少儿自学编程第29课:Python 二分查找——在有序列表中快速找目标
- 2026-06-15 17:05:28

昨天Tyree写完了冒泡排序,把一列乱序的数字排得整整齐齐。他问我:“排好之后,我想找一个特定的数字,比如找‘92’,怎么找最快?”
我说:“最简单的方法是从头到尾挨个看,叫‘线性查找’。但如果列表很长,比如一万个数,最坏情况要看一万次。你有没有更快的方法?”
他想了想:“就像猜数字游戏那样?我先猜中间的数,如果目标比它小,就只找左半边;比它大,就找右半边。这样每次都能砍掉一半!”
我惊讶地说:“不错哦,你这就悟出了‘二分查找’的核心思想!”
今天我们就来实现这个高效的查找算法。你会学到二分查找的原理、怎么用循环实现、以及它比线性查找快多少。
以后你在有序数据里找东西,再也不用傻傻地从头翻到尾了。
01
先看最简单的:线性查找
在学二分查找之前,我们先看看最笨的方法——从头到尾挨个找。
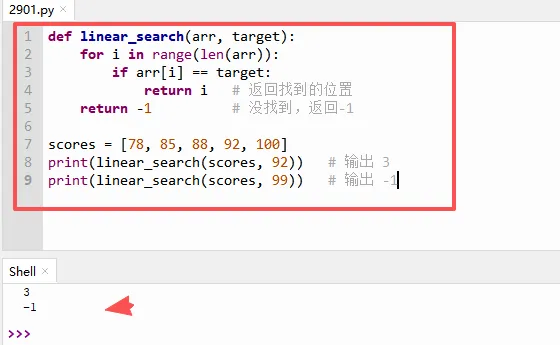
`def linear_search(arr, target):` 定义了一个查找函数,接收两个参数:要查找的列表 `arr` 和目标值 `target`。
`for i in range(len(arr)):` 使用 `i` 作为索引,从 `0` 到列表长度减1,依次访问每个位置。
`if arr[i] == target:` 检查当前这个位置的值是否等于目标。如果相等,`return i` 立即返回当前索引,函数结束。注意这个 `return` 会跳出循环,不再往后找。
如果循环结束还没找到,就执行 `return -1`。返回 `-1` 是编程里的习惯,表示“没找到”,因为正常的索引都是从0开始的,-1 不可能是有效位置。
Tyree问:“为什么不直接返回 `None`?” 我告诉他,`-1` 更常见,而且有时候 `None` 也可能被当成有效值(比如列表里允许存 `None`),用 `-1` 更明确。
这个函数很简单,就是循环列表,一个一个比。如果列表有10000个数,最坏情况要找10000次。Tyree说:“这太慢了,要是查字典也这样翻,得翻到什么时候!”
02
分查找的思想(像猜数字)
二分查找有一个非常重要的前提:列表必须是已排序的(从小到大或从大到小)。比如排好序的成绩 `[78, 85, 88, 92, 100]`。
步骤:
1. 找中间位置的数。
2. 如果中间数等于目标,就找到了。
3. 如果目标比中间数小,就到**左半边**继续找。
4. 如果目标比中间数大,就到**右半边**继续找。
5. 重复直到找到或区间缩小到空。
这就像你猜数字时,每次都猜中间的数,然后根据“大了”或“小了”缩小范围。Tyree自己画了张图,把区间每次砍半的过程画出来,他说:“这样每一步都能排除一半的错误答案,太聪明了!”
03
用循环实现二分查找
我们手动模拟一个例子:在 `[78, 85, 88, 92, 100]` 中找 `92`。
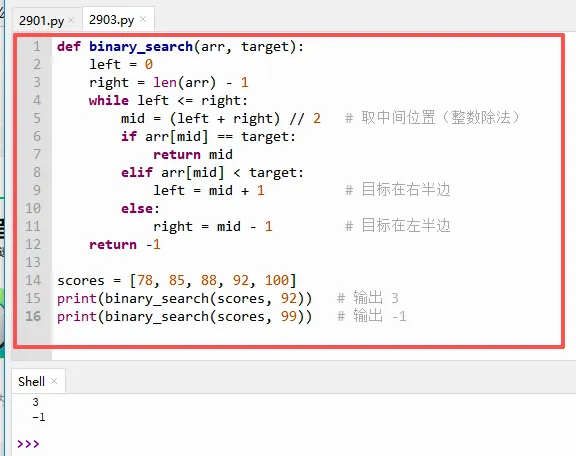
`left = 0`:左边界,初始指向列表的第一个元素(索引0)。
`right = len(arr) - 1`:右边界,初始指向最后一个元素(索引 `长度-1`)。比如长度5,`right` 就是4。
`while left <= right:` 只要左边界没有超过右边界,就继续查找。如果 `left > right`,说明区间里已经没有元素了,目标不存在。
`mid = (left + right) // 2`:`//` 是整数除法,向下取整。比如 `(0+4)//2 = 2`,取中间位置。当 `left` 和 `right` 是奇数个数时,中间偏左。
`if arr[mid] == target:` 如果中间位置的值正好等于目标,恭喜,找到!返回 `mid`。
`elif arr[mid] < target:` 如果中间值比目标小,那么目标一定在右半边(因为列表从小到大排)。于是把 `left` 更新为 `mid + 1`,丢弃左半边。
`else:` 剩下的情况就是中间值比目标大,目标在左半边,所以把 `right` 更新为 `mid - 1`。
循环结束后还没返回,这就说明没找到,返回 `-1`。
Tyree试了几次,每次 `left` 和 `right` 的变化都记在纸上,他说:“看到区间一点点缩小,最后只剩一个位置,太直观了。”
04
二分查找的步数对比
我们可以写一个小程序,对比线性查找和二分查找在1000000个数中的查找次数。
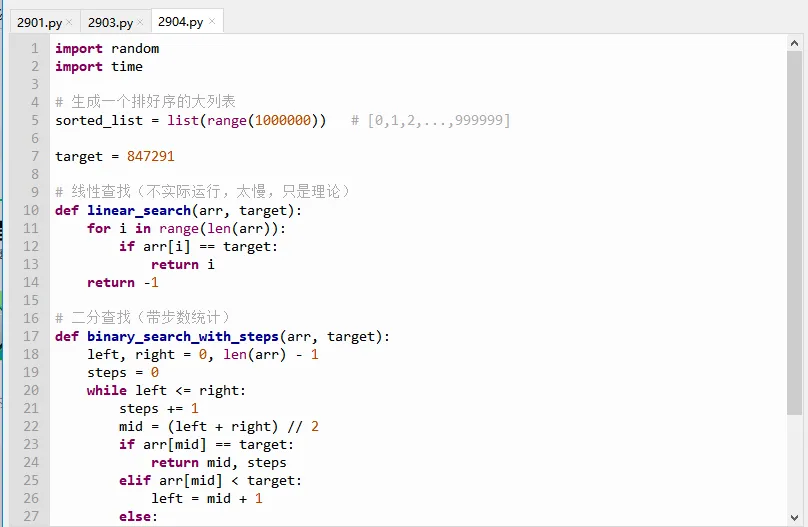
`list(range(1000000))` 生成一个从0到999999的列表,本身就是排好序的。
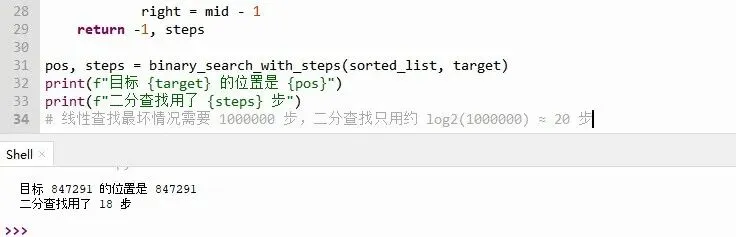
二分查找的 `steps` 记录了循环次数。运行后你会发现只用了大约20步。因为每次区间减半,2^20 = 1,048,576,所以最多20次就能覆盖100万个数。
Tyree惊讶地说:“一百万个数只查20次?太牛了!” 我告诉他这就是“指数级”和“线性”的区别,数据越大,差距越离谱。
05
二分查找的递归写法(了解即可)
除了用循环,还可以用递归(函数自己调用自己)。递归写法更简洁,但理解起来稍难,可以当作扩展知识。
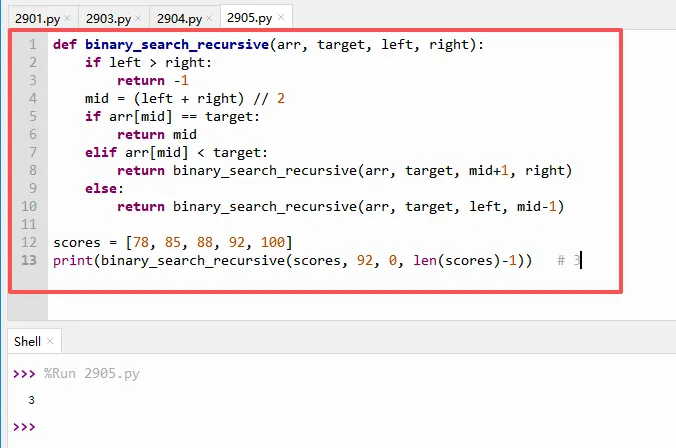
递归版本不需要 `while` 循环,而是每次调用自己,并改变边界。
基线条件:`if left > right:` 说明区间空,返回 -1。
否则计算 `mid`,比较后决定往左半边或右半边递归。
要注意的是:递归深度受限于Python的默认递归限制(约1000),但二分查找的深度很小(log2(10^6)≈20),所以安全。
Tyree一开始觉得递归有点绕,但把每次调用的参数写在纸上后,他说:“原来就是循环的另一种写法,只是函数自己叫自己。”
06
小项目:用二分查找在水熊虫存活天数中查某个值
假设你记录了100只水熊虫的存活天数(已排序),你想知道是否有存活15天的。
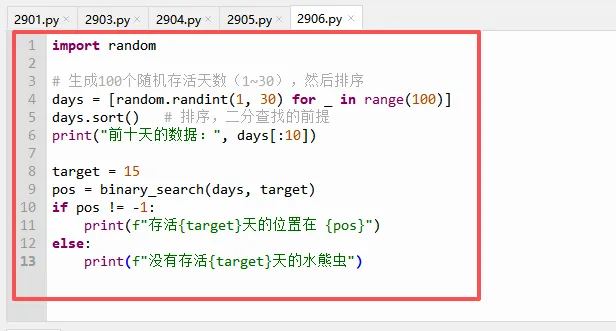
`[random.randint(1,30) for _ in range(100)]` 是一个列表推导式,生成100个随机数。
`days.sort()` 原地排序,这是二分查找的必要条件。
然后调用我们写好的 `binary_search`,根据返回值判断是否存在。
Tyree说:“以后我在一堆实验数据里找某个值,再也不用傻乎乎遍历了。”
07
今天学到了什么
线性查找:一个个比,简单但慢,适合小数据或无序数据。
二分查找:必须有序,每次砍掉一半,速度指数级提升,大数据必备。
循环实现:维护 `left` 和 `right` 边界,更新 `mid`,注意循环条件 `left <= right`。
边界更新:`left = mid + 1` 和 `right = mid - 1`,不能写成 `left = mid`,否则可能死循环。
递归实现:函数自己调用自己,基线条件 `left > right`。
应用场景:查字典、猜数字、在有序数据中快速定位。
Tyree兴奋地说:“以后我查字典也可以用这个思路!先翻中间,看拼音在哪一半。” 我说对,编程思想在生活中无处不在。
好了,今天课程就到这里,课后多多敲键盘哦!
下一节课:综合练习——学生成绩管理系统。
我们会把排序、查找、文件读写、数据可视化全部用上,做一个完整的项目。
Tyree说要把他的期末成绩输进去,然后画个柱状图看看哪科最好。
————热门推荐————
少儿自学编程第28课:Python冒泡排序——让乱序数字排排坐
自学编程第8课:turtle画对称图形(彩色螺旋、彩色对称花、等边三角形、五角星)
自学编程第7课:turtle画图入门(画一个正方形,五角形,螺旋形,三角形)
自学编程第2课:用input让电脑问你名字(做一个打招呼程序)
自学编程第一步:安装Python和Thonny(零基础图文教程)
(本系列教程每天更新,欢迎关注收藏)
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 机房又封?Python在线模考平台已就绪!
- 听说公司要裁员?我用 Python 连夜盘完了 850 条真实数据,发现了搞钱的终极秘密!
- Linux 7.1-rc1 来了!NTFS 性能暴涨 110%,服役 30 年的 i486 正式退役
- Python从入门到实战-第 9 章:练习示例
- PHP + RabbitMQ 死信队列实战:延迟订单自动取消、超时任务重试,一文搞定
- 一图掌握python命令速查表!
- python做金句视频,自己下载音效
- 安装Python环境——自然语言编程需要用到的软件环境
- kali-linux-2025.3-installer|官方纯净镜像,自定义安装
- Pynsisit:让Python程序变身Windows安装包
