#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
长虎爬虫模块
功能:
1. 抓取 https://apphwhq.longhuvip.com/w1/api/index.php 接口数据,
2. 自动处理 gzip 解码及 JSON 解析,
3. 在终端中以表格形式打印数据。
"""
importrequests
# 尝试引入 tabulate 库,用于美化终端表格打印;若未安装则自动采用手动格式化打印
try:
fromtabulateimporttabulate
exceptImportError:
tabulate=None
classLonghuCrawler:
"""
长虎爬虫类,用于抓取并解析接口数据
"""
def__init__(self, base_url="https://apphwhq.longhuvip.com"):
self.base_url=base_url
self.headers= {
"Accept-Language": "zh-Hans-US;q=1.0",
"Accept": "*/*",
"Connection": "keep-alive",
"Accept-Encoding": "gzip;q=1.0, compress;q=0.5",
"User-Agent": "lhb/5.18.1 (com.kaipanla.www; build:0; iOS 16.3.1) Alamofire/4.9.1"
}
deffetch_sharp_withdrawal_list(self, params=None):
"""
获取 SharpWithdrawalList 数据
:param params: 请求参数字典,如为空则使用默认参数
:return: JSON 数据,若请求异常返回 None
"""
# 默认参数设置
ifparamsisNone:
params= {
"Index": "0",
"Order": "0",
"PhoneOSNew": "2",
"Type": "5",
"VerSion": "5.18.0.1",
"a": "SharpWithdrawalList",
"apiv": "w39",
"c": "HomeDingPan",
"st": "7"
}
url=self.base_url+"/w1/api/index.php"
try:
response=requests.get(url, headers=self.headers, params=params, timeout=10)
response.raise_for_status() # 检查请求状态
# 自动处理 gzip 解码,并转换为 JSON
data=response.json()
returndata
exceptExceptionase:
print("请求过程中发生异常:", e)
returnNone
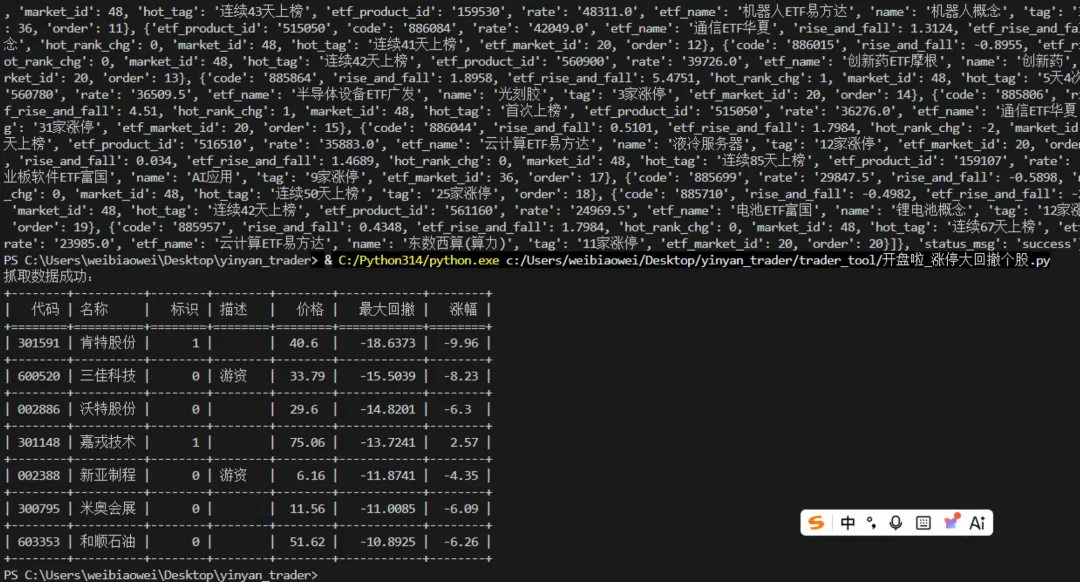
defprint_table_with_tabulate(data):
"""
使用 tabulate 库在终端打印表格
:param data: 接口返回的 JSON 数据
"""
if"info"notindata:
print("没有表格数据")
return
# 根据实际字段含义自定义表头
headers= ["代码", "名称", "标识", "描述", "价格", "最大回撤", "涨幅"]
rows=data["info"]
print(tabulate(rows, headers=headers, tablefmt="grid"))
defprint_table_manual(data):
"""
手动格式化打印表格(若 tabulate 库不可用时)
:param data: 接口返回的 JSON 数据
"""
if"info"notindata:
print("没有表格数据")
return
headers= ["代码", "名称", "标识", "描述", "参数1", "参数2", "参数3"]
rows=data["info"]
# 计算每列的最大宽度
col_widths= [len(header) forheaderinheaders]
forrowinrows:
fori, cellinenumerate(row):
col_widths[i] =max(col_widths[i], len(str(cell)))
# 打印表头
header_line=" | ".join(header.ljust(col_widths[i]) fori, headerinenumerate(headers))
separator_line="-+-".join("-"*col_widths[i] foriinrange(len(headers)))
print(header_line)
print(separator_line)
# 打印每一行数据
forrowinrows:
print(" | ".join(str(cell).ljust(col_widths[i]) fori, cellinenumerate(row)))
defmain():
"""
主函数:创建爬虫实例,抓取数据,并以表格形式打印至终端
"""
crawler=LonghuCrawler()
data=crawler.fetch_sharp_withdrawal_list()
ifdata:
print("抓取数据成功:")
iftabulate:
print_table_with_tabulate(data)
else:
print_table_manual(data)
else:
print("抓取数据失败。")
if__name__=="__main__":
main()
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
