在数据清洗和特征工程中,我们经常会遇到用父子关系表存储的层级分类数据,例如商品类目、组织架构、地区划分等。一条记录代表一个父子关系,多张表拼接才能得到完整路径。当需要让每一条完整路径独占一行、并带上每一层的等级信息时,就需要将这种“竖着存”的树形数据“横着铺开”。
本文通过一个直观的示例,讲解如何用 Python 的 pandas 和原生数据结构,将树形分类表平铺成多级列宽表。
一、问题场景
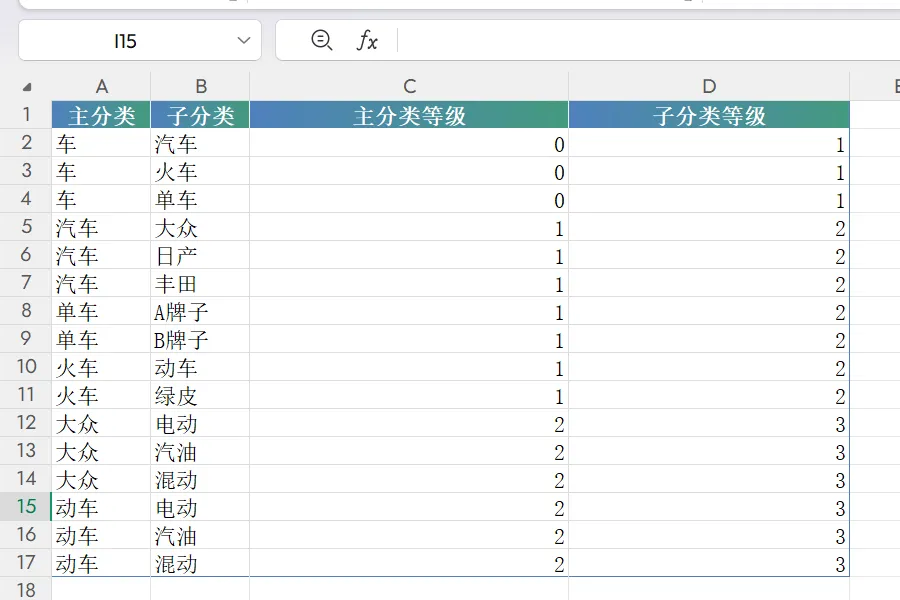
假设我们有一张表示分类关系的 Excel 表 source_classification.xlsx,记录了主分类、子分类以及各自的层级等级:
这张表实际上定义了一棵树:根节点是“车”,它的子节点是“汽车”“火车”“单车”;“汽车”又有子节点“大众”“日产”“丰田”;“大众”下还有“电动”“汽油”“混动”。所有叶子节点深度并不完全相同,例如“日产”没有下一级,而“电动”已经是第三级。
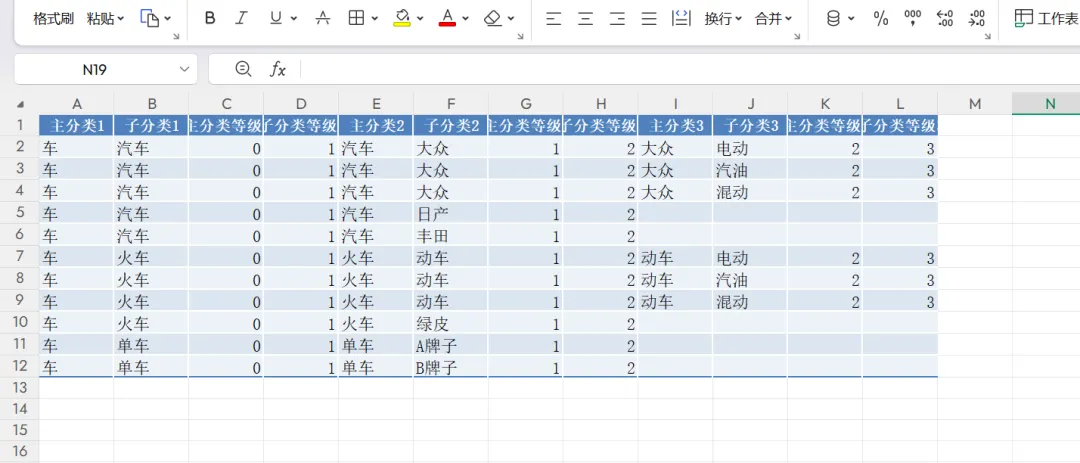
我们的目标是将其展开为如下形式:
每一行是一条从根到叶子节点的完整路径,每一步(即一条父子边)被拆成4列:该步的主分类、子分类、主分类等级、子分类等级。深度较浅的路径在缺少的位置填上空字符串。这样每一行就包含了该叶子节点的全部上游信息,极大方便了下游的查询、筛选和建模。
二、解决思路
整个过程可以拆分为三个核心步骤:

- 树重建:从关系表中提取父子连接,构建一个“父亲 → 孩子列表”的映射,并锁定根节点。
- 路径收集:从根节点开始进行深度优先遍历(DFS),记录每一条从根到叶子的完整路径,路径中的每一步保存四元组
(主, 子, 主等级, 子等级)。 - 平铺对齐:计算所有路径的最大深度,按最大深度构造 DataFrame,深度不足的路径用空字符串填充,最后输出。
我们完全使用 Python 标准库和 pandas 实现,无需额外安装树结构库。
三、代码实现详解
首先引入依赖并读取数据:
import pandas as pd
from collections import defaultdict
source_file = 'source_classification.xlsx'
df = pd.read_excel(source_file)
1. 构建父子关系字典
我们使用 defaultdict(list) 来存储树的结构:键为父节点名称,值为一个列表,每个元素是 (子节点, 父等级, 子等级) 的元组。
children = defaultdict(list)
for _, row in df.iterrows():
parent = row['主分类']
child = row['子分类']
p_level = row['主分类等级']
c_level = row['子分类等级']
children[parent].append((child, p_level, c_level))
这样 children 就形成了一棵多叉树的邻接表表示。
2. 定位根节点
根据业务逻辑,根节点是“主分类等级”为 0 且唯一的那个主分类。我们可以从原表中直接筛选出来:
roots = df[df['主分类等级'] == 0]['主分类'].unique()
if len(roots) != 1:
raise ValueError("根节点不唯一或不存在")
root = roots[0] # 在本例中为 '车'
这样做可以避免硬编码根节点名称,让代码适应不同的数据。
3. DFS 收集所有路径
定义空列表 all_paths 用于存放每一条完整路径。这里路径的含义是从根到当前节点所经过的所有“边”,而不是节点本身。每条路径是一个列表,其中的元素为单条边的四元组 (主分类, 子分类, 主等级, 子等级)。
all_paths = []
defdfs(node, path):
if node notin children: # 叶子节点,保存当前路径
all_paths.append(path.copy())
return
for child, p_lv, c_lv in children[node]:
path.append((node, child, p_lv, c_lv))
dfs(child, path)
path.pop() # 回溯
dfs(root, [])
注意两点:
- 只有当节点没有子节点(即
children 中不存在该键)时,才将路径存入 all_paths。这样得到的是所有叶子路径。 - 使用
path.copy() 是为了保存路径的副本,避免后续回溯修改影响已存储的结果。
4. 计算最大深度并平铺
每条路径的长度(边数)可能不同,最大深度决定了最终表格有多少组列(每组4列)。
max_depth = max(len(p) for p in all_paths) if all_paths else0
接下来遍历所有路径,对每条路径构造一行数据。对于第 i 层(0 <= i < max_depth),如果路径有该层数据则取出四元组,否则填充四个空字符串。
rows = []
for path in all_paths:
row = []
for i in range(max_depth):
if i < len(path):
parent, child, plv, clv = path[i]
row.extend([parent, child, plv, clv])
else:
row.extend(['', '', '', ''])
rows.append(row)
最后生成列名,格式为 “主分类1, 子分类1, 主分类等级1, 子分类等级1, 主分类2, …”:
columns = []
for i in range(1, max_depth + 1):
columns += [f'主分类{i}', f'子分类{i}', f'主分类等级{i}', f'子分类等级{i}']
df_flat = pd.DataFrame(rows, columns=columns)
5. 输出结果
将平铺后的 DataFrame 保存为新的 Excel 文件,并打印前几行以供预览。
output_file = 'flattened_classification.xlsx'
df_flat.to_excel(output_file, index=False)
print(f"平铺结果已保存至 {output_file}")
print("\n预览前5行:")
print(df_flat.head(5).to_string(index=False))
运行后会生成 flattened_classification.xlsx,内容完全符合预期。
四、运行结果展示
基于文章开头的示例数据,输出表格的前 5 行大致如下(列名省略):
可以看到,叶子“日产”和“丰田”没有第三级,所以对应的第 3 组列全部为空。树形结构被完整、整齐地展开为二维表格。
本文展示了一种纯 Python 解决方案,将父子关系表转换为全路径宽表。核心思想是通过 DFS 提取所有根到叶子的完整路径,再利用最大深度进行对齐平铺。该方法具有以下优点:
- 无需递归限制:Python 默认递归深度足够应对常见层级(通常数百层以内),若层级极深可以改用迭代栈。
- 列数自动适配:根据实际数据的最大深度动态生成列,不会冗余也不会缺失。
- 灵活可调:只需修改四元组的内容和列名生成逻辑,就可以适应不同字段的层级数据。
希望这篇文章能帮助你理解树形数据的平铺技巧,并在遇到类似场景时快速套用。完整代码已包含在文中,欢迎直接取用并根据自己的数据结构调整列名与层级字段。
为了能随时获取最新动态,大家可以动动小手将公众号添加到“星标⭐”哦,点赞 + 关注,用时不迷路!!!!
关注公众号:IT小本本 👇

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
