科研绘图 | 基于Python 绘制PCC + VIF + TOL 相关性(共线性)多角度分析图
- 2026-07-02 16:54:11
机器学习建模前最怕的,不是变量少,而是变量乱。有些特征看起来很多,实际上表达的是同一件事;有些特征虽然保留下来了,但彼此互相影响,最后会让模型参数变得很敏感,甚至影响预测稳定性。因此本文把 PCC、VIF 和 TOL 放到一起,先看特征之间像不像,再看会不会互相干扰,最后用一张图把结果讲清楚。这样做不是为了好看,而是为了在正式机器学习建模前先把特征理一遍。
1. 读取数据
读取数据后拆成特征和标签。因为 PCC 和 VIF 都是基于特征算出来的,先把输入整理清楚,后面的图才有意义,逻辑也不会乱。所以把 label 单独拿出来,是因为后面的判断都是围绕“特征”和“类别”两个对象展开的,先分开,思路会更清楚。
# 导入CSV数据data = pd.read_csv("分类样本.csv")# 分割特征和目标列X = data.drop(columns=["label"])y = data["label"]features = Xlabels = y2. 先看特征像不像:使用PCC
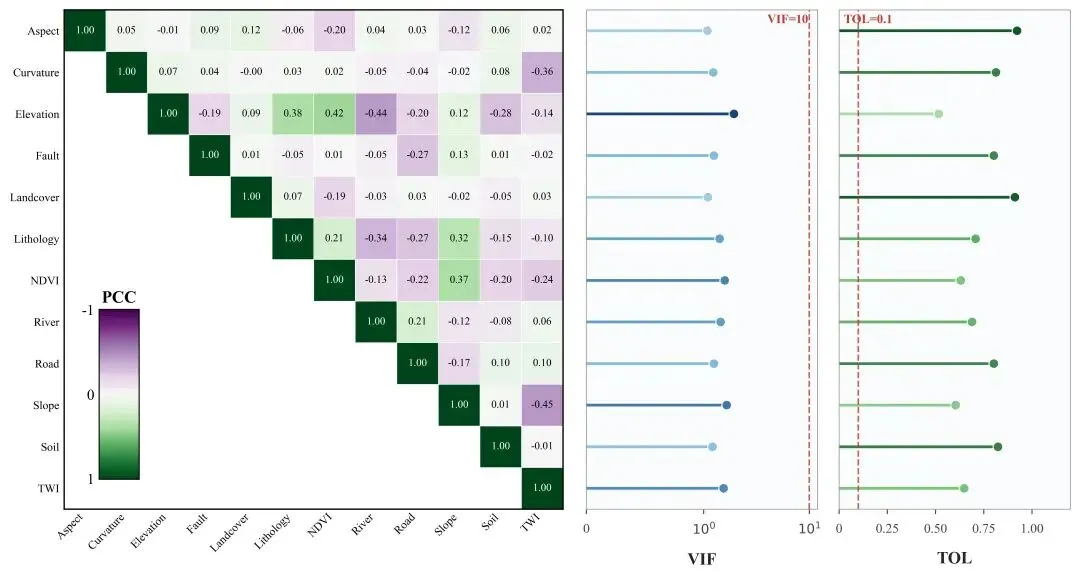
PCC 看的是两个特征之间像不像。简单理解,相关系数越高,说明两个特征提供的信息越接近;相关系数越低,说明它们表达的内容差别越大。对二分类和回归问题来说,这一步很有价值,因为它能先帮我们找出“表达信息重复”的变量。比如两个变量几乎总是一起增减,那保留太多这样的变量,通常只会让模型更复杂,但不一定更好。把 PCC 画成热力图,也是为了让这种关系一眼能看出来,省得一列一列地翻表格。图里只画上三角区域,也是为了避免重复展示同一组相关性,读起来更干净。
# PCC相关系数矩阵correlation_matrix = features.corr(method="pearson")correlation_matrix.to_csv(os.path.join(output_dir, "correlation_matrix_data.csv"))3. 再看会不会互相干扰:VIF 和 TOL
PCC 只能告诉你“像不像”,但不能完全回答“会不会互相干扰”。这时候就要看 VIF 和 TOL 了。VIF 越大,说明这个特征越容易被其他特征解释,也就是共线性越明显;TOL 越小,说明它越不独立。换句话说,VIF 更像是在问“这个变量是不是被别的变量包住了”,TOL 则是在问“它还剩多少独立信息”。很多时候,VIF 的值会特别大,如果还按普通数字显示,图就会很难读,所以脚本把 VIF 的刻度做成了 10^0、10^1、10^2 这种指数形式,这样即使数值变化很大,也能保持清晰。
defformat_vif_tick(value, pos):if np.isclose(value, 0.0):return'0'if value <= 0:return'' exponent = np.log10(value)if np.isclose(exponent, np.round(exponent)):returnrf'$10^{{{int(np.round(exponent))}}}$'return''defformat_tol_tick(value, pos):if np.isclose(value, 0.0):return'0'returnf'{value:.2f}'defcalculate_vif_tol(df): X_numeric = df.select_dtypes(include=[np.number]) X_with_const = add_constant(X_numeric) vif_list = []for i in range(1, X_with_const.shape[1]): vif_list.append(variance_inflation_factor(X_with_const.values, i))return pd.DataFrame({'Feature': X_numeric.columns,'VIF': vif_list,'TOL': [1 / v if v != 0else0for v in vif_list] })4. 把三部分放到同一张图里
最后一步,就是把 PCC、VIF、TOL 放在同一个画布上,左中右依次排开。这样做最大的好处,是对比起来特别快:左边看两个特征是否重复,中间看这个特征会不会被别的变量“带偏”,右边看它稳不稳。不需要来回切换表格,也不用把多个结果拆开看,只要盯着这一张图,基本就能把特征的整体状态摸个大概。
fig = plt.figure(figsize=(total_w, total_h))gs = GridSpec( nrows=1, ncols=3, width_ratios=[heatmap_w, bar_w, bar_w], wspace=0.03)ax_heat = fig.add_subplot(gs[0])ax_vif = fig.add_subplot(gs[1])ax_tol = fig.add_subplot(gs[2])fig.subplots_adjust(left=0.12, right=0.99, bottom=0.18, top=0.95, wspace=0.02)5. 批量输出几套配色
最后还批量输出了几套配色。核心逻辑不变,只是颜色方案不同,方便你挑一版最顺眼的。对于同一份结果来说,不同配色最大的作用是让重点更容易被看见。比如有的配色更适合强调正负相关,有的配色更适合突出差异层次,你可以根据文章风格或者期刊要求来选。直接把多张图保存到输出文件夹里,也省去了反复手动画图的麻烦。
color_schemes = [ ('RdBu_r', 'PCC_VIF_TOL_RdBu_r'), ('coolwarm', 'PCC_VIF_TOL_coolwarm'), ('seismic', 'PCC_VIF_TOL_seismic'), ('PuOr', 'PCC_VIF_TOL_PuOr'), ('BrBG', 'PCC_VIF_TOL_BrBG'), ('PRGn', 'PCC_VIF_TOL_PRGn'),]print("\nGenerating combined plots...")for cmap_name, suffix in color_schemes: filename = f'{suffix}.jpg' plot_pcc_vif_tol_combined(correlation_matrix, vif_tol_df, cmap_name, filename)小结
这套方法本质上是在做建模前的基础筛选:先看重复,再看共线性,再把结果放到一张图里。它不复杂,但很实用,适合在正式训练模型之前先把数据摸一遍。很多时候,模型效果差并不一定是算法问题,而是输入特征本身就有重复、干扰或者不稳定的问题。先把这些基础问题处理好,后面的模型通常会更省心。
现在绘图代码都不支持免费获取了,20/篇文章。同时欢迎加入小编科研绘图VIP群,298/年,所有科研绘图相关文章代码免费获取,涵盖机器学习模型(回归和分类)的shap分析、还有各种如皮尔逊分析等相关的图,以及期刊复现图,源代码直接复制或者打开就能绘图。同时进群赠送SHAP科研分析软件6.0(文本版)和最优地理探测器软件,且免费更新使用。VX:GISyanjiushengya!
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 172个Linux口令汇总!!!
- 2026嵌入式linux开发板服务商选购避坑指南:启扬智能领跑
- 网络工程师 vs Linux 运维:2026年 IT 职场,哪个更有 “钱” 途?
- Linux 最新资讯 20260528——Phoronix 今日精选
- 不愧是北大推荐的书,啃到一半Python上了岸
- 暑假悄悄内卷!学完70个python实战练手项目
- 零基础小白狂喜!这个中文免费Python网站,不用装软件,手机就能敲代码
- 这网站我愿称为python 学习之光!!
- 这个Python学习网站简直夯爆了!
- CTF 实战:Python 字节码与 PyInstaller 程序逆向
