Python学习【176】:Doris + MinIO 架构解析:构建低成本、高性能的大数据湖仓一体方案
用对象存储保存海量文件,用分析数据库秒级查询,一套组合拳搞定结构化和非结构化数据。在真实的数据场景中,我们往往面临两种需求:一是存储图片、视频、日志等非结构化文件;二是对订单、用户行为等结构化表格进行快速分析。传统做法是:文件放 HDFS 或对象存储,分析用 Hive/Spark。但 Hive 查询延迟高(分钟级),不适合交互式分析。有没有一种方案,既能利用对象存储的低成本,又能实现秒级的分析查询?Doris + MinIO 正是这样一套现代数据栈。
- 管理内容:图片、视频、压缩包、日志文件、CSV/Parquet 数据文件等。
- 管理内容:二维表(如订单表、用户画像、指标报表)。
- 优势:亚秒级查询响应、支持高并发、兼容 MySQL 协议。
将 MinIO 作为数据湖(存放所有原始文件),Doris 作为数据仓库(存放结构化分析结果),并通过 Doris 的外部表 能力,直接查询 MinIO 上的 Parquet/CSV 文件,实现:- 一份数据,多种引擎:文件只需要存一次,Doris、Spark、Presto 都可以读。
- 存储与计算分离:对象存储廉价且可靠,Doris 按需扩容计算资源。
- 实时与批处理统一:可以同时处理实时写入的数据(通过 Doris 内部表)和历史文件(外部表)。
- 准备:调整宿主机内核参数(必须)
Doris 要求 vm.maxmapcount 至少为 2000000,否则 BE 无法启动。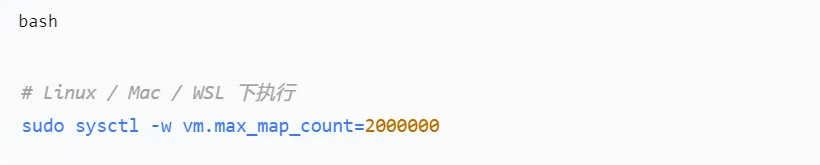
- 使用官方快速启动脚本(推荐)
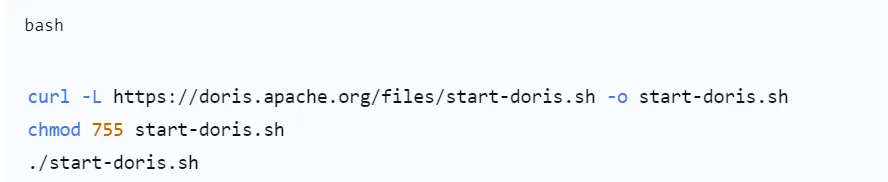
脚本会自动拉取镜像(apache/doris:fe-2.1.8 和 be-2.1.8),并启动一个 FE 和一个 BE。 - 使用 docker-compose(备选)
创建 docker-compose-doris.yml,内容参考前文。注意国内镜像可用 selectdb/doris.fe-ubuntu:2.1.8 加速。
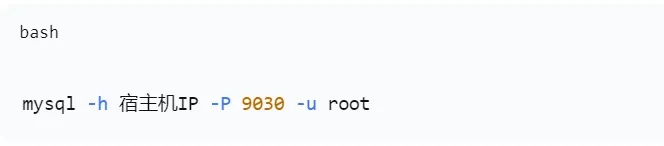
- Web 控制台:http://宿主机IP:8030,用户名 root,无密码。
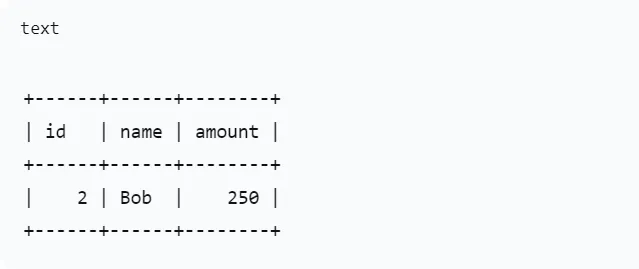
我们之前已经有一个 MinIO 服务(IP 192.168.1.6,端口 9000),桶 my-first-bucket 下有一个 CSV 文件 sales.csv,内容如下:- 在 Doris 中创建外部表(指向 MinIO)
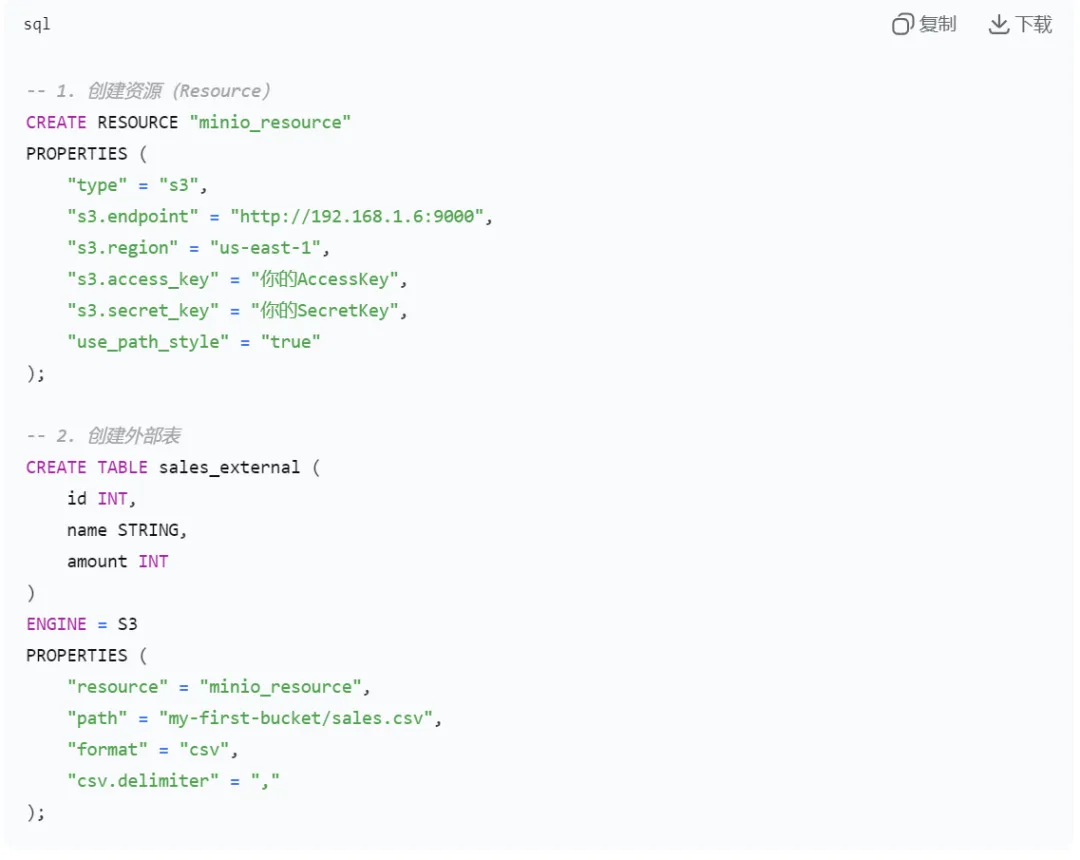
- 数据依然存储在 MinIO 上,Doris 只在查询时扫描文件,不占用本地存储。
- 支持文件格式:CSV、Parquet、ORC、JSON 等。
- 支持分区发现:如果文件目录按 dt=2024-01-01/ 组织,可以创建分区表自动识别。
- ✅ 弹性扩展:Doris 计算节点可独立扩缩容,存储不变。
- ✅ 秒级响应:MPP 引擎 + 列式存储,比 Hive 快 10~100 倍。
Doris + MinIO 不是简单的“数据库 + 文件系统”,而是一套完整的湖仓一体解决方案。它让企业能够:如果你正在构建数据平台,或者苦恼于 Hive 查询太慢、对象存储无法直接分析,不妨试试这套组合。从 Docker 安装 Doris 开始,到创建外部表查询 MinIO 上的 CSV,整个过程不到 10 分钟——这就是现代数据栈的魅力。让我们保持学习的热情,2026年一马当先、马到成功!





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
