【论文分享】PHP:从人类技能到机器人动作——深度视觉策略让人形机器人自主选择并执行跑酷技能
- 2026-07-02 03:06:04
摘要
🤖 Perceptive Humanoid Parkour (PHP) 提出一个模块化框架,通过运动匹配和教师-学生训练流程,使人形机器人能够自主执行长程、高动态的跑酷行为。
🤸 该框架利用运动匹配将人类原子技能合成为多样化的运动轨迹,并结合 DAgger 和强化学习(RL)将多专家策略蒸馏为一个基于深度(depth-based)的单一人形机器人视觉运动策略。
✨ 实验在 Unitree G1 人形机器人上实现了零样本(zero-shot)的模拟到现实(sim-to-real)迁移,展示了其在复杂障碍物上自主选择技能、平滑过渡以及对实时扰动适应的能力。

这篇论文介绍了感知人形机器人跑酷(Perceptive Humanoid Parkour,PHP),这是一个模块化框架,旨在使人形机器人在复杂障碍物课程中,利用机载感知自主执行长时间、高动态的跑酷行为。该框架通过运动匹配(Motion Matching)方法,将各种灵活的人体技能组合成长时间的运动轨迹,并采用“教师-学生”训练流程,将多个专家策略提炼成一个单一的、基于深度感知的多技能策略。
核心方法与技术细节
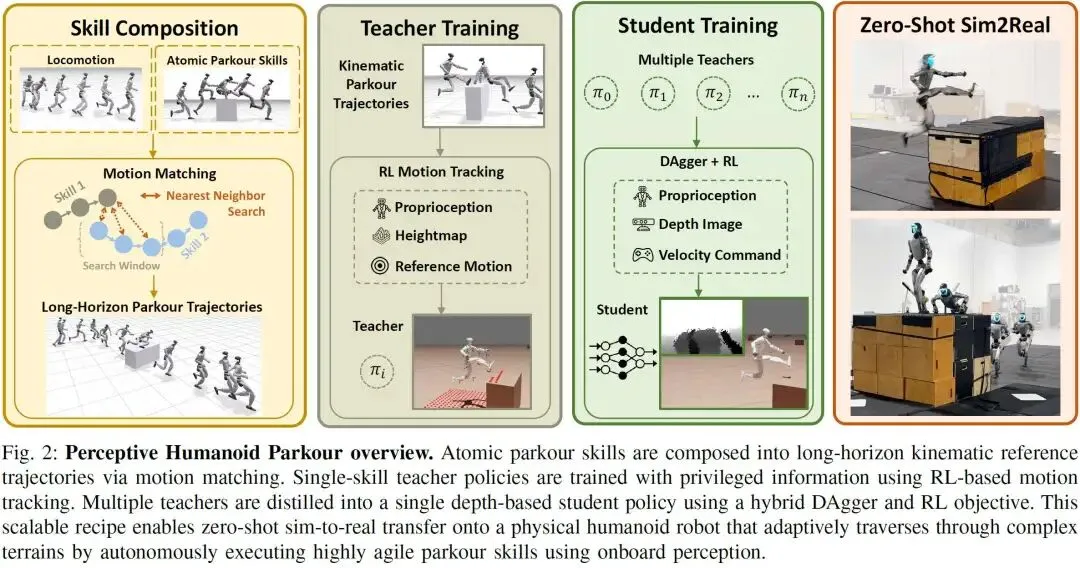
该框架的核心在于其能够将稀疏的原子级人体运动数据(如跳跃、翻滚、攀爬等)合成为丰富、连贯且适应性强的长时间运动序列,并将其转化为机器人可以在真实世界中执行的感知运动策略。
技能组合(Skill Composition)
运动匹配(Motion Matching):PHP利用运动匹配作为合成长时间运动轨迹的关键机制。运动匹配通过在设计的特征空间中进行最近邻搜索,检索和拼接运动片段,从而生成长而流畅的运动。
运动数据库与特征预计算:首先,所有运动片段都被重定向(retarget)到Unitree G1人形机器人模型,形成帧序列。对于每一帧 ,存储机器人配置 ,包括根部平移 、根部四元数 和关节角度 。同时,预计算一个特征向量 ,其包含:
未来根部轨迹 :在未来0.33秒、0.67秒和1秒处的平面根部位置和朝向。
局部脚部状态 :左右脚在根部坐标系下的位置和线速度。
根部速度 :根部线速度。
为了增加数据覆盖,所有运动片段都通过镜像进行数据增强。
查询特征构建与最近邻搜索:在运行时,给定当前机器人配置 和一个2D速度指令,构建一个查询特征 。从 中提取姿态相关特征(局部脚部状态 和根部速度 )。然后,将2D速度指令转换为短时程未来根部轨迹 ,这通过一个临界阻尼弹簧模型(critically damped spring model)实现。弹簧模型应用于2D根部速度和根部朝向。弹簧状态 在未来时间 的闭合形式为:
其中 ,,且 为阻尼参数。平面位置 通过积分闭合形式的速度得到:
接着,通过以下公式在特定搜索窗口 中检索最佳匹配帧 :
搜索窗口 根据用户指定的即将执行的技能动态调整。
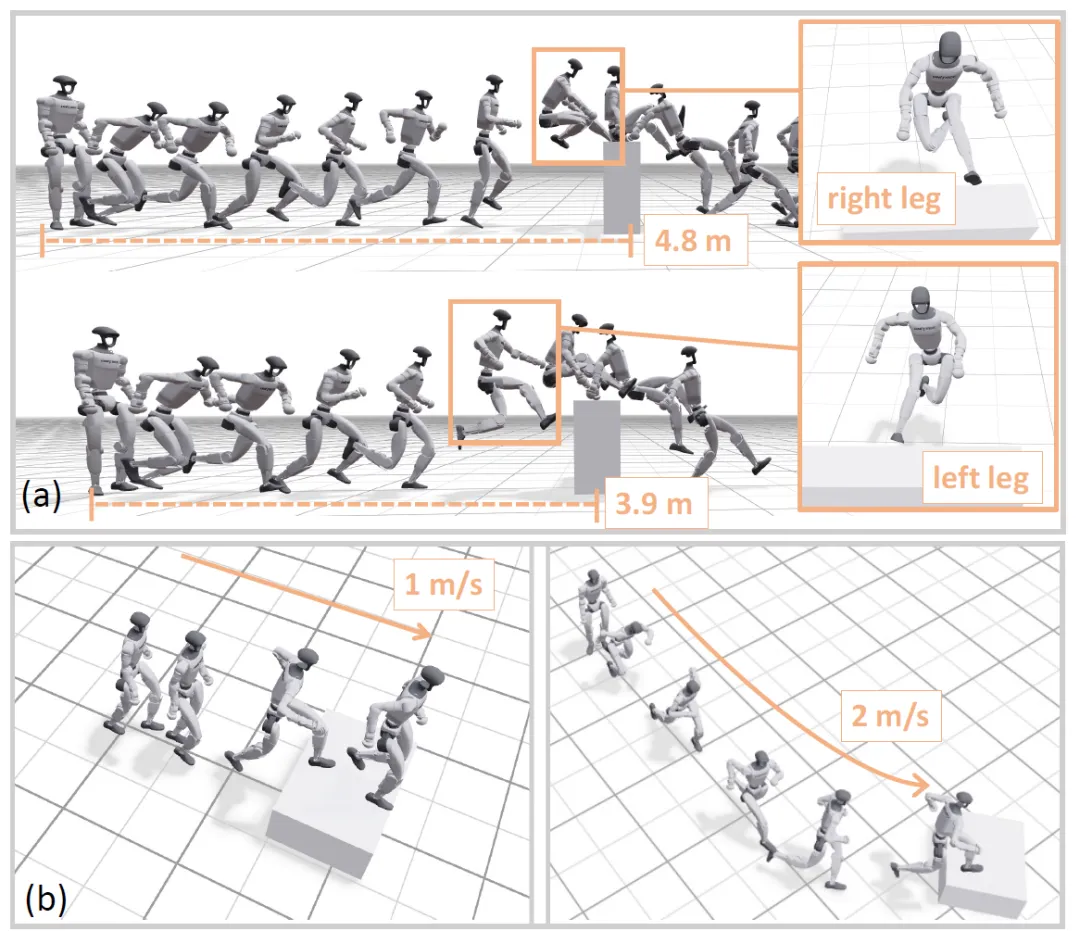
长时间跑酷轨迹合成:将运动和原子跑酷技能合成为“运动 → 跑酷技能 → 运动”的形式。
维护一个运动数据库 和一个技能数据库集合 。
每个原子技能片段都标注了开始帧 和结束帧 ,并定义了一个预技能进入窗口 ,用于捕获主操作前的接近阶段。
运动模式:正常运动时,搜索窗口 。
运动 → 技能过渡:当需要过渡到技能 时,搜索窗口限制在预技能进入窗口 ,机器人过渡到匹配的进入帧。技能执行期间,关闭运动匹配,顺序播放技能片段。
技能 → 运动过渡:到达 后,切换回运动模式。
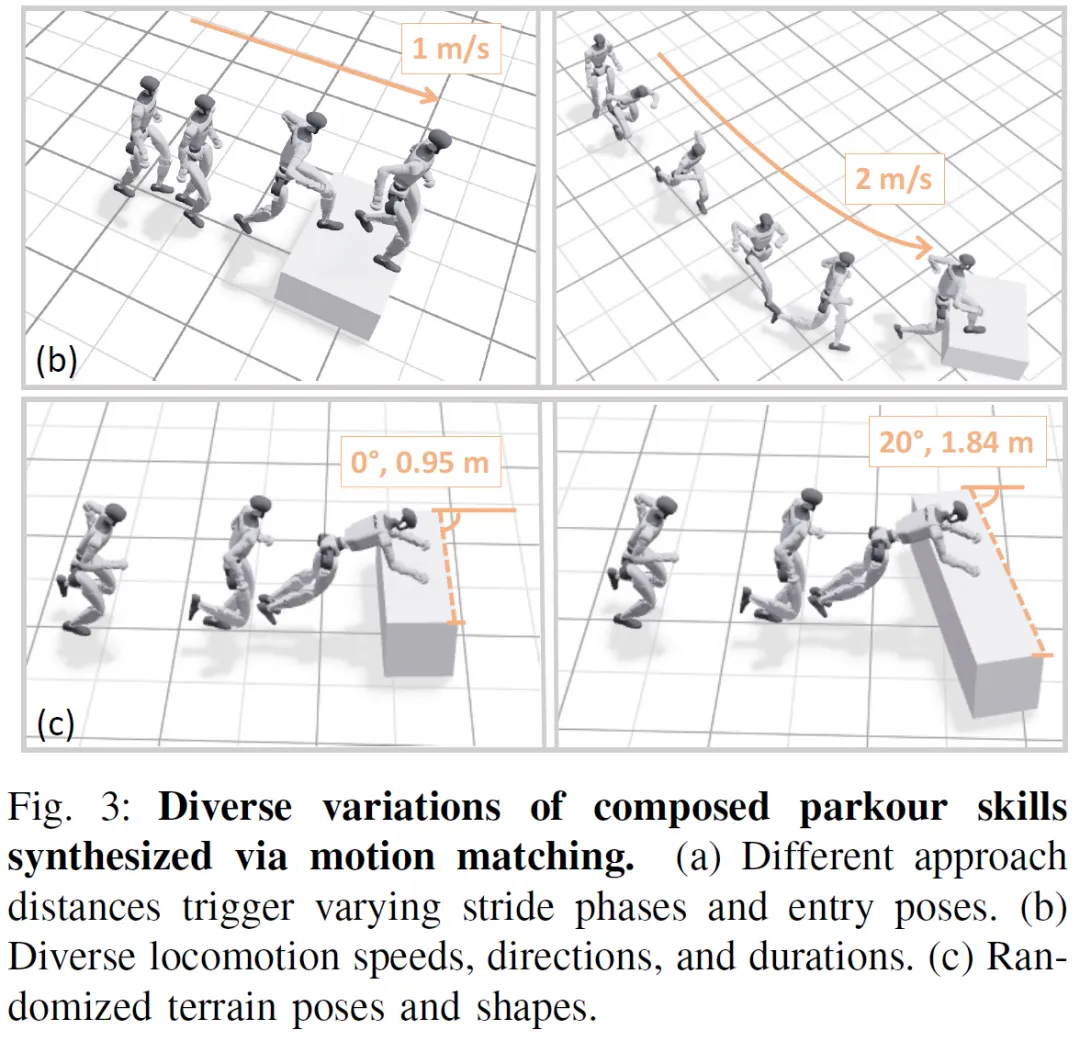
数据集构建:通过采样2D速度指令、随机化预技能运动持续时间([0.1, 3]秒)、随机化障碍物几何形状和姿态(宽度、尺寸和偏航角)、并放置干扰物(distractors)来合成多样化的长程参考轨迹,以增强策略对环境变化的适应性。
惯性化(Inertialization):为了确保切换播放索引时平滑过渡,采用惯性化技术,通过计算当前播放运动与目标运动之间的偏移量并逐渐衰减至零来消除不连续性。
视觉运动策略学习(Learning a Visuomotor Policy)
两阶段训练:
专家策略训练(Expert Policy Training):为每个技能训练运动追踪专家策略。
观测:包括参考关节位置/速度、参考骨盆姿态误差、骨盆线/角速度、关节位置/速度以及前一动作。此外,专家还获得0.7m x 0.7m的高度扫描(height scan)。
特权信息:专家拥有骨盆全局位置和速度等特权信息,使其能够学习恢复行为,这对于与地形紧密耦合的参考运动至关重要。
自适应采样:优先从更频繁失败的区域进行采样,以帮助学习高难度技能。
奖励与终止条件:遵循BeyondMimic风格的追踪奖励,包括动作率、关节限制和碰撞惩罚,以及基于追踪的提前终止。
统一学生策略蒸馏(Distilling a Unified Student Policy):将多个专家策略蒸馏成一个单一的、基于深度的多技能学生策略。
DAgger + RL 混合目标:纯粹的DAgger(Dataset Aggregation)模仿学习不足以应对像攀爬和跳跃这类高动态技能,因为其不对情景结果负责,且对瞬时高扭矩动作不敏感。因此,PHP结合了DAgger和RL(强化学习)目标:
其中 是PPO(Proximal Policy Optimization)损失, 是DAgger损失。PPO提供了一个成功驱动的信号,鼓励利用专家行为(如高扭矩动作),而非仅模仿每一步的动作。
观测:学生策略接收本体感受信号(骨盆重力矢量和角速度、关节位置和速度、前一动作)以及通过Nvidia WARP渲染的深度图像。
相机建模与深度伪影:为了弥合仿真与现实之间的差距,对模拟相机进行校准(匹配自可见性)、随机化相机外部参数(平移2.5cm,旋转2.5°)、注入逼真的深度噪声(±3cm偏移,3cm标准差高斯噪声)和观测延迟(60ms-80ms)。
课程学习(Curriculum):在训练初期,PPO梯度可能不稳定,因此采用课程学习策略。
逐渐降低 ,在训练前半段从1线性衰减到0.1。
放宽终止阈值(从专家策略的0.5m放宽到1m),以避免因镜像执行而被提前终止。
仅在 超过0.1后才启用自适应学习率和基于KL散度的探索控制。
采样:学生训练期间禁用自适应采样,并均匀采样每个技能内部的数据,以避免数据不平衡和模拟到现实的差距。
实验与结果
该框架在Unitree G1人形机器人上进行了广泛的真实世界实验,并进行了仿真量化评估。
真实世界表现:
人类水平的敏捷性:机器人能够执行高动态跑酷技能,例如在1.25米高墙上的攀爬(占机器人身高的96%),并在3.63秒内完成,与人类跑酷者表现相当。此外,还展示了猫越(cat vault)和落地缓冲等技能。
多障碍物课程:机器人能够组合多种技能(如踩踏、低/高墙攀爬),在复杂障碍物课程中连续运动。通过运动匹配合成的长时间参考轨迹,使策略能够在线生成平滑的技能切换。
对障碍物变化的适应性:在执行过程中,机器人能适应随机移动约0.5米的障碍物,调整其接近方式和操作时机,显示出闭环适应能力。



仿真量化结果:
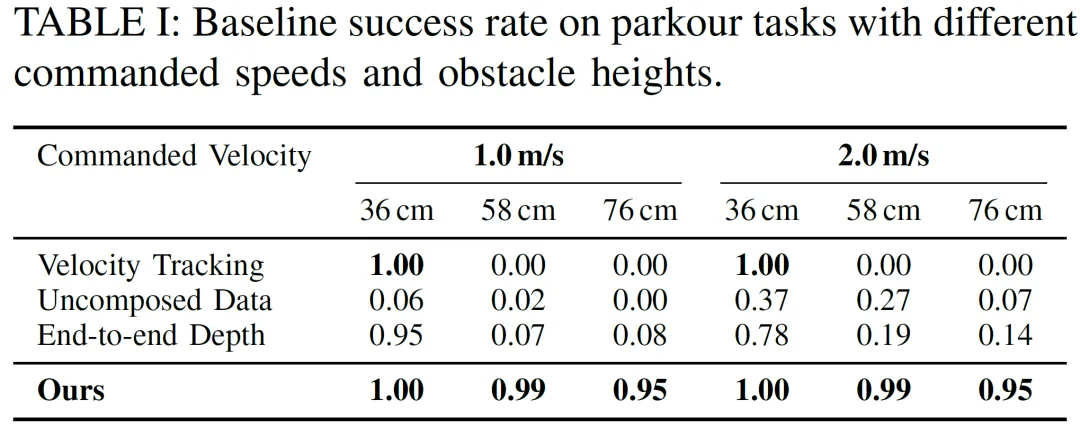
基线比较:
Velocity Tracking:纯粹通过奖励整形学习,在低障碍物上成功,但无法应对高障碍物和全身攀爬策略,凸显了仅靠奖励整形RL的局限性。
Uncomposed Motion Data:尽管有原子技能,但表现极差。机器人走到障碍物前却无法执行攀爬或跳跃,说明孤立的运动不足,且缺少显式的长时程组合和障碍物感知。
End-to-end Depth Policy:端到端训练的深度策略在低障碍物上可行,但在挑战性任务上性能显著下降,表明RL在从头开始探索时存在困难。
PHP:在所有障碍物高度和速度下都表现出更高的成功率,尤其是在高动态技能上。
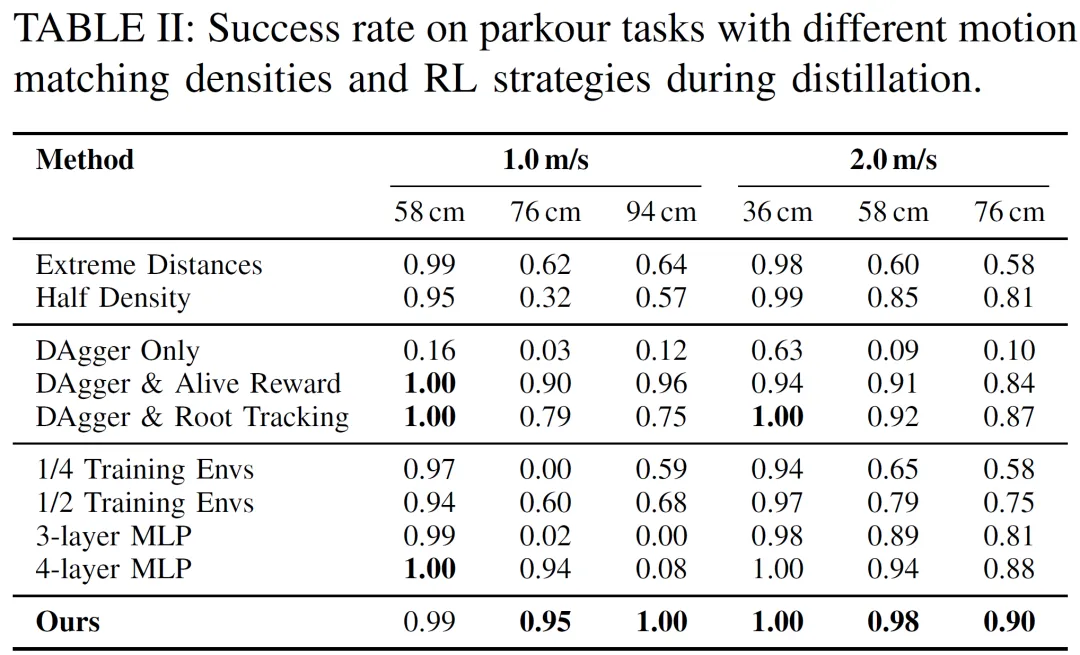
消融研究:
运动匹配数据密度:减少运动匹配数据密度(如只使用极限距离、一半密度)会导致性能下降,尤其是在困难技能上,验证了密集数据覆盖对于准确时机和任务成功的关键作用。
训练可扩展性:增加并行训练环境数量和模型容量(更深的MLP)通常能提高成功率,尤其是在更具挑战性的跑酷任务上,说明蒸馏框架与模型容量和吞吐量呈良好扩展性。
蒸馏中的RL作用:
DAgger Only:性能显著下降,说明DAgger alone不足以捕捉高动态技能。高扭矩爆发动作难以被DAgger精确学习。
DAgger + RL Alive Reward / Root Tracking Reward:这两种简化的RL奖励(而非全身追踪)也能取得与全身追踪相当的成功率,表明RL主要作为成功驱动的利用信号,补偿DAgger的保守性,对奖励设计相对鲁棒。
RL在蒸馏过程中至关重要,能纠正模仿学习引起的保守性并提高技能学习。同时,DAgger项必须在整个训练过程中保持活跃,否则纯RL可能导致不自然的行为。
结论与未来工作
PHP框架成功地使人形机器人自主执行长时间、高动态的跑酷行为,并利用机载感知适应多样化障碍物。其关键在于运动匹配提供的连贯长时程参考运动和暴露策略于广泛的接近条件,以及通过RL增强蒸馏过程,高效地将专家能力转移到多技能、基于深度的学生策略。
未来工作方向包括:
融入语义场景理解,例如通过语言,实现更精细的控制和多样性。
改进感知和硬件能力,例如更广视场的短程相机,以减少感知模糊性。
解决硬件在手部/夹持器强度上的限制,以便探索更极端的攀爬和悬挂操作。



【论文分享】RPL:从特权专家到深度视觉——人形机器人复杂地形自适应行走的Transformer解决方案
【论文分享】LatentMimic:四足机器人运动学习新范式——潜空间解耦实现复杂地形高成功率穿越与风格保真
【论文分享】TRANS:两阶段强化学习框架,融合地形感知运动与社交导航,实现四足机器人复杂环境敏捷导航
【算法框架】PPO:以截断概率比实现近端优化,奠基四足人形强化学习的经典基石!
【算法框架】Asymmetric Actor-Critic:Critic用状态Actor看图像,以非对称训练攻克视觉策略学习难题
【算法框架】Diffusion Policy:将机器人策略建模为去噪过程,实现多模态高维动作的稳定学习与部署
【论文分享】OpenHEART:单策略适配多种异构铰接物体!特征提取+自适应关节估计,实现腿式机械手跨域鲁棒操作
【论文分享】MimicKit:运动模仿的一站式研究平台!统一可配置架构助力探索DeepMimic/AMP/ASE/ADD等核心方法
【论文分享】AugMPC:无需预设步态的跨域控制!RL与MPC分层协作,让重型机器人学会自主生成高效全身运动


