OpenAI Python SDK 实战:responses.create 和 responses.parse 到底怎么选?🤖
最近使用 OpenAI Python SDK,很多同学都会遇到一个问题。
以前我们熟悉的是:
client.chat.completions.create(...)
现在文档和示例里,越来越多地方开始出现:
client.responses.create(...)
然后又冒出来一个:
client.responses.parse(...)
再加上消息里的角色,也不只是 system / user / assistant了。
现在还经常看到:
{"role": "developer", "content": "..."}
第一次看到的时候,脑子大概是这样的:
又改接口了?
create 和 parse 到底差在哪?
developer 又是啥?
我项目里到底该用哪个?😭
今天这篇,就从实战角度讲清楚。
不绕弯子。
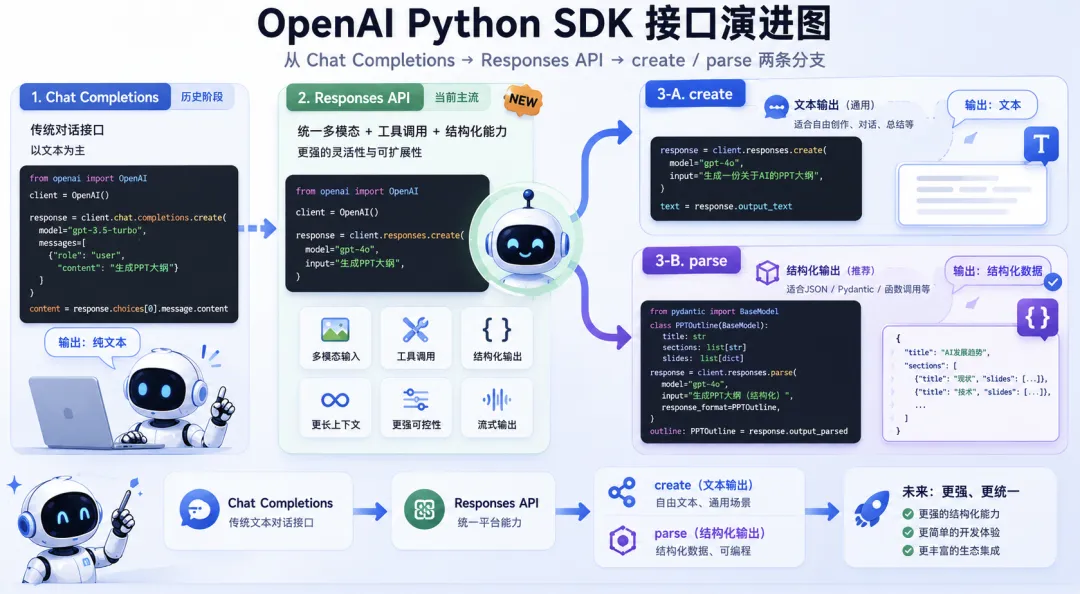
一、为什么会有 Responses API?
先说结论:
Responses API 是 OpenAI 新一代统一生成接口。
以前的 Chat Completions 更像“聊天接口”。
输入是 messages。
输出是 choices。
取结果要这样写:
result = response.choices[0].message.content
能用。
但写多了你会发现:
这套接口比较偏“对话”。
而现在的 AI 应用,不只是聊天。
它还要:
所以 Responses API 的思路更像:
统一入口。
不管你是普通问答、工具调用、多模态输入,还是结构化输出,都尽量往一个体系里收。
这对工程项目比较友好。
少一点历史包袱。
多一点统一抽象。
(SDK 终于开始像个“系统”了,不再像接口考古现场🐛)
二、先看 responses.create:普通生成就用它
responses.create()可以理解成最常用的生成接口。
适合:
如果你的结果主要是给人看的文本,大概率用它就够了。
示例 1:最简单的 create 用法
下面这段代码,用 Responses API 生成一段解释文本。
from openai import OpenAI
import os
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"), base_url=os.getenv("OPENAI_BASE_URL"))
response = client.responses.create(
model="gpt-5.5",
input="用通俗的话解释一下什么是 RAG,不要超过 100 字。"
)
print(response.output_text)
这里最舒服的是:
不用再写:
response.choices[0].message.content
对新项目来说,代码更干净。
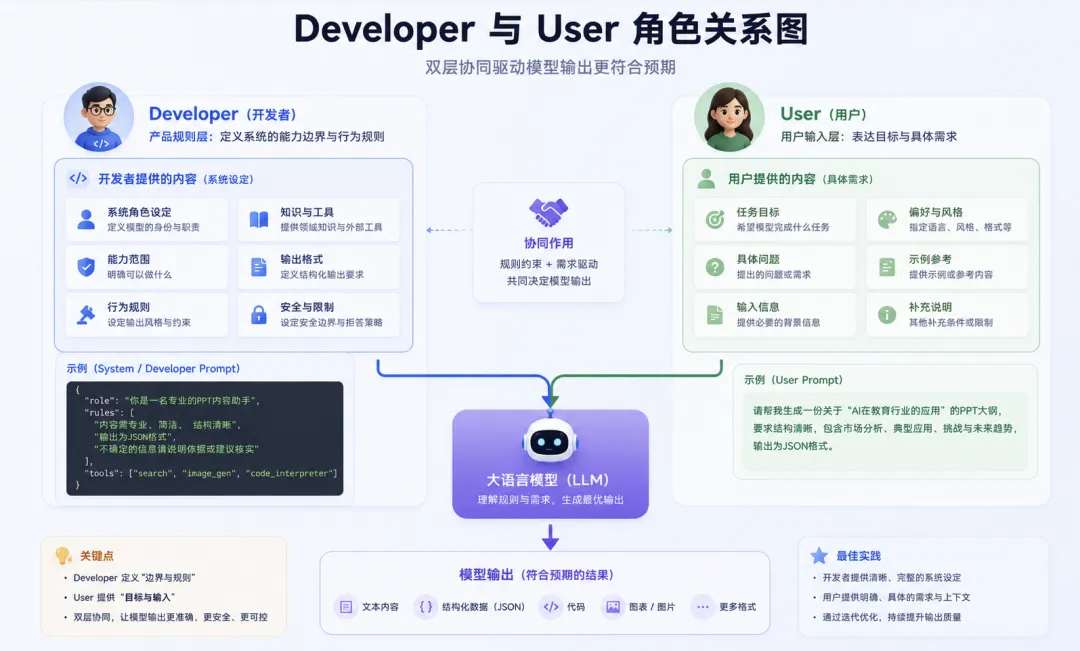
三、messages 里为什么出现 developer?
以前很多人习惯这样写:
messages = [
{"role": "system", "content": "你是一个严谨的技术助手。"},
{"role": "user", "content": "解释一下 RAG。"}
]
现在在 Responses API 里,你也可以看到:
input=[
{
"role": "developer",
"content": "你是一个严谨的技术助手,回答要简洁,避免编造。"
},
{
"role": "user",
"content": "解释一下 RAG。"
}
]
那 developer是什么?
简单理解:
developer 是开发者给模型的应用级指令。
它通常用来放:
比如:
input=[
{
"role": "developer",
"content": "你是一个技术文档助手。回答必须准确、简洁,不要输出未经确认的 API 参数。"
},
{
"role": "user",
"content": "介绍 responses.create 的用法。"
}
]
这样写的好处是:
把“应用规则”和“用户问题”分开。
用户问什么,是 user。
你的产品要求模型怎么答,是 developer。
这对工程项目很重要。
四、developer 和 system 怎么理解?
很多人会问:
那 developer和 system到底怎么选?
实战里可以这样理解:
system
更像底层系统级指令。
比如:
developer
更像应用开发者指令。
比如:
在实际项目里,我更建议:
业务应用规则优先放 developer。
比如你做一个合同审核助手:
input=[
{
"role": "developer",
"content": "你是合同审核助手。必须只基于用户提供的合同内容分析,不要编造法律条文。"
},
{
"role": "user",
"content": "帮我看看这段合同有什么风险:..."
}
]
这样结构更清楚。
不是所有规则都往 system里塞。
system像地基。
developer像产品说明书。
user像用户现场提问。
别混成一锅粥。
不然后期维护会想哭。😭
五、再看 responses.parse:结构化输出就用它
responses.parse()是这篇文章的重点。
一句话:
parse 适合让模型直接返回 Python 对象。
它通常配合 Pydantic 使用。
也就是说,你先定义好数据结构。
然后让模型按这个结构输出。
SDK 会帮你解析成对象。
这对工程项目非常香。
因为很多 AI 应用,最后不是要一段自然语言。
而是要结构化数据。
比如:
这些场景,如果只用 create(),你通常会让模型输出 JSON。
然后自己:
再处理异常。
再兜底。
再修格式。
再骂一句:怎么又少了个逗号。🐛
parse()就是为了减少这类痛苦。
六、示例 2:用 parse 提取结构化信息
下面我们写一个小例子。
假设用户输入一句话:
张三是一名后端工程师,主要做 Python 和 FastAPI,有 5 年经验。
我们希望模型直接解析成对象。
先定义 Pydantic 模型:
from pydantic import BaseModel
from openai import OpenAI
client = OpenAI()
class DeveloperProfile(BaseModel):
name: str
role: str
skills: list[str]
years_of_experience: int
然后调用 responses.parse():
response = client.responses.parse(
model="gpt-5.2",
input=[
{
"role": "developer",
"content": "你负责从文本中提取开发者信息。只提取文本中明确出现的信息。"
},
{
"role": "user",
"content": "张三是一名后端工程师,主要做 Python 和 FastAPI,有 5 年经验。"
}
],
text_format=DeveloperProfile,
)
profile = response.output_parsed
print(profile.name)
print(profile.role)
print(profile.skills)
print(profile.years_of_experience)
你拿到的不是一段 JSON 字符串。
而是一个 Pydantic 对象。
类似:
DeveloperProfile(
name="张三",
role="后端工程师",
skills=["Python", "FastAPI"],
years_of_experience=5
)
这就是 parse()的价值。
模型输出,直接进入程序逻辑。
这里我注意,很多人使用的是国内中转API可能会导致程序失败。这是由于第三方中转站的原因。
这里我推荐使用我们自己的 开发喵API中转服务,真实、有效。
七、create 和 parse 的核心区别
直接看表。
记住一句话:
create 输出文本。parse 输出对象。
再说得更工程一点:
create 适合内容生成,parse 适合数据生成。
八、什么时候用 create?
如果你最终要展示给用户看,优先用 create()。
比如:
1. 聊天机器人
用户问:
“帮我解释一下什么是 MCP。”
你输出一段自然语言回答。
用 create()。
2. RAG 问答
用户问:
“根据知识库,解释一下合同审核流程。”
你检索文档后,让模型生成答案。
用 create()。
3. 公众号文案
比如:
“帮我写一个 AI PPT 技术方案的开头。”
这类内容创作,用 create()。
4. 代码解释
比如:
“解释一下这段 Python 代码在做什么。”
输出自然语言解释。
还是 create()。
九、什么时候用 parse?
如果结果要进入程序处理,优先用 parse()。
比如:
1. 合同审核
你希望输出:
这明显是结构化数据。
用 parse()。
2. AI 生成 PPT
你希望输出:
这也适合 parse()。
因为后面程序要根据这些字段生成 PPTX。
3. 用户意图识别
比如用户说:
“帮我查一下昨天的订单。”
你希望模型输出:
intent = "query_order"
date = "yesterday"
这种场景,用 parse()。
4. 数据入库
比如简历解析、发票解析、表单提取。
只要后面要写数据库。
就不要让模型随便写文本。
直接上 parse()。
十、一个真实项目里的组合用法
实际项目里,create()和 parse()不是二选一。
经常是混用。
比如做一个 AI PPT 生成系统。
第一步:用 create 生成整体讲稿思路
这一步结果给人看,也方便调试。
response = client.responses.create(
model="gpt-5.2",
input=[
{
"role": "developer",
"content": "你是一个产品方案顾问,擅长把复杂技术讲成清晰的汇报结构。"
},
{
"role": "user",
"content": "帮我规划一份 8 页的 AI 合同审核产品介绍 PPT 大纲。"
}
],
)
print(response.output_text)
第二步:用 parse 生成页面结构
这一步结果给程序用。
所以要结构化。
from pydantic import BaseModel
class SlidePage(BaseModel):
page_number: int
title: str
layout: str
key_points: list[str]
visual_suggestion: str
speaker_notes: str
class SlideDeck(BaseModel):
topic: str
pages: list[SlidePage]
response = client.responses.parse(
model="gpt-5.2",
input=[
{
"role": "developer",
"content": "你是PPT结构设计助手。请把用户主题拆成可生成PPT的页面结构。"
},
{
"role": "user",
"content": "生成一份 8 页的 AI 合同审核产品介绍 PPT 页面结构。"
}
],
text_format=SlideDeck,
)
deck = response.output_parsed
for page in deck.pages:
print(page.page_number, page.title, page.layout)
这就是比较稳的工程路线:
create 负责思考和表达。parse 负责结构和落地。
十一、parse 不是万能的,也有坑
parse()很好用。
但不要神化它。
它也有几个注意点。
1. Schema 不要设计太复杂
字段太多。
嵌套太深。
约束太绕。
模型就更容易出错。
建议从简单结构开始。
先跑通,再扩展。
2. 字段描述要清楚
比如:
这就有点模糊。
更好的做法是用枚举。
from enum import Enum
from pydantic import BaseModel
class RiskLevel(str, Enum):
low = "low"
medium = "medium"
high = "high"
class ContractRisk(BaseModel):
risk_level: RiskLevel
risk_type: str
original_text: str
suggestion: str
这样更稳。
3. 不要把大段正文塞进结构化字段
PPT 场景尤其常见。
你让模型输出:
它可能塞一大段。
后面生成 PPT 直接爆版。
建议拆成:
title: str
bullet_points: list[str]
speaker_notes: str
页面上放 bullet。
详细内容放备注。
这才像 PPT。
4. 失败要有兜底
结构化输出仍然可能失败。
比如:
所以生产环境里要加:
别裸奔上线。
AI 会给你惊喜。也会给你惊吓。🐛
十二、developer role 的实战建议
如果你现在写新项目,我建议这样组织输入。
普通问答
input=[
{
"role": "developer",
"content": "你是一个技术助手。回答要准确、简洁,不要编造 API。"
},
{
"role": "user",
"content": "responses.create 怎么用?"
}
]
结构化抽取
input=[
{
"role": "developer",
"content": "你负责信息抽取。只输出文本中明确出现的信息,不要推测。"
},
{
"role": "user",
"content": "李雷,产品经理,擅长需求分析和原型设计。"
}
]
企业业务场景
input=[
{
"role": "developer",
"content": "你是企业合同审核助手。必须保守判断,不确定时标记为 needs_review。"
},
{
"role": "user",
"content": "请审核以下合同条款:..."
}
]
核心原则:
developer 放规则,user 放任务。
这样后期维护会舒服很多。
十三、我的选择建议
如果你只是写 Demo:
用 responses.create()。
简单。直观。够用。
如果你做真实项目:
认真考虑 responses.parse()。
尤其是结果要进入数据库、流程引擎、PPT 生成器、合同审核系统的时候。
如果你做 Agent:
两个都要会。
Agent 往往需要:
- • 用
parse()做计划、分类、动作参数、状态流转
最后给一个实战判断:
小结 💡
今天这篇,我们讲了三个点:
- 1. Responses API 是更统一的新接口。
新项目可以优先考虑它。 - 2. responses.create 适合生成文本。
结果主要给人看,就用它。 - 3. responses.parse 适合结构化输出。
结果要给程序处理,就用它。
再加一句:
developer role 更适合放应用规则,user role 更适合放用户任务。
最后记住这句话:
给人看的,用 create。给程序用的,用 parse。
这基本能解决 80% 的选择问题。🚀
互动问题
你在项目里用 OpenAI SDK 时,最头疼的是哪一类问题?
是接口迁移?
结构化输出?
还是工具调用和 Agent 工作流?
欢迎留言聊聊。🐱
AI喵智能体
通俗讲AI,带你做实战。
关注我,和AI一起成长。


