这2天测试了一个简单的spark任务,更确切的说,是让我的Windows10电脑具备了跑spark任务的基础环境,事情听起来很简单,但中间遇到了一个问题搞了很久才成功,分享一下,希望对初学spark的人有所帮助。
一、主要部件:
python:3.13.13版本
pyspark:4.1.2版本
PyCharm:2026.1
二、主要步骤:
安装Python,并设置环境变量Path
安装pyspark
增加环境变量PYSPARK_PYTHON,值为Python的安装地址
用PyCharm新建项目,选择已安装的Python作为解释器
执行以下代码:
from pyspark import SparkContext,SparkConfconf = SparkConf() \ .setMaster("local[2]") \ .setAppName("amountSum") \ .set("spark.driver.host","127.0.0.1")sc = SparkContext(conf = conf)sc.setLogLevel("ERROR")data = sc.parallelize([('user1',100),('user2',200),('user1',300),('user2',100)])print(data.collect())sum_rdd = data.reduceByKey(lambda x,y:x+y)print(sum_rdd.collect())
输出结果:

三、问题处理
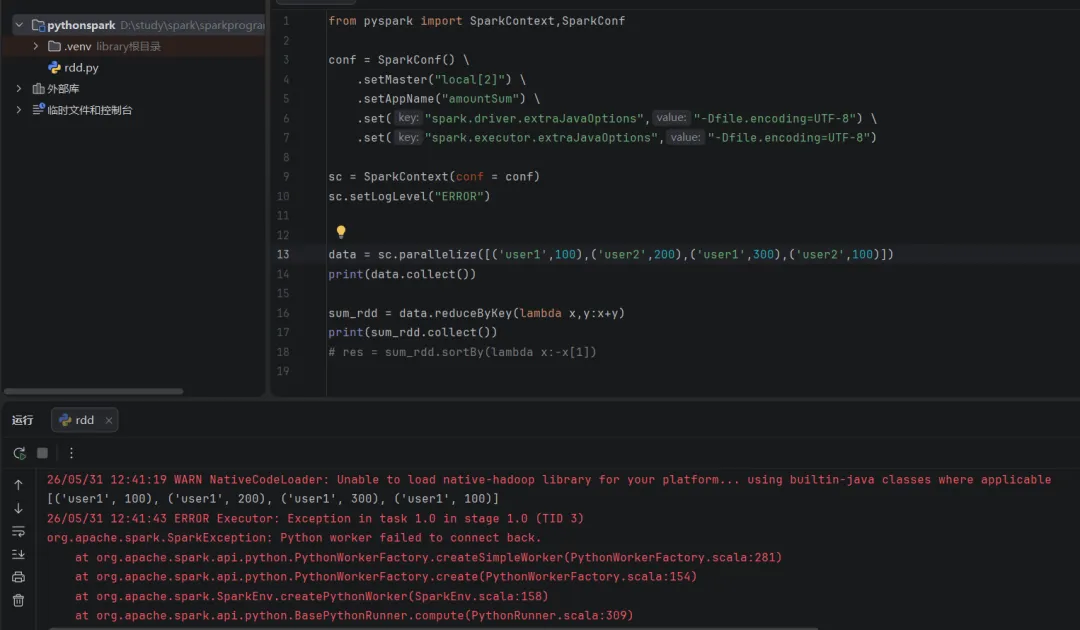
开始执行上面代码时,报这个错误:
看报错的位置,发现如果只是创建一个rdd,是可以执行的,但执行到reduceByKey,也就是涉及到shuffle操作,就报错了,主要的错误信息是Python worker failed to connect back。从网上搜了各种解决办法,包括下载配置Windows环境下的Hadoop工具、切换Python版本、配置各种环境变量等,都没好用。
最后是调整了这2个地方,代码可以跑成功了:
代码中增加了这行配置:
set("spark.driver.host","127.0.0.1")
猜测是因为我的电脑装了虚拟机,会给宿主机再分配一个ip地址(192.168.56.1),driver的ip分配成了这个ip,但local环境下,executor回连driver是只认127.0.0.1的,所以报了failed to connect back的错误。
2. 增加了环境变量PYSPARK_PYTHON,值为Python的安装地址
但是后来又出现一个奇怪的情况,代码中不配置spark.driver.host,也能跑成功了。不管怎么样,如果有同学也遇到了相同的错误,可以尝试一下这个点。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
