最近用 CDS API 下载了 ERA5 数据集的几个变量,遇到了一些坑,这里记录并分享给大伙,包含数据处理相关的代码。
找到模板数据集,然后按需点选即
2.一定要注意右侧或下侧的"Request size"不能超标
打开 Show API request code,复制代码,粘贴到编辑器
批量下载多年每年的3-9月850hpa的比湿、风速
import cdsapiimport osfrom calendar import monthrangeclient = cdsapi.Client()dataset = "derived-era5-pressure-levels-daily-statistics"# 设置参数years = range(2005, 2025) # 2005-2024年months = range(3, 10) # 3-9月# 创建保存目录os.makedirs("./ERA5", exist_ok=True)for year in years: for month in months: # 获取该月天数 ndays = monthrange(year, month)[1] days = [f"{d:02d}"for d in range(1, ndays + 1)] # 构建请求 request = { "product_type": "reanalysis", "variable": [ "specific_humidity", "u_component_of_wind", "v_component_of_wind", ], "year": str(year), "month": f"{month:02d}", "day": days, "pressure_level": ["850"], "daily_statistic": "daily_mean", "time_zone": "utc+00:00", "area": [35, 100, 15, 125], # [north, west, south, east] } # 文件名:年-月.zip zip_filename = f"./ERA5/{year}_{month:02d}.zip" # 检查文件是否已存在 if os.path.exists(zip_filename): print(f"文件 {zip_filename} 已存在,跳过下载") continue print(f"正在下载: {year}年{month:02d}月...") try: # 下载并保存为zip文件 client.retrieve(dataset, request, zip_filename) print(f"完成: {zip_filename}") except Exception as e: print(f"下载失败 {year}_{month:02d}: {e}")
client.retrieve(dataset, request, filename)
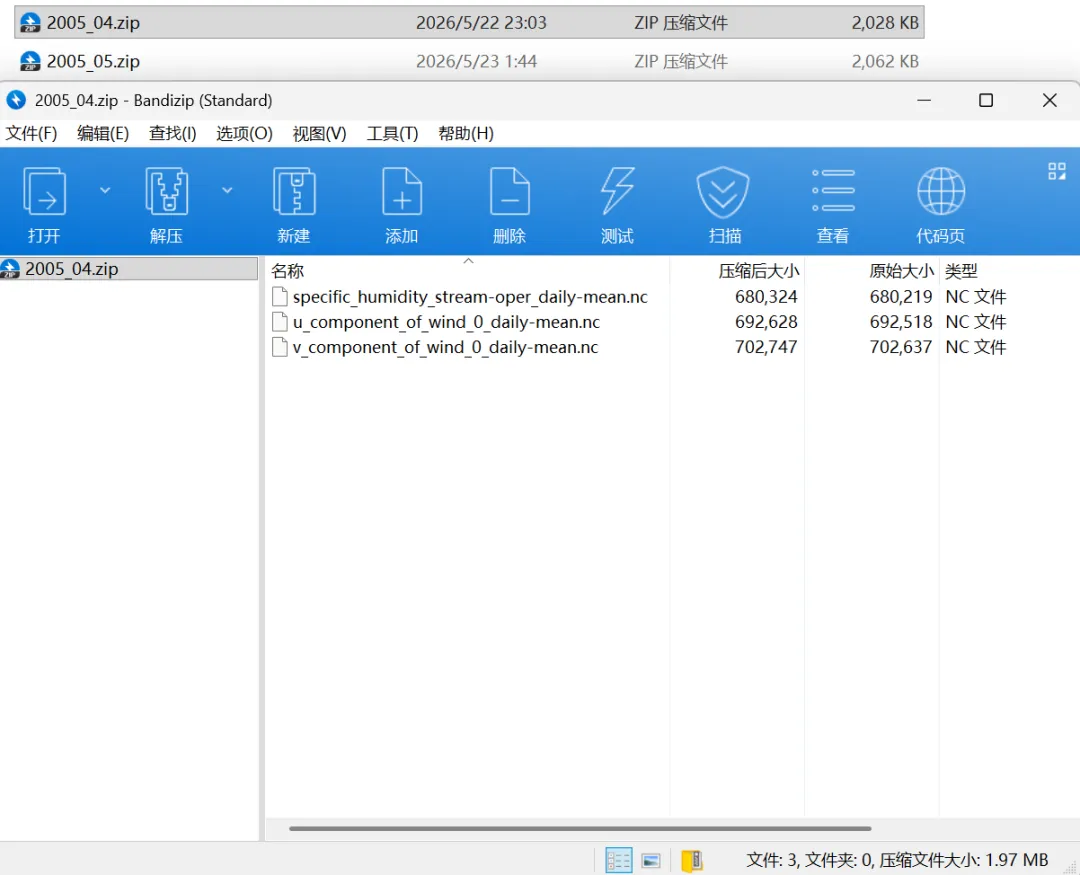
这里的filename一定要是zip后缀。大家在官网可以下载一天的数据,用Submit form提交,然后观察下载下来的数据,是zip文件。所以我们使用API下载的时候,也要设置为zip格式,里面一个压缩文件对应三个变量的nc文件。
检查是否下载的哪个文件数据有问题
from pathlib import Pathimport zipfilebad_files = []for f in Path(".").glob("*.zip"):try: with zipfile.ZipFile(f, "r") as z: z.testzip() # 测试完整性 except Exception as e: print(f"坏文件: {f}") print(e) bad_files.append(f)print("\n总坏文件数:", len(bad_files))
合并多个变量构建数据集
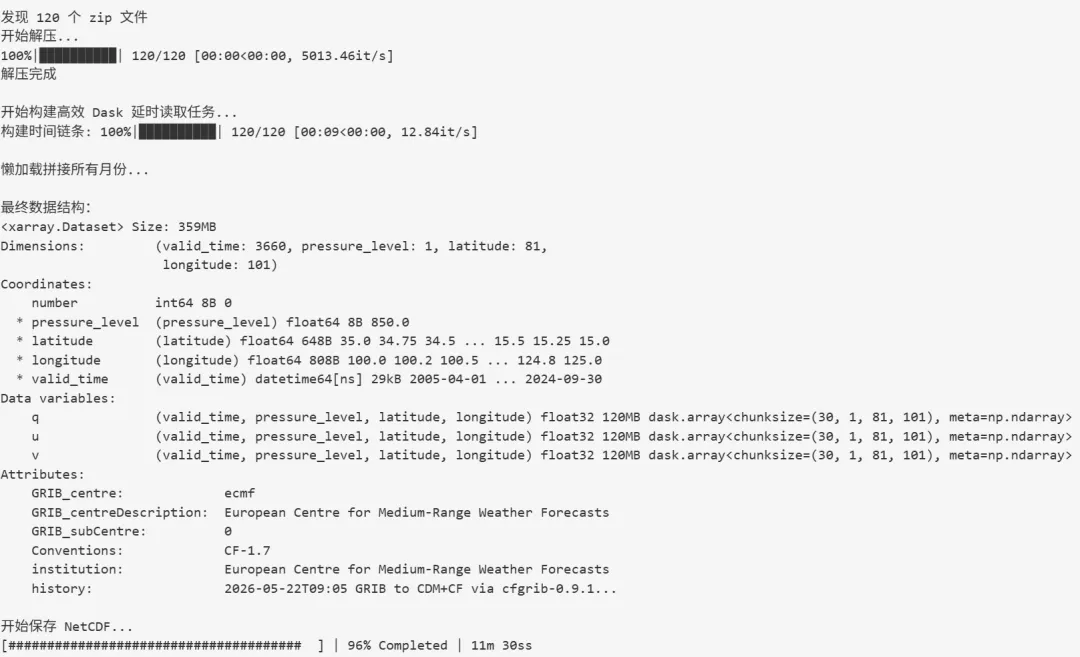
import osimport reimport zipfilefrom pathlib import Pathimport xarray as xrfrom tqdm import tqdmimport dask# ============================================================# 0. 工作目录与初始化# ============================================================os.chdir(r'你的数据路径')data_dir = Path("./")extract_root = Path("./unzipped")extract_root.mkdir(exist_ok=True)# ============================================================# 1. 解压(保持你原本的高效解压逻辑)# ============================================================pattern = re.compile(r"^\d{4}_\d{2}\.zip$")zip_files = sorted([f for f in data_dir.iterdir() if pattern.match(f.name)])print(f"发现 {len(zip_files)} 个 zip 文件\n开始解压...")for zip_path in tqdm(zip_files): outdir = extract_root / zip_path.stem if outdir.exists(): continue outdir.mkdir(exist_ok=True) try: with zipfile.ZipFile(zip_path, "r") as z: z.extractall(outdir) except zipfile.BadZipFile: print(f"坏文件,跳过: {zip_path}") continueprint("解压完成")# ============================================================# 2. 最高效的单步读取与合并策略# ============================================================print("\n开始构建高效 Dask 延时读取任务...")# 找出所有的月度文件夹monthly_dirs = sorted([d for d in extract_root.iterdir() if d.is_dir()])# 定义一个预处理函数:负责在【单个文件夹内部】合并变量,完全避免全局对齐def process_single_month(month_dir): # 使用 open_dataset 配合 chunks 开启懒加载 # drop_variables 确保不加载无关的冲突坐标 q_file = list(month_dir.glob("specific_humidity*.nc"))[0] u_file = list(month_dir.glob("u_component*.nc"))[0] v_file = list(month_dir.glob("v_component*.nc"))[0] # 单个文件读取非常快,指定统一的 chunks ds_q_m = xr.open_dataset(q_file, chunks={"valid_time": 100}) ds_u_m = xr.open_dataset(u_file, chunks={"valid_time": 100}) ds_v_m = xr.open_dataset(v_file, chunks={"valid_time": 100}) # 局部合并(同一月份的坐标绝无冲突,xarray 不需要做复杂的对齐) merged_m = xr.merge([ds_q_m, ds_u_m, ds_v_m]) return merged_m# 批量加载所有月份datasets = []for m_dir in tqdm(monthly_dirs, desc="构建时间链条"): try: datasets.append(process_single_month(m_dir)) except Exception as e: print(f"文件夹 {m_dir.name} 读取失败,跳过. 错误: {e}")# 在时间维度(valid_time)上拼接所有月份(按顺序拼接,无需排序)print("\n懒加载拼接所有月份...")ds_final = xr.concat(datasets, dim="valid_time")print("\n最终数据结构:")print(ds_final)# ============================================================# 3. 压缩写出优化# ============================================================print("\n开始保存 NetCDF...")encoding = { var: { "zlib": True, "complevel": 4, # 4级是性价比最高的平衡点 "dtype": "float32" } for var in ds_final.data_vars}# 终极提速:在写入前,显式配置 Dask 并行诊断(可以看进度条)from dask.diagnostics import ProgressBarwith ProgressBar(): ds_final.to_netcdf( "ERA5_q_uv_2005_2024.nc", encoding=encoding )print("\n完成!")





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
