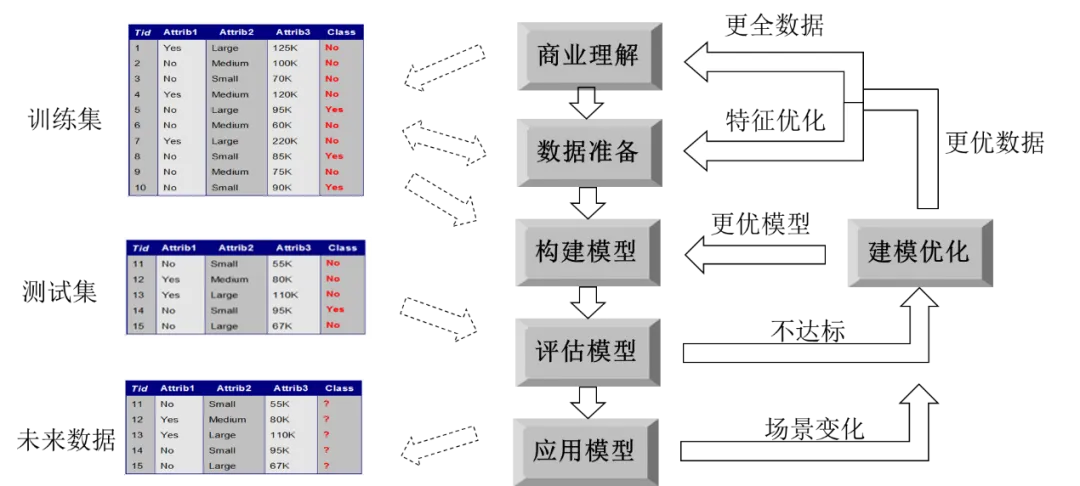
第一部分:模型超参优化
1、 模型优化的三大方向
2、 模型超参优化原理
3、 超参优化通用方法
Ø网格搜索GridSearchCV(更具通用性)
Ø随机搜索RandomizedSearchCV
Ø贝叶斯超参优化BayesSearchCV
Ø超参搜索空间的表示方式
4、 模型优化
Ø优化模型:选择新模型/修改模型
Ø优化数据:新增显著自变量
Ø优化公式:采用新的计算公式
第二部分:模型集成优化
1、 模型集成思想
2、 模型集成的关键问题
Ø如何得到基类模型
Ø如何选择结合策略
3、 Bagging集成基本原理
Ø有放回抽样
Ø加权投票
4、 随机森林RandomForest
5、 Boosting集成基本原理
Ø基于错分样本的基类模型
Ø预测概率加权求和
6、 Boosting典型模型
ØAdaboost
ØGBDT梯度提升树
ØXGBoost大赛利器
ØXGBoost原理、早期停止、自定义损失函数
7、 Stacking集成基本原理
ØXGBoost+SVM
第三部分:特征工程优化
1、 为什么要做特征工程
2、 特征工程内容
Ø异常数据处理
Ø变量变换
Ø变量派生
Ø类型转换
Ø特征选择
Ø因子合并
3、 缺失值对模型的影响
Ø缺失值填充方式:固定值填充、两点插值法、拉格朗日插值、。。。
Ø不同填充方式对模型效果的影响
案例:泰坦尼克号沉船幸存者预测
4、 预测离群值的识别与处理
5、 样本均衡的5种方式
6、 特征选择的:选择重要变量,剔除不重要变量
ØFilter/Wrapper/Embedded
7、 基于变量本身的重要性筛选
Ø缺失值所占比例过大
Ø标准差/变异系数过小(VarianceThreshold)
Ø类别值比值失衡严重
Ø类别值与样本量比例过大
8、 Filter式(特征选择与模型分离)
Ø常用评估指标(相关系数/显著性/互信息等)
Øf_regression,f_classif,chi2,
Ømutual_info_regression,mutual_info_classif
案例:客户流失预测的特征选择
9、 Wrapper式(利用模型结果进行特征选择)
ØSklearn实现(RFE/RFECV-Recursive Feature Elimination)
10、 Embedded式(模型自带特征选择功能)
ØL1正则项(Lasso/ElasticNet)
Ø信息增益(决策树)
ØSklearn实现(SelectFromModel)
11、 因子合并
Ø因子分析原理及思想(FactorAnalysis)
Ø载荷矩阵相关概念(变量共同度/方差贡献率)
Ø如何确定降维的因子个数
Ø主成份分析(Principal Component Analysis)原理
ØPCA的几何意义
案例:汽车油效预测
12、 变量变换
Ø为何需要变量变换
Ø函数转换:中心化、对数变换、平方根变换…
Ø标准化转换:min-max、mean、max absolution、Z-score…
Ø正则化转换:将数据缩放到单位范式(L1/L2变换)
Ø正态化转换:将变量转换成正态分布(Box-Cox、Yeo-Johnson)
Ø因变量变换对模型质量的影响
案例:波士顿房价预测
13、 特征标准化
Ø标准化的作用: 缩小,消除/统一量纲
Ø常用标准化方法:MinMaxScaler, StandardScaler,…
Ø不同模型对标准化的要求
Ø不同标准化对模型的影响
案例:医院肿瘤预测
14、 其它变换:正态化、正则化
15、 变量派生:多项式等
第四部分:管道技术实现
1、 管道实现的价值
2、 常用管道实现类
3、 管道类Pipeline
4、 列转换类ColumnTransformer
5、 特征合并类FeatureUnion
第五部分:XGBoost模型详解及优化
1、 基本参数配置
Ø框架基本参数: n_estimators, objective
Ø性能相关参数: learning_rate
Ø模型复杂度参数:max_depth,min_child_weight,gamma
Ø生长策略参数: grow_policy, tree_method, max_bin
Ø随机性参数:subsample,colsample_bytree
Ø正则项参数:reg_alpha,reg_lambda
Ø样本不均衡参数: scale_pos_weight
2、 早期停止与基类个数优化(n_estimators、early_stopping_rounds)
3、 样本不平衡处理
Ø欠抽样与过抽样
scale_pos_weight=
neg_num/pos_num
4、 XGBoost模型欠拟合优化措施
Ø增维,派生新特征
a) 非线性检验
b) 相互作用检验
Ø降噪,剔除噪声数据
a) 剔除不显著影响因素
b) 剔除预测离群值(仅回归)
c) 多重共线性检验(仅回归)
Ø变量变换
a) 自变量标准化
b) 残差项检验与因变量变换
Ø增加树的深度与复杂度
a) 增大max_depth
b) 减小min_child_weight, gamma等
Ø禁止正则项生效
5、 特征重要性评估与自动特征选择
6、 超参优化策略:
Ø分组调参:参数分组分别调优
Ø分层调参:先粗调再细调
7、 XGBoost模型过拟合优化措施
Ø降维,减少特征数量
Ø限制树的深度和复杂度
a) 减小max_depth
b) 增大min_child_weight,gamma等
Ø采用dart模型来控制过拟合(引入dropout技术)
Ø启用正则项惩罚:reg_alpha,reg_lambda等
Ø启用随机采样:subsample,colsample_bytree等
8、 Stacking模式:XGBoost+LR、XGBoost+RF等
9、 XGBoost的优化模型:LightGBM
第六部分:实战训练篇
1、 互联网广告判断模型
2、 客户流失预测模型
3、 直销响应模型
结束:课程总结与问题答疑。