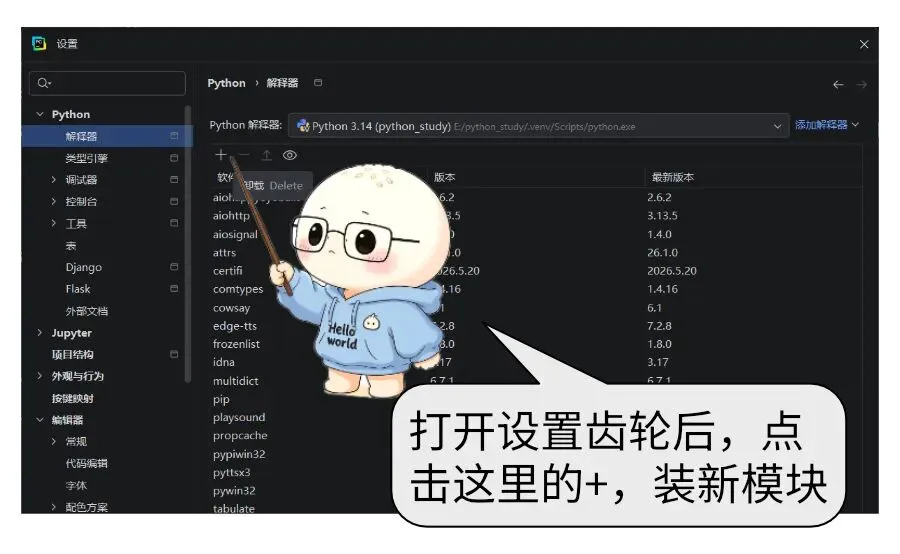
用最精彩的案例,用最简单的语句,带你玩转python高级编程。不用背语法,不用啃算法,快速抵达python甜点区。
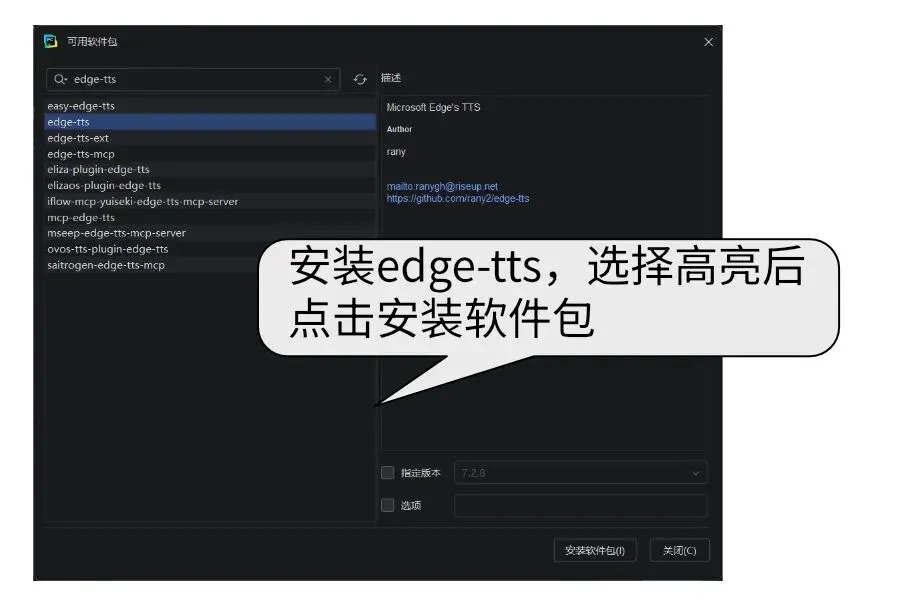
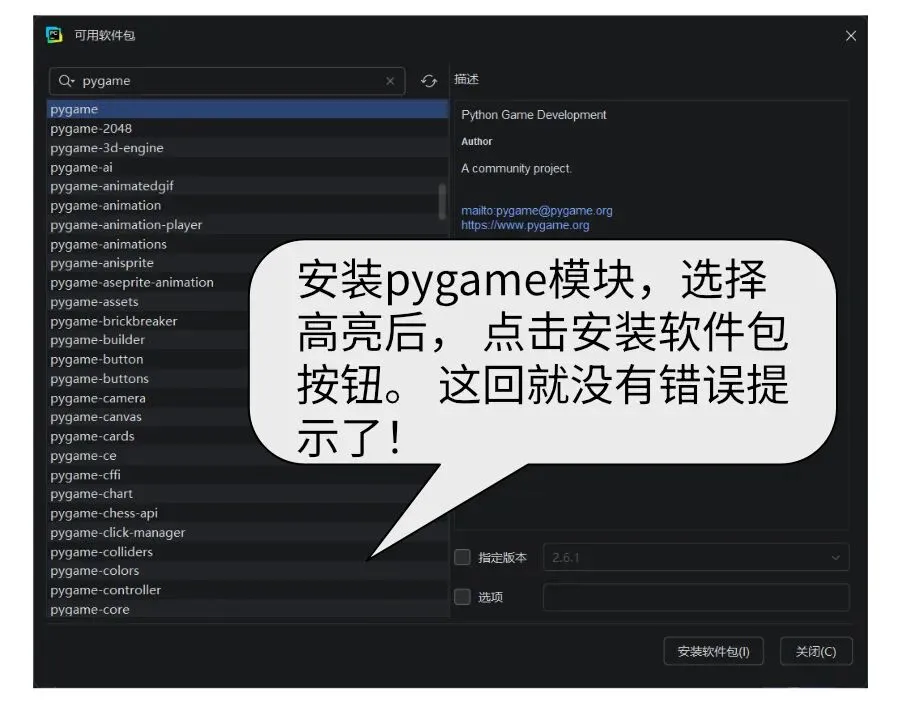
使用微软的Edge-tts实现多角色的文字转语音,为后面大语言模型交互做好语音准备。上一个案例使用了极简的playsound模块,但是这个模块并不够稳定,我们打算换成游戏引擎的pygame里面的播放功能。
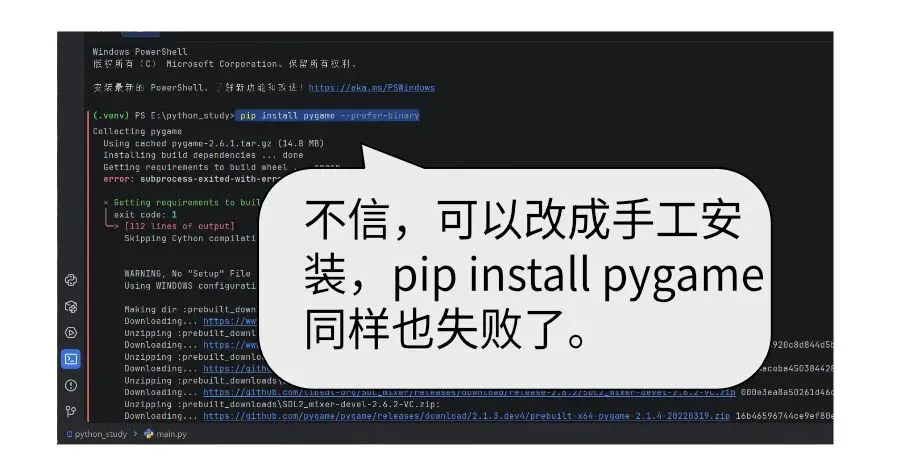
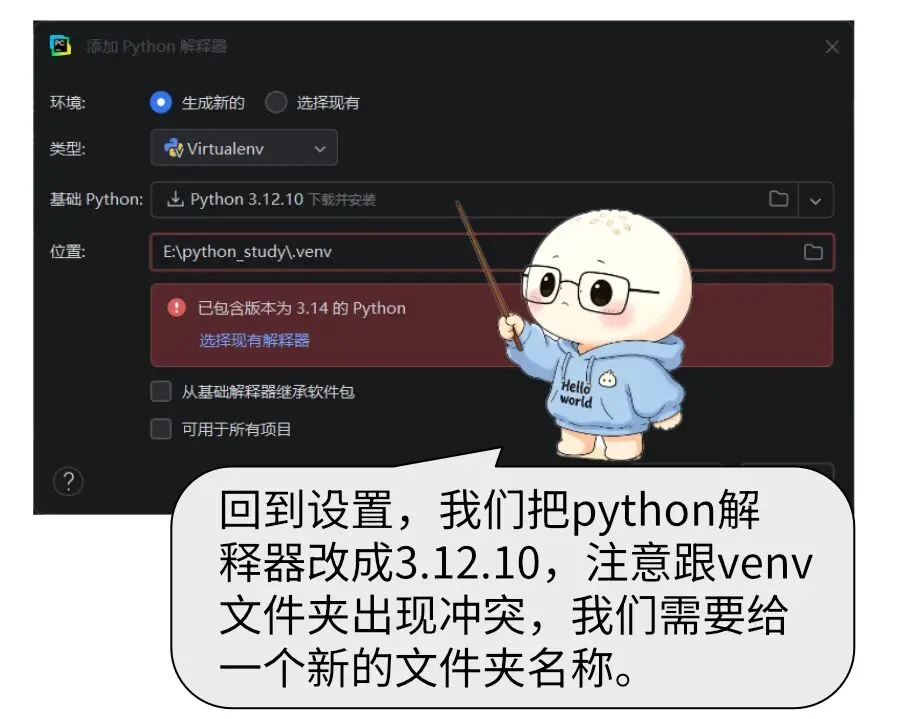
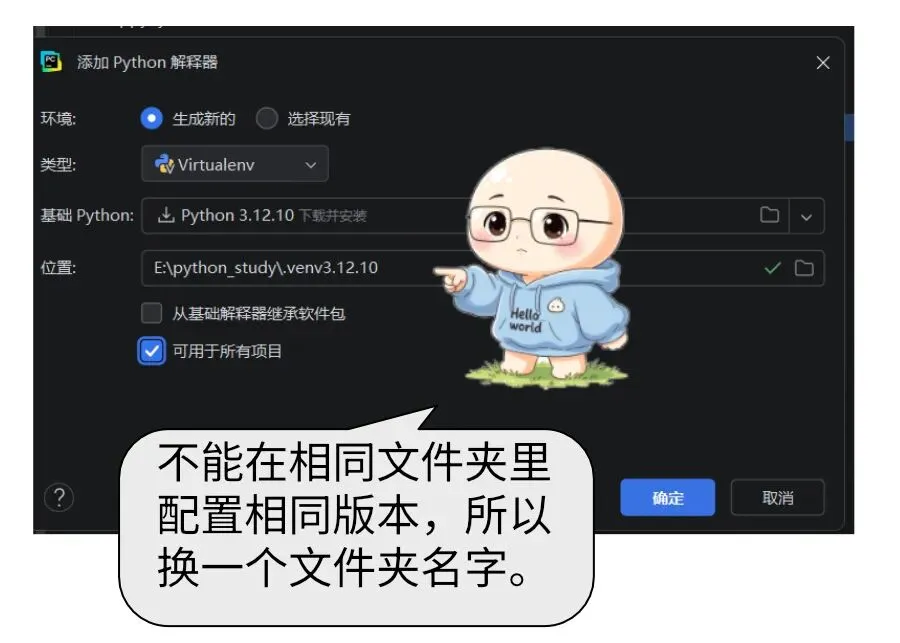
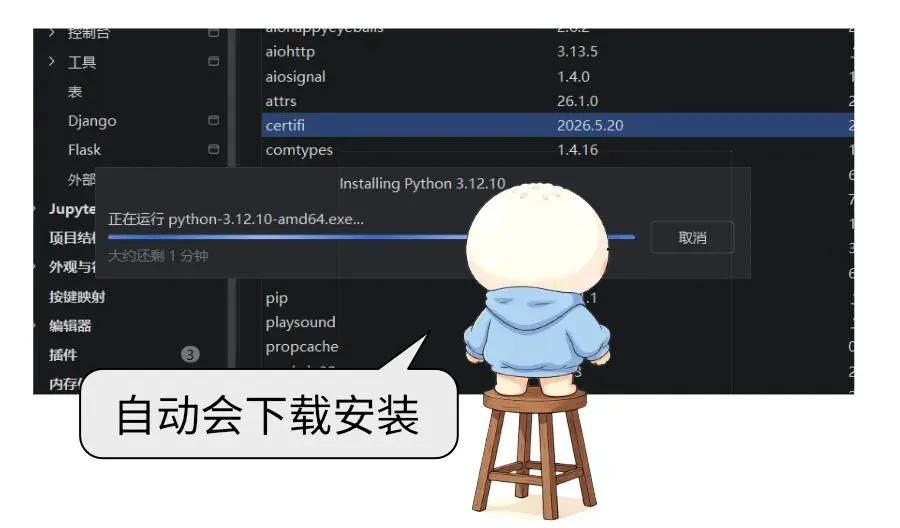
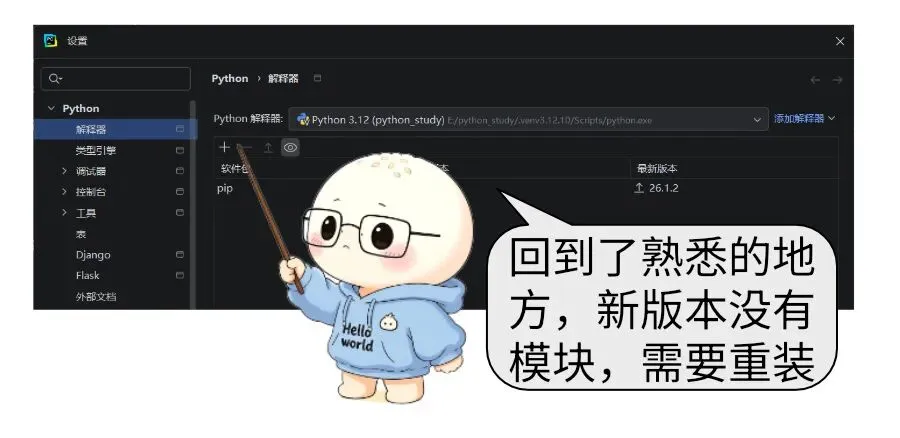
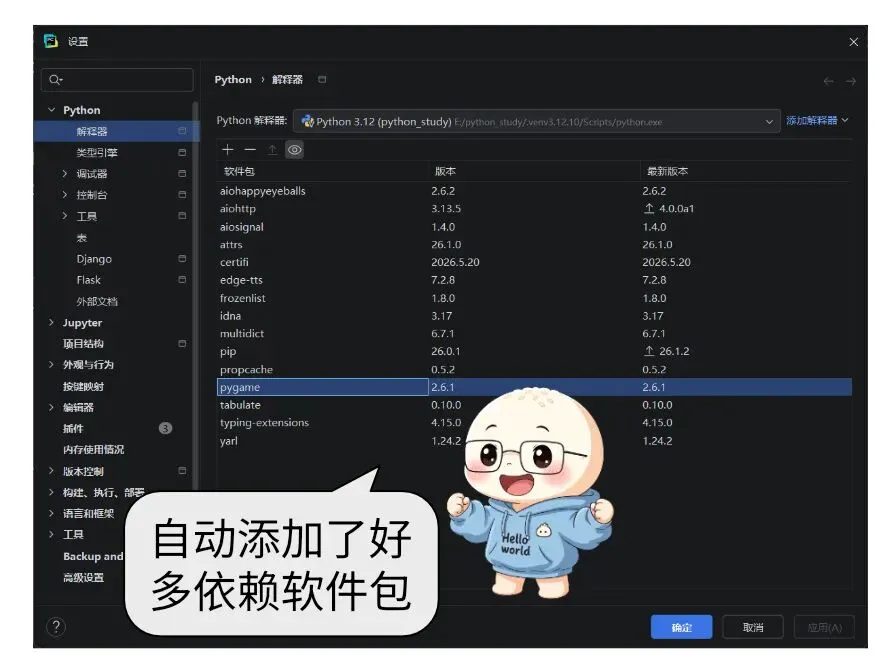
但是切换模块遇到了python非常典型的版本冲突bug,本文也成了理解python版本兼容性问题的最好案例。
Python 最闹心的就是版本兼容难题,不仅不同解释器版本语法不互通,各类第三方模块也时常因为版本不一出现报错。版本错乱、依赖冲突,一直是使用 Python 路上的主要阻碍。日常开发没必要跟风上新,挑选用户基数大、口碑扎实的成熟老版本,能大幅减少兼容故障。
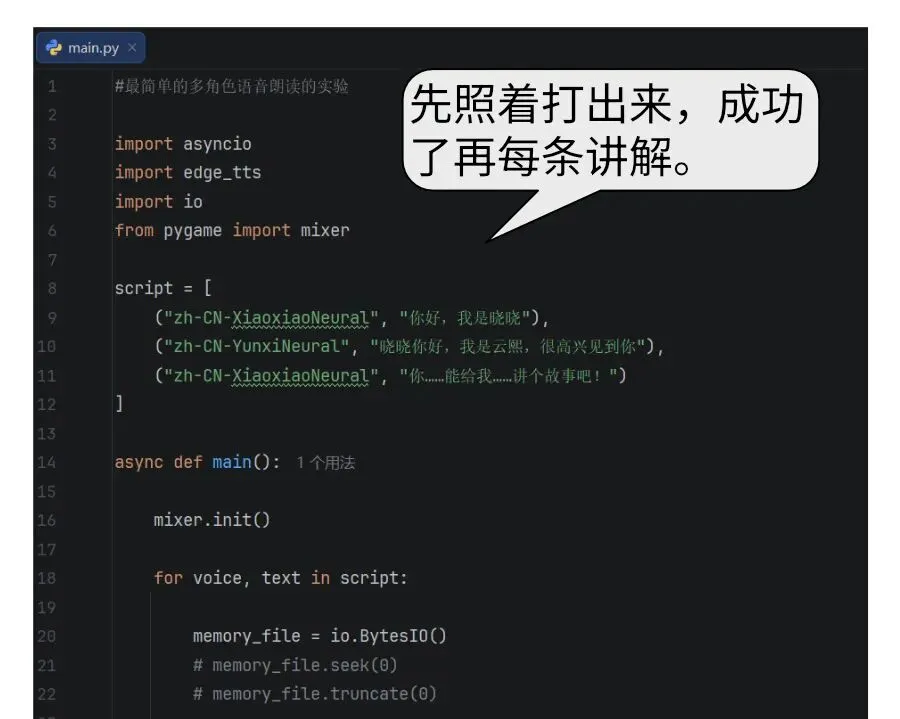
#多角色语音朗读的实验import asyncioimport edge_ttsimport iofrom pygame import mixerscript = [ ("zh-CN-XiaoxiaoNeural", "你好,我是晓晓"), ("zh-CN-YunxiNeural", "晓晓你好,我是云熙,很高兴见到你"), ("zh-CN-XiaoxiaoNeural", "你~~~能给我,讲个故事吗~?")]async def main(): mixer.init() for voice, text in script: memory_file = io.BytesIO() # memory_file.seek(0) # memory_file.truncate(0) communicate = edge_tts.Communicate(text, voice) async for chunk in communicate.stream(): if chunk["type"] == "audio": memory_file.write(chunk["data"]) memory_file.seek(0) print(f"正在播放……") mixer.music.load(memory_file) mixer.music.play() while mixer.music.get_busy(): await asyncio.sleep(0.1) mixer.music.unload()if __name__ == '__main__': asyncio.run(main())
下面我们逐句解释一下:
import asyncio
导入异步IO库,用于异步处理音频流和等待
import edge_tts
导入 edge_tts 库,调用微软在线语音合成服务
import io
导入内存字节流,用于把音频数据存到内存里,不写本地文件
from pygame import mixer
导入 pygame 的混音器模块,用于播放音频
script = [
("zh-CN-XiaoxiaoNeural", "你好,我是晓晓"),
("zh-CN-YunxiNeural", "晓晓你好,我是云熙,很高兴见到你"),
("zh-CN-XiaoxiaoNeural", "你~~~能给我,讲个故事吗~?")
]
定义了一个列表元组(其实就是只读序列,这个名字翻译的是在太草了)。所谓元组是python里面专属的只能只读的序列。我们用来保存每句话里,角色描述和讲话内容。然后把每句话都放到一个列表里面。列表定义用[]方括号。元组定义用圆括号,里面每个元素之间用逗号。
async def main():
因为edge_tts是异步模块,所以把调用函数定义成异步函数。async是指明异步函数的标识。
mixer.init()
pygame的使用需要初始化,因为这是一个很厉害的游戏引擎,我们仅仅使用其中的声音播放。
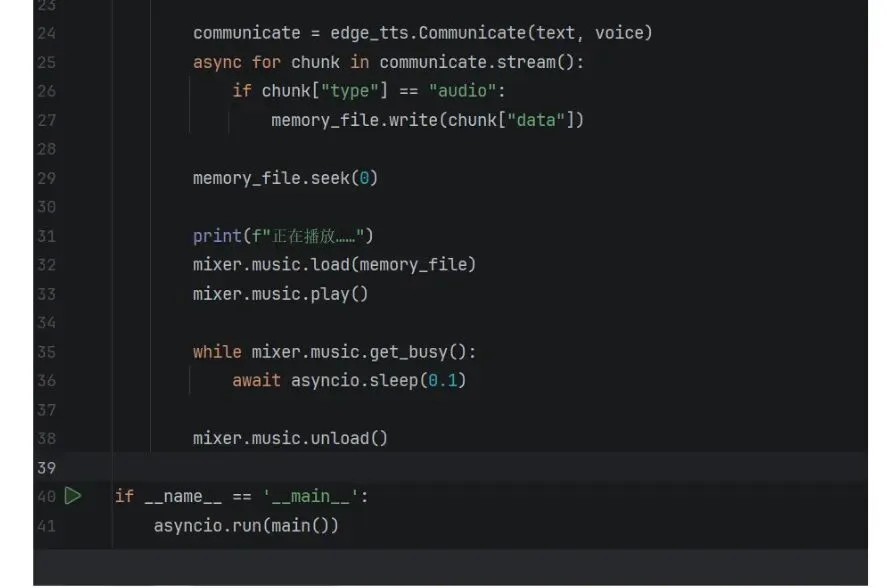
for voice, text in script:
对列表进行遍历循环,人话就是逐个读每一行,其中第一个元素放到voice里面,第二个元素放到text里面。
memory_file = io.BytesIO()
在内存里模拟一个文件出来,这样不会频繁读写硬盘提高程序的性能。我们上一个案例就是读写硬盘上的文件,对硬盘不太友好。
communicate = edge_tts.Communicate(text, voice)
拿到一个语音合成结果的对象放到communicate这里。我们把text文本和voice角色描述都发给edge_tts,他就会返回一个对象。
async for chunk in communicate.stream():
因为tts传来的是语音片段,所以我们用for循环,收集communicate里面的所有语音片段,放到chunk里面
if chunk["type"] == "audio":
因为chunk是一个字典类型的数据,他有好几种,有的是语音文件,有的是歌词。我们需要判断一下,当前chunk拿到的这个片段里面type类型是不是audio。
字典是python的一种数据类型,因为python里面没有结构体,我们通常用字典来代用其他语言的结构体。定义用{}.
注意python这几个高级数据结构定义都很有意思, 字典{}, 列表[], 元组()。
memory_file.write(chunk["data"])
把二进制文件写到内存模拟出来的文件里面
memory_file.seek(0)
把内存文件的指针移动到开头,就好像录音带在听歌时候,要先倒带,让磁带装到开头。
print(f"正在播放……")
打印,他的调试意义大于存在意义
mixer.music.load(memory_file)
调用mixer的加载音乐的功能,加载mp3文件
mixer.music.play()
加载好了就开始播放。
while mixer.music.get_busy():
await asyncio.sleep(0.1)
因为语音要讲一段时间,这里进行异步等待,等讲完了。才往后执行
mixer.music.unload()
播放完成后,释放资源,就好像老磁带机,放完歌曲,把磁带拿出来。
if name == 'main':
标记程序唯一的入口
asyncio.run(main())
异步函数的调用方法,只能用asyncio.run来调用。
今天我们遇到了python解释器和安装模块版本不兼容的问题。采用了对python解释器降级的方式解决的安装问题。经验是不管python还是模块都不要选择最新版,最好的办法是选择口碑最好的。如果你不确定哪个版本,那就看别人都选择什么。 使用内存文件来代替硬盘文件,减少了对硬盘高频读写的损伤。用更高级的游戏引擎pygame来替代功能不足的playsound模块。这样就可以在播放完后释放文件,从而进行下一轮的转换。 python和别的语言相比,强大之处,这几个结构里面的元素类型是没有限定的,你可以随意往一个列表里放各种类型的数据。 本文提供的案例,已经几乎是稳定的代码了,可以做实战使用了。但是跟商业项目级别的代码还有一些差距,比如tts网络连接失败的处理,播放异常的处理等。但是如果加足了这些辅助代码,就失去了当前案例清晰的美感,跟咱们初衷不符。所以保持每一段代码的干净美观是才是带领大家学习的原始动力。 我们后续会把这部分功能封装成一个函数,给以后大语言模型智能体提供讲话的能力。