深空探测器离地球几亿公里,传回来的信号微弱到接收端几乎是一片噪声。能把数据从噪声里捞回来的,是纠错码。CCSDS(空间数据系统咨询委员会)给深空链路定的 AR4JA LDPC 码,比老一代的 Viterbi 卷积码多出 3 dB 以上的增益。3 dB 是什么概念:同样的发射功率能传更远,或者同样距离能塞进更多数据。
MATLAB 的 Wireless HDL 工具箱里,直接有一个现成的 AR4JA LDPC 解码器 IP,一键就能生成 FPGA 硬件。问题来了:如果我们不手写 Verilog,而是用一套"把 Python 算法自动变成硬件"的框架去做,做出来的解码器,能不能和这个厂商 IP 掰手腕?
我们把 9 种配置全做完,和 MATLAB 逐位对照,再在 FPGA 上真实布线测了一遍。这篇文章讲的就是结果。
Python → RTL
零手写 Verilog,自动生成 9 种硬件
1AR4JA LDPC 是个什么码
AR4JA 是 CCSDS 131.0-B-3 标准里的一族码,专门为深空通信设计。它有 9 种配置,来自 3 种信息块长(1024、4096、16384 位)和 3 种码率(1/2、2/3、4/5)的组合。块越长、码率越低,纠错越强,硬件也越大。
LDPC 的解码是"迭代"的:解码器拿到一串带噪声的软信息,来回猜几遍,每一遍都让答案更接近一个合法码字,几轮之后收敛到正确结果。所以衡量一个 LDPC 解码器,主要看三件事:解得对不对、解得快不快、占的芯片资源省不省。下面就按这三件事来对。
2不手写硬件,让框架自己生成
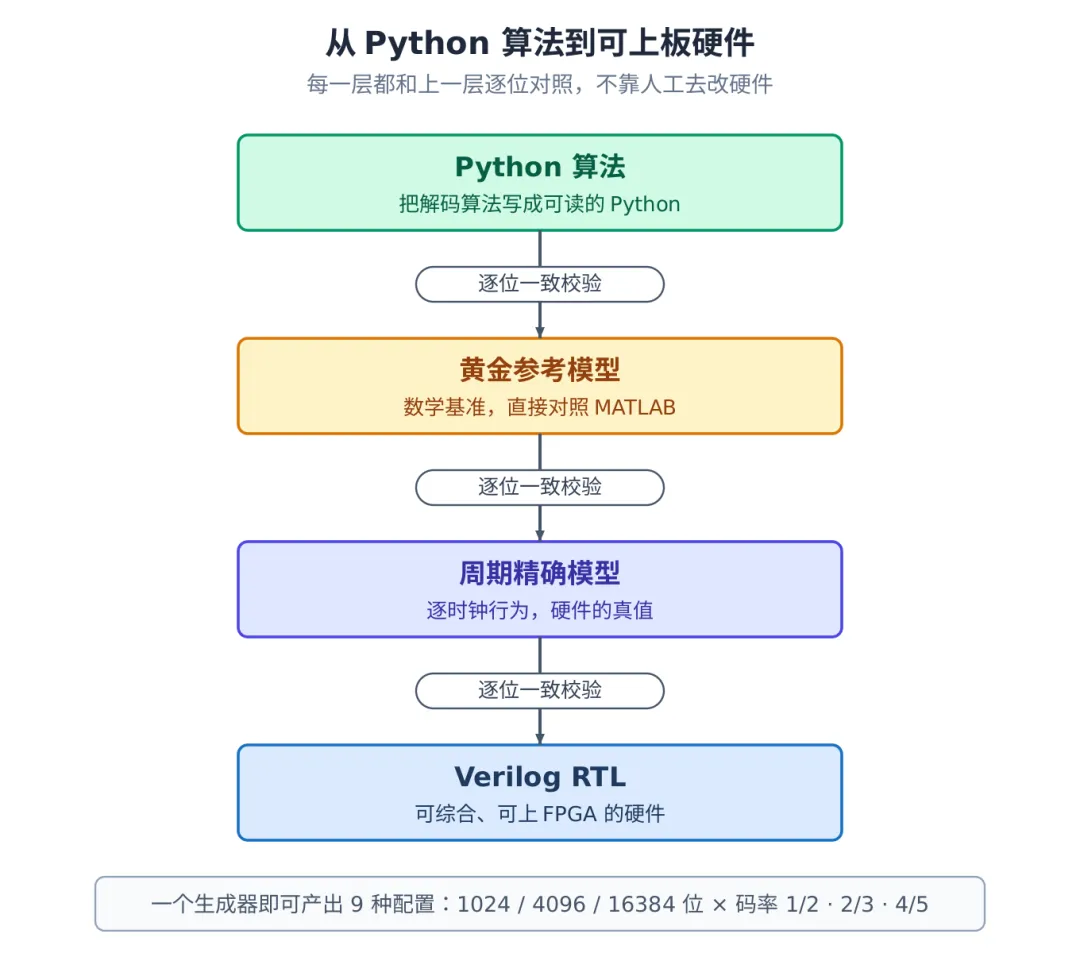
我们没有手写 Verilog,而是让框架从同一份 Python 算法一路自动往下生成硬件。中间隔着两个"对照层":先把算法写成一个纯数学的黄金参考模型,再写一个逐时钟行为的周期精确模型,最后才翻译成可综合的 Verilog。关键在于,相邻两层之间都要逐位一致,差一个比特都不放过。
从 Python 算法到可上板硬件
图 1:从 Python 算法到可上板硬件,每一层都和上一层逐位对照。
更省事的是,9 种配置不是各写一套,而是同一个生成器读入不同的校验矩阵后自动产出,没有一处硬件是为某个特定配置手工写死的。这点后面会看到好处:把 9 种配置一起生成、一起验证,反而把那些"只在某个尺寸下才会犯"的隐藏 bug 都逼了出来。
3对不对:和 MATLAB 逐位一样
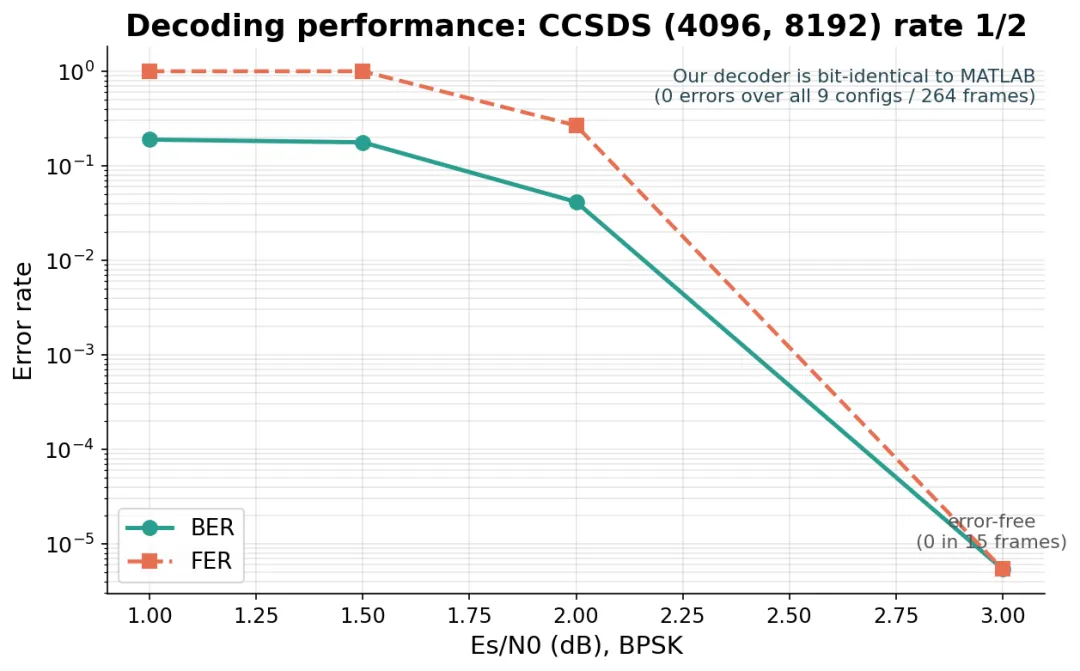
正确性是底线。我们把同一批带噪声的帧,分别喂给自己的解码器和 MATLAB 的 ldpcDecode,逐位比对。结果是 9 种配置、264 帧,零误码,每一个判决比特都和 MATLAB 完全一致,连那些没收敛的难帧也一样。
误码与误帧曲线
图 2:(4096, 8192) 码率 1/2 的纠错性能曲线,信噪比一过门限误码就掉到零。我们的解码器与 MATLAB 逐位相同,两条曲线是重合的。
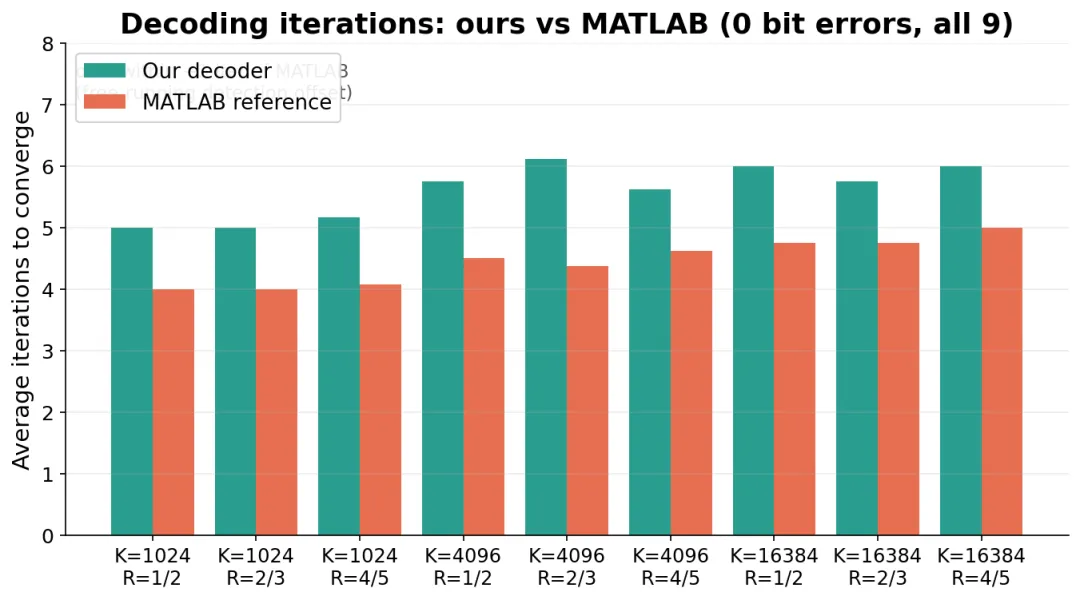
收敛速度也基本一致:正常工作信噪比下,两边都是几轮迭代就纠对,轮数也几乎一样。
平均收敛迭代次数
图 3:平均收敛迭代次数,我们 vs MATLAB,9 种配置全部零误码。
为什么我们多跑了大约一轮
仔细看图 3 会发现,我们平均比 MATLAB 多跑大约一轮。这不是说我们解得更慢。在同一轮里,码字其实已经被纠对了。差别在于"什么时候发现它对了"。
MATLAB 每跑完一轮,会专门停下来验一次校验和,所以它在码字变对的那一轮就停。我们的硬件用了一个更"顺手"的办法:不额外停下来验,而是在下一轮往前读数据的时候,顺便看一眼"是不是已经全对了"。这样检查几乎不花额外硬件,也不占额外时钟,代价是发现"对了"的时刻,比码字真正变对晚了一轮。
那多出来的一轮,买的是 一次完全免费的提前停止。对吞吐来说,这是笔划算的买卖。
4好不好:吞吐、时钟、面积
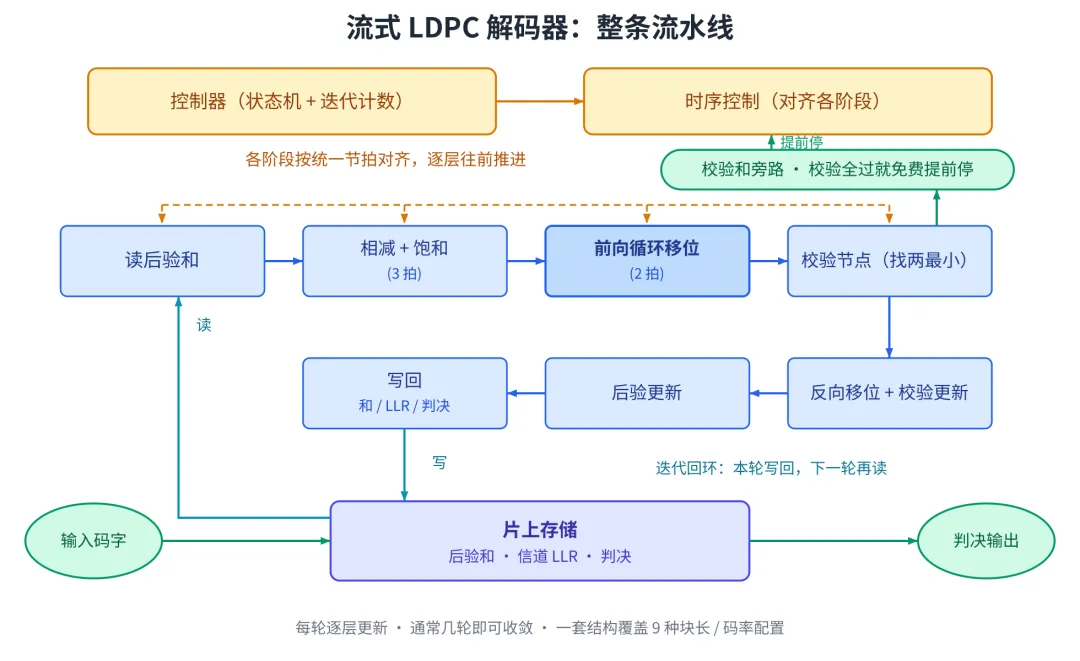
先看流式解码器长什么样。数据像流水线一样不停往前走:从存储器读出、循环移位、过一段桥接延迟、在校验节点找出两个最小值、再写回;写回之后进入下一轮迭代,复用同一套硬件。前面提到的"免费提前停止",就是图里那条绿色的旁路。
流式解码器的数据通路
图 4:流式解码器的数据通路,每一轮迭代复用同一套硬件。
性能这块走过一段弯路,得专门讲一下。
一开始,9 种配置里只有 1 种的吞吐打得过 MATLAB。瓶颈不在算得快不快,而在流水线里的一段"空等":相邻两层计算会读到对方刚算出、但还没写进存储器的数据,为了不读错,硬件只能插入空转的时钟去等它落地。
后来发现,这段空等很大程度上是个"调度"问题,而不是物理极限。只要把每一层内部的处理顺序重排一下,让"先被写的"和"后被读的"在时间上错开,空等就能压到很小。重排之后,打得过 MATLAB 的配置从 1 种变成了 4 种。
下面是重排后、在 FPGA 上真实布线测出来的结果。器件是 AMD UltraScale+ 系列,和 MATLAB 参考用的 ZCU102 同属一个速度等级,可以直接比。
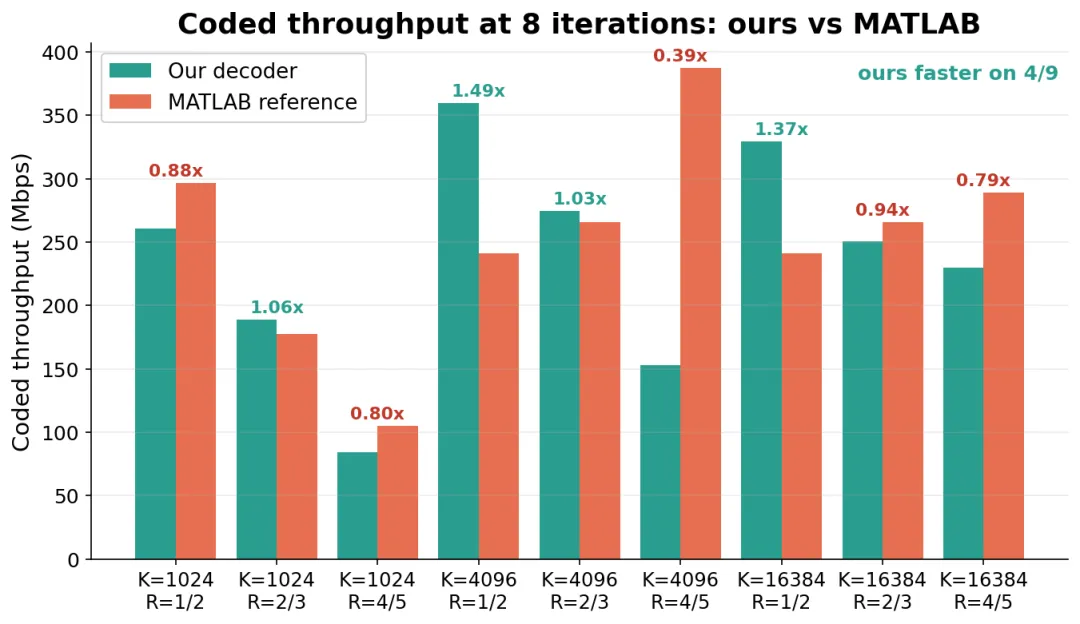
编码吞吐对比
图 5:相同 8 轮迭代下的编码吞吐,我们 vs MATLAB。9 种配置里 4 种更快,最高 1.49 倍。
吞吐上,9 种里有 4 种超过 MATLAB,领头的两个高折叠配置分别快 1.49 倍和 1.37 倍。落后的 5 种集中在码率 4/5 那一档,它们的"空等"是另一种成因,重排帮不上忙,得换别的办法,这是还没做完的部分。
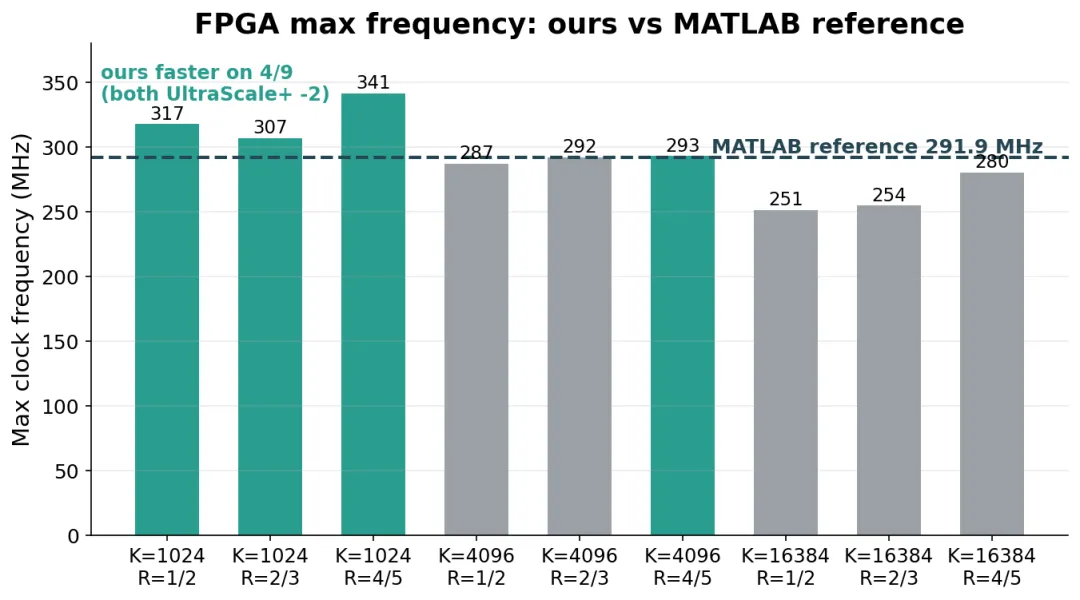
最高时钟频率对比
图 6:布线后最高时钟频率,对比 MATLAB 的 291.9 MHz 基准线。
时钟频率上,统一用标准流程(不做逐配置的人工布局微调)有 4 种超过 MATLAB 的 291.9 MHz,加上人工布局微调能到 6 种,最高的一种到 341 MHz。
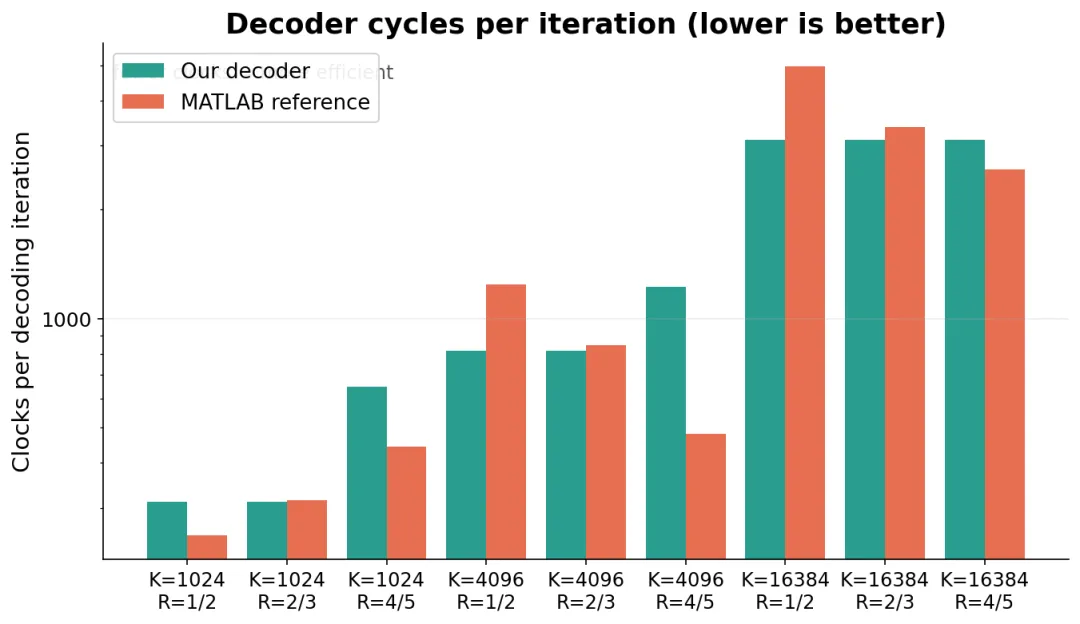
每轮迭代花多少时钟,是个和器件无关的纯架构指标,越低越省。
每轮迭代的时钟数
图 7:每一轮迭代花的时钟数,越低越省。
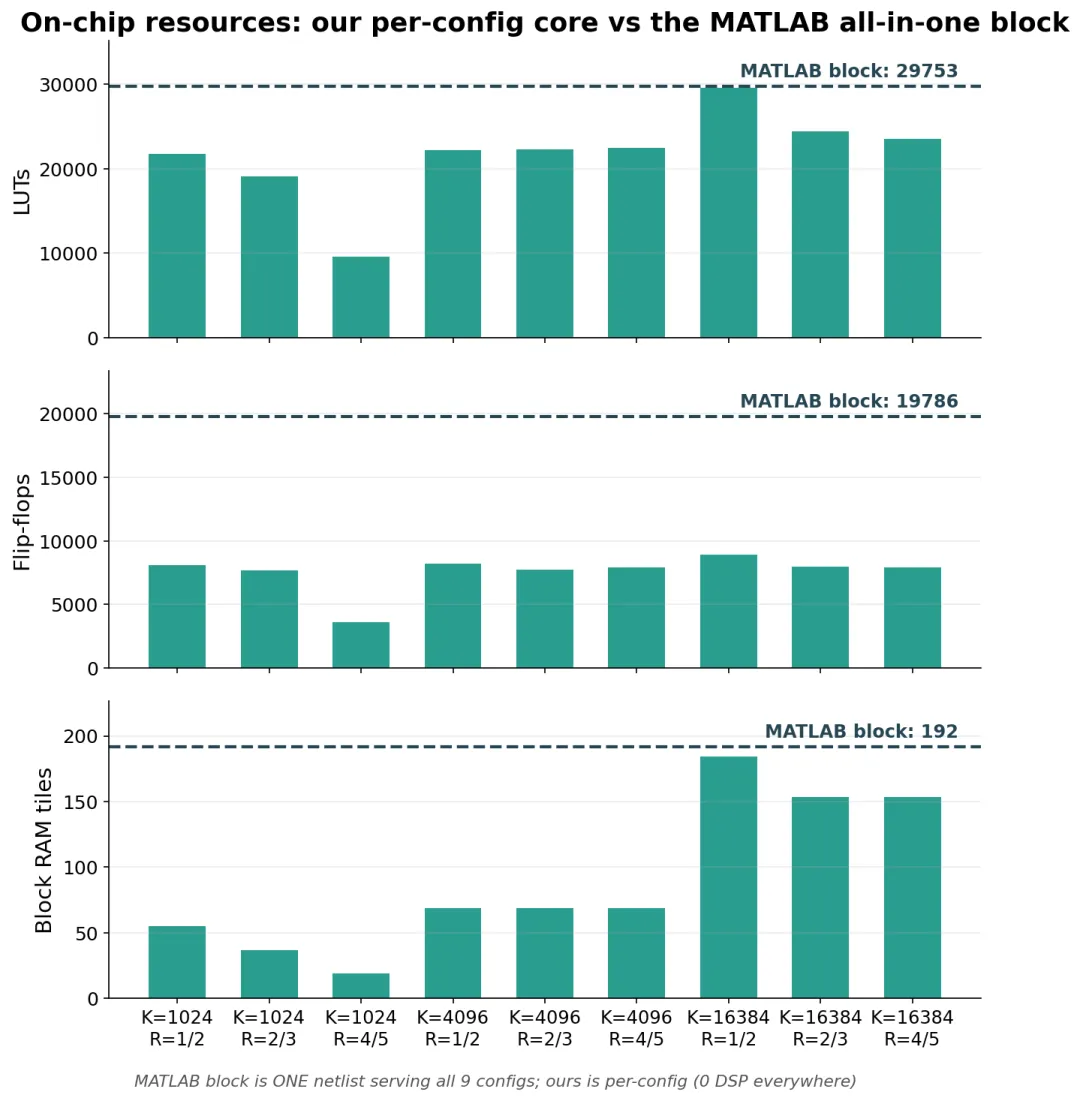
面积上,对比要小心。MATLAB 那个 IP 是"一套硬件跑全部 9 种配置",资源是按最大那个配置定的;我们是每种配置一套专用硬件。
资源对比
图 8:每种配置的 LUT、触发器、Block RAM,对比 MATLAB 那一套通用硬件。我们每种配置都更小,且不用任何 DSP。
可以看到,我们每种配置的 LUT、触发器、Block RAM 都明显小于 MATLAB 那套通用硬件,而且全程一个 DSP 都没用。这要理解成"专用核比通用核小",而不是"我们比它的单配置实现更省"。
5诚实地说,哪里赢哪里输
把账摊开:
- ▶正确性:9 种配置、264 帧逐位等于 MATLAB,零误码
- ▶吞吐:9 种里 4 种更快,最高 1.49 倍,落后的集中在码率 4/5 一档
- ▶时钟:标准流程 4 种超过 291.9 MHz,加人工布局微调到 6 种,最高 341 MHz
- ▶面积:
- ▶纠错余量:我们用 8-bit 软信息,MATLAB 用 4-bit,我们大约多 1 dB 余量
两个前提得先说清楚。一是上面说的"我们更小",是专用核对通用核,不是单配置对单配置。二是 MATLAB 用 4-bit、默认 8 轮,我们用 8-bit、靠提前停通常更早收敛,纠错能力略好,代价是数据通路宽一点。把这些摆在前面,对比才公平。
还没做完的,是码率 4/5 那几种配置的吞吐。它们的瓶颈和高折叠配置不是一回事,得换一套办法。这是下一步。
6小结
这件事真正的价值,不在某一项数字赢了多少,而在整条路:从一份 Python 算法出发,逐层逐位对照,自动生成 9 种配置的硬件,最后在真实器件上和厂商 IP 同台。把 9 种配置一起做,既逼出了隐藏的 bug,也让"重排调度"这种通用优化一次性惠及所有配置。
正确性追平、面积更省、吞吐和时钟各有四成配置反超,对一套自动生成的硬件来说,已经是一个能打的起点。
7参考
- ▶标准:CCSDS 131.0-B-3(TM Synchronization and Channel Coding),AR4JA LDPC 码的定义
- ▶参考 IP:MathWorks Wireless HDL Toolbox 的 ccsdsLDPCDecoder
- ▶算法对照:

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
