目录
1.ps ajx命令是如何获取PID的
2.实验:编写代码,通过系统调用来获取PID
pid_t类型的本质
strace命令
3.PPID
父进程和子进程
PPID
结论
4.使用fork()创建子进程
测试代码1
测试代码2
5.回答与fork()有关的5个问题
6.简单理解fork()是怎么创建子进程的?
父子进程的代码段分析
父子进程的数据段分析
结论
7.使用vfork()创建子进程
vfork()与fork()的区别
8.总结:创建进程的两种方法
9.练习题
10.进程树、所有进程的祖先
使用pstree查看进程树
systemd进程是由谁创建的呢?
承接OS17.【Linux】进程基础知识(1)文章,继续讲解进程的基础知识
1.ps ajx命令是如何获取PID的
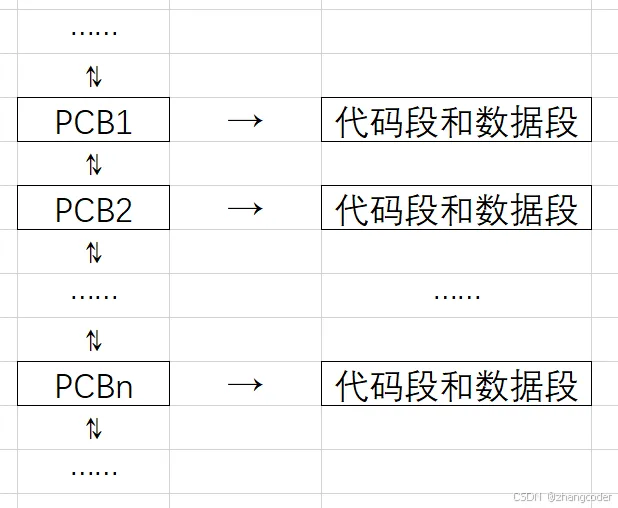
一般情况下,进程的PCB是通过双向链表连接起来的,PCB中含有指向该进程的代码段和数据段
的指针,如下图所示:
进程由操作系统管控,那么ps ajx只能通过系统调用接口来遍历这个双向链表,由于PCB中存储着进程的PID,那么ps ajx就能获取进程的各个信息,之后打印到显示器上
2.实验:编写代码,通过系统调用来获取PID
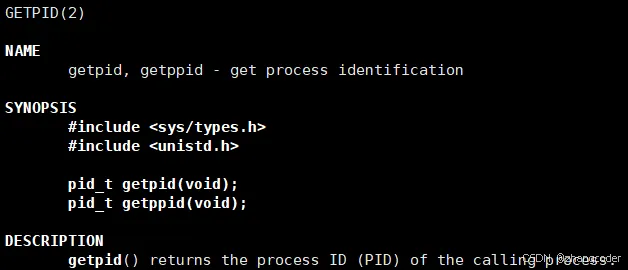
手册中对getpid()函数的描述:
(注:查系统调用一定要查2号手册)
作用:返回调用进程的PID
返回类型:pid_t
需要包含两个头文件: <sys/types.h>和<unistd.h>
pid_t类型的本质
有几种方法
1.GNU官网www.gnu.org Process-Identification对pid_t的解释
Data Type: pid_t
The pid_t data type is a signed integer type(有符号整型) which is capable of representing a process ID. In the GNU C Library, this is an int.
2.也可以使用C++的typeid来打印pid_t的类型
#include<iostream>#include<typeinfo>#include<sys/types.h>using namespace std; intmain(){pid_t id; cout << "Type of pid_t: " << typeid(id).name() << endl; return 0;}
运行结果:
3.使用man命令
(7号手册内容是系统数据类型)
也提到了是int类型
4.其实pid_t也是被重定义的
阅读linux内核源代码,/usr/include/sys/type.h下有说明:
#ifndef __pid_t_definedtypedef __pid_t pid_t;# define __pid_t_defined#endif
结论: 可以用%d打印pid_t类型
#include<stdio.h>#include<sys/types.h>#include<unistd.h>intmain(){ printf("The process's PID is %d",getpid()); getchar();//防止进程退出 return 0;}
运行结果:
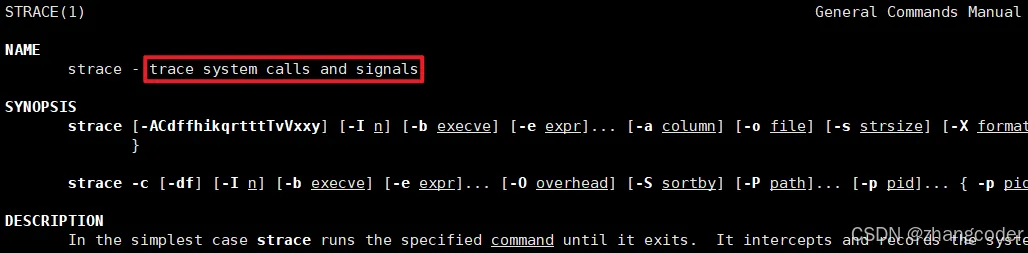
strace命令
作用:跟踪系统调用和信号
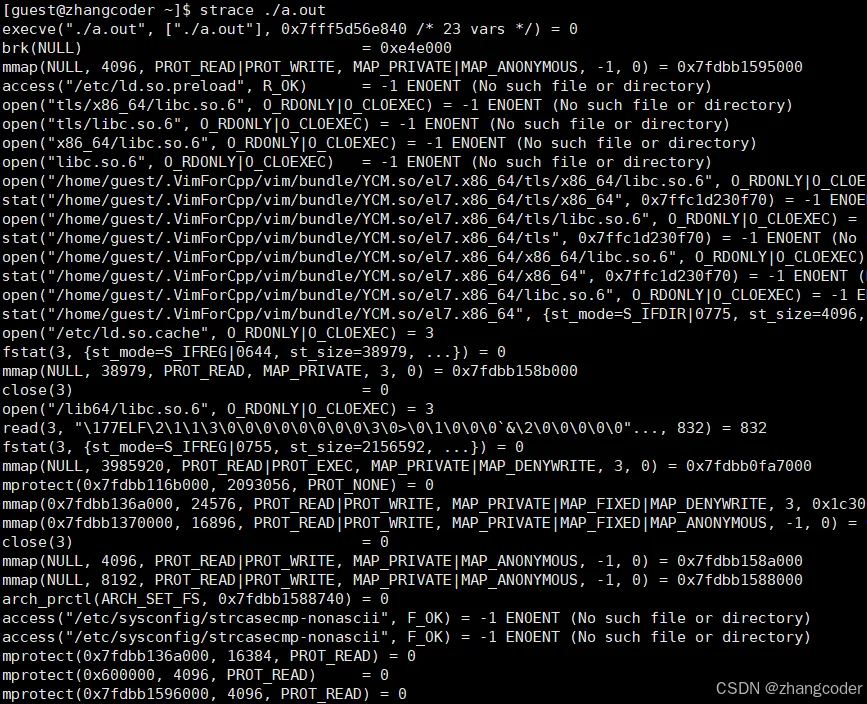
例如查看上方代码生成的可执行程序的系统调用:
往下翻可以看到getpid()
3.PPID
父进程和子进程
从名称上来看,父进程创建子进程,所以父子进程是相对的
PPID
PPID的全称是Parent Process ID,即父进程的PID
可以使用getppid()函数来获取PPID:
作用:返回调用进程的父进程的PID
返回类型:pid_t
需要包含两个头文件: <sys/types.h>和<unistd.h>
#include<stdio.h>#include<sys/types.h>#include<unistd.h>intmain(){ printf("The process's PID is %d,PPID is %d\n",getpid(),getppid()); return 0;}
运行结果:
第一次运行:
第二次运行:
第三次运行:
发现:PID一直在变,但PPID没有变
查看PID为23811是哪个进程:
为bash命令行解释器进程,是合情合理的,因为bash作为父进程,通过./a.out来创建子进程
如果重新连一下服务器,再查bash进程的PID:
ps ajx | head -1 && ps ajx | grep "bash"
会发现PID变了
结论
1.bash作为父进程,通过./a.out来创建子进程
2.连接远程服务器会创建bash进程
4.使用fork()创建子进程
查下手册中对fork()的描述:
作用:
fork() creates a new process by duplicating(复制) the calling process. The new process is referred to as the child process. The calling process is referred to as the parent process.
通过复制调用的进程来创建新进程,新进程指的是子进程,调用的进程指的是父进程
返回类型:pid_t
需要包含两个头文件: <sys/types.h>和<unistd.h>
返回值:On success, the PID of the child process is returned in the parent, and 0 is returned in the child. On failure, -1 is returned in the parent, no child process is created, and errno is set appropriately.
会发现fork()如果成功创建子进程,会返回两个返回值,父进程得到的返回值是子进程的PID,子进程的得到的返回值是0,这和以前C语言中将的函数的返回值只有一个是不一样的
fork()如果无法创建子进程,父进程得到的返回值是-1,errno 会被设置为相应的错误码
测试代码1
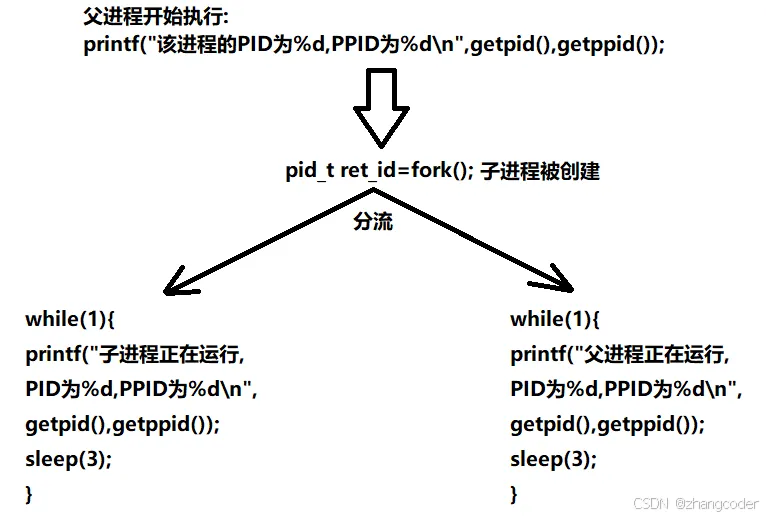
既然说fork()如果成功创建子进程,会返回两个返回值,那就根据这个特点写一个父子进程分流的代码:
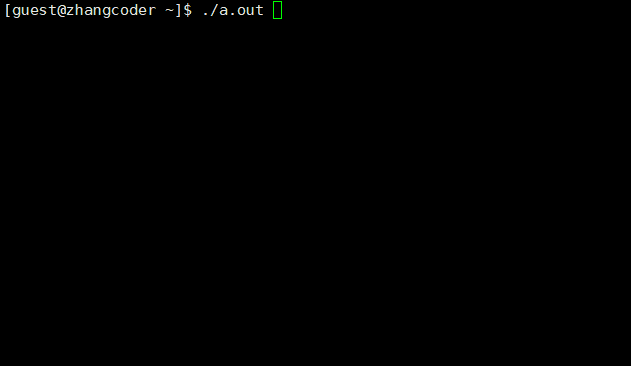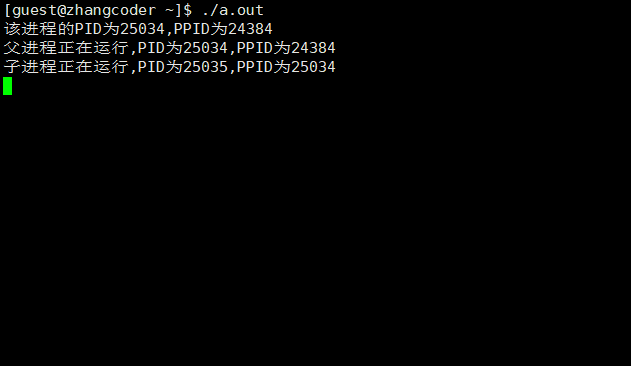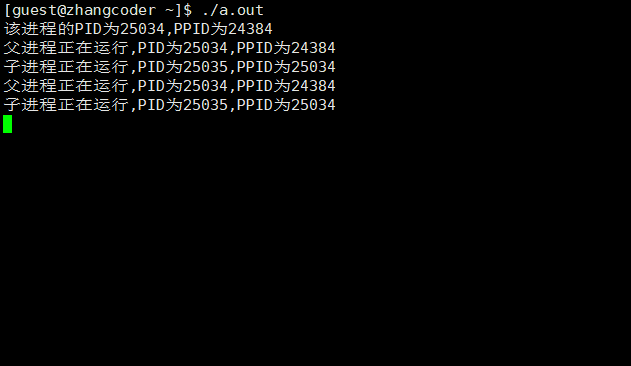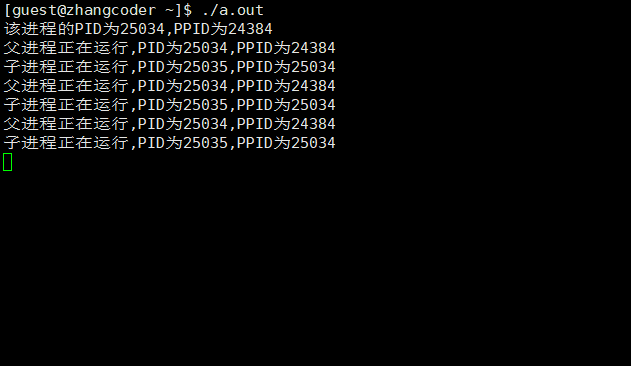
#include <stdio.h>#include <sys/types.h>#include <unistd.h>int main(){printf("该进程的PID为%d,PPID为%d\n",getpid(),getppid()); pid_t ret_id=fork();if (ret_id==0) {while(1) {printf("子进程正在运行,PID为%d,PPID为%d\n",getpid(),getppid()); sleep(3); } } else if (ret_id>0) {while(1) {printf("父进程正在运行,PID为%d,PPID为%d\n",getpid(),getppid()); sleep(3); } }else {printf("error!"); }return 0;}
运行结果:
会发现两个死循环都在运行,显然分为两个执行流
分析两个执行流:
1.父进程的PID是子进程的PPID
2.执行流程
父子进程会分流
3.父子进程的执行顺序
父子进程执行顺序是随机的,由进程调度所决定的
测试代码2
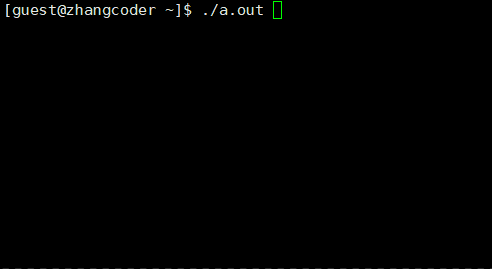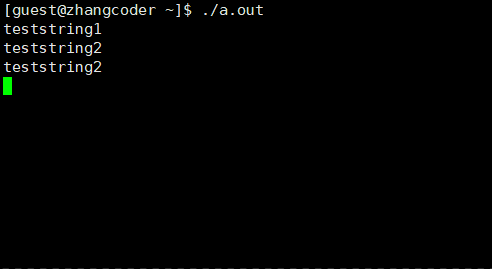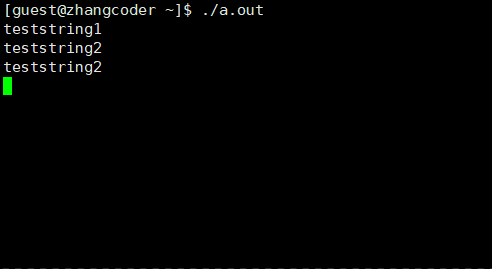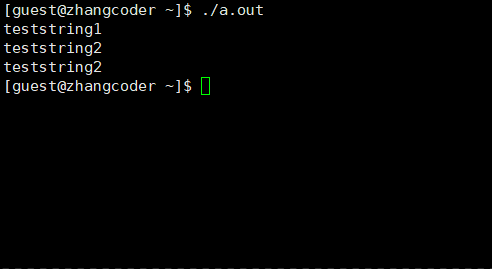
#include<stdio.h>#include<sys/types.h>#include<unistd.h>intmain(){ printf("teststring1\n"); fork(); printf("teststring2\n"); sleep(3);}
运行结果:
现象:
1.teststring1打印了一次,但teststring2打印了两次
2.打印teststring1一次,teststring2两次后停顿3s后退出
分析:
根据测试代码1提到的分流原则,有:父进程从printf("teststring1\n")执行,子进程从fork()后的printf("teststring2\n")开始执行,最后父子进程都sleep(3),近似同时退出(发现父子进程的代码是共享的这个后面会再次提到)
5.回答与fork()有关的5个问题
1.为什么fork()成功创建子进程后,要给父子进程返回不同的值?
内核开发者设计创建子进程函数的目的:让子进程执行和父进程不同的代码,可以根据父子进程的得到访返回值的不同,采用if-else分流父子进程
2.fork()成功创建子进程后为什么要给父进程返回子进程的PID?
一个父进程可以有多个子进程,由于每个进程的PID是独一无二的,因此fork()给父进程返回子进程的PID是为了区分不同的子进程
反过来,一个子进程只能有一个父进程
3.fork()成功创建子进程后为什么要给子进程返回0?
一个子进程只会有一个父进程,PID==0总是由内核交换进程使用,所以一个子进程的PID不可能为0
4.fork()是如何做到返回两次值的?
一般而言父子进程的代码是共享的,那么父子进程各执行一次fork()里面的return,因此return两次
而且代码段是不能被修改的,具体的原因和保护模式有关,这里不介绍
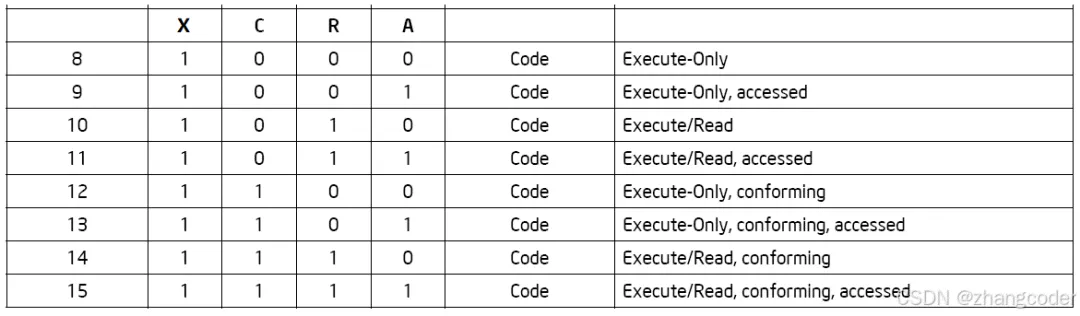
而且保护模式下的代码段只定义了这三个属性:accessed (访问,A), read enable (可读,R), and conforming (一致,C).
(来自Intel® 64 and IA-32 Architectures Software Developers Manual, Volume 3A: System Programming Guide, Part 1)
而且在保护模式下操作系统对内存是分段管理的,每个段的属性存储在段描述符中,Intel手册中给出了详细内容:
代码段不可修改也和DPL(Descriptor Privilege Level)有关,其控制对段的访问
5.对于pid_t ret_id=fork(),变量ret_id为什么会有两个不同的值?
暂且不回答,在进程地址空间会提到原因
6.简单理解fork()是怎么创建子进程的?
会议进程的组成,对于子进程,有以下公式:
子进程=子进程的PCB+子进程的代码段和数据段
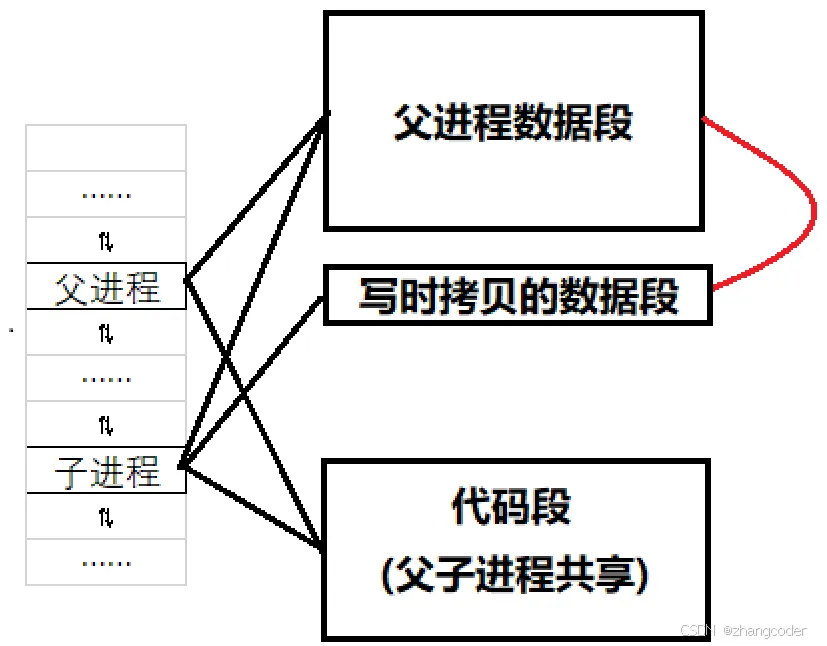
父子进程的代码段分析
因此fork()创建子进程会创建子进程的task_struct,并向task_struct写入数据
上面提到了,父子进程的代码段是共享的,因此子进程的task_struct的执行代码段的指针指向父进程的代码段
这样父子进程都有独立(即隔离)的task_struct,可以被CPU调度执行了
注:任何平台的进程之间都是独立的,具体和保护模式有关
父子进程的数据段分析
数据段可读可写,一开始(子进程刚刚创建时),父子进程的数据段是共享的,当子进程需要修改数据段中的内容时会发生写时拷贝(在文章CD40.【C++ Dev】string类的模拟实现(4)(operator=、拷贝构造函数的现代写法、写时拷贝的简单了解)提到过),操作系统会拷贝那一部分数据供子进程修改,保证父进程的数据不受影响
例如子进程的pid_t肯定要写时拷贝
注意:没有必要将父进程数据段的所有内容拷贝一份给子进程,因为这子进程可能只会使用一部分数据,导致内存资源被浪费
结论
结论: 用fork()创建子进程时,父子进程共用同一份代码,数据以写时拷贝的方式各自私有
7.使用vfork()创建子进程
作用: 创建子进程并阻塞(block)父进程
使用前包含<unistd.h>头文件
vfork()与fork()的区别
1.vfork直接使用父进程存储空间,不用拷贝
2.vfork保证子进程先运行,当子进程调用exit退出后,父进程才执行(之前父进程被阻塞了)
8.总结:创建进程的两种方法
方法1.通过bash执行可执行文件(指令级别),其实bash也是通过fork()来创建子进程的
方法2.使用fork()或vfork()创建子进程(代码级别)
9.练习题
不算main 这个进程自身,到底创建了多少个进程?
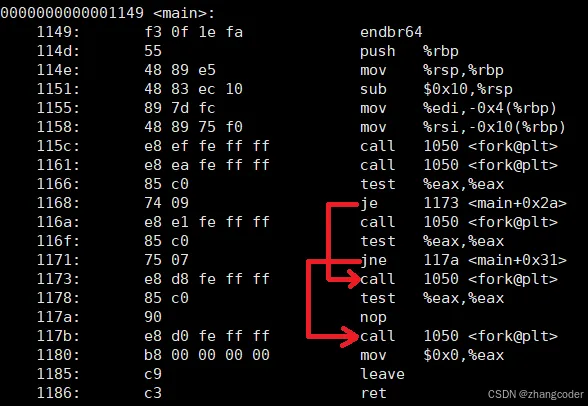
int main(int argc, char* argv[]){ fork(); fork() && fork() || fork(); fork();}
分析:
注意&&和||短路运算的特点,如果记不得的话可以反汇编ELF文件看看编译器是怎么处理的:
test %eax,%eax是检查fork()的返回值是否为0,如果为0,则设置标志位ZF=1,如果不为0,则设置标志位ZF=0
test指令内部逻辑:
Intel开发手册是这样说明的:
| Opcode | Instruction | Op/ En | 64-Bit Mode | Compat/ Leg Mode | Description |
| | | | | AND r32 with r/m32; set SF, ZF, PF according to result. |
那么test %eax,%eax会将eax寄存器的值和自己进行与运算,计算的结果用于设置ZF,不修改eax寄存器的值
答案是19
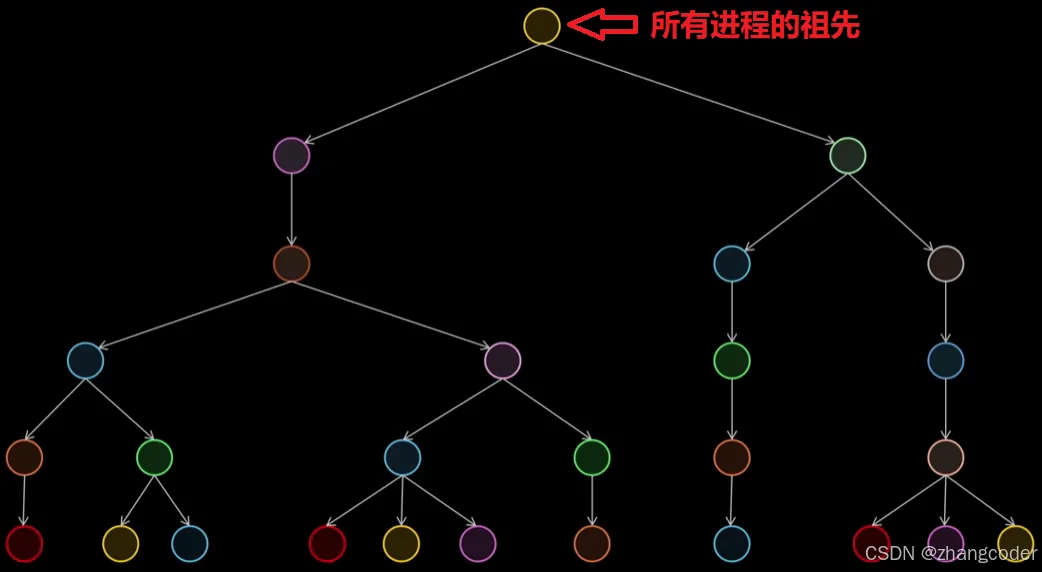
10.进程树、所有进程的祖先
使用pstree查看进程树
上面说到了: 子进程是由父进程创建而来的
那么可以自然得出父进程是由父父进程创建而来的,父父进程是由父父父进程创建而来的......
按照上面这样思考,向上逆推可以得出系统中所有进程的组织方式,那么就可以理出一个进程树:
注: 进程树的图来自The Question Nobody Ever Explains: Where Does the Kernel End? - YouTube,中文翻译见无人解答的问题:内核的终点在哪里?- Bilibili
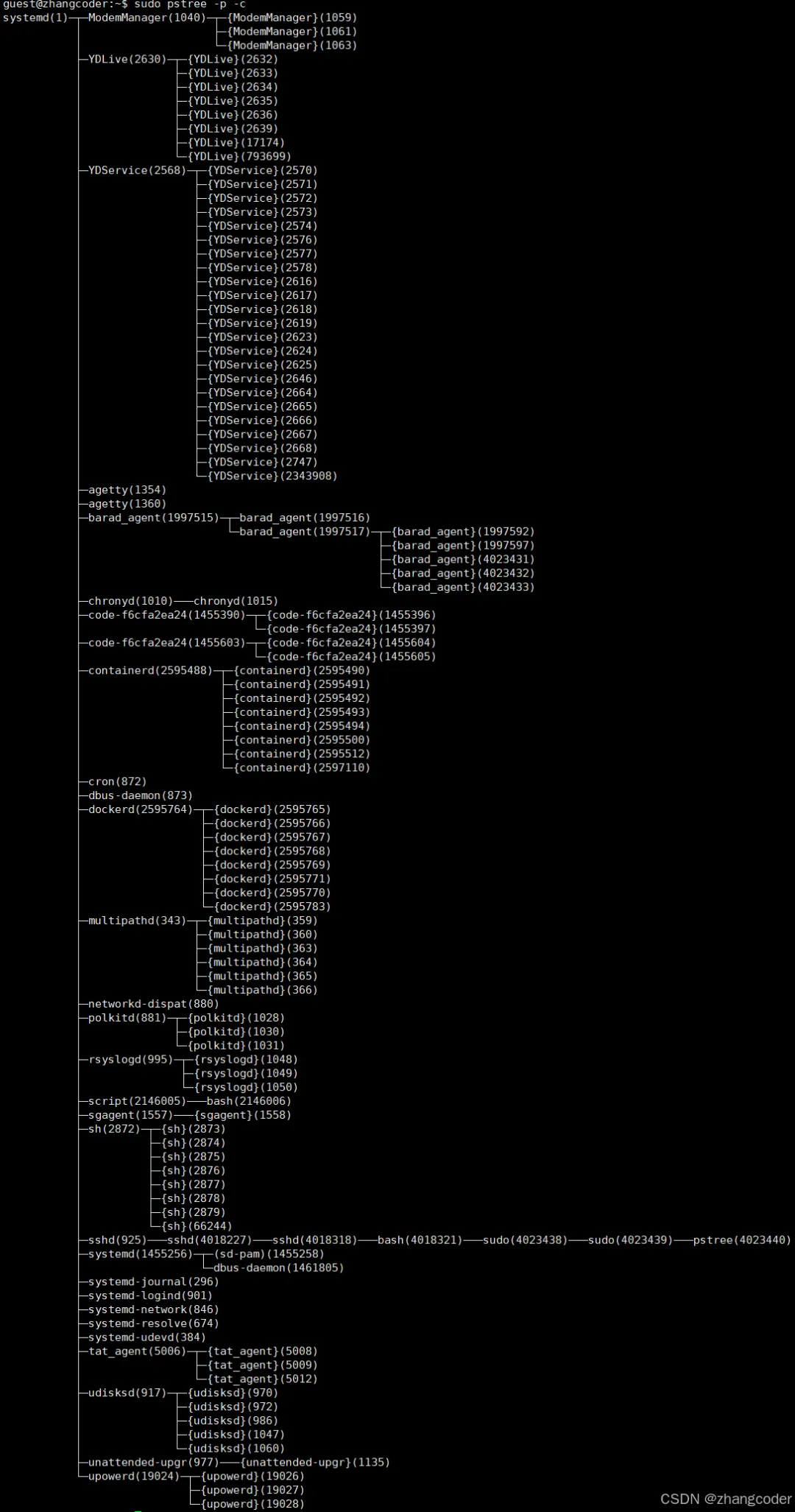
在linux上可以通过以下命令看这个进程树:
sudo pstree -p -c #使用-p显示 PID,使用-c关闭合并,这样可以更细致地查看进程与线程
运行结果:
{ }中的是线程,( )中的是进程PID或者线程TID
可以看到,在Linux上,所有进程的祖先是PID=1的systemd进程,或者称为init进程
结论: PID=1的进程就是init进程,也就是systemd进程,而且这个进程处于用户空间,不是内核空间
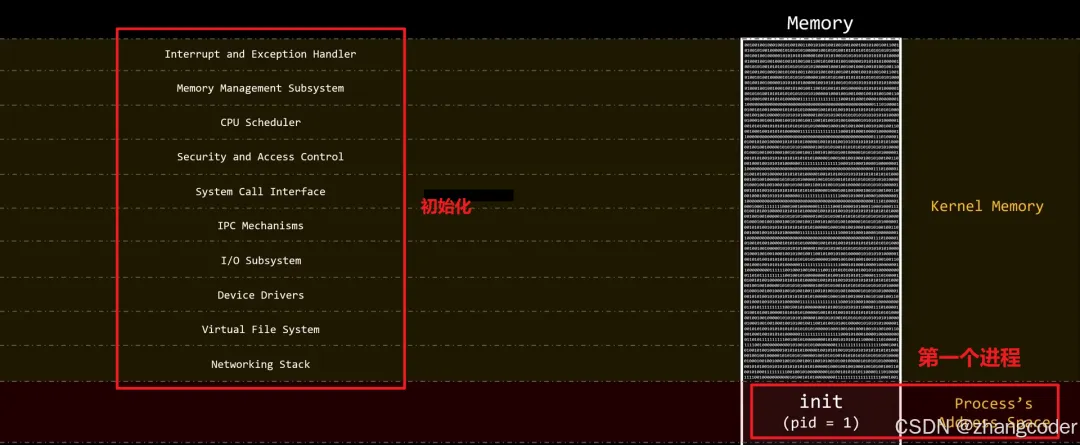
systemd进程是由谁创建的呢?
由内核创建,内核完成初始化后,会创建系统中的第一个进程,也就是systemd进程
内核通过位于/init/main.c的kernel_init函数来创建PID=1的用户进程,在这个函数的最后执行的是:
if (!try_to_run_init_process("/sbin/init") || !try_to_run_init_process("/etc/init") || !try_to_run_init_process("/bin/init") || !try_to_run_init_process("/bin/sh")) return 0;
try_to_run_init_process也定义在/init/main.c中,其内部调用run_init_process函数:
staticinttry_to_run_init_process(constchar *init_filename){int ret; ret = run_init_process(init_filename);if (ret && ret != -ENOENT) { pr_err("Starting init: %s exists but couldn't execute it (error %d)\n", init_filename, ret); }return ret;}
run_init_process也定义在/init/main.c中,其内部调用kernel_execve函数:
staticintrun_init_process(constchar *init_filename){const char *const *p; argv_init[0] = init_filename; pr_info("Run %s as init process\n", init_filename); pr_debug(" with arguments:\n");for (p = argv_init; *p; p++) pr_debug(" %s\n", *p); pr_debug(" with environment:\n");for (p = envp_init; *p; p++) pr_debug(" %s\n", *p);return kernel_execve(init_filename, argv_init, envp_init);}
★调用链: kernel_init() → try_to_run_init_process() → run_init_process() → kernel_execve()
注意: kernel_execve()不同于后面OS26.【Linux】进程等待 (下) 和 进程程序替换(上)文章和OS27.【Linux】进程程序替换(下)文章讲的execve系统调用,kernel_execve()是在内核态下执行的,和用户态下进程可以使用的系统调用不一样
原文首发于CSDN,点击阅读全文即可查看













 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
