爬虫本质上是一种通过编程自动化地从网站中采集数据的技术。你可以试着打开任意一个网页,右键选择"查看网页源代码",你看到的那些HTML标签就是网页的结构,而爬虫则相当于一个替你浏览并提取这些页面信息的"自动化助手"。
这篇文章会手把手带你从零构建一个Python爬虫程序,哪怕你从未写过一行代码,也能轻松学会。废话不多说,我们开始。
一、爬虫的核心工作步骤
1.发起请求:爬虫对目标网站发起HTTP请求,拿到页面的响应内容。
2.解析页面:对返回的页面数据进行分析,从中筛选出你所需要的信息。
3.存储数据:把筛选出来的信息写入文件或存入数据库,方便后续使用和分析。
二、主流爬虫工具库
Python生态中,有两个被广泛使用的爬虫相关库:
requests:负责发起网络请求,获取页面的响应数据。
BeautifulSoup:负责对页面内容进行解析,从中抽取目标数据。
1. 安装库
在开始之前,你需要先把这两个库装好。打开终端或命令提示符,运行如下安装命令即可:
三、入门爬虫实战
下面,我们动手写一个基础爬虫,从某个网页中抓取数据。
1. 请求网页内容
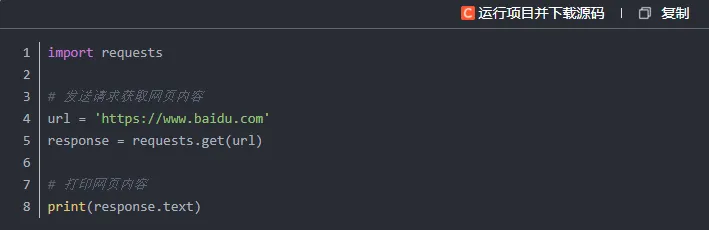
第一步要做的是借助 requests 库向目标网址发起请求,拿到页面数据,这里我们拿百度首页来做演示。
解释:
requests.get(url) 的作用是向目标URL发送GET请求并接收响应。
response.text 可以拿到页面完整的HTML源码。
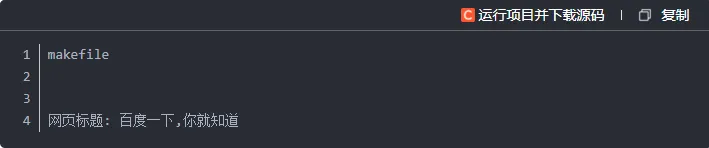
执行代码后,控制台会输出一大段HTML标签内容,这就是百度首页的源码。
2. 解析页面数据
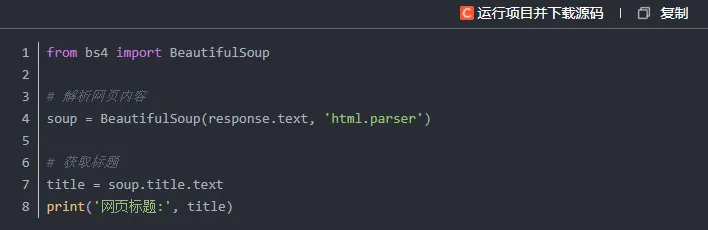
拿到页面源码之后,下一步就是利用 BeautifulSoup 库对HTML进行解析,定位并提取我们关心的内容,下面演示如何获取百度首页的标题。
解释:
BeautifulSoup(response.text, 'html.parser') 的功能是将HTML文本转化为可操作的解析对象。
soup.title.text 能够提取出页面的标题文本。
输出:
3. 抓取更多数据
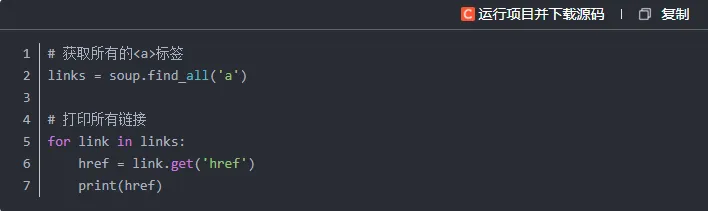
我们再进一步,尝试提取页面中所有的超链接(即 <a> 标签里的 href 属性值)。这在实际场景中很实用,比如你想批量采集某个站点下的所有文章地址。
解释:
soup.find_all('a') 能够找到页面中全部的超链接元素。
link.get('href') 用于读取每个链接元素的 href 属性,也就是对应的网址。
四、爬虫的类型划分
1. 静态网页爬虫
如果目标页面是静态渲染的,所有数据都直接嵌在HTML源码里,这类页面抓取起来最为简单。前面的示例就属于典型的静态页面爬虫。
2. 动态网页爬虫(应对JavaScript渲染)
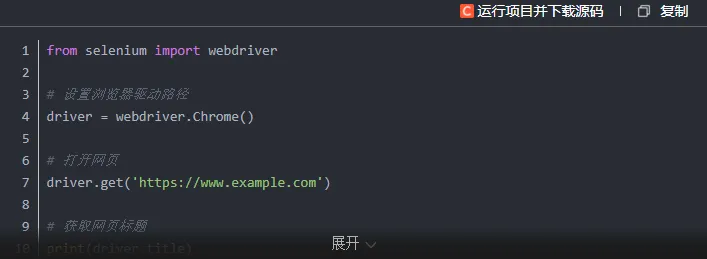
部分网站的数据并非直接写在HTML中,而是依靠JavaScript在浏览器端动态加载生成的。面对这类页面,需要采用更高级的手段,一般会借助 Selenium 这类工具来模拟真实浏览器的行为。
安装Selenium:
Selenium 能够像真人操作浏览器一样与页面互动,包括点击按钮、上下滚动等操作。例如需要采集动态加载的数据时,就可以用Selenium先让页面完整渲染出来。
示例:
3. 专业爬虫框架(Scrapy)
当你的需求是大批量、高效率地采集数据时,可以选用专业的爬虫框架——Scrapy。Scrapy 是一款功能强大的爬虫框架,支持异步并发、运行效率高,非常适合搭建结构复杂的爬虫系统。
安装Scrapy:
五、爬虫常见难题与应对策略
1. 反爬虫机制
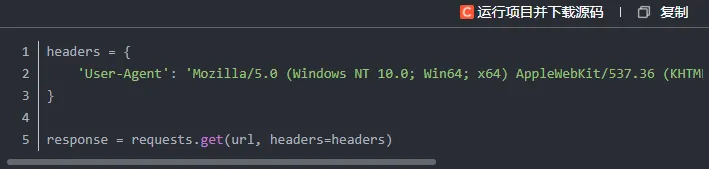
不少网站会对爬虫进行拦截,常见手段包括检测请求头信息或识别IP地址来阻止自动化访问。要突破这类限制,我们可以将请求伪装成普通用户的浏览行为。
解决方法:添加请求头
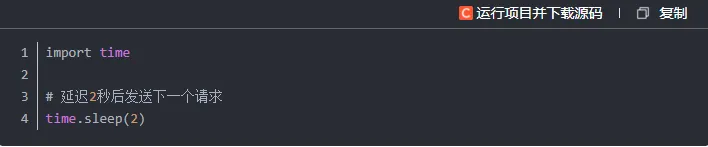
2. 延迟访问
短时间内高频访问同一网站很容易触发反爬策略,我们可以在每次请求之间加入适当的时间间隔来规避这个问题。
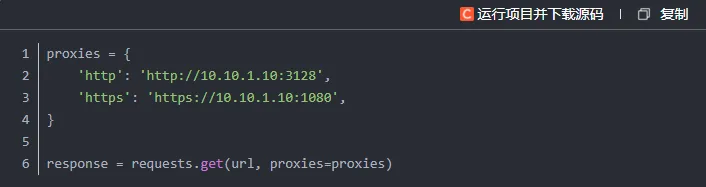
3. IP代理
如果网站是通过识别IP地址来限制访问频率的,我们可以借助代理IP来轮换请求来源。
六、数据保存
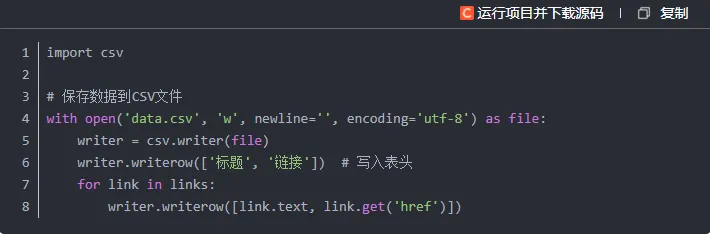
当我们成功提取到目标信息后,一般需要将数据持久化保存。常见的存储方式包括写入CSV文件或存入数据库。
1.保存到CSV文件
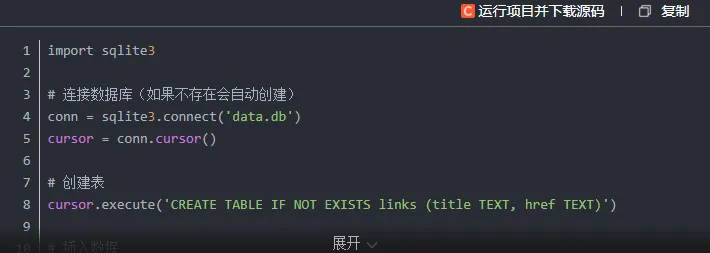
2.保存到数据库
可以使用 SQLite 或其他数据库,将数据保存到数据库中。
七、总结回顾
1.爬虫的核心流程:发起请求,解析页面,提取数据并保存。
2.常用工具库:requests 负责网络请求,BeautifulSoup 负责HTML解析。
3.进阶方向:动态页面需要借助 Selenium 处理,大规模采集推荐使用 Scrapy 框架。
4.反爬应对:通过伪造请求头、控制访问频率以及使用代理IP等手段来突破反爬限制。