Python 写策略很爽,但有一个致命弱点:慢。
前面聊了 Polars(6/3) 和 DuckDB(6/6) 解决数据处理的速度问题。但有些计算——比如逐 K 线遍历、路径依赖型策略、蒙特卡洛模拟——必须用 for 循环,Polars/DuckDB 帮不上忙。
今天聊 Numba——1.1 万 Star,LLVM JIT 编译器。加一行 @njit,你的 Python for 循环就能跑出 C 的速度。
项目地址: https://github.com/numba/numba
⭐ 11,000+ Stars | 1,200+ Forks | Python | BSD-2 License
官方文档: https://numba.readthedocs.io
它是什么?
Numba = Python 的 JIT(即时)编译器。
code
Python 慢的原因:
Python 是解释型语言
每一行代码都要经过 Python 解释器
for 循环尤其慢——每次迭代都有解释开销
Numba 的原理:
┌──────────────────────────────────────────┐
│ 你的 Python 函数 │
│ ↓ @njit 装饰器 │
│ Numba 分析代码 + 推断类型 │
│ ↓ LLVM 编译器 │
│ 原生机器码(和 C 一样快) │
└──────────────────────────────────────────┘
第一次调用:编译(稍慢)
第二次调用:直接跑机器码(极快)
结果:
for 循环提速 50-200 倍
不用学 C / C++ / Rust
不用改算法
只加一行装饰器
快速上手
安装
bash
pip install numba
第一个 @njit
python
from numba import njit
import numpy as np
import time
# 纯 Python 版本
defslow_sum(arr):
total = 0.0
for i inrange(len(arr)):
total += arr[i]
return total
# Numba 版本——只加了一行 @njit
@njit
deffast_sum(arr):
total = 0.0
for i inrange(len(arr)):
total += arr[i]
return total
arr = np.random.rand(10_000_000)
# 纯 Python
t0 = time.time()
slow_sum(arr)
print(f"Python: {time.time() - t0:.3f}s")
# Numba(第一次调用包含编译时间)
fast_sum(arr) # 预热编译
t0 = time.time()
fast_sum(arr)
print(f"Numba: {time.time() - t0:.3f}s")
# 输出:
# Python: 2.340s
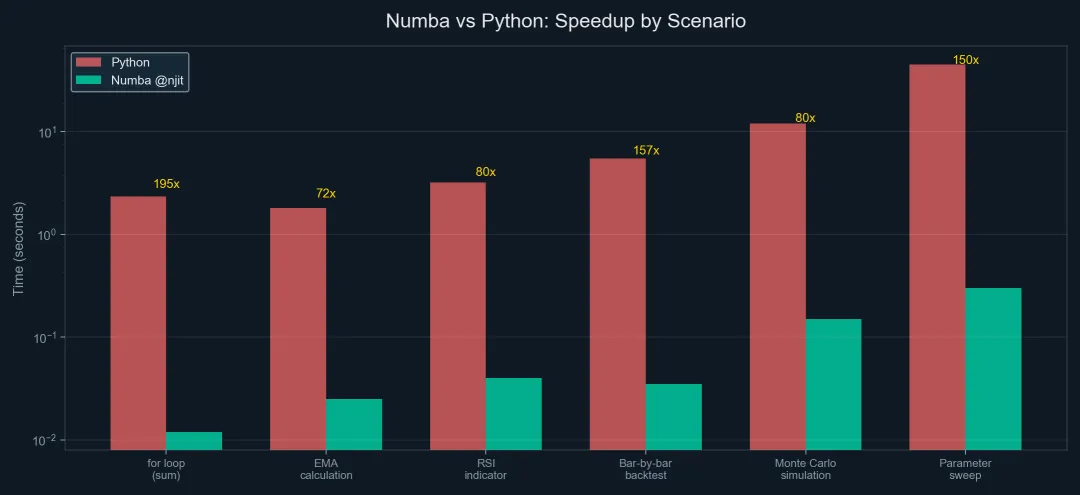
# Numba: 0.012s ← 快了 195 倍!
量化实战场景
场景 1:自定义技术指标
python
from numba import njit
import numpy as np
@njit
defema(prices, period):
"""指数移动平均线——Numba 加速版"""
result = np.empty_like(prices)
alpha = 2.0 / (period + 1)
result[0] = prices[0]
for i inrange(1, len(prices)):
result[i] = alpha * prices[i] + (1 - alpha) * result[i - 1]
return result
@njit
defrsi(prices, period=14):
"""RSI 指标——Numba 加速版"""
result = np.full(len(prices), np.nan)
gains = np.zeros(len(prices))
losses = np.zeros(len(prices))
for i inrange(1, len(prices)):
change = prices[i] - prices[i - 1]
if change > 0:
gains[i] = change
else:
losses[i] = -change
# 初始平均
avg_gain = np.mean(gains[1:period + 1])
avg_loss = np.mean(losses[1:period + 1])
if avg_loss == 0:
result[period] = 100.0
else:
result[period] = 100.0 - 100.0 / (1 + avg_gain / avg_loss)
# 后续值
for i inrange(period + 1, len(prices)):
avg_gain = (avg_gain * (period - 1) + gains[i]) / period
avg_loss = (avg_loss * (period - 1) + losses[i]) / period
if avg_loss == 0:
result[i] = 100.0
else:
result[i] = 100.0 - 100.0 / (1 + avg_gain / avg_loss)
return result
# 4000 只股票 × 250 天
prices = np.random.rand(4000, 250) * 100
# pandas 版要 5-10 秒,Numba 版 < 0.1 秒
场景 2:逐 K 线回测(路径依赖)
python
from numba import njit
import numpy as np
@njit
defbacktest_ma_cross(close, fast_period, slow_period, initial_cash):
"""均线交叉回测——逐 K 线遍历"""
n = len(close)
cash = initial_cash
position = 0.0
equity = np.empty(n)
for i inrange(slow_period, n):
# 计算均线
fast_ma = np.mean(close[i - fast_period + 1:i + 1])
slow_ma = np.mean(close[i - slow_period + 1:i + 1])
# 金叉买入
if fast_ma > slow_ma and position == 0:
position = cash / close[i]
cash = 0.0
# 死叉卖出
elif fast_ma < slow_ma and position > 0:
cash = position * close[i]
position = 0.0
# 记录净值
equity[i] = cash + position * close[i]
return equity
# 单次回测
close = np.random.rand(5000) * 100 + 50
equity = backtest_ma_cross(close, 5, 20, 100000.0)
场景 3:蒙特卡洛模拟
python
from numba import njit, prange
import numpy as np
@njit(parallel=True)
defmonte_carlo_portfolio(returns, n_simulations, n_days):
"""蒙特卡洛模拟——并行加速"""
mean_ret = np.mean(returns)
std_ret = np.std(returns)
final_values = np.empty(n_simulations)
for sim in prange(n_simulations): # prange = 并行循环
portfolio = 1000000.0# 初始资金 100 万
for day inrange(n_days):
# 随机收益率
daily_return = np.random.normal(mean_ret, std_ret)
portfolio *= (1 + daily_return)
final_values[sim] = portfolio
return final_values
# 10 万次模拟,250 天
returns = np.random.normal(0.0005, 0.02, 1000)
results = monte_carlo_portfolio(returns, 100_000, 250)
print(f"中位数终值: {np.median(results):,.0f}")
print(f"5% VaR: {np.percentile(results, 5):,.0f}")
print(f"95%分位: {np.percentile(results, 95):,.0f}")
场景 4:批量参数扫描
python
from numba import njit, prange
import numpy as np
@njit
defsingle_backtest(close, fast, slow):
"""单次回测,返回 Sharpe"""
n = len(close)
returns = np.empty(n)
pos = 0.0
prev_equity = 100000.0
for i inrange(slow, n):
fast_ma = np.mean(close[i - fast + 1:i + 1])
slow_ma = np.mean(close[i - slow + 1:i + 1])
if fast_ma > slow_ma and pos == 0:
pos = prev_equity / close[i]
elif fast_ma < slow_ma and pos > 0:
prev_equity = pos * close[i]
pos = 0.0
equity = prev_equity if pos == 0else pos * close[i]
returns[i] = (equity - prev_equity) / prev_equity if prev_equity > 0else0
prev_equity = equity
valid = returns[slow:]
if np.std(valid) == 0:
return0.0
return np.mean(valid) / np.std(valid) * np.sqrt(252)
@njit(parallel=True)
defparameter_sweep(close, fast_range, slow_range):
"""批量参数扫描——并行"""
n_fast = len(fast_range)
n_slow = len(slow_range)
results = np.empty((n_fast, n_slow))
for i in prange(n_fast):
for j inrange(n_slow):
if fast_range[i] >= slow_range[j]:
results[i, j] = np.nan
else:
results[i, j] = single_backtest(
close, fast_range[i], slow_range[j]
)
return results
# 扫描 fast=[3..30], slow=[10..120]
close = np.random.rand(2000) * 100 + 50
fast_range = np.arange(3, 31)
slow_range = np.arange(10, 121)
sharpe_matrix = parameter_sweep(close, fast_range, slow_range)
# 28 × 111 = 3108 次回测,并行执行
Numba 的三个关键装饰器
python
from numba import njit, jit, vectorize
# 1. @njit(推荐,nopython 模式)
# 完全编译为机器码,不调用 Python 解释器
# 最快,但有类型限制
@njit
deffast_func(x):
return x ** 2
# 2. @njit(parallel=True) + prange
# 自动并行化循环
@njit(parallel=True)
defparallel_func(arr):
result = np.empty_like(arr)
for i in prange(len(arr)):
result[i] = arr[i] ** 2
return result
# 3. @vectorize
# 自定义 ufunc(逐元素操作)
from numba import float64
@vectorize([float64(float64, float64)])
defclip_return(ret, threshold):
if ret > threshold:
return threshold
elif ret < -threshold:
return -threshold
return ret
Numba 能加速什么 / 不能加速什么
| | |
|---|
| for 循环 | | |
| NumPy 数组运算 | | |
| 蒙特卡洛 | | |
| 逐 K 线回测 | | |
| 自定义指标 | | |
| 参数扫描 | | |
| | |
| | |
| | |
| | |
code
Numba 的黄金法则:
"如果你的瓶颈是 for 循环 + 数值计算,
Numba 就是你的答案。"
"如果你的瓶颈是 I/O / 网络 / 数据库,
Numba 帮不了你——用 DuckDB / Polars。"
Numba + 本系列工具
| |
|---|
| |
| |
| |
| |
| Numba + Backtesting.py(5/17) | |
典型工作流
code
完整加速方案:
┌────────────────────────────────────┐
│ 数据层:DuckDB(SQL 查大文件) │
│ ↓ │
│ 清洗层:Polars(DataFrame 加工) │
│ ↓ │
│ 计算层:Numba(因子循环加速) │
│ ↓ │
│ 模型层:XGBoost(因子建模) │
│ ↓ │
│ 调参层:Optuna(超参数优化) │
│ ↓ │
│ 分析层:QuantStats(绩效报告) │
└────────────────────────────────────┘
每一层用最合适的工具,
每一层都跑在最优性能。
常见陷阱
| |
|---|
| 首次调用慢 | |
| 类型不匹配 | Numba 需要确定类型,传入 NumPy 数组而非 list |
| pandas 不支持 | |
| 全局变量 | |
| debug 困难 | |
python
# 常见错误:传入 pandas Series
@njit
defbad_func(series): # ← 会报错
...
# 正确做法:传入 numpy array
@njit
defgood_func(arr):
...
# 调用时转换
result = good_func(df['close'].values) # ← .values 转 numpy
Numba vs 其他加速方案
| | | |
|---|
| Numba @njit | | | |
| Polars | | | |
| Cython | | | |
| C 扩展 | | | |
| Rust (PyO3) | | | |
code
选择建议:
DataFrame 操作慢 → Polars
SQL 查询慢 → DuckDB
for 循环慢 → Numba(推荐)
极致性能 → Cython / Rust
不想改代码 → 升级硬件
局限性
| |
|---|
| 不支持 pandas | 只支持 NumPy 数组和基本 Python 类型 |
| 不支持所有 Python | |
| 首次编译开销 | |
| 调试困难 | |
| GPU 支持有限 | |
code
关键认知:
Numba 不是"让所有 Python 代码变快"——
它是"让数值循环代码变快"的专用工具。
最佳实践:
1. 先写纯 Python,调通逻辑
2. 用 profiler 找到瓶颈函数
3. 只给瓶颈函数加 @njit
4. 传入 NumPy 数组
5. 享受 100 倍加速
小结
code
Numba:
- 11,000+ Star,Python JIT 编译器
- 加一行 @njit → for 循环快 50-200 倍
- 基于 LLVM,编译为原生机器码
- prange 并行循环,利用多核 CPU
- 完美支持 NumPy 数组
- 量化场景:因子计算 / 逐 K 线回测 / 蒙特卡洛
- BSD-2 开源协议
量化性能加速全景:
数据查询 → DuckDB(SQL)
数据加工 → Polars(DataFrame)
数值循环 → Numba(JIT 编译)
引擎底层 → Rust / C++(NautilusTrader)
一句话:
"不用学 C++,不用换语言——
@njit 一行,Python 起飞。"
⚠️ 免责声明:Numba 是性能优化工具,不构成投资建议。本文仅介绍技术工具,投资决策请综合多方信息。
#Numba #JIT #性能优化 #Python加速 #蒙特卡洛 #量化投资 #投资

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
