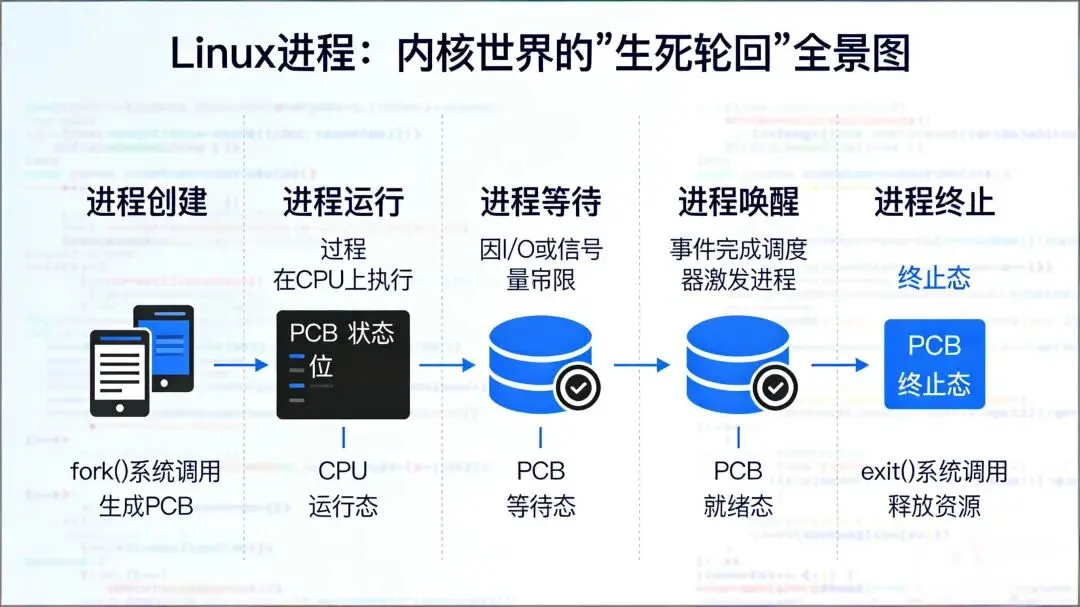
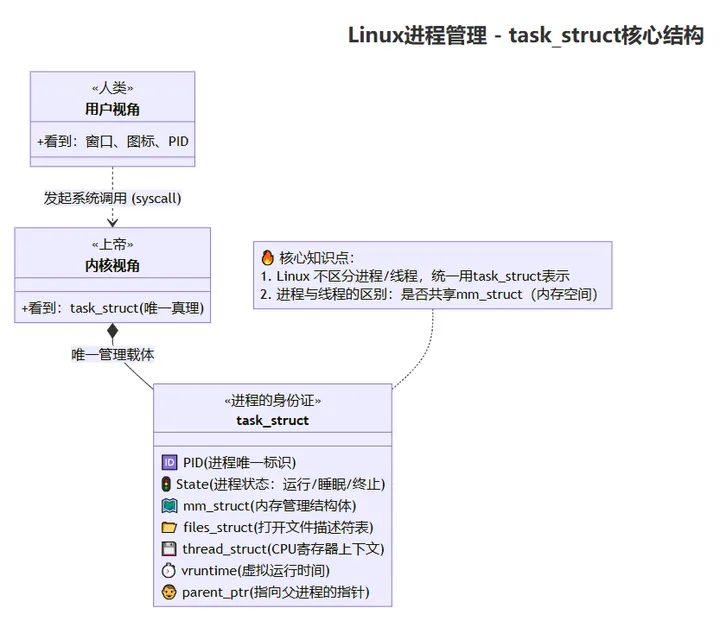
误区:进程 = 运行中的程序代码。 ✅ 真相:进程 = 一本账本 (task_struct) + 一堆资源。 内核根本不认识“程序”,它只认这本账本。
误区:fork 是把爸爸的家产(内存)全复制一份给儿子。 ✅ 真相:写时复制 (COW)。刚生出来时,父子共用家产,谁先动手改,才给谁分家。👨 父进程 (PID 100) 👶 子进程 (PID 101)
[页表 A] [页表 B]
| |
+----------+-----------+
⬇️ (指向同一物理页,标记 🔒只读)
[ 📄 物理内存:数据 "Hello"]
💰 成本:几乎为 0 (只复制了页表)
👶 子进程执行:data = "World"
⚡ CPU 发现页面是 🔒只读的 -> 抛出缺页异常 (Page Fault)
🛑 内核警察介入!
🛠️ 内核操作流:
1. 申请新物理页 🆕
2. 复制 "Hello" -> "Hello"
3. 修改新页内容为 "World"
4. 更新子进程页表 -> 指向新页
5. 解除锁 🔓
👨 父进程 👶 子进程
[页表 A] [页表 B]
| |
⬇️ ⬇️
[ 📄 物理页:"Hello"] [ 🆕 物理页:"World" ]
(原封不动) (独立修改)
爆款洞察:如果 fork 后立刻 exec (加载新程序),永远不会触发复制!这是 Linux 启动速度快的核心秘密。
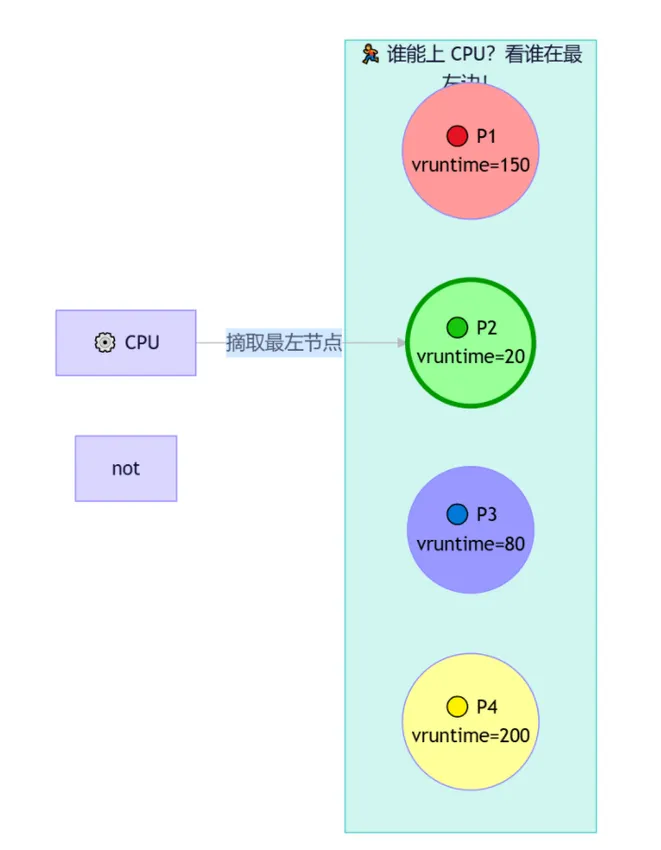
误区:大家轮流坐庄,每人固定跑 10ms (时间片)。 ✅ 真相:完全公平调度 (CFS)。谁最饿 (vruntime 最小),谁就先吃。公式:vruntime 增长速度 = 实际运行时间 / 权重
🐢 高优先级 (Nice -5) 🐇 低优先级 (Nice +5)
权重:大 (1.5) 权重:小 (0.6)
运行 10ms: 运行 10ms:
vruntime += 10 / 1.5 = 6.6 vruntime += 10 / 0.6 = 16.6
结果:
高优先级在树上长得慢 ➡️ 一直排在左边 ✅ (爽)
低优先级长得快 ➡️ 迅速被挤到右边 ❌ (饿)
误区:进程直接操作物理内存条。 ✅ 真相:每个进程都活在一个4GB/128TB 的幻觉中。物理内存由内核通过页表偷偷映射。🔝 0xFFFFFFFF (高地址)
┌─────────────────────┐
│ 🛡️ 内核空间 │ <-- 所有进程共享,用户态禁入 (违者 Segfault)
├─────────────────────┤
│ 📦 栈 (Stack) │ <-- 向下生长 (函数调用链)
│ ⬇️ │
│ ... │
│ ⬆️ │
│ 🏗️ 堆 (Heap) │ <-- 向上生长 (malloc/new)
│ │
├─────────────────────┤
│ 📚 共享库 (.so) │
├─────────────────────┤
│ 📄 BSS / Data │
├─────────────────────┤
│ 💻 代码段 (.text) │
└─────────────────────┘
🔻 0x00000000 (低地址)
💥 危险时刻:
如果 堆 ⬆️ 和 栈 ⬇️ 相遇 = Segmentation Fault (段错误)
深入点:mmap 区域可以动态插入中间,是高性能内存池的基石。
误区:进程只有“运行”和“停止”。 ✅ 真相:有一种状态叫**“想死死不了”** (D 状态),连 kill -9 都无效!stateDiagram-v2
[*] --> 创建 : fork/exec
state "🏃 RUNNING (R)"as R
state "💤 可中断睡眠 (S)"as S
state "💣 不可中断睡眠 (D)"as D
state "🛑 停止 (T)"as T
state "🧟 僵尸 (Z)"as Z
创建 --> R
R --> S : 等网络/键盘 (可被 kill)
R --> D : 等磁盘 I/O (🚫 信号无效!)
R --> T : 调试暂停
S --> R : 事件到达
D --> R : I/O 完成 (只能等硬件!)
T --> R : SIGCONT
R --> Z : exit() (灵魂出窍)
Z --> [*] : 父进程 wait() (超度)
note right of D
⚠️ **D 状态陷阱**
通常意味着:
1. 磁盘坏了
2. NFS 卡死
3. 驱动死锁
🚫 kill -9 对此无效!
end note
note right of Z
🧟 **僵尸危机**
内存已释放 ✅
PID 被占用 ❌
堆积过多 = 系统瘫痪
end note
误区:切换只是换个程序跑。 ✅ 真相:切换是性能杀手!因为它会清空 CPU 的“短期记忆” (Cache/TLB)。🕒 T1: 进程 A 正在爽
[ CPU 寄存器: EIP=100 ]
[ L1/L2 Cache: 装满 A 的数据 ] 🔥 热乎的
⚡ 切换信号 (中断/时间片到)
1️⃣ 存档:寄存器 -> A 的 task_struct
2️⃣ 换图:CR3 寄存器 -> B 的页表 (⚠️ TLB 瞬间清空!)
3️⃣ 读档:B 的 task_struct -> 寄存器
🕒 T2: 进程 B 开始跑
[ CPU 寄存器: EIP=800 ]
[ L1/L2 Cache: 全是空的 ] ❄️ 冰冷
💸 代价:
CPU 必须从慢速内存重新加载数据
一次切换 ≈ 几千个时钟周期 wasted!
优化铁律:高并发系统中,减少上下文切换比优化代码逻辑更重要!
剧本 A:孤儿进程 (Orphan) -> 幸福结局👨 父进程 --exit()--> 💀 死了
|
👶 子进程 (还在跑)
✅ 自动过继机制:
systemd/init (PID 1) 瞬间成为新爸爸
|__ 定期调用 wait() 清理
(系统非常稳健)
剧本 B:僵尸进程 (Zombie) -> 悲剧现场👶 子进程 --exit()--> 🧟 变成僵尸 (保留退出码)
|
👨 父进程 (在忙/写挂了/忘了 wait)
❌ 后果:
- 内存?已释放 ✅
-task_struct?还在占用 ❌
-PID?被占用了 ❌
💥 终极爆炸:
僵尸堆积 -> PID 耗尽 -> 无法创建新进程 -> 系统宕机
🔧 救援方案:
杀死父进程 (kill -9 父PID)
-> 子进程变孤儿 -> PID1 接手超度 -> 世界和平
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
