双指针-Linux内核是怎么原地给数组排序的?
- 2026-06-30 14:27:18
双指针-Linux内核是怎么原地给数组排序的?
数据结构与算法 · 数组 · 第 04 篇
标签:#双指针 #快速排序 #Linux内核 #LeetCode #面试
预计阅读时间:10分钟
开篇:整理书架的智慧
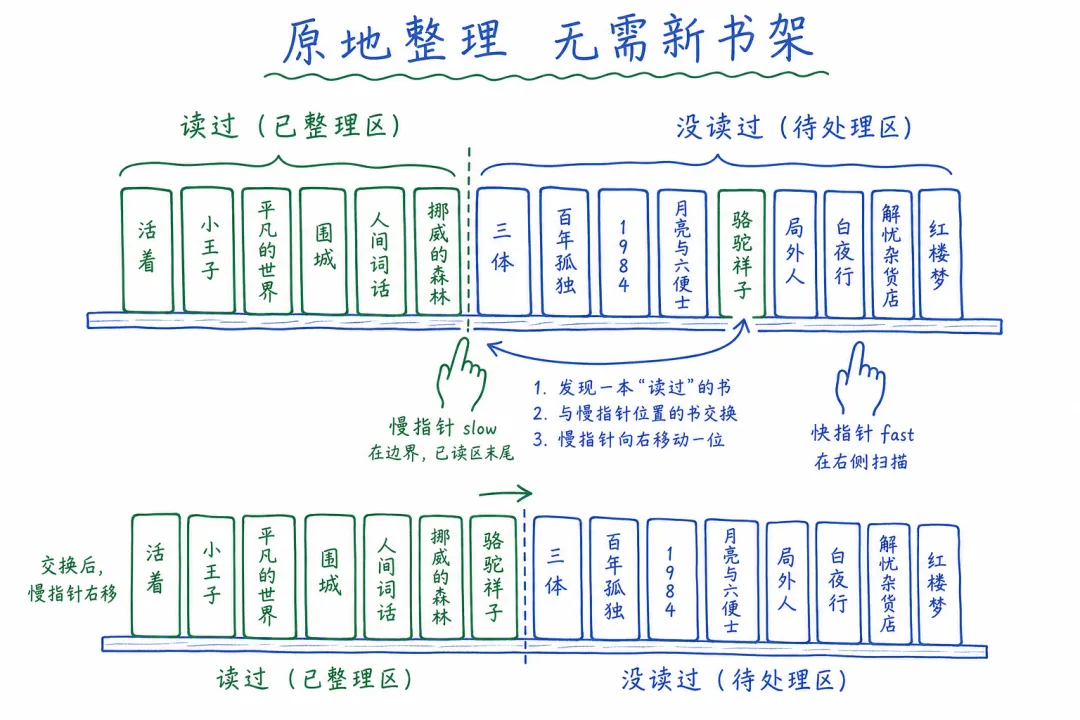
你有一排书架,要把"读过的"放左边,"没读过的"放右边。
笨办法:另买一个书架,逐本判断,读过的放左边,没读过的放右边。需要额外空间。
聪明办法:用两个手指。slow 指着"已整理好的边界",fast 逐本看过去。读过的?和 slow 位置交换,slow 右移。没读过的?不管,fast 继续看下一本。
两个手指协作,原地完成整理。
这就是快慢指针。Linux 内核的快速排序 partition 用的就是这个思路。
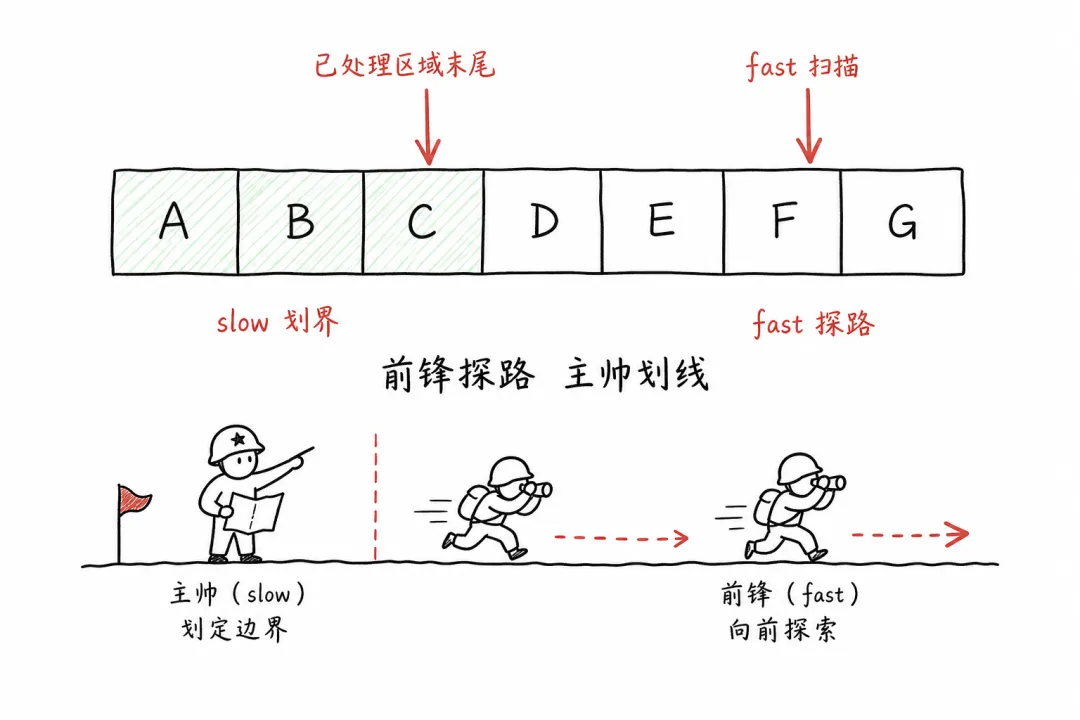
一个人探路,一个人划线
slow 前面的区域永远是"处理好的",fast 只需要关心"当前看到的元素该放哪"。
这种分工很像古代行军打仗——前锋探路(fast),主帅划线定界(slow)。前锋遇到什么敌情都报给主帅,主帅决定推进还是驻守。
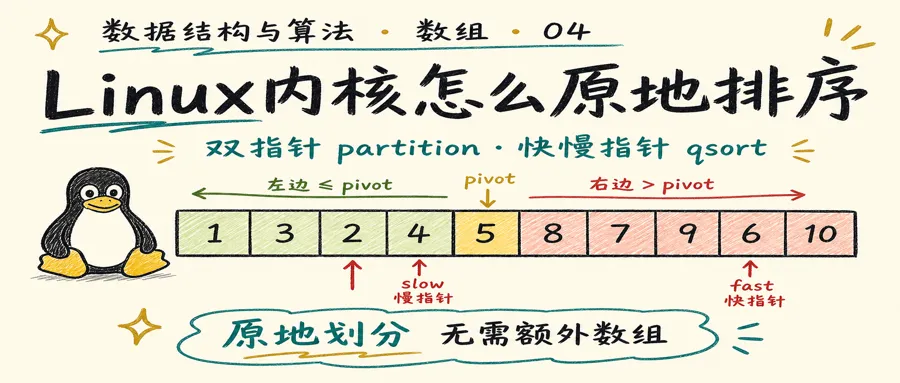
Linux 内核的快速排序:原地排序的秘密
排序算法有很多种。冒泡排序好懂但太慢,归并排序稳定但需要额外空间。快速排序的优势是原地排序——不需要另开一块内存,直接在原数组上交换元素。
快速排序的核心是一个叫 partition(划分) 的操作。它的任务很简单:选一个基准值(pivot),把数组分成左右两部分——左边都 ≤ pivot,右边都 > pivot。然后对左右两边递归做同样的事,整个数组就有序了。
partition 是怎么做到"原地"的呢?答案就是快慢指针。
一步步拆解 partition(Lomuto 划分)
Lomuto是提出这个算法的大佬,其实还有Hoare的快排算法,两者思路基本一致,在具体操作过程中有差异。Linux内核里常见的是 Lomuto 划分:选最左边当 pivot,用 slow / fast 两个下标,把数组切成「≤ pivot」和「> pivot」两段,全程只在原数组上交换。
说实话,虽然规则简单,但在计算机世界理解这个过程其实挺费神的,由于是递归实现,而递归又挺反人类思考模式的,所以下面只能用尽量详细的说明每个步骤了。
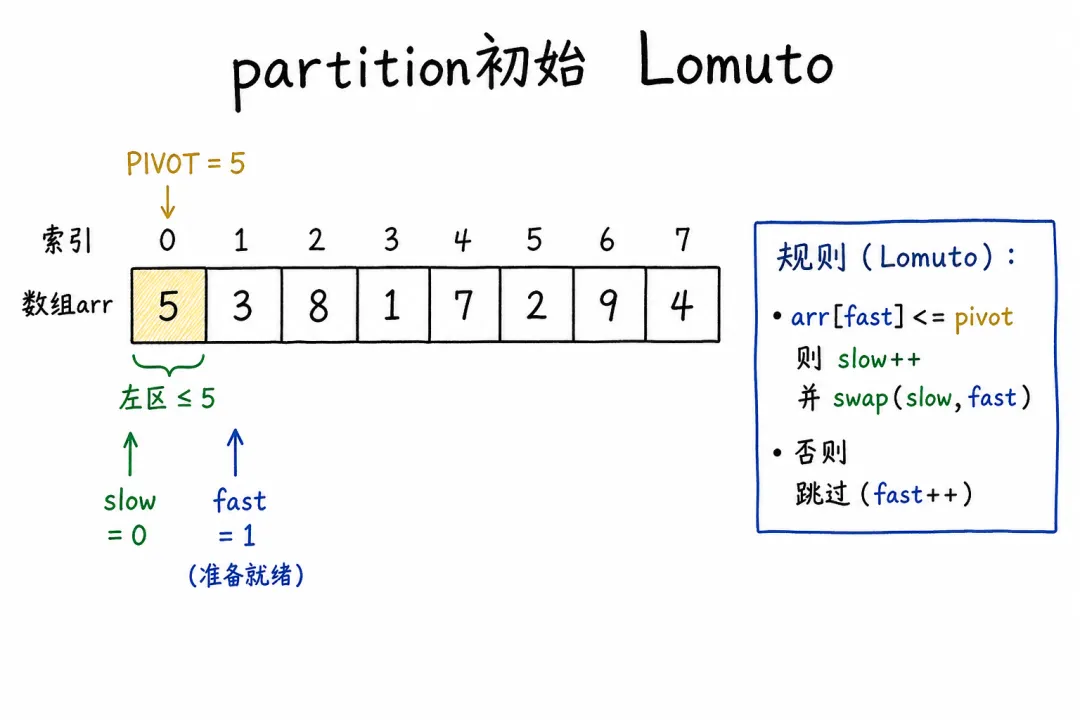
下面用数组 [5, 3, 8, 1, 7, 2, 9, 4],pivot = arr[0] = 5 走一遍。
先记住三个角色:
| pivot | arr[0],扫描结束后再换到最终位置 |
| slow | slow = 0(只有 pivot 自己) |
| fast | 1 扫到 n-1,逐个检查 arr[fast] |
对应代码(与 Linux qsort 同类写法):
// 划分 [left, right],返回 pivot 最终下标int partition(int[] arr, int left, int right) {int pivot= arr[left];int slow= left; // ≤ pivot 区的右边界for (intfast= left + 1; fast <= right; fast++) {if (arr[fast] <= pivot) { slow++; swap(arr, slow, fast); // 把「小值」收进左区 } } swap(arr, left, slow); // pivot 放到 slowreturn slow;}初始状态
绿色左区 [0..slow] 目前只有 pivot 5;fast 即将从 1 开始检查。
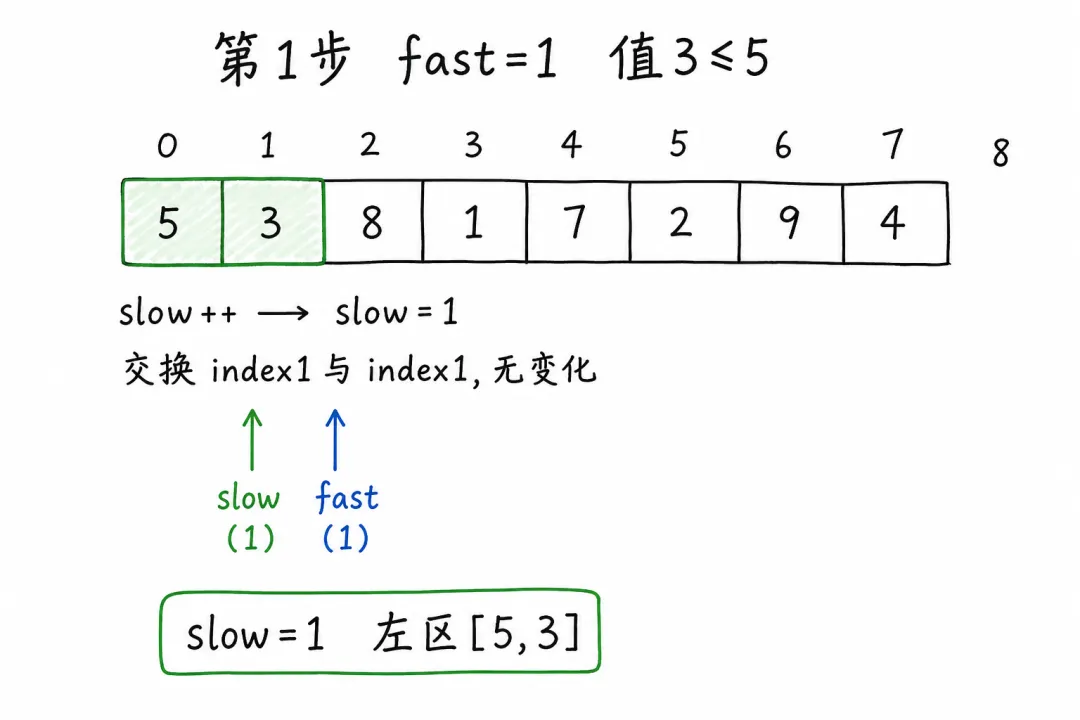
第 1 步:fast = 1,值为 3(≤ 5)
slow++→slow = 1swap(arr[1], arr[1]),数组不变左区变为 [5, 3]
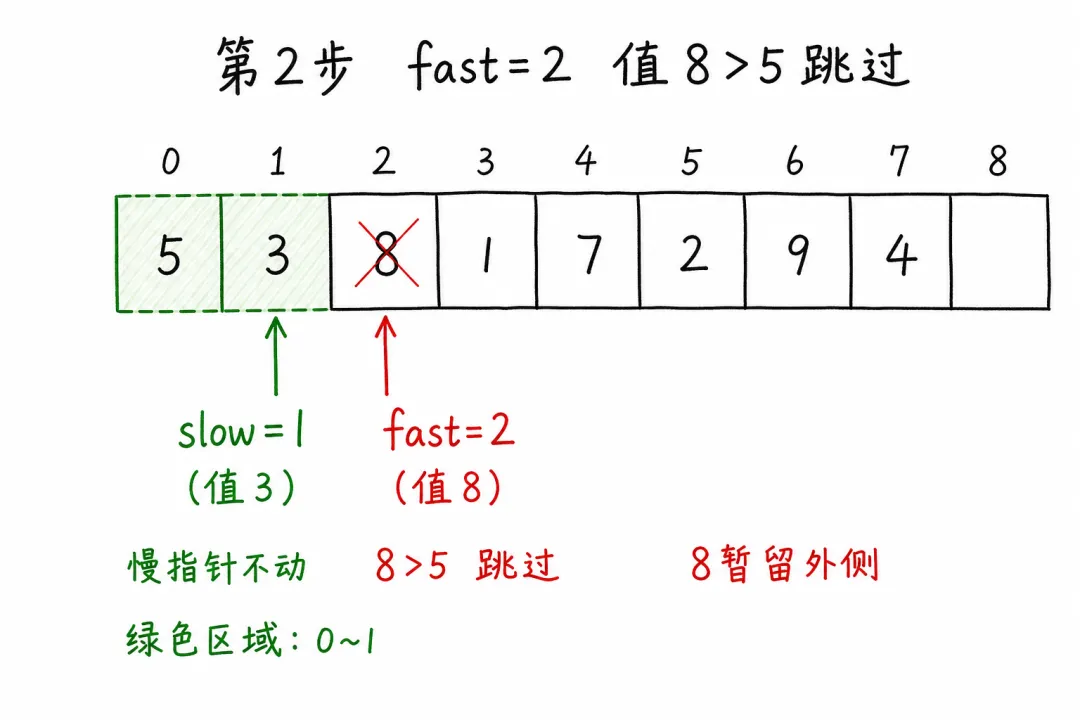
第 2 步:fast = 2,值为 8(> 5)
不满足条件,不交换, slow仍为18暂时留在左区边界外,等后面的小值来换走它
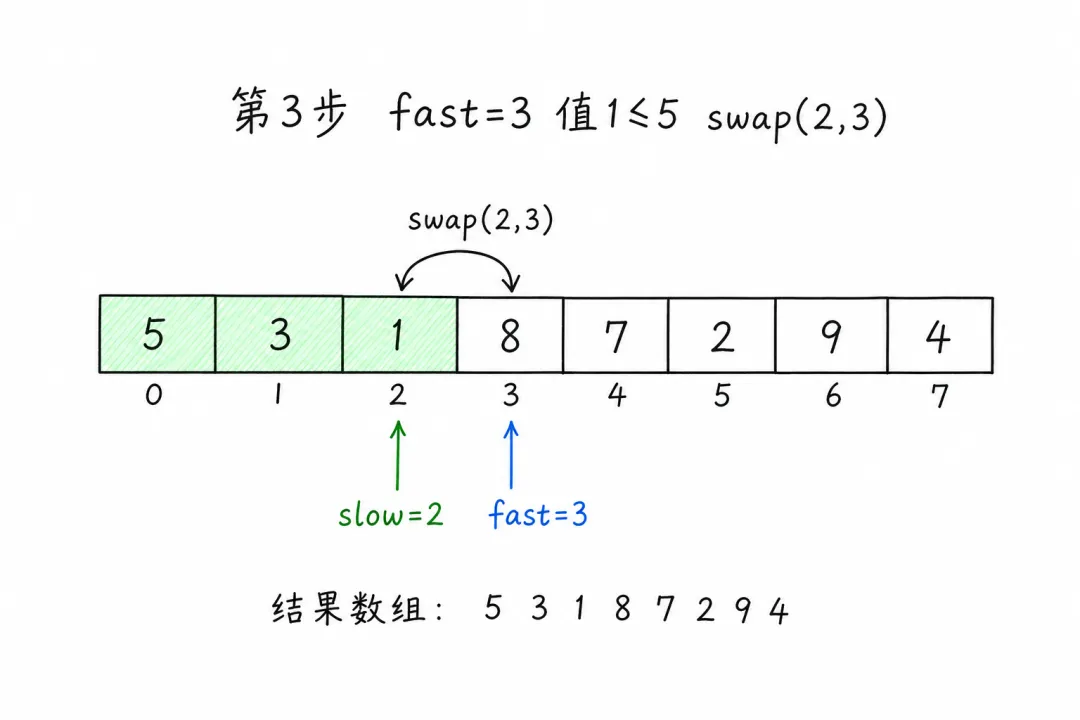
第 3 步:fast = 3,值为 1(≤ 5)
slow++→slow = 2swap(arr[2], arr[3]):交换 8 和 1 →[5, 3, 1, 8, 7, 2, 9, 4]左区 [5, 3, 1],大的8被换到右侧
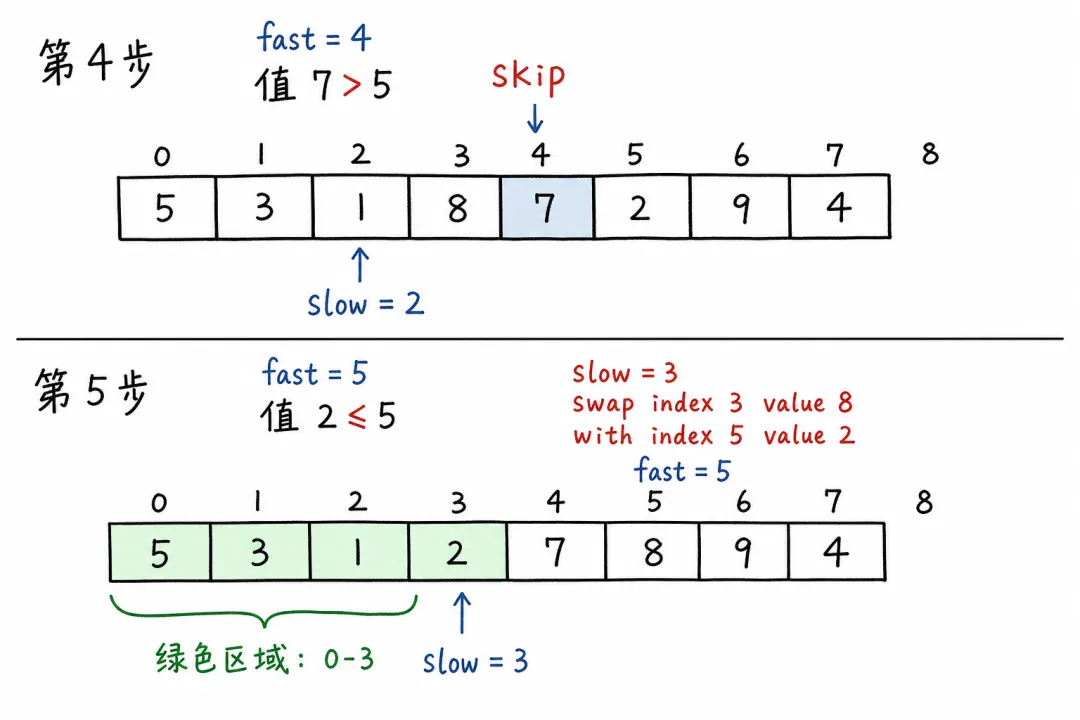
第 4 步:fast = 4,值为 7(> 5) → 跳过,slow 不动。
第 5 步:fast = 5,值为 2(≤ 5)
slow++→slow = 3swap(arr[3], arr[5]):交换 8 和 2 →[5, 3, 1, 2, 7, 8, 9, 4]左区 [5, 3, 1, 2]
第 6 步:fast = 6,值为 9(> 5) → 跳过。
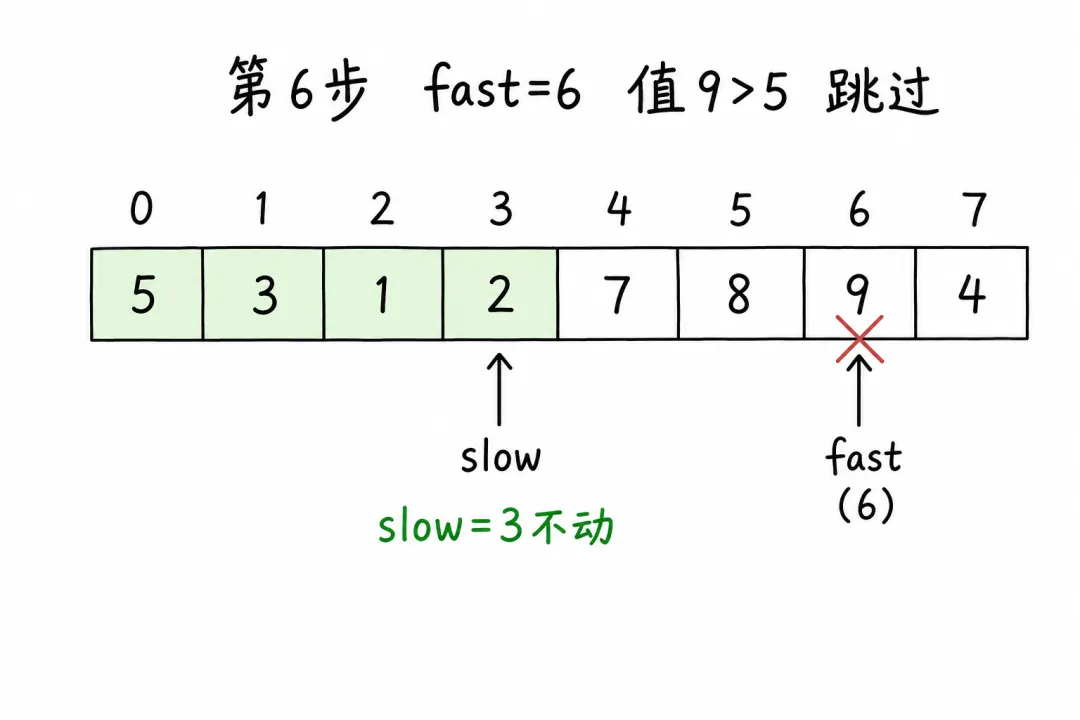
第 7 步:fast = 7,值为 4(≤ 5)
slow++→slow = 4swap(arr[4], arr[7]):交换 7 和 4 →[5, 3, 1, 2, 4, 8, 9, 7]左区 [5, 3, 1, 2, 4],扫描结束
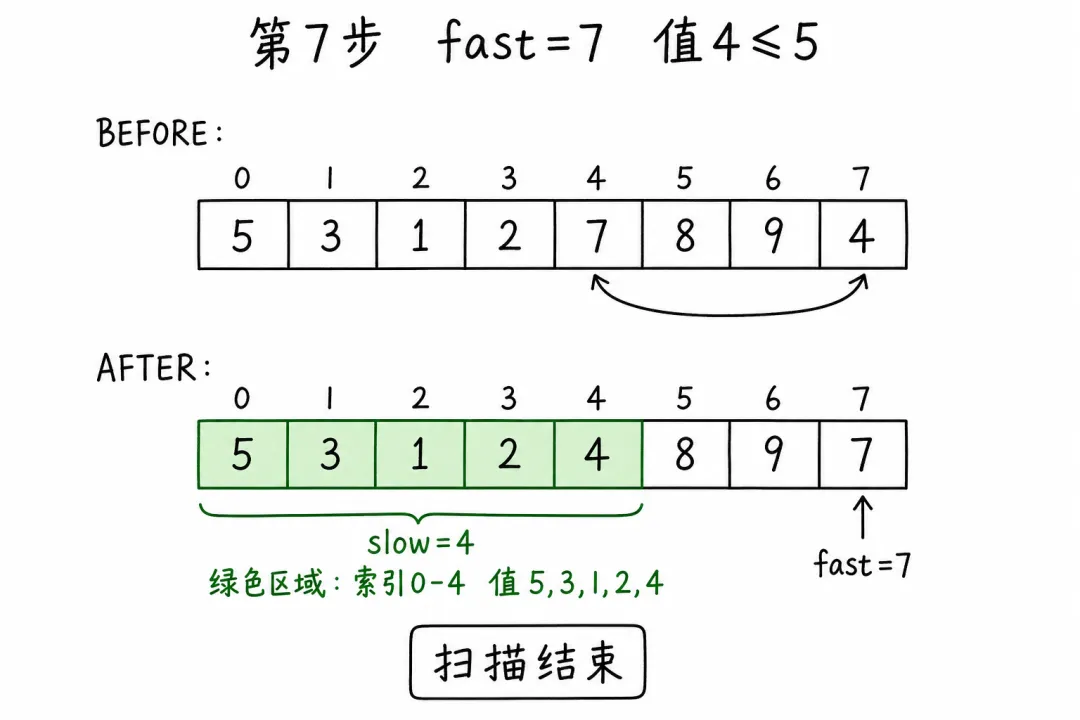
最后一步:pivot 归位
swap(arr[0], arr[4]):交换 5 和 4 → [4, 3, 1, 2, 5, 8, 9, 7]
下标 4左侧[4,3,1,2]都 ≤ 5下标 4右侧[8,9,7]都 > 5partition 完成,返回 slow = 4作为切分点,左右子数组可递归快排
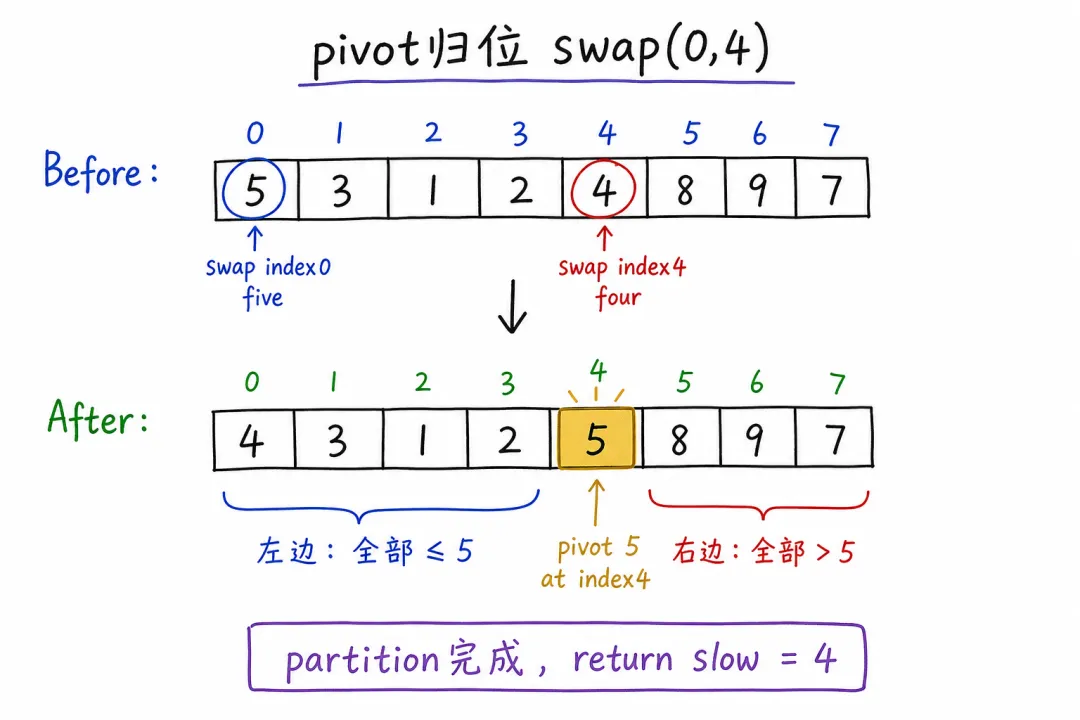
两个指针到底在干什么
fast | left+1 扫到 right | |
slow | [left..slow] 的右边界 |
fast 看到 ≤ pivot 的数,就 slow++ 并把它 swap 进左区末尾;看到更大的数就跳过。扫完后 pivot 与 arr[slow] 交换,pivot 落在正确分界上。
为什么 Linux 内核用快排
Linux 内核的 qsort 使用快速排序,三个原因:
原地排序:空间复杂度 O(log n),不需要额外数组 缓存友好:partition 过程顺序访问数组,CPU 缓存命中率高 平均 O(n log n):虽然最坏 O(n²),但实际中很少出现
双指针 partition 是实现这一切的关键。没有快慢指针的原地划分,快排就要变成归并排序,空间翻倍。
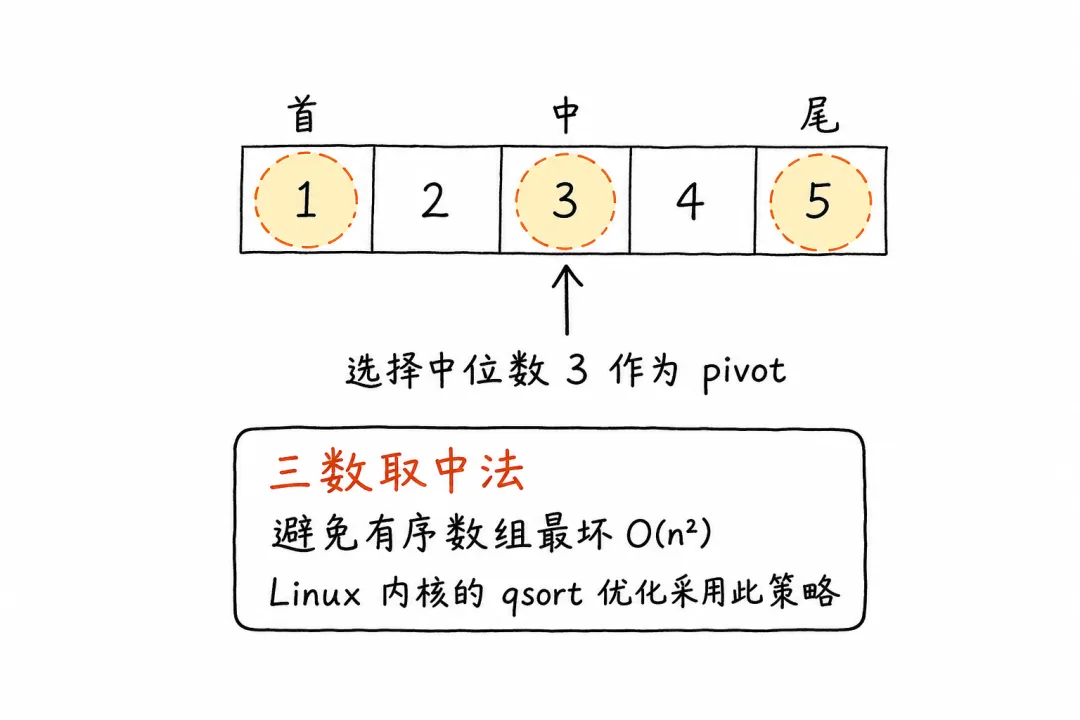
三数取中法:避免最坏情况
如果数组已经有序(比如 [1,2,3,4,5]),每次都选第一个当 pivot,partition 会极度不均衡——一边0个元素,一边n-1个。退化成 O(n²)。
Linux 内核的解决办法是三数取中法:取数组的首、中、尾三个元素,选它们的中位数作为 pivot。简单的优化,大幅降低了最坏情况出现的概率。
总结
快慢指针的精髓不是"一快一慢",而是"一个人探路,一个人划线"——划定边界,原地整理。
觉得有收获?转发给正在准备面试的朋友。
你写过快速排序吗?快慢指针的 partition 算法,你觉得容易理解吗?评论区聊聊。

