昨天我们掌握了数据分析的核心技能(描述统计/相关性/透视表/时间序列),今天我们将聚焦效率利器——Pandas常用函数!掌握 mean/median/std 等统计函数、str 字符串向量化操作、apply/map 自定义函数应用,你就能用更少的代码完成更复杂的数据处理,真正实现"优雅编程"!常用统计函数:快速洞察数据特征
统计函数是数据分析的"基础工具箱",一行代码搞定核心指标计算。
基础统计量计算
import pandas as pdimport numpy as np# 创建示例数据df = pd.DataFrame({ 'Sales': [1200, 1500, 1800, 2100, 2400, np.nan], 'Profit': [300, 450, 520, 680, 750, 820], 'Region': ['East', 'West', 'East', 'West', 'East', 'West']})# ✅ 均值:反映"平均水平"(自动忽略NaN)print("🔹 销售额均值:", df['Sales'].mean()) # 1800.0# ✅ 中位数:反映"中间水平",抗异常值干扰print("🔹 利润中位数:", df['Profit'].median()) # 600.0# ✅ 标准差:反映"波动程度",值越大越不稳定print("🔹 销售额标准差:", df['Sales'].std()) # 469.04# ✅ 方差:标准差的平方,数学推导常用print("🔹 利润方差:", df['Profit'].var()) # 33733.33
分位数与自定义聚合
# 📌 分位数:定位数据分布位置(25%/50%/75%)quantiles = df['Profit'].quantile([0.25, 0.5, 0.75])print("\n🔹 利润分位数:\n", quantiles)# 📌 一键生成统计报告(数值列)print("\n🔹 描述性统计:\n", df.describe())# 📌 自定义聚合:灵活组合多个统计量custom_stats = df['Profit'].agg([ 'count', # 非空值数量 'mean', # 均值 lambda x: x.quantile(0.9), # 90%分位数(自定义函数!) 'max' # 最大值])print("\n🔹 自定义统计报告:\n", custom_stats)
业务应用:用 agg() 一次性输出业务关心的多个指标,避免重复遍历数据,效率提升50%+!字符串处理函数:文本清洗的"瑞士军刀"
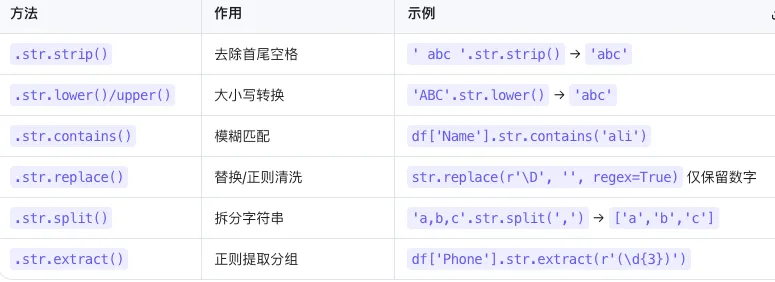
实际业务中,姓名、地址、商品描述等文本数据常含空格、大小写混乱、格式不规范等问题。Pandas 的 .str 访问器让字符串操作像数值计算一样高效!基础清洗操作
# 创建含"脏文本"的示例数据df_str = pd.DataFrame({ 'Name': [' alice ', 'BOB', 'charlie', ' David '], 'Phone': ['138-0013-8000', '13900138001', '(010)88889999', '137 0013 8002'], 'Email': ['Alice@Gmail.com', 'bob@qq.COM', 'CHARLIE@163.com', 'david@outlook.cn']})# ✅ 去除首尾空格 + 统一大小写(姓名标准化)df_str['Name'] = df_str['Name'].str.strip().str.title()print("🔹 标准化姓名:\n", df_str['Name'])# ✅ 字符串替换:正则表达式支持!(手机号格式化)df_str['Phone'] = df_str['Phone'].str.replace(r'[\(\)\-\s]', '', regex=True)print("\n🔹 格式化手机号:\n", df_str['Phone'])# ✅ 大小写转换:统一邮箱格式df_str['Email'] = df_str['Email'].str.lower()print("\n🔹 标准化邮箱:\n", df_str['Email'])
高级字符串操作
# 🔍 模糊匹配:筛选包含特定关键词的行contains_alice = df_str['Name'].str.contains('Alice', case=False)print("\n🔹 包含'Alice'的行:\n", df_str[contains_alice])# ✂️ 提取子串:从手机号提取前3位(区号)df_str['AreaCode'] = df_str['Phone'].str[:3]print("\n🔹 提取区号:\n", df_str[['Phone', 'AreaCode']])# 🔗 字符串拼接:生成用户标识df_str['UserID'] = df_str['Name'].str[:3] + '_' + df_str['AreaCode']print("\n🔹 生成用户ID:\n", df_str['UserID'])
应用函数:自定义逻辑的"万能接口"
当内置函数无法满足业务需求时,apply() 和 map() 让你轻松注入自定义逻辑。apply():行列级自定义操作
# 创建示例数据df_apply = pd.DataFrame({ 'Price': [100, 200, 300, 400], 'Quantity': [2, 3, 1, 4]})# ✅ 场景1:对单列应用函数(计算含税价)def add_tax(price): return price * 1.13 # 13%增值税df_apply['Price_Tax'] = df_apply['Price'].apply(add_tax)print("🔹 含税价格:\n", df_apply[['Price', 'Price_Tax']])# ✅ 场景2:对整行应用函数(计算订单总额)def calc_total(row): return row['Price'] * row['Quantity'] * 1.13df_apply['Total'] = df_apply.apply(calc_total, axis=1) # axis=1 表示按行应用print("\n🔹 订单总额:\n", df_apply[['Price', 'Quantity', 'Total']])
map():值映射与替换(专为Series设计)
# 创建示例数据df_map = pd.DataFrame({ 'Level': ['L1', 'L2', 'L3', 'L1', 'L2'], 'Score': [85, 92, 78, 88, 95]})# ✅ 场景1:字典映射(等级→中文描述)level_map = {'L1': '初级', 'L2': '中级', 'L3': '高级'}df_map['Level_CN'] = df_map['Level'].map(level_map)print("\n🔹 等级映射结果:\n", df_map)# ✅ 场景2:函数映射(分数→评级)def grade_label(score): if score >= 90: return 'A' elif score >= 80: return 'B' else: return 'C'df_map['Grade'] = df_map['Score'].map(grade_label)print("\n🔹 分数评级:\n", df_map[['Score', 'Grade']])
函数 | 适用对象 | 核心用途 | 性能 |
|---|
apply()
| Series / DataFrame | 任意自定义逻辑 | 中等(支持复杂操作) |
map()
| 仅 Series | 值映射/替换 | ⚡ 更快(专为映射优化) |
最佳实践:能用 map() 就别用 apply(),能用向量化操作就别用循环!避坑指南
综合实战:用户数据清洗流水线
将今日知识点串联,模拟真实业务场景:
import pandas as pdimport numpy as np# 1. 构造"脏用户数据"df_raw = pd.DataFrame({ 'Name': [' alice ', 'BOB', 'charlie', 'David', np.nan], 'Phone': ['138-0013-8000', '139 0013 8001', '(010)88889999', '13700138002', '13600138003'], 'Level': ['L1', 'L2', 'L3', 'L1', 'L2'], 'Score': [85, 92, np.nan, 88, 95], 'RegisterDate': ['2023-01', '2023/02', '2023.03', '2023-04', '2023-05']})print("🔹 原始数据预览:\n", df_raw.head())# 2. 字符串清洗df = df_raw.copy()df['Name'] = df['Name'].str.strip().str.title() # 姓名标准化df['Phone'] = df['Phone'].str.replace(r'[\(\)\-\s/.]', '', regex=True) # 手机号纯数字# 3. 缺失值处理 + 类型转换df['Score'] = pd.to_numeric(df['Score'], errors='coerce') # 非法值转NaNdf['Score'] = df['Score'].fillna(df['Score'].median()) # 中位数填充df['RegisterDate'] = pd.to_datetime(df['RegisterDate'], errors='coerce')# 4. 应用自定义函数level_map = {'L1': '初级', 'L2': '中级', 'L3': '高级'}df['Level_CN'] = df['Level'].map(level_map).fillna('未知')def grade_label(score): if pd.isna(score): return 'N/A' elif score >= 90: return 'A' elif score >= 80: return 'B' else: return 'C'df['Grade'] = df['Score'].map(grade_label)# 5. 统计摘要print("\n🔹 清洗后数据质量报告:")print(f" • 有效用户数: {df['Name'].notna().sum()}")print(f" • 平均分数: {df['Score'].mean():.1f}")print(f" • 等级分布:\n{df['Level_CN'].value_counts()}")print(f" • 手机号格式合格率: {(df['Phone'].str.len() == 11).mean():.1%}")# 6. 导出结果df.to_excel('cleaned_users.xlsx', index=False)print("\n✅ 清洗完成!结果已保存至 cleaned_users.xlsx")
预期输出:控制台展示原始数据 → 清洗逻辑 → 质量报告 → 导出确认,助你快速验证处理效果。📝 今日知识速记卡
函数类型 | 核心函数 | 关键技巧 |
|---|
统计函数 | mean(), median(), std(), quantile()
| agg() 支持自定义函数,describe() 一键概览
|
字符串函数 | .str.strip(), .str.replace(), .str.contains()
| 正则用 regex=True,缺失值加 na=False |
应用函数 | apply(), map()
| map 专用于 Series 映射,apply(axis=1) 按行操作
|
【一起学Python】每天进步一点点,365天后遇见更优秀的自己!
👉 关注公众号,不错过每天的学习内容!
🎯 今日金句:"函数是代码的积木,组合越巧,效率越高;理解越深,自由越大。" 🧱✨


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
