PREEMPT、PREEMPT_RT 当成四种不同的东西。但从第一性原理看,它们的区别只有一个:允许在多少地方检查 need_resched。
具体来说:
PREEMPT_NONE:最保守。只有在 ret_from_intr 和 ret_from_sys_call 这些汇编路径上才会检查。进程进了内核态,就算时间片用完了,也得等它自己出来。
PREEMPT_VOLUNTARY:在 NONE 的基础上,内核代码里加了几个 cond_resched() 调用点。本质上就是开发者在"我觉得这里比较安全"的地方主动让出 CPU。
PREEMPT:这才是真正的内核态抢占。每次 preempt_enable() 归零时都会检查 need_resched,如果需要调度就立即 schedule()。这是大多数桌面 Linux 的默认配置。
PREEMPT_RT:在 PREEMPT 的基础上更进一步——把中断处理线程化(原来中断上下文不能调度,现在变成内核线程就可以调度了),把自旋锁改成可抢占的 rt_mutex。
查看当前内核的抢占模型:
$ grep PREEMPT /boot/config-$(uname -r)
CONFIG_PREEMPT=y
# CONFIG_PREEMPT_DYNAMIC is not set
抢占是怎么发生的
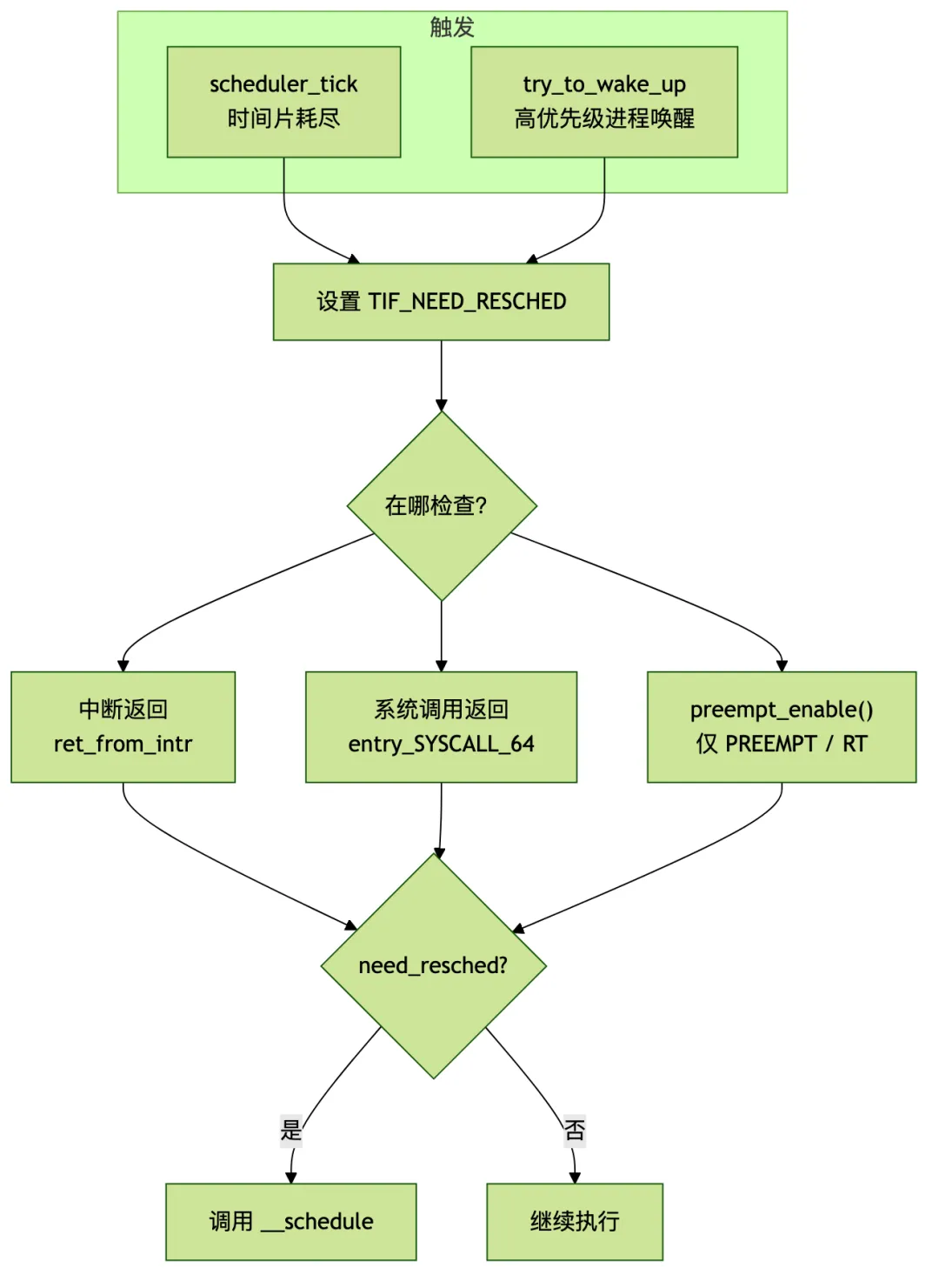
抢占不是魔法,就是三个步骤:触发 → 检查 → 执行。
谁触发 need_resched
/* kernel/sched/core.c — 时间片用完 */
void scheduler_tick(void)
{
curr->sched_class->task_tick(rq, curr, 0);
/* 如果当前进程时间片耗尽,设置 TIF_NEED_RESCHED */
}
/* kernel/sched/core.c — 唤醒更高优先级进程 */
static int try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
{
/* ... */
if (p->prio < rq->curr->prio)
resched_curr(rq); /* 设置当前运行进程的 TIF_NEED_RESCHED */
}
两个最常见的触发场景:时钟中断发现时间片用完了,或者唤醒了一个更高优先级的进程。
在哪里检查
检查点一:中断返回路径(汇编层面)
/* arch/x86/entry/entry_64.S */
SYM_INNER_LABEL_ALIGN(ret_from_intr, SYM_L_GLOBAL)
INTERRUPT_RETURN
SYM_CODE_START(noinstr interrupt_entry)
/* ... 中断处理 ... */
/* 返回时检查是否需要抢占 */
testb $TIF_NEED_RESCHED, CS_OFFSET+THREAD_INFO_FLAGS(%rsp)
jnz int_with_check
jmp restore_regs_and_iret
这是所有抢占模型都有的检查点——不管你编译的是 NONE 还是 RT,中断返回时都会看一眼 need_resched。
检查点二:系统调用返回
/* arch/x86/entry/entry_64.S */
SYM_INNER_LABEL(entry_SYSCALL_64_after_hwframe, SYM_L_GLOBAL)
movq %rsp, %rdi
call do_syscall_64 /* 执行系统调用 */
/* 返回时检查 need_resched */
movq %rsp, %rdi
call syscall_return_slowpath
/* 如果需要调度,跳转到 schedule() */
检查点三:preempt_enable()(仅 PREEMPT 和 RT)
这就是 PREEMPT 和 NONE 的核心区别。PREEMPT 模式下,每次 preempt_count 归零都会检查:
/* kernel/sched/core.c */
asmlinkage __visible void __sched notrace preempt_schedule(void)
{
struct task_struct *tsk = current;
do {
preempt_disable();
__schedule(SM_NONE); /* 立即调度 */
sched_preempt_enable_no_resched();
} while (need_resched());
}
来一张完整流程图:
schedule() 做了什么
一旦决定要抢占,最终都会走到 __schedule():
/* kernel/sched/core.c */
static void __sched notrace __schedule(unsigned int sched_mode)
{
struct task_struct *prev, *next;
struct rq *rq;
rq = cpu_rq(smp_processor_id());
prev = rq->curr;
next = pick_next_task(rq, prev, NULL); /* 从运行队列选下一个进程 */
if (likely(prev != next)) {
rq->curr = next;
rq->nr_switches++;
/* 切换上下文 */
context_switch(rq, prev, next, RF_ENABLED);
}
}
context_switch 是真正干活的地方:
/* kernel/sched/core.c */
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
/* 切换地址空间(如果需要) */
if (!next->mm) /* 内核线程 → 使用 prev 的 mm */
enter_lazy_tlb(prev->mm, next);
/* 切换页表 */
switch_mm_irqs_off(prev->active_mm, next->mm, next);
/* 切换寄存器和栈指针(汇编实现) */
switch_to(prev, next, prev);
return rq;
}
switch_to 是一段架构相关的汇编代码,做的事情就是保存当前 CPU 的所有寄存器到 prev 的 task_struct,然后从 next 的 task_struct 恢复。执行到这里之后,"当前进程"就已经变了。
用 cyclictest 验证
理论讲完了,拿数据说话。用 cyclictest 测量调度延迟:
$ sudo apt install rt-tests
$ sudo cyclictest -m -n -p 80 -i 1000 -l 100000
# -m: 锁内存 -n: nanosleep -p 80: 优先级80 -i 1000: 间隔1ms -l 100000: 10万次
T: 0 ( 1956) P:80 I:1000 C:100000 Min: 8 Act: 12 Avg: 15 Max: 182
同一台机器,换成 PREEMPT_RT 内核:
T: 0 ( 1956) P:80 I:1000 C:100000 Min: 5 Act: 8 Avg: 9 Max: 47
| 指标 |
PREEMPT |
PREEMPT_RT |
| 最小延迟 |
8μs |
5μs |
| 平均延迟 |
15μs |
9μs |
| 最大延迟 |
182μs |
47μs |
最大延迟差了将近 4 倍。这就是 PREEMPT_RT 的价值——不是平均延迟更好,而是尾延迟可控。实时系统最怕的不是"偶尔慢一点",而是"不知道什么时候会突然慢 200μs"。
我之前优化一个交易系统时就踩过这个坑:PREEMPT 内核下,99.9% 的订单延迟都在 50μs 以内,但每分钟都有那么几次突然飙到 200μs 以上,最后换成 PREEMPT_RT 才稳定下来。
怎么选
| 场景 |
选型 |
理由 |
| 数据库/大数据 |
PREEMPT_NONE |
吞吐量优先 |
| 通用服务器/桌面 |
PREEMPT |
低延迟,默认配置 |
| 实时/金融/工业控制 |
PREEMPT_RT |
尾延迟可控 |
没有什么"最好"的配置,看你的业务能不能容忍不可预测的延迟尖刺。能容忍就 NONE,不能就 RT。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
