🎯 你是不是想有个自己的音频克隆软件,我用Python+fish实现了,复制我的代码即可——上传一段 30 秒录音,让 AI 用你的声音朗读任何文字!
一、🤔 这是什么神仙项目?
👉 一句话总结:开源免费(有付费的)
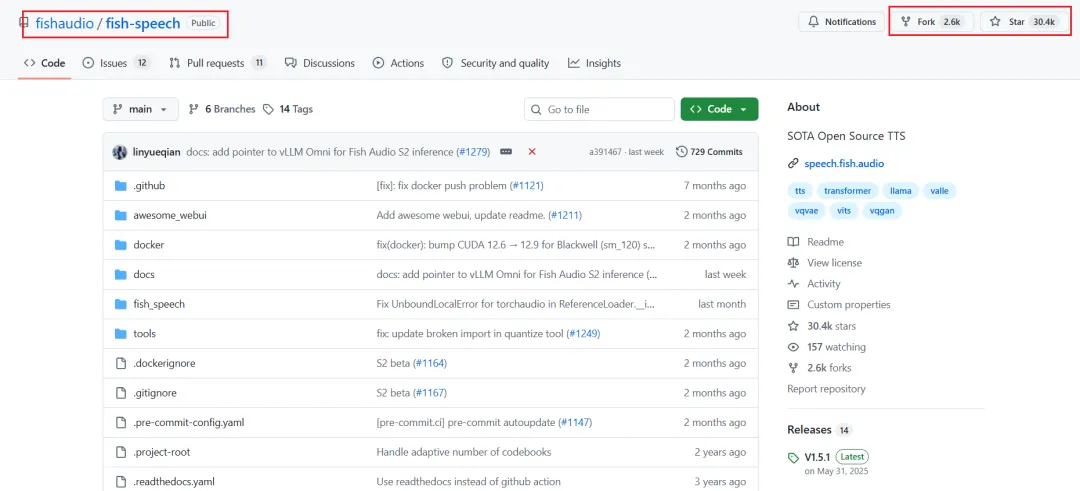
- • 🏠 开源地址:https://github.com/fishaudio/fish-speech
- • 📖 官方文档:https://docs.fish.audio
- • 🌐 在线体验:https://fish.audio
关注我,送您一个月的“plus”会员福利
🌟 核心亮点速览
| |
|---|
| |
| |
| |
| Apache 2.0 协议,支持本地部署,数据不出门 |
二、⚡ 3 分钟极速上手
🪜 Step 1:获取 API Key 🔑
🆕 点击 New API Key,复制密钥(形如 sk-xxxxxxxx)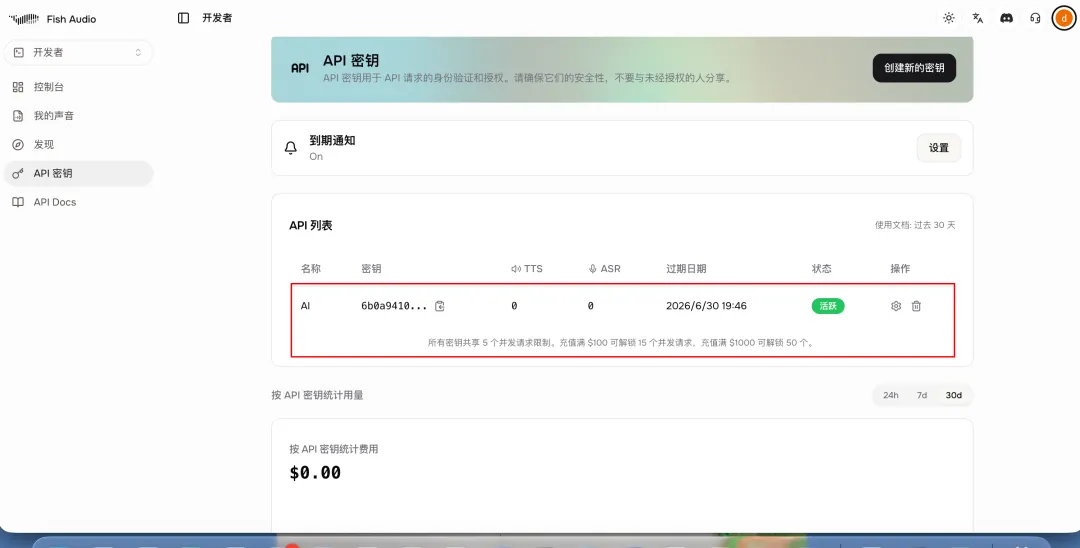
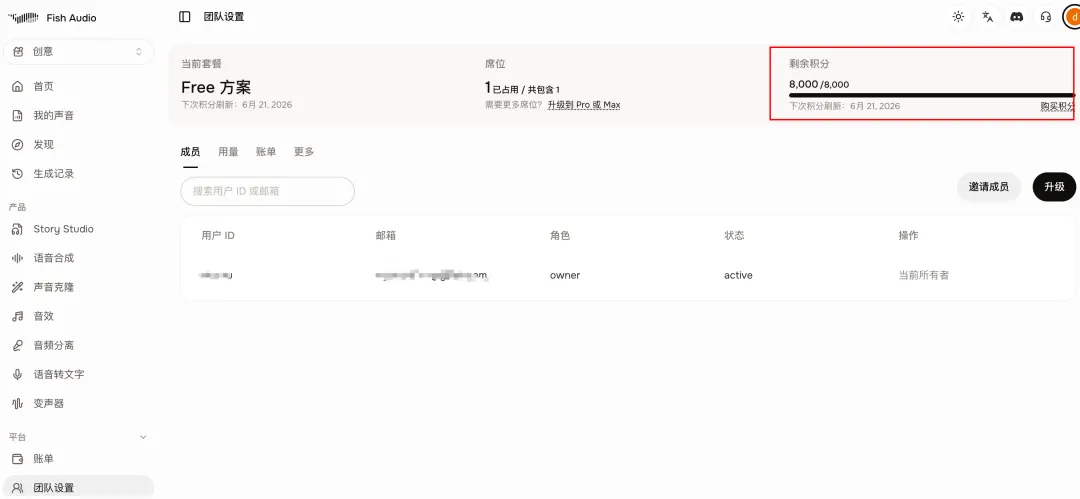
🎁 免费额度:每月 7 分钟 高质量语音 + 8000 积分,够你玩到吐!
📦 Step 2:安装依赖
pip install requests gradio # 就这两个,没了
🚀 Step 3:跑通第一个 Demo(要充值)
把下面代码保存为 tts_demo.py,替换 YOUR_API_KEY,运行即可:
import requestsAPI_KEY = "YOUR_API_KEY"TEXT = "你好,欢迎使用 Fish Audio,这是我的声音克隆效果。" # ✏️ 改这里REFERENCE_AUDIO = "my_voice.wav" # 🎤 改成你的录音文件路径OUTPUT_AUDIO = "output.mp3" # 💾 输出文件名url = "https://api.fish.audio/v1/tts"headers = {"Authorization": f"Bearer {API_KEY}"}with open(REFERENCE_AUDIO, "rb") as f: files = {"reference_audio": (REFERENCE_AUDIO, f, "audio/wav")} data = { "text": TEXT, "reference_text": "", # 录音对应的文本,不知道可留空 "model": "fish-speech-1.5", "format": "mp3" } response = requests.post(url, headers=headers, files=files, data=data)if response.status_code == 200: with open(OUTPUT_AUDIO, "wb") as out: out.write(response.content) print(f"✅ 合成成功!音频已保存为 {OUTPUT_AUDIO}")else: print(f"❌ 请求失败:{response.status_code}\n{response.text}")python tts_demo.py
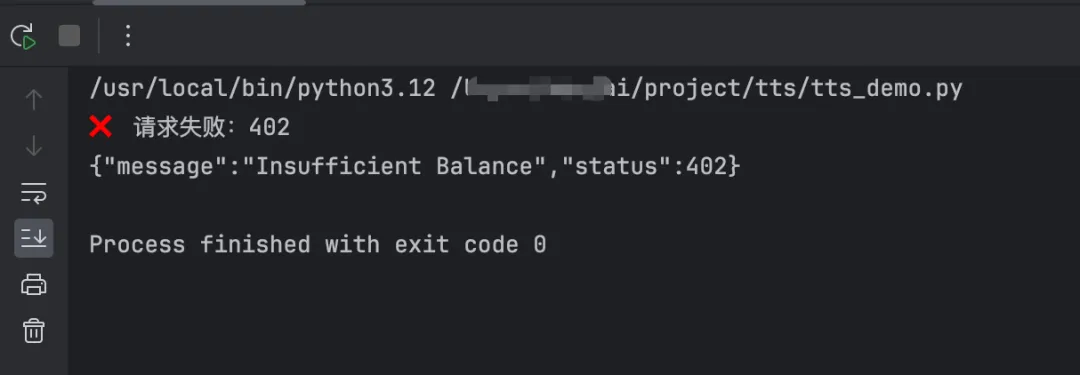
意思是余额不足,要充值
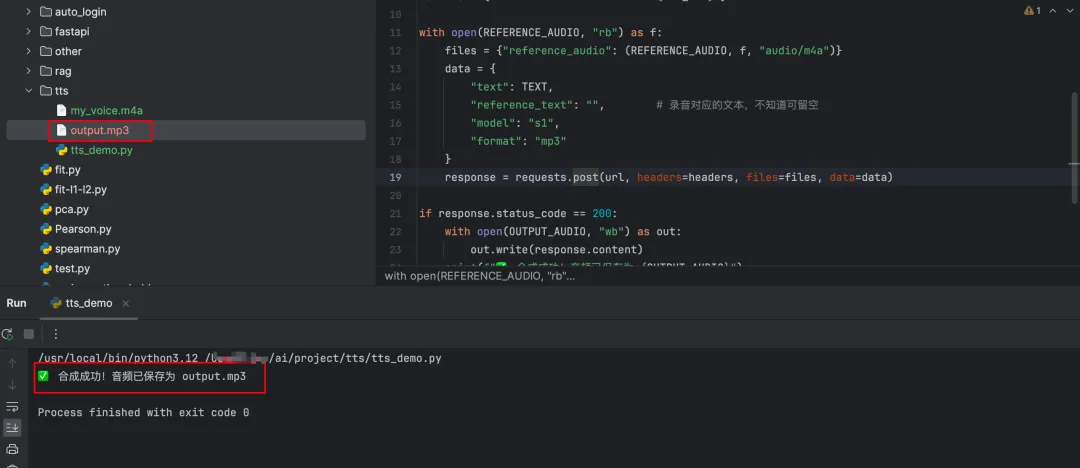
🎉 打开 output.mp3 —— 恭喜,你已经成功,克隆了自己的声音!
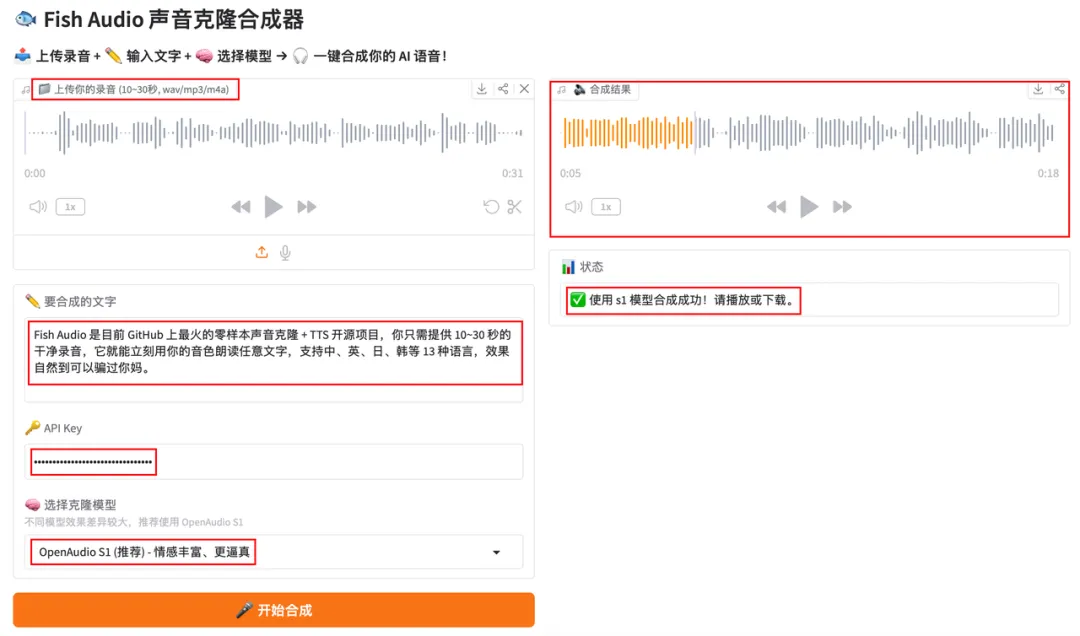
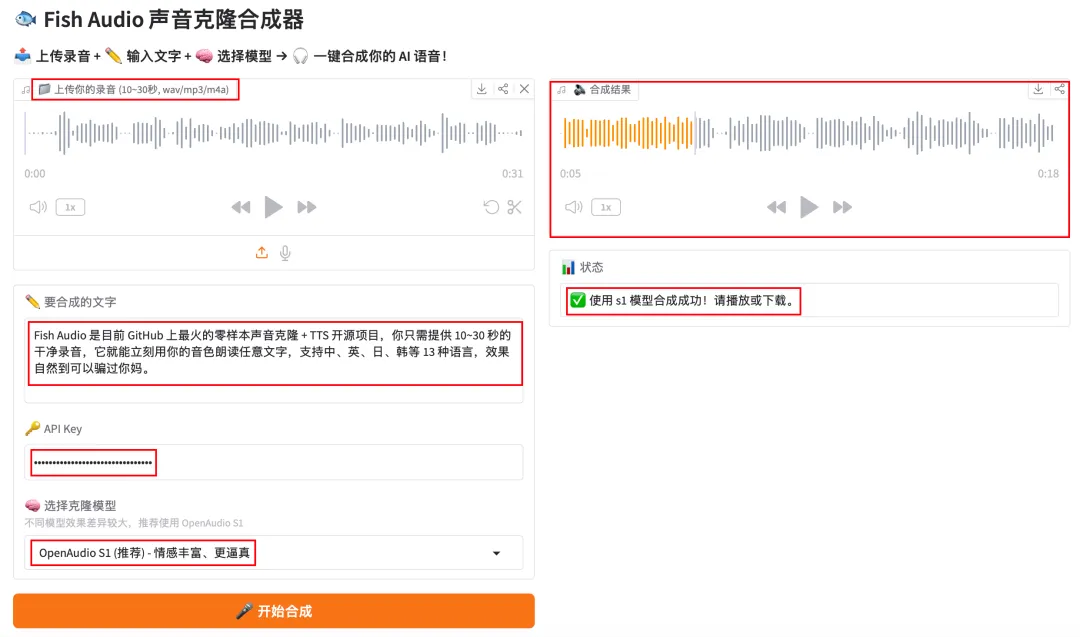
三、🖥️ Python 图形界面——点点鼠标就能用!
🎨 基于 Gradio 的 Web 界面,上传录音 → 输入文字 → 一键合成 → 在线播放 & 下载!
🎛️ 界面功能
- • 🔑 填写 API Key(仅本地使用,不上传)
▶️ 运行
完整代码仔最后;
浏览器打开 http://127.0.0.1:7860,开箱即用!
四、🥊 同期大乱斗:谁才是声音克隆之王?
下面一张表帮你快速选型:
| | | | | |
|---|
| ⭐ GitHub | | | | | |
| 🎤 最少样本 | | 3 秒 | | 2 秒 | |
| 🌐 语言支持 | 13 种 | | | | |
| 🎭 情感控制 | | 细粒度情感指令 | | | |
| ⚡ 推理速度 | | | | RTF 0.15 | |
| 🎯 音色相似度 | | | 95%+ | | |
| 📜 开源协议 | | | | | |
| 💻 本地部署 | | | | | |
| 🌍 在线 API | | | | | |
📌 选型速览:
- • 🧧 中文优先 + 有 API 需求 → 🐟 Fish Audio(语言支持最广,在线 API 可用)
- • 🎙️ 追求极致克隆逼真度 → 🎯 CosyVoice / ⚡ GPT-SoVITS(音色相似度天花板)
- • 🏭 批量生产 + 极速推理 → 🔥 F5-TTS(2 秒克隆,实时因子 0.15)
- • 🎬 需要情感表演 → 🎯 CosyVoice(支持哭腔、方言口音调整)
六、📊 API 费用一览
如果你后期想要完全免费 + 无限调用 + 数据不出门,本地部署是终极选择(需要 NVIDIA 显卡,显存 ≥ 8GB)
import gradio as grimport requestsimport tempfileimport osdef tts_clone(audio_file, text, api_key): """🪄 使用 Fish Audio API 进行声音克隆与合成""" if not api_key: return None, "❌ 请输入 API Key" if audio_file is None: return None, "❌ 请上传参考录音" if not text.strip(): return None, "❌ 请输入要合成的文本" url = "https://api.fish.audio/v1/tts" headers = {"Authorization": f"Bearer {api_key}"} with open(audio_file, "rb") as f: files = {"reference_audio": (os.path.basename(audio_file), f, "audio/wav")} data = { "text": text, "reference_text": "", "model": "fish-speech-1.5", "format": "mp3" } try: resp = requests.post(url, headers=headers, files=files, data=data, timeout=30) except Exception as e: return None, f"❌ 网络错误:{e}" if resp.status_code == 200: with tempfile.NamedTemporaryFile(suffix=".mp3", delete=False) as tmp: tmp.write(resp.content) tmp_path = tmp.name return tmp_path, "✅ 合成成功!请播放或下载。" else: return None, f"❌ API 错误 {resp.status_code}:{resp.text}"# 🎨 构建界面with gr.Blocks(title="🐟 Fish Audio 声音克隆合成器") as demo: gr.Markdown(""" # 🐟 Fish Audio 声音克隆合成器 ### 📤 上传录音 + ✏️ 输入文字 → 🎧 一键合成你的 AI 语音! """) with gr.Row(): with gr.Column(scale=1): audio_input = gr.Audio( label="📁 上传你的录音 (10~30秒, wav/mp3)", type="filepath" ) text_input = gr.Textbox( label="✏️ 要合成的文字", lines=4, placeholder="请输入需要朗读的内容... 💬" ) api_key_input = gr.Textbox( label="🔑 API Key", type="password", placeholder="输入你的 Fish Audio API Key" ) submit_btn = gr.Button("🎤 开始合成", variant="primary", size="lg") with gr.Column(scale=1): output_audio = gr.Audio(label="🔊 合成结果", type="filepath", interactive=False) status_text = gr.Textbox(label="📊 状态", interactive=False) submit_btn.click( fn=tts_clone, inputs=[audio_input, text_input, api_key_input], outputs=[output_audio, status_text] ) gr.Markdown("---") gr.Markdown(""" > 🔐 API Key 仅在本地使用,不会上传到第三方。 > 🔗 获取地址:[Fish Audio 设置页](https://fish.audio/user/settings) """)if __name__ == "__main__": demo.launch()
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
