在深度学习大火的今天,很多新手忽略了一个最简单、最实用、零训练门槛的经典分类算法——KNN(K近邻)。
它不需要复杂的网络结构、不需要反向传播、不需要调参炼丹,却能轻松搞定图像分类、字符识别、特征匹配等基础CV任务。
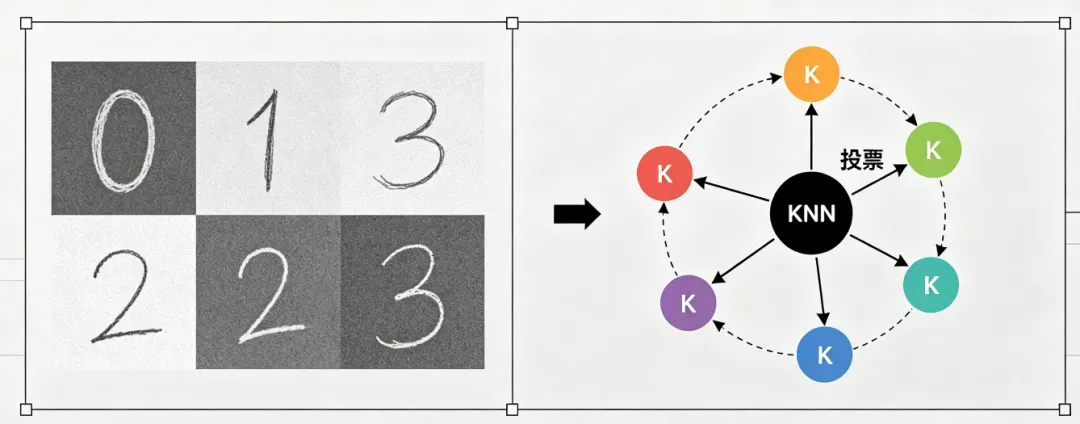
在 OpenCV 传统视觉项目中,KNN 是轻量化图像识别的首选基线算法。尤其适合:手写数字识别、简单字符OCR、物体分类、样本少的轻量化场景。
今天这篇文章,带你从零吃透 KNN 核心原理、优缺点、K值选型,手把手实现手写数字 OCR 识别实战,零基础也能直接落地运行!
一、什么是 KNN(K近邻算法)?通俗大白话
KNN(K-Nearest Neighbors),全称 K近邻算法,是最简单的有监督机器学习分类算法。
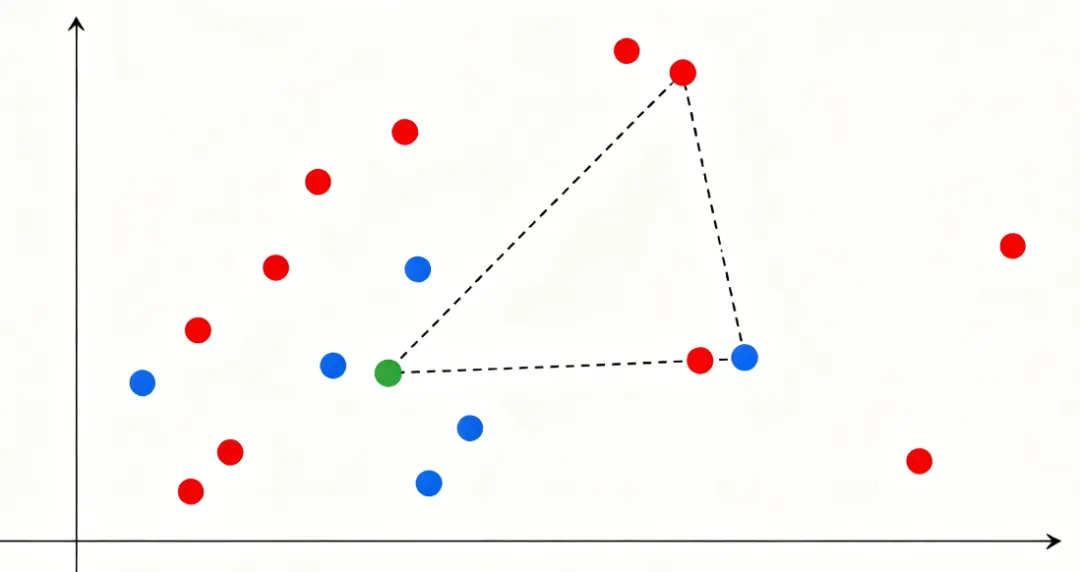
核心思想一句话:物以类聚,看邻居判类别。
把所有数据映射在特征空间中,对于一个未知样本:
1、计算它与所有已知样本的空间距离
2、选出距离最近的 K 个邻居样本
3、统计这 K 个邻居的类别,少数服从多数,即为当前样本分类结果
全程无复杂计算、无拟合过程、无脑匹配,极其适合入门图像识别!
二、KNN 核心知识点(必懂)
1、常用距离计算公式
OpenCV-KNN 默认使用欧式距离,也是图像识别最通用的距离算法:
简单理解:两个样本特征差异越小,距离越近,相似度越高。
2、K值如何选择?(核心重点)
•K值过小:只看少量邻居,极易受噪点、异常值干扰,过拟合
•K值过大:会吸纳远距离无关样本,特征模糊,欠拟合、分类精度下降
工程经验:K 一般取奇数(避免平票),常规场景 K=3、5、7 效果最优。
3、KNN 整体工作流程
•步骤1:准备训练数据集(已知类别图像+标签)
•步骤2:图像扁平化,转为一维特征向量
•步骤3:初始化KNN模型,载入训练样本
•步骤4:输入待测图像,计算距离、匹配近邻、投票分类
•步骤5:输出识别结果
三、KNN 优缺点深度总结
✅ 核心优点
•原理极简、上手零难度、无需训练迭代
•对小样本、简单图像任务适配性极强
•无训练成本、推理速度快、轻量化、可嵌入式部署
•对异常样本不敏感(合理K值下)
❌ 缺点局限
•属于惰性学习,每次识别都要遍历所有样本,大数据集速度慢
•对高分辨率、复杂图像特征提取能力弱
•对样本不均衡数据集适配差
适用场景:手写字符、数字识别、简单OCR、小样本分类、低算力设备识别任务。
四、实战项目:KNN 手写数字 OCR 识别(完整可运行代码)
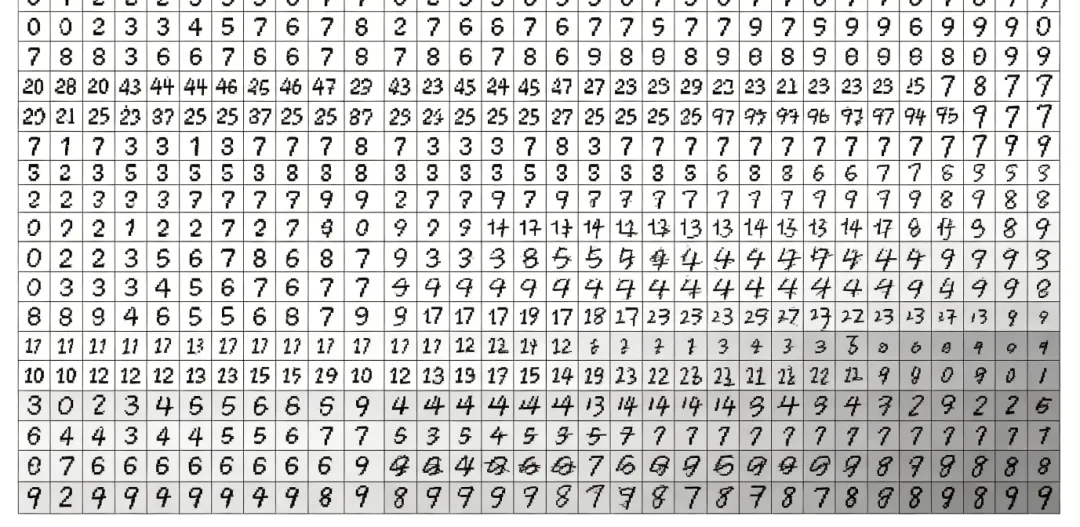
我们基于 OpenCV 内置的手写数字数据集,搭建一套端到端KNN数字识别系统,实现:数据加载、特征处理、模型训练、数字OCR识别、结果输出。
pythonimport cv2import numpy as np# 1、加载OpenCV自带手写数字数据集# 数据集:5000张手写数字图片(0-9),20*20分辨率img = cv2.imread("digits.png", 0)# 2、图像切片分割:拆分为单个数字样本# 图片尺寸:1000*2000,分割为 50行*100列 单个20*20数字cells = [np.hsplit(row, 100) for row in np.vsplit(img, 50)]# 3、构建训练集与标签x = np.array(cells)# 训练样本:扁平化 (5000,400)train = x.reshape(-1, 400).astype(np.float32)# 制作标签:0-9循环500次label = np.arange(10)train_labels = np.repeat(label, 500)[:,np.newaxis]# 4、初始化KNN模型并训练knn = cv2.ml.KNearest_create()knn.train(train, cv2.ml.ROW_SAMPLE, train_labels)# 5、读取测试手写数字图片(自定义测试图)test_img = cv2.imread("test_num.jpg", 0)# 缩放为20*20标准尺寸,扁平化test_img = cv2.resize(test_img, (20,20))test = test_img.reshape(1, -1).astype(np.float32)# 6、KNN识别推理 K=5ret, result, neighbours, dist = knn.findNearest(test, k=5)# 7、输出识别结果print(f"KNN识别结果:{int(result[0][0])}")print(f"邻近5个样本类别:{neighbours}")print(f"对应样本距离:{dist}") |
五、核心代码解析
1、样本预处理逻辑
所有图像必须统一尺寸、扁平化一维向量,这是KNN识别的关键。KNN无法直接识别二维图像,只能对比一维特征数据。
2、K值设置逻辑
代码中 K=5 为通用最优参数,兼顾抗干扰性和识别精度。复杂手写模糊场景可微调为K=7,干净标准手写体可使用K=3。
3、输出参数含义
•result:最终识别分类结果(预测数字)
•neighbours:K个近邻样本的类别
•dist:对应近邻样本的距离值,距离越小可信度越高
六、效果优化技巧(提升OCR准确率)
•图像二值化:测试图片先做黑白二值化,去除背景噪点,强化数字轮廓
•形态学降噪:通过开闭运算去除椒盐噪点,优化手写边缘
•尺寸归一化:所有训练、测试图像必须统一20*20标准尺寸
•动态调K值:清晰图像用小K,模糊干扰图像用大K
七、新手常见误区避坑
•误区1:KNN需要深度学习训练❌ KNN是惰性学习,无训练迭代过程,仅存储样本,识别时匹配计算
•误区2:K值越大精度越高❌ K值过大会引入无关样本,反而降低识别准确率
•误区3:直接使用彩色图识别❌ 必须灰度化+归一化,彩色通道会干扰特征距离计算
•误区4:样本尺寸不统一❌ 尺寸不一致,特征维度不同,识别直接失效
八、全文总结
KNN 是传统机器学习+机器视觉的入门神器,没有复杂公式、没有晦涩原理,却能落地实用的手写OCR识别任务。
对于简单字符识别、小样本分类、低算力设备,KNN 依然是性价比最高的算法!
相比于深度学习模型,它无需海量数据、无需GPU、无需训练调参,开箱即用,极其适合新手入门图像识别领域。
掌握KNN,就是掌握了传统图像分类、轻量化OCR识别的核心基础!
❤️点赞+在看,后台回复关键词【KNN】,领取完整优化代码+手写数字测试素材+K值调参手册!
关注本号,持续更新 OpenCV 传统视觉+机器学习实战干货!
评论区打卡:KNN手写识别,一起从零入门图像OCR!
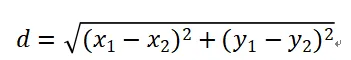
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
