由于借助 AI 工具学习编程已经变得非常容易了,因此之后的课程就不再默认进行视频讲解了,如果特别需要视频讲解也可以联系李老师预约讲解~讲义材料学习过程中遇到的问题也可以及时与李老师联系。
购买 RStata 名师讲堂会员即可参加该课程啦(之前的和未来的都可以参加)!
价格:2800/年 或者 4800/长期
购买会员可以从这里下单:https://rstata.duanshu.com/#/card/list/
名师讲堂会员权益:
- 参加平台上的其他 R 语言和 Stata 的课程;
- 以会员折扣价购买我们分享的数据资料(10 元/份);
* 如果发票可添加小编微信 r_stata2 (RStata 李老师)开具。如需数据资料,购买后可添加小编微信免费领取数据折扣卡。
更多关于 RStata 会员的更多信息可添加微信号 r_stata2 咨询:

课程主页(点击文末的阅读原文即可跳转):https://rstata.duanshu.com/#/brief/course/e4ac5c33a05940f6bc7f82b4dfb5fa2c
今天给大家分享使用 Python 测算区域技术专业化的方法。该方法参考自林原(2018)《技术流动对区域技术专业化的影响研究》,通过IPC专利分类和RTA指数来综合测度区域的技术专业化程度。
附件中提供了该参考文献的 PDF 文件,感兴趣的小伙伴可以阅读原文。
指标来源与计算原理
区域技术专业化(Regional Technological Specialization)
区域技术专业化是衡量地区在特定技术领域集聚程度的重要指标。该方法的核心思想是:
- IPC专利分类:利用世界知识产权组织(WIPO)的IPC与技术领域对照表,将专利按IPC代码归类到35个技术领域
- RTA指数(Revealed Technological Advantage):计算区域在特定技术领域的相对优势
- CV(变异系数):用调整后RTA的变异系数衡量区域技术专业化的整体程度
RTA指数
调整后RTA
CV计算
计算步骤概述
整个计算过程分为以下几个步骤:
- RTA计算:计算各省份各技术领域的RTA和调整后RTA
使用 reticulate 创建与管理 Python 虚拟环境
在 R 中通过 reticulate 包来调用 Python,最好的实践是为项目创建一个专属的 Python 虚拟环境,将所需依赖隔离到独立空间,避免与系统 Python(如 Anaconda)发生版本冲突。
重要说明(避免"已初始化"报错):reticulate 在 R 会话中只能绑定一次 Python——一旦某个 {python} 代码块运行,Python 解释器就被锁定,之后再调用 use_virtualenv() 会报错:
ERROR: The requested version of Python cannot be used, as another version has already been initialized.因此,虚拟环境的激活必须在所有 {python} 代码块之前完成。本文档的解决方案是在 setup chunk 中通过 Sys.setenv(RETICULATE_PYTHON = ...) 提前锁定 Python 路径,这是 reticulate 选取 Python 的最高优先级入口。
安装 reticulate(仅首次)
# 设置 CRAN 镜像(knit 时 R 处于非交互模式,不会自动选择镜像)options(repos = c(CRAN = "https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))# 仅在尚未安装时才安装,避免每次 knit 都重装if (!requireNamespace("reticulate", quietly = TRUE)) { install.packages("reticulate") message("reticulate 安装完成!") message("reticulate 已安装,版本:", packageVersion("reticulate"))虚拟环境初始化原理(已在 setup chunk 中完成)
本文档的 setup chunk(隐藏运行)包含如下逻辑:
.venv_python <- virtualenv_python(.venv_name)if(!file.exists(.venv_python)){ virtualenv_create(.venv_name) .venv_python <- virtualenv_python(.venv_name)# 通过环境变量抢先锁定 Python(优先级最高,早于任何 {python} chunk)Sys.setenv(RETICULATE_PYTHON = .venv_python)use_virtualenv(.venv_name, required =TRUE)在虚拟环境中安装 Python 包(仅首次)
本项目主要使用 pandas 和 numpy,都是 Python 标准库,不需要额外安装:
py_pkgs <- c("pandas", "numpy")installed <- py_list_packages(".venv")$packageneed_install <- setdiff(py_pkgs, installed)if (length(need_install) > 0) { virtualenv_install(".venv", packages = need_install) message("已安装缺失的包:", paste(need_install, collapse = ", ")) message("所有 Python 包已就绪,无需安装")验证激活状态
# 验证当前绑定的 Python 路径(应指向 .venv 目录)
详细计算代码
数据读取
读取专利数据和WIPO对照表:
DATA_DIR = Path(__file__).parent if'__file__'indir() else Path(".")PATENT_FILE = DATA_DIR / "2010.csv"WIPO_FILE = DATA_DIR / "WIPO_IPC_and_Technology_Concordance_Table.csv"df_raw = pd.read_csv(PATENT_FILE, encoding="utf-8")print(f"原始数据行数: {len(df_raw)}")wipo = pd.read_csv(WIPO_FILE, encoding="utf-8")print(f"WIPO对照表: {len(wipo)} 个技术领域")数据说明:
2010.csv:包含各省份各专利的详细信息,包括IPC代码、省市县等字段WIPO_IPC_and_Technology_Concordance_Table.csv:WIPO发布的IPC与技术领域对照表,包含35个技术领域
数据预处理——按地区去重
由于同一专利可能在多个地区出现(如共同申请),需要进行去重处理:
df_raw["公开公告号_clean"] = df_raw["公开公告号"].str.replace(r"[A-Z]$", "", regex=True)df_raw = df_raw.drop_duplicates( subset=["省", "市", "县", "公开公告号_clean"],print(f"按地区+公告号去重后: {len(df_raw)} 行")df_raw = df_raw.drop_duplicates( subset=["省", "市", "县", "申请号"],print(f"按地区+申请号去重后: {len(df_raw)} 行")df_raw = df_raw.drop_duplicates( subset=["省", "市", "县", "newipzlid"],print(f"按地区+专利ID去重后: {len(df_raw)} 行")构建IPC查找表
WIPO对照表中IPC代码的表示规则:
| | |
|---|
| G09F, G09G, G11B | |
# | G06# | |
## | H04N-013, H04N-017 | |
-xxx | H04N-003 | |
not | (G06# not G06Q) | |
关键函数说明:
pattern_to_prefix():将各种IPC表示规则转换为统一的前缀格式build_ipc_lookup():构建完整的IPC到技术领域的映射,处理逗号分隔、#、排除规则等
IPC匹配函数
test_ipcs = ["G06F19/00", "G06Q99/00", "H04L", "C12P1/00", "F42B10/26", "G01N", "B01D01/00", "H04N001/01"] result = match_ipc_fast(tc, lookup_sorted, exclude_map) tech_names = wipo[wipo["序号"].astype(str).isin(result)]["技术领域名称"].tolist() if result else ["无匹配"]print(f" {tc} -> {', '.join(result)} ({', '.join(tech_names)})")对唯一IPC建立查找表(高效匹配)
为避免对86万条专利逐条匹配,先对唯一IPC代码建立查找表:
应用查找表到全部数据
print("\n=== Step 6: 应用查找表到全部专利 ===")df_raw["技术领域"] = df_raw["IPC"].map(ipc_to_tech)df_raw["技术领域"] = df_raw["技术领域"].replace("", np.nan)df_raw["tech_count"] = df_raw["技术领域"].notna().astype(int)matched_patents = df_raw["tech_count"].sum()unmatched_patents = (df_raw["tech_count"] == 0).sum()print(f"有技术领域匹配的专利数: {matched_patents}")print(f"无匹配的专利数: {unmatched_patents}")print(f"总专利数: {len(df_raw)}")df_expanded = df_raw.dropna(subset=["技术领域"])[["省", "省代码", "newipzlid", "技术领域"]].copy()df_expanded = df_expanded.assign( 技术领域=df_expanded["技术领域"].str.split(";")df_expanded = df_expanded.rename(columns={"技术领域": "技术领域序号"})df_expanded = df_expanded.drop_duplicates( subset=["省", "省代码", "newipzlid", "技术领域序号"]df_expanded = df_expanded.dropna(subset=["省"])print(f"展开后行数: {len(df_expanded)}")展开数据说明:
由于一个专利可能同时属于多个技术领域(如同时涉及计算机技术和半导体),需要将专利-领域关系展开为多行。
按省份和技术领域汇总
print("\n=== Step 7: 按省份和技术领域汇总 ===")tech_by_region = df_expanded.groupby().size().reset_index(name="专利数量")print(f"汇总后行数: {len(tech_by_region)}")print(f"涉及省份数: {tech_by_region['省'].nunique()}")计算RTA指数
RTA解读:
计算CV
CV解读:
CV(变异系数)衡量区域技术分布的均衡程度:
保存结果
print("\n=== Step 10: 保存结果 ===")tech_names = wipo[["序号", "技术领域名称", "技术领域名称中文"]].copy()tech_names.columns = ["技术领域序号", "技术领域名称", "技术领域名称中文"]tech_names["技术领域序号"] = tech_names["技术领域序号"].astype(str)tech_df = tech_by_region.merge(tech_names, on="技术领域序号", how="left")tech_df = tech_df.dropna(subset=["省"]).sort_values(["省", "技术领域序号"])cv_output = "区域技术专业化CV_python.csv"cv_by_region.to_csv(cv_output, index=False, encoding="utf-8-sig")print(f"已保存: {cv_output}")tech_output = "技术领域按省份汇总_python.csv"tech_df.to_csv(tech_output, index=False, encoding="utf-8-sig")print(f"已保存: {tech_output}")
R与Python对比
| | |
|---|
| read_csv() | pd.read_csv() |
| distinct() | drop_duplicates() |
| str_remove() | str.replace() |
| group_by() %>% summarize() | groupby().agg() |
| separate_rows() | str.split().explode() |
| sd()/mean() | std()/mean() |
直接运行Python脚本
除了通过Rmd文档运行外,也可以直接运行Python脚本:
cd"/Users/ac/Desktop/使用 Python 测算区域技术专业化"Python脚本会使用内置的 pandas 和 numpy 库,无需额外安装。
如何参加课程?
购买 RStata 名师讲堂会员即可参加该课程啦(之前的和未来的都可以参加)!
价格:2800/年 或者 4800/长期
购买会员可以从这里下单:https://rstata.duanshu.com/#/card/list/
名师讲堂会员权益:
- 参加平台上的其他 R 语言和 Stata 的课程;
- 以会员折扣价购买我们分享的数据资料(10 元/份);
* 如果发票可添加小编微信 r_stata2 (RStata 李老师)开具。如需数据资料,购买后可添加小编微信免费领取数据折扣卡。
更多关于 RStata 会员的更多信息可添加微信号 r_stata2 咨询:

课程主页(点击文末的阅读原文即可跳转):https://rstata.duanshu.com/#/brief/course/e4ac5c33a05940f6bc7f82b4dfb5fa2c










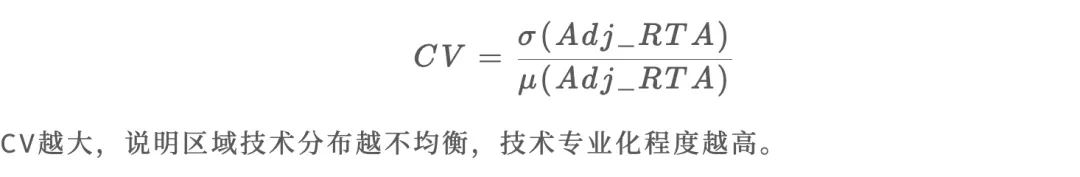
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
