Linux 主机上配置的默认网关,本质通常是路由表里的默认路由下一跳。
但真正让人头疼的,往往不是“网关是什么”,而是这些现场问题:
“两个网卡都写了网关,为什么网络时好时坏?”
“网关能 ping 通,为什么公网还是不通?”
“重启网络后,网关怎么又变回去了?”
“多网关是不是一定错?”
这篇就围绕排障和进阶场景,把这些坑一次讲透。
一、坑 1:多块网卡都配默认网关
很多双网卡机器会被配成这样:
default via 192.168.31.1 dev eth0 metric 100default via 10.0.0.1 dev eth1 metric 100192.168.31.0/24 dev eth0 proto kernel scope link src 192.168.31.10010.0.0.0/24 dev eth1 proto kernel scope link src 10.0.0.10
看起来每块网卡都有自己的网关,很“完整”。但问题恰恰在这里:默认路由是兜底路由,兜底规则太多,就容易抢出口。
这里要修正一个常见误解:并不是所有“相同 metric 的多条默认路由”都会稳定地按 50/50 负载均衡。Linux 的实际行为和内核版本、路由写法、是否使用 ECMP nexthop、NetworkManager 生成方式等都有关系。你可能看到的是其中一条被选中,也可能看到多路径转发。
但从运维角度结论不变:如果你没有明确设计多路径或策略路由,不要让多块网卡随便拥有同优先级默认路由。它会让出站路径、回包路径和防火墙状态都变得不可控。
更稳妥的做法是:
# 外网口保留默认路由ip route add default via 192.168.31.1 dev eth0 metric 100# 内网口只负责直连网段ip route add 10.0.0.0/24 dev eth1# 需要访问其他内网网段时,单独加静态路由ip route add 172.16.0.0/16 via 10.0.0.1 dev eth1
一句话:默认路由负责兜底,内网路由负责精确匹配。不要让“兜底规则”到处都是。
二、坑 2:设置不同 metric,不等于自动高可用
有人会说,那我给两个默认网关设置不同 metric 不就行了吗?
ip route add default via 192.168.31.1 dev eth0 metric 100ip route add default via 10.0.0.1 dev eth1 metric 200
这样确实能让 metric 100 的路由优先于 metric 200。但注意:这不等于完整的网关高可用。
Linux 通常不会因为“下一跳设备还能 ARP 到,但它后面的公网断了”就自动切到高 metric 的默认路由。只有当路由被删除、接口 down、网络管理服务重新计算路由,或者你有额外的健康检查脚本时,备用路由才可能真正接管。
所以不同 metric 适合表达优先级,但如果你想做可靠的出口高可用,还需要配合:
- NetworkManager dispatcher、keepalived、脚本或路由协议;
别把 metric 当成万能 HA,它只是路由选择里的一个优先级参数。
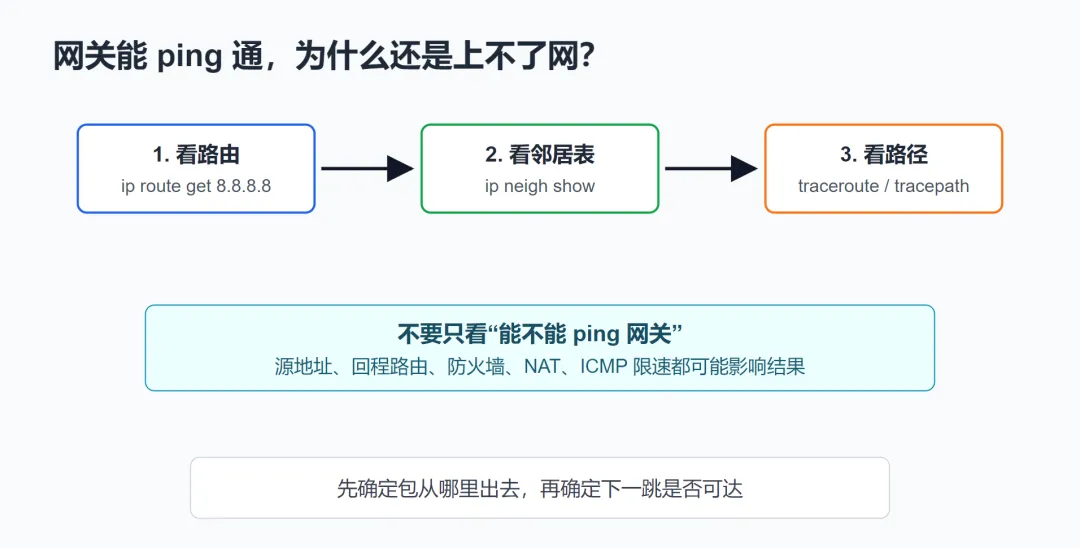
三、坑 3:网关能 ping 通,但就是上不了外网
ping 网关只能证明一件事:本机到网关这个下一跳的基本连通性大概率没问题。
它不能证明:
比如机房网关做了源地址校验,你本机 IP 配错了。你 ping 网关时,网关只需要回你本机;但你要访问公网时,网关发现源地址不合法,直接丢包。
再比如你访问的是外网地址,包确实从网关出去了,但回包不知道怎么回到你的私网段,也会表现为访问失败。
排查时可以按这个顺序来:
ip route get 8.8.8.8
先确认访问目标时实际选中了哪个出口、哪个源地址、哪个下一跳。
ip neigh show dev eth0
再确认下一跳的邻居表状态是否正常。
tracepath 8.8.8.8# 或traceroute 8.8.8.8
最后看路径断在哪里。
不过 traceroute 的结果也要谨慎解读。中间设备可能禁止或限速 ICMP/UDP 探测包,所以看到 * * * 不一定等于设备完全不转发。它是线索,不是最终判决。
四、坑 4:重启网络后,网关变了
如果你只是临时执行:
ip route replace default via 192.168.31.1 dev eth0
这只改了当前内核路由表。网络服务重启、机器重启、DHCP 续租、NetworkManager 重新激活连接,都可能把配置重新生成一遍。
所以排查“重启后网关变了”,要同时看两件事:
ip route
看当前路由表。
再看你的网络管理方式到底是哪一种:
nmcli connection shownetworkctl statusls /etc/netplan/ls /etc/sysconfig/network-scripts/
常见原因有三个:
- 多个连接配置里都写了默认网关,后激活的连接改变了默认路由。
- DHCP 自动下发了默认路由,覆盖或并存了手工配置。
如果使用 NetworkManager,通常应该通过连接配置修改:
nmcli connection modify eth0 ipv4.gateway 192.168.31.1nmcli connection modify eth0 ipv4.never-default nonmcli connection modify eth1 ipv4.never-default yesnmcli connection up eth0
具体连接名以你的系统实际输出为准。
五、坑 5:网关 MAC 变了,ARP 缓存没跟上
本机把包发给网关时,真正发到二层网络里的目标不是“网关 IP”,而是“网关 MAC”。
IPv4 下,这个 IP 到 MAC 的映射在邻居表里,也就是大家常说的 ARP 表:
ip neigh show 192.168.31.1 dev eth0
可能看到:
192.168.31.1 lladdr 3c:48:98:aa:bb:cc REACHABLE
如果网关设备切换、VRRP 漂移、上游替换设备,IP 还是 192.168.31.1,但 MAC 变了,旧邻居项没有及时更新,就可能出现短时间不通。
可以手动删掉对应邻居项,让系统重新解析:
ip neigh del 192.168.31.1 dev eth0ping -c 1 192.168.31.1ip neigh show 192.168.31.1 dev eth0
现代网络里,VRRP、免费 ARP、邻居不可达检测都会帮助刷新邻居表,但现场环境复杂时,知道这一层会让排障快很多。
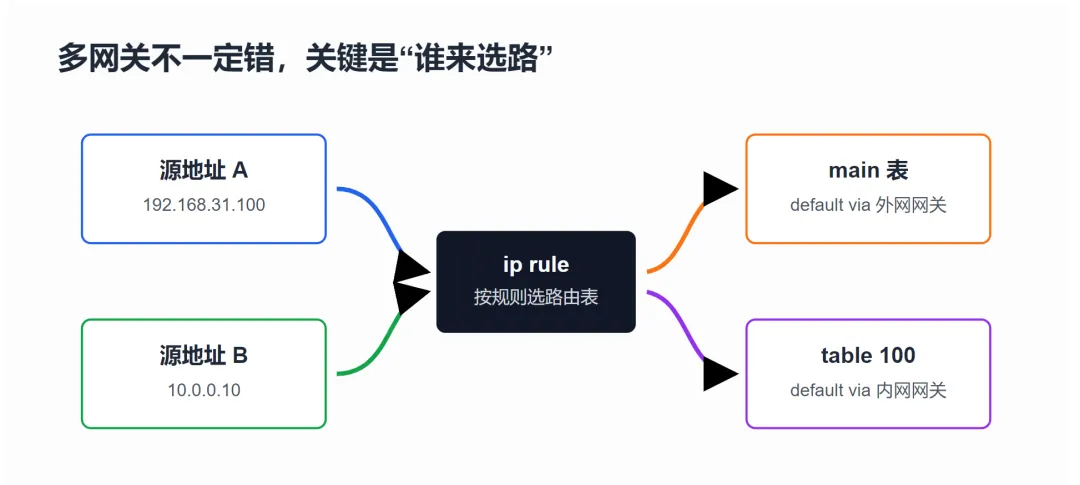
六、进阶:多网关并不一定错,错的是没有规则
有些场景确实需要多个网关,比如:
关键是:不能让所有流量都挤在同一张主路由表里抢默认路由,而是要用策略路由明确选择。
例如让源地址 10.0.0.10 的流量走 100 号路由表:
ip route add default via 10.0.0.1 dev eth1 table 100ip rule add from 10.0.0.10/32 table 100 priority 100
查看规则:
ip rule show
查看指定表:
ip route show table 100
这样多网关就不再互相抢,而是由 ip rule 决定不同流量查哪张路由表。
这才是多网卡、多线路环境里更可控的做法。
七、还有一种默认路由没有 via
你可能见过这样的路由:
default dev ppp0 proto static scope link metric 50
它没有 via 下一跳。
这常见于 PPP、部分隧道、点到点链路等场景。点到点接口的对端是链路语义的一部分,不需要像以太网那样先写一个下一跳 IP 再解析 MAC。
注意,这不等于普通以太网主机都可以随便写:
default dev eth0
在常规以太网里,这会让系统把大量目标都当作链路直连地址处理,可能尝试对外部地址做邻居解析,通常不是你想要的默认网关配置。普通服务器上,默认路由一般还是应该写成:
default via 网关IP dev 网卡名
八、最后做个排障清单
遇到网关问题时,可以按这个顺序看:
ip addr:本机 IP、掩码、接口状态是否正确。ip route:默认路由和静态路由是否符合预期。ip route get 目标IP:实际选路是否正确。ip neigh show:下一跳 MAC 是否解析正常。tracepath 或 traceroute:路径大概断在哪里。- 防火墙、NAT、源地址校验、回程路由:这些经常才是真正原因。
网关问题看起来杂,其实主线很清楚:先确定路由选谁,再确定下一跳能不能到,最后确认它是否愿意并且能够继续转发。
把这个顺序记住,排查 Linux 网络时会少绕很多弯。
互动
你在日常运维里踩过哪些网关坑?是多默认路由、ARP 缓存,还是网关能通但外网不通?欢迎在评论区聊聊你的现场经历。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
