大家好,我是蟹老板~
很多人学 Linux 并发,喜欢从锁开始。
互斥锁、自旋锁、读写锁、RCU、原子操作、内存屏障,一路学下来,脑子里全是 API,全是概念,全是“这个场景用那个锁更好”。
但真到线上出问题的时候呢?
CPU 飙高,锁竞争严重,线程莫名其妙抖动,网络中断全打到一个核上,perf 看一堆 cache miss,top 看着每个 CPU 都挺忙,可吞吐就是上不去。
这时候你会发现,光会用锁,不够。
真的不够。
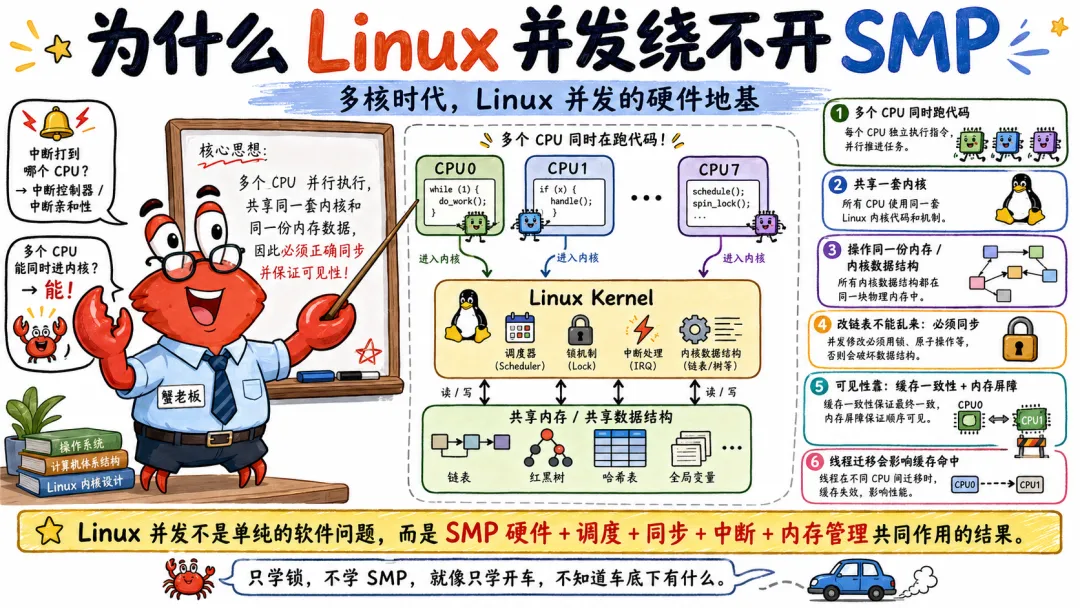
因为 Linux 并发的底层,不是从 pthread_mutex_lock() 开始的,也不是从 spin_lock() 开始的。它真正绕不开的东西,是 SMP,也就是对称多处理架构。
你不懂 SMP,就很难真正懂 Linux 并发。
不是说你不能写代码,能写,还能写得挺快。但一到性能、一到多核、一到内核同步、一到中断和调度,你就会像在雾里开车,方向盘握得很紧,心里没底。
今天的这篇文章会有点长(万字预警),别心急,认真看,SMP 真的不是简单几句就能讲明白的东西。
一、什么是 SMP
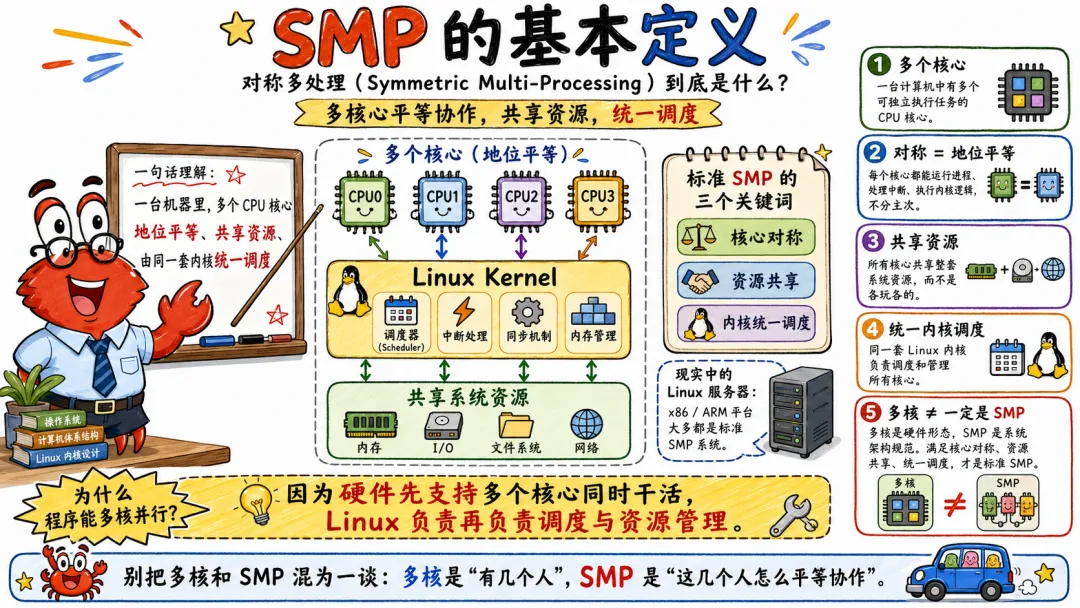
SMP 的全称是 Symmetric Multiprocessing,中文一般叫对称多处理。
简单说,SMP 就是一台机器里有多个处理器,或者多个 CPU 核心,它们地位平等,共享同一块内存和 I/O 资源,运行同一个操作系统实例,并且都可以执行内核代码和用户进程。
1.1 SMP 的基本定义
最传统的 SMP 系统有几个特征。
多个 CPU 共享同一个主存地址空间。
所有 CPU 都可以访问 I/O 设备。
所有 CPU 都由同一个操作系统统一管理。
从软件视角看,每个 CPU 都能运行同样的内核代码。
系统里没有哪个 CPU 天生只负责“打杂”,也没有哪个 CPU 天生只能跑某一种任务。
这就是所谓的对称。
注意,这里的 CPU 可以是物理处理器,也可以是现代处理器里的核心。很多文章会把 processor、core、CPU 混着叫,容易把新人绕晕。
在 Linux 里,我们经常说的 CPU,更偏向逻辑 CPU。
比如一颗 8 核 16 线程的处理器,在 Linux 里可能会看到 16 个 logical CPU。你 top 里按下 1,看到的就是这些逻辑 CPU 的使用情况。
lscpuArchitecture: x86_64CPU(s): 16Thread(s) per core: 2Core(s) per socket: 8Socket(s): 1NUMA node(s): 1
这里的 CPU(s) 不一定等于物理核数。它可能包含 SMT,也就是超线程。
但从 Linux 调度器角度看,它们都是可以调度任务的执行单元。只不过调度器知道它们之间有拓扑关系,有的共享 L1/L2,有的共享 L3,有的跨 NUMA 节点,调度成本不一样。
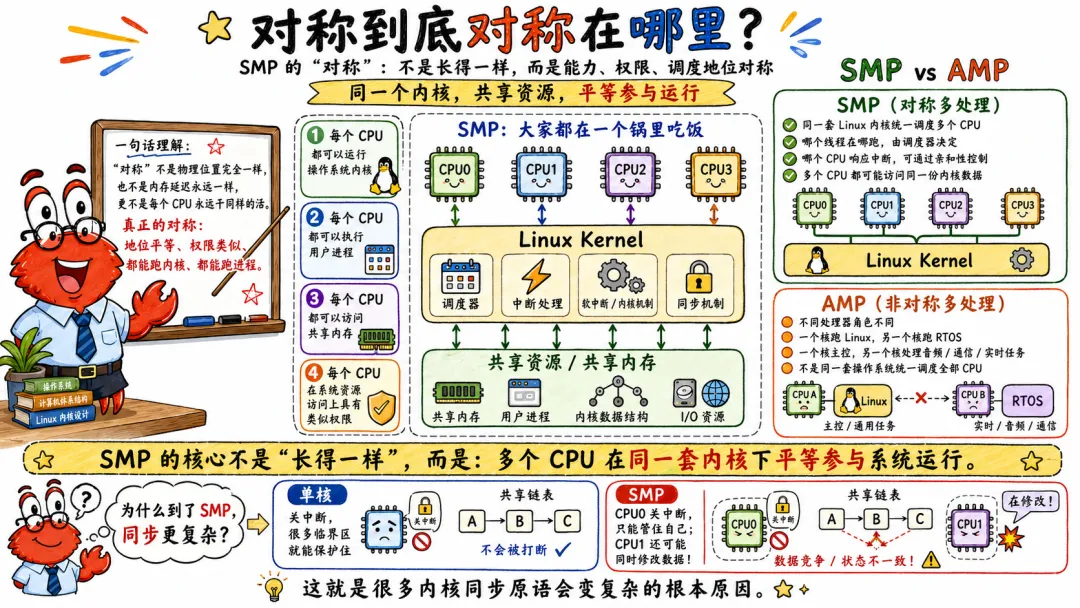
1.2 对称到底对称在哪里?
“对称”这个词很容易让人误会,它不是说每个 CPU 的物理位置完全一样,也不是说每个 CPU 访问内存的延迟完全一样,更不是说每个 CPU 永远干同样的活。
在经典 SMP 里,对称主要体现在几个层面。
每个 CPU 都可以运行操作系统内核。
每个 CPU 都可以执行用户进程。
每个 CPU 都可以访问共享内存。
每个 CPU 在系统资源访问上具有类似权限。
和它相对的是 AMP,非对称多处理。AMP 里不同处理器的角色往往不一样。比如一个核跑 Linux,另一个核跑 RTOS;一个核负责主控,另一个核专门处理音频、通信或者实时任务。它们不是一套操作系统统一调度所有 CPU。
SMP 则是大家都在一个锅里吃饭。
这句话听着土,但很准确。
同一个 Linux 内核,管理多个 CPU。哪个线程去哪跑,由调度器决定。哪个 CPU 响应中断,可以通过亲和性控制。哪个 CPU 处理软中断,也受内核机制影响。内核数据结构大家都可能访问,所以必须小心同步。
这也是 SMP 麻烦的地方。
单核时代,很多问题根本不存在。因为同一时刻只有一个执行流真正跑。你关中断,就能保护很多临界区。到了 SMP,CPU0 关中断,只能管住 CPU0 自己。CPU1 还在跑呢,它照样可能来改你的数据结构。
这就是很多内核同步原语变复杂的原因。
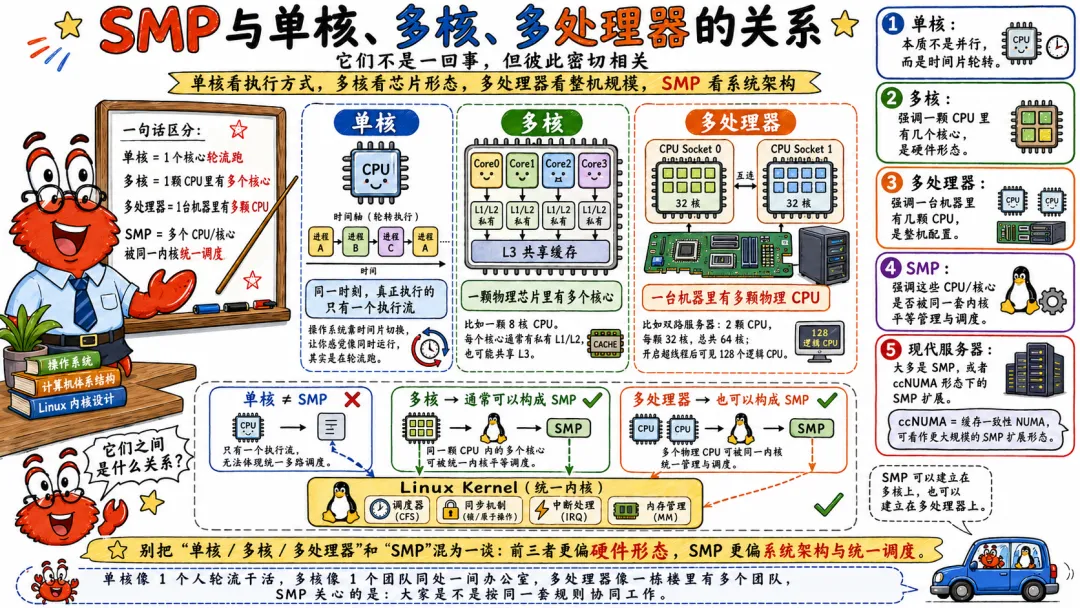
1.3 SMP 与单核、多核、多处理器的关系
单核很好理解,一个 CPU 核心,同一时刻只有一个执行流真正执行。操作系统通过时间片切换,让你觉得多个进程在同时运行。其实是在轮流跑。
多核指一颗物理芯片里有多个核心。比如一颗 8 核 CPU。每个核心都有自己的执行单元,通常有私有 L1/L2 缓存,也可能共享 L3 缓存。
多处理器指一台机器里有多颗物理 CPU socket。比如双路服务器,两颗 CPU,每颗 32 核,加起来 64 核,开超线程后 128 个逻辑 CPU。
SMP 可以建立在多核上,也可以建立在多处理器上。
所以关系大致是这样:
单核不是 SMP。
多核通常可以构成 SMP。
多处理器也可以构成 SMP。
现代服务器大多是 SMP 或者 ccNUMA 形态下的 SMP 扩展。
为什么要强调这个?
因为 很多人嘴上说多核,其实脑子里还是单核模型。写代码的时候默认“我改了变量别人马上看到”,“加线程就一定更快”,“锁只要保护住数据就完事”。
结果被硬件现实打脸,多核不只是多个单核复制粘贴那么简单。多个核心之间有缓存,有互联,有一致性协议,有访问延迟差异。Linux 内核必须把这些东西都考虑进去。
二、SMP 硬件架构基础
要理解 Linux 在 SMP 上干了什么,先得看硬件长什么样。
不用变成硬件专家,但基本结构要有了解。
我见过不少人分析性能,上来就是改线程池大小、改锁、改队列。问他机器拓扑,他一脸茫然。问他几个 NUMA 节点,他说“不都是内存吗”。问他中断落在哪个 CPU,他说“这也能控制?”
能啊。不但能控制,而且有时候就是性能差异的关键。
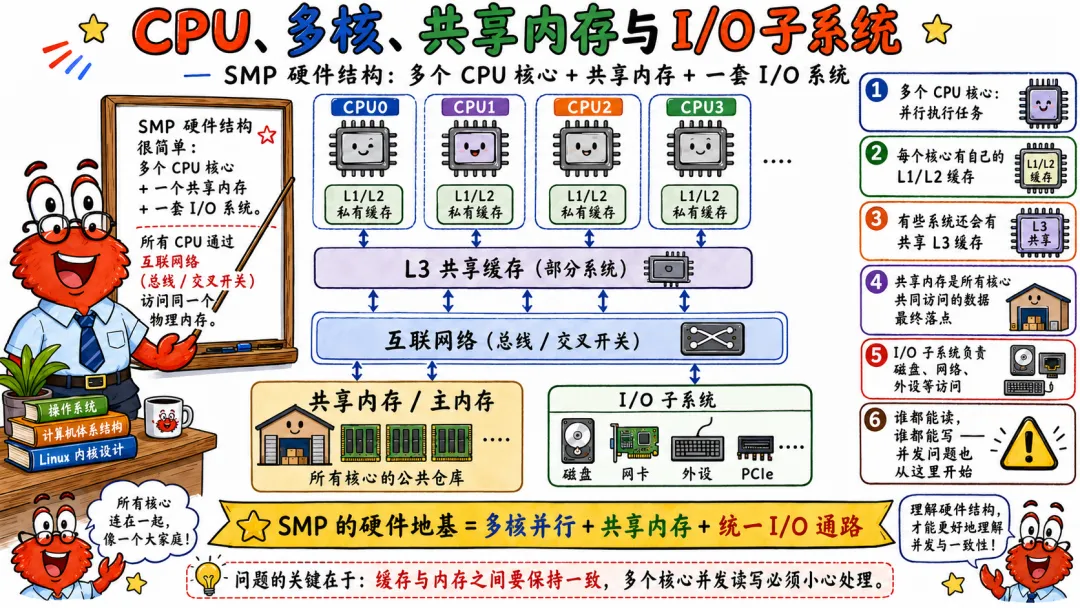
2.1 CPU 多核 共享内存与 I/O 子系统
一个 SMP 系统里,CPU 是执行代码的地方。
每个 CPU 核心有寄存器、执行单元、流水线、私有缓存。多个核心通过某种互联结构连接到共享缓存、内存控制器、I/O 控制器。
内存是共享的。
共享内存意味着所有 CPU 看到的是同一个物理地址空间。CPU0 写地址 0x1000,CPU1 也可以读地址 0x1000。当然,它什么时候看到新值,要经过缓存一致性和内存顺序保证。
I/O 子系统负责外设,比如磁盘、网卡、GPU、USB 控制器。外设通过中断通知 CPU,通过 DMA 读写内存。
这句话里面其实已经埋了很多坑。
网卡收包,不是 CPU 一字节一字节从网卡搬到内存。通常是网卡 DMA 到内存,然后发中断告诉 CPU,有包到了。CPU 再跑驱动、软中断、协议栈。
那中断给哪个 CPU?
DMA 写的内存在哪个 NUMA 节点?
协议栈处理线程跑在哪个 CPU?
应用线程又跑在哪个 CPU?
你看,一个网络包从网卡进来,已经跟 SMP 拧在一起了。不是你写个 epoll 就完事了。
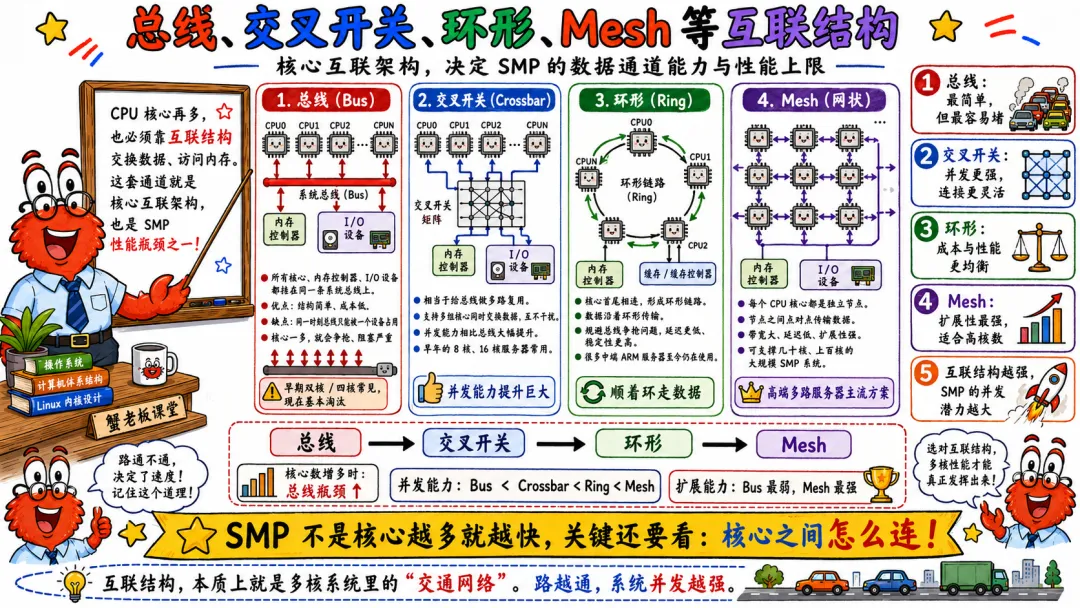
2.2 总线 交叉开关 环形 Mesh 等互联结构
早期 SMP 系统比较简单,多个 CPU 挂在同一条总线上,共享内存也接在总线上。
这种模型好理解,但扩展性差。
CPU 少的时候还行。CPU 一多,总线就成瓶颈。所有 CPU 都要通过一条路访问内存、同步缓存、通信,谁都想抢,谁都嫌慢。
后来出现了更复杂的互联结构。
交叉开关可以让多个节点之间并行通信,扩展性比单总线强。
环形互联常见于一些多核芯片内部。核心、缓存、内存控制器像站点一样挂在环上,数据沿着环传。
Mesh 互联更适合核心数量更多的处理器。核心像网格节点一样连接,数据在网格里路由。
还有很多厂商自己的互联技术。名字各不一样,本质都是为了解决一个问题。
CPU 多了以后,怎么让它们高效访问缓存、内存和 I/O。
这事儿很难。
因为多核系统的性能瓶颈,很多时候不在“CPU 会不会算”,而在“数据能不能及时到 CPU 手里”。
算得速度快也没用,数据在路上堵着,CPU 就只能等。
所以 现代 CPU 设计里,缓存层次、片上互联、内存控制器、预取、一致性协议,全都很关键。软件调优如果完全无视这些,最多调个寂寞。
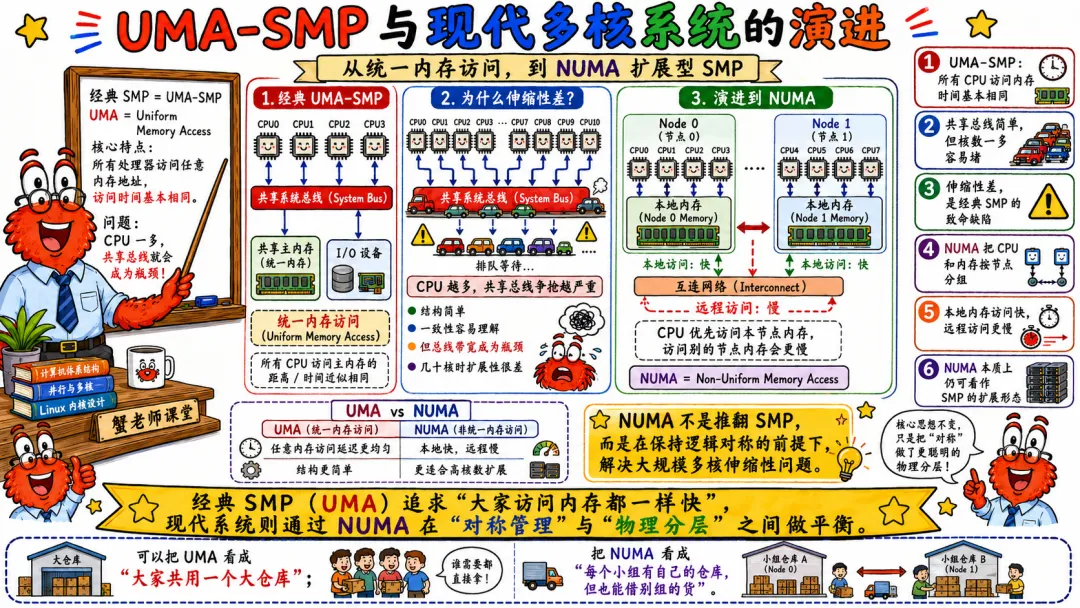
2.3 UMA-SMP 与现代多核系统的演进
UMA 是 Uniform Memory Access,统一内存访问。
在 UMA-SMP 模型里,所有 CPU 访问任意内存位置的延迟大致相同。经典 SMP 就经常和 UMA 放在一起讲。
这个模型简单,适合理解基本概念。
但现代服务器早就复杂多了。
双路、四路服务器里,每颗 CPU socket 往往有自己的本地内存控制器和本地内存。CPU 访问本地内存快,访问另一颗 CPU 挂着的远程内存慢。
这就是 NUMA。
NUMA 不是完全推翻 SMP。很多时候现代 Linux 运行在 ccNUMA 机器上,它仍然是一个统一的操作系统实例,所有 CPU 共享地址空间,缓存一致性仍然存在。只是内存访问不再“均匀”。
这也是为什么很多人说现代 SMP 更准确地讲是 ccNUMA。
cc 是 cache coherent,缓存一致。
也就是说,系统仍然维护缓存一致性,但内存访问有远近之分。
你可以这样理解。
传统 UMA-SMP 像一个办公室,大家用同一个公共资料柜,谁去拿资料路程差不多。
NUMA 像一个大公司有多个楼层。每层都有自己的资料柜。你拿自己楼层的资料很快,跑到别的楼层拿就慢。公司规定资料内容要保持一致,但你来回跑楼梯的成本没人替你消失。
Linux 调度器、内存管理、NUMA balancing、CPU affinity、内存绑定,都是在处理这类现实问题。
所以 别再把“共享内存”理解成“访问成本一样”。
真的不一样。
三、SMP 的核心运行机制
SMP 的核心不是多个 CPU 摆在那里,摆在那里没用。
关键是多个 CPU 怎么一起跑同一个系统,怎么共享内核,怎么访问全局数据,怎么处理并发冲突。
这部分是理解所有并发逻辑的核心。
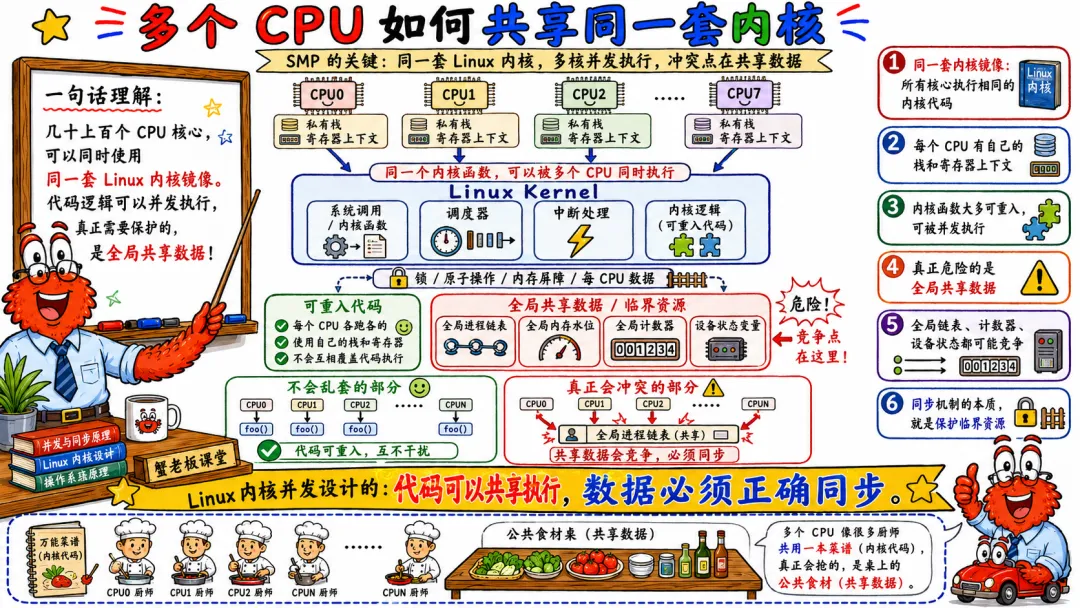
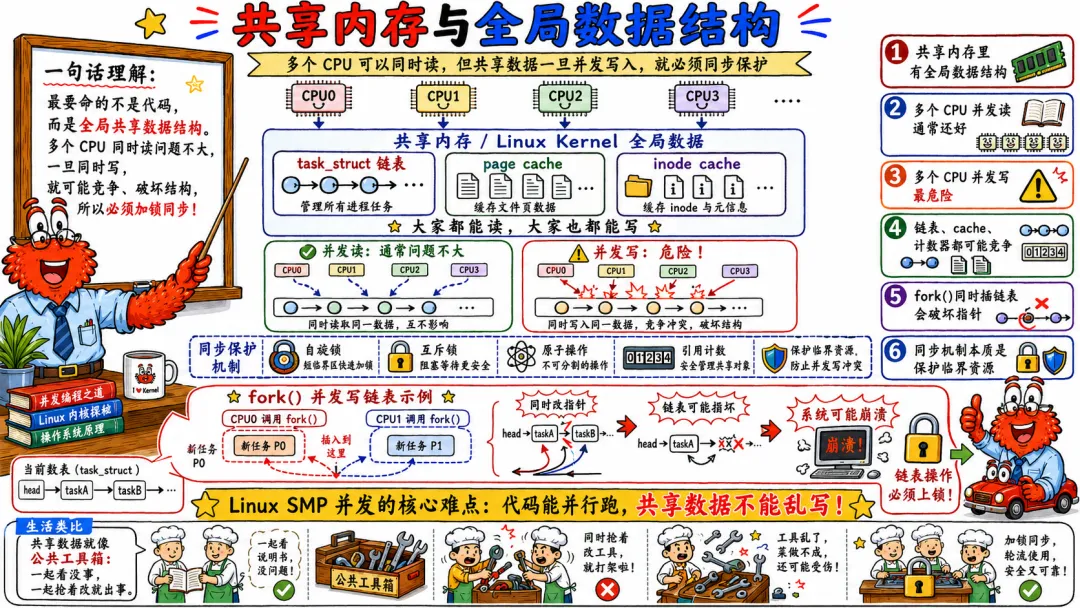
3.1 多个 CPU 如何共享同一套内核
Linux 内核会被加载到内存里。每个 CPU 都可以进入内核态执行内核代码。
用户进程在 CPU0 上执行系统调用,CPU0 进入内核。
另一个用户进程在 CPU1 上执行网络收包相关系统调用,CPU1 也进入内核。
这两个 CPU 执行的可能是同一份内核代码,只是执行路径不同,栈不同,当前任务不同。
代码可以共享。
数据不能乱共享。
内核代码段通常是只读的,多 CPU 并发执行没问题。真正麻烦的是内核数据结构。
比如进程调度队列、文件描述符表、页表、inode、dentry、socket buffer、网络队列、slab 分配器、定时器队列。
这些数据可能被多个 CPU 同时访问。
如果没有同步,就会炸。
一个经典例子是链表。
CPU0 正在删除链表节点,CPU1 正在遍历同一个链表。没有锁,没有 RCU,没有引用计数,结果可能就是 CPU1 读到了已经释放的节点。轻则数据错,重则内核崩。
用户态也一样。
两个线程同时修改同一个全局变量,C 语言层面就是数据竞争。你以为是 count++,汇编层面可能是读、加、写三个步骤。两个 CPU 同时做,结果很容易丢更新。
// 这段代码在多线程下不安全static int counter = 0;void *worker(void *arg){ for (int i = 0; i < 1000000; i++) { counter++; } return NULL;}
counter++ 看着像一个动作,实际上不是。
它可能被拆成类似这样。
mov eax, [counter]add eax, 1mov [counter], eax
CPU0 读到 100。
CPU1 也读到 100。
CPU0 写回 101。
CPU1 也写回 101。
两次加法,结果只加了一次。
这不是编译器坏,也不是 CPU 调皮。是你写的程序没有告诉系统“这里需要同步”。
3.2 共享内存与全局数据结构
SMP 最大的方便是共享内存。
线程之间通信很容易。一个线程写内存,另一个线程读内存。进程之间也可以通过共享内存通信。内核各子系统也可以访问全局结构。
但方便背后是代价。
共享内存意味着共享状态。
共享状态意味着竞争。
竞争意味着同步。
同步意味着开销。
开销意味着性能问题。
这条链路很残酷,但非常真实。
Linux 内核为了减少共享状态带来的问题,做了大量设计。
能拆分的全局锁,就拆成细粒度锁。
能每 CPU 一份的数据,就用 per-CPU 变量。
读多写少的路径,用 RCU。
计数器高频更新,就做 percpu counter 或者分片。
内存分配器做每 CPU 缓存。
调度器每个 CPU 有自己的 runqueue。
网络协议栈也尽量让收包、软中断、应用消费在同一个 CPU 或同一个 NUMA 节点附近完成。
这些都是被 SMP 逼出来的。
全局共享数据在单核时代很爽,在多核时代就是性能炸药桶。
我以前写过一个统计模块,所有请求结束后都更新一个全局结构。压测时 QPS 一上来,锁竞争把 CPU 干得满头包。后来改成每线程本地统计,定期聚合,吞吐直接舒服了。
那时候才明白,“共享”这两个字看着温柔,其实挺凶。
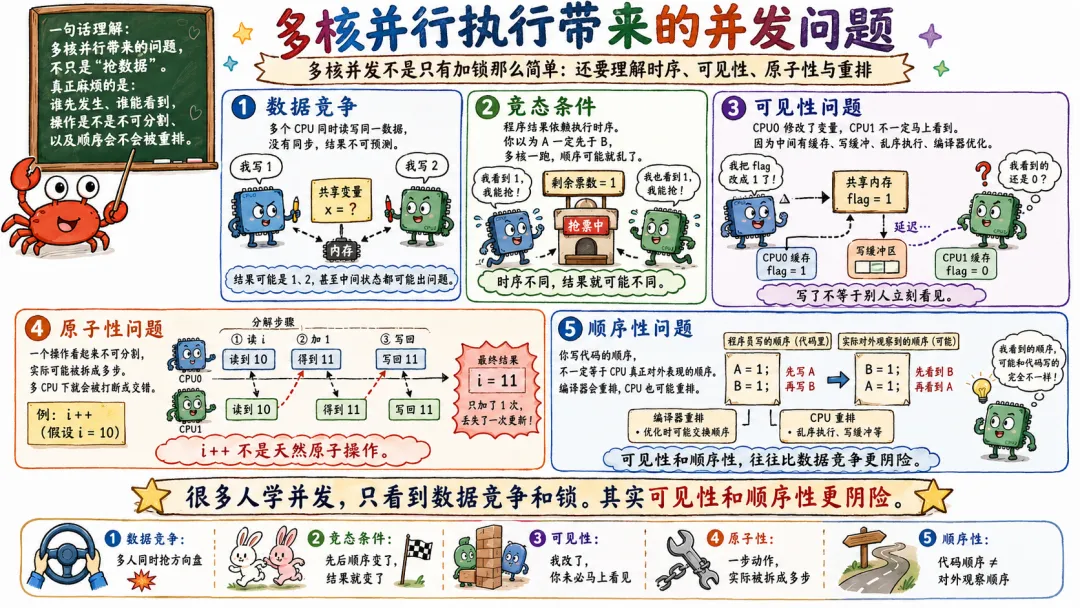
3.3 多核并行执行带来的并发问题
多核并行带来的问题,大概可以分几类。
数据竞争。
多个 CPU 同时读写同一数据,没有同步,结果不可预测。
竞态条件。
程序结果依赖执行时序。你以为 A 一定在 B 前面发生,实际多核一跑,顺序就乱了。
可见性问题。
CPU0 修改了变量,CPU1 不一定马上看到。因为中间有缓存、写缓冲、乱序执行、编译器优化。
原子性问题。
一个操作看起来不可分割,实际可能被拆成多步。多 CPU 下就会被打断或交错。
顺序性问题。
你写代码的顺序,不一定等于 CPU 真正对外表现的顺序。编译器会重排,CPU 也可能重排。
很多人学并发,只看到数据竞争和锁。其实可见性和顺序性更阴险。
比如一个典型的 flag 通知。
int data = 0;int ready = 0;// CPU0data = 42;ready = 1;// CPU1while (!ready) ;printf("%d\n", data);
你以为 CPU1 看到 ready == 1 后,就一定看到 data == 42。
在某些体系结构和编译器优化下,这个假设不一定稳。你需要合适的原子操作和内存屏障来表达 happens-before 关系。
在 x86 上你可能很多时候“碰巧没出事”,然后误以为天下太平。换到 ARM、RISC-V,或者编译器优化一上来,就开始做人了。
这也是为什么 Linux 内核里有大量 smp_mb()、smp_rmb()、smp_wmb()、READ_ONCE()、WRITE_ONCE()、cmpxchg()、atomic_*()。
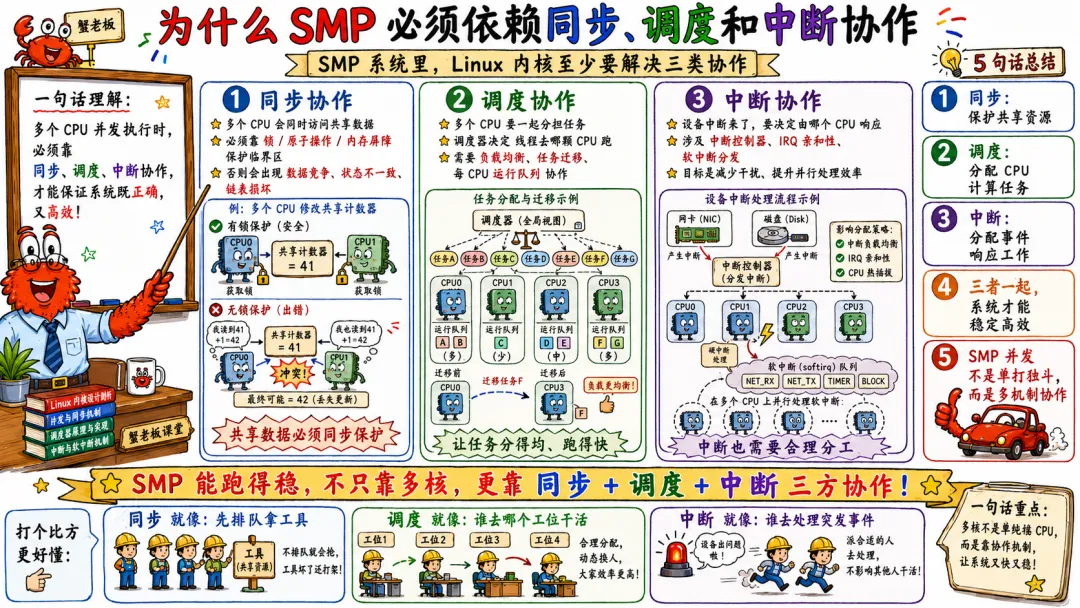
3.4 为什么 SMP 必须依赖同步 调度和中断协作
SMP 系统里,Linux 内核至少要解决三类协作。
同步协作。
多个 CPU 访问共享数据时,必须有锁、原子操作、RCU、内存屏障等机制保证正确性。
调度协作。
多个 CPU 都能跑任务。调度器要决定任务放在哪个 CPU,什么时候迁移,如何负载均衡,如何利用缓存局部性,如何处理 CPU 拓扑。
中断协作。
外设中断不能乱打。中断分发、软中断处理、IPI 通知、TLB shootdown,都需要 CPU 之间协作。
这三类东西纠缠在一起。
比如一个线程被唤醒,可能需要从 CPU0 唤醒 CPU3。怎么通知 CPU3?可能用 IPI。
比如一个 CPU 修改了某个进程的页表,其他 CPU 正在运行这个进程。它们的 TLB 里可能还缓存着旧映射。怎么办?发 IPI,让它们刷 TLB。
比如网卡中断都落在 CPU0,CPU0 忙死,其他 CPU 闲着。怎么办?调中断亲和性,配合 RPS/XPS、队列绑定、应用线程亲和性。
这些问题不理解 SMP,就很难看懂。
你会觉得 Linux 内核里很多机制“怎么这么麻烦”。
它不是故意复杂,它是在多 CPU 现实里活下来的结果。
四、SMP 最核心难点是缓存一致性
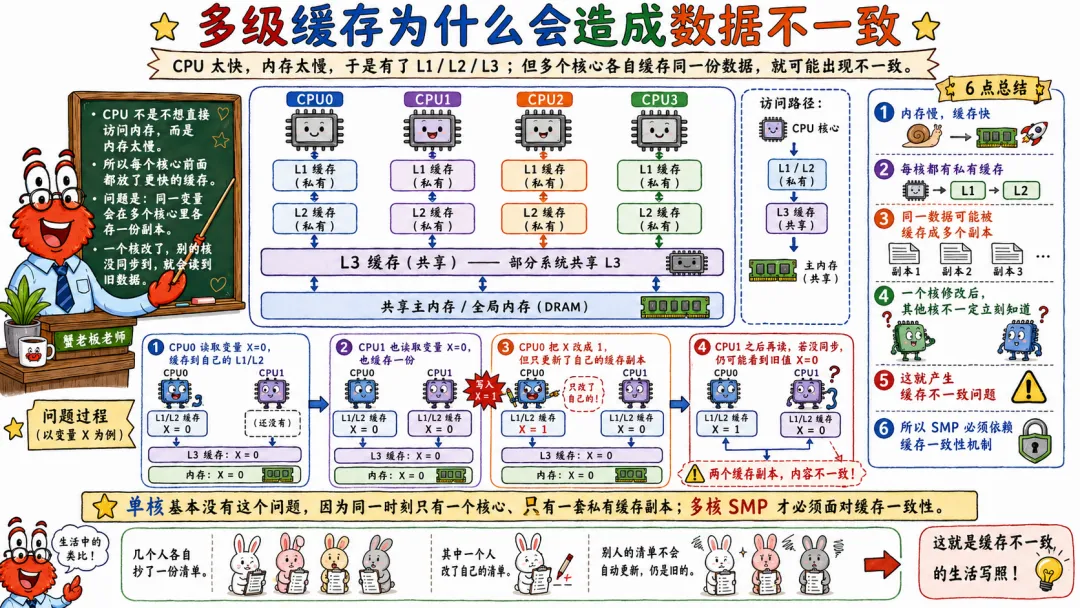
SMP 里最难、最容易被低估的东西,就是缓存一致性,这也是90%的Linux并发性能问题的根源。
很多人以为多核共享内存就是多个 CPU 直接读写同一块内存。
想得太美了。
如果 CPU 每次读写都去访问主内存,性能会慢到怀疑人生。CPU 比内存快太多了,所以每个核心都有缓存。
L1 很快,L2 也快,L3 稍慢但还是比内存快。CPU 大部分时间希望数据在缓存里解决,别老去内存拿。
问题就来了。
多个 CPU 各自有缓存。它们缓存了同一个内存地址的数据。CPU0 改了自己的缓存,CPU1 缓存里的旧数据怎么办?
这就是缓存一致性问题。
4.1 多级缓存为什么会造成数据不一致
假设内存里有个变量 x = 0。
CPU0 读取 x,把它加载到自己的缓存。
CPU1 也读取 x,也加载到自己的缓存。
现在 CPU0 把 x 改成 1。
如果没有一致性机制,CPU1 缓存里还是 0。它再读 x,就读到旧值。
这就乱套了。
所以 硬件需要缓存一致性协议,保证多个 CPU 对同一内存位置的缓存副本,在一定规则下保持一致。
注意,是“一定规则下”。
缓存一致性解决的是同一个缓存行的数据一致性问题,但它不等于完整的程序顺序保证。内存屏障、原子操作、编译器约束还得上场。
这点特别容易混。
缓存一致性告诉你,大家最终别拿着同一个地址的矛盾副本各玩各的。
内存模型告诉你,读写操作在多 CPU 之间以什么顺序被观察到。
原子操作告诉你,某些读改写操作不能被打断,且通常还带有特定内存序语义。
这三个东西有关系,但不是一个东西。
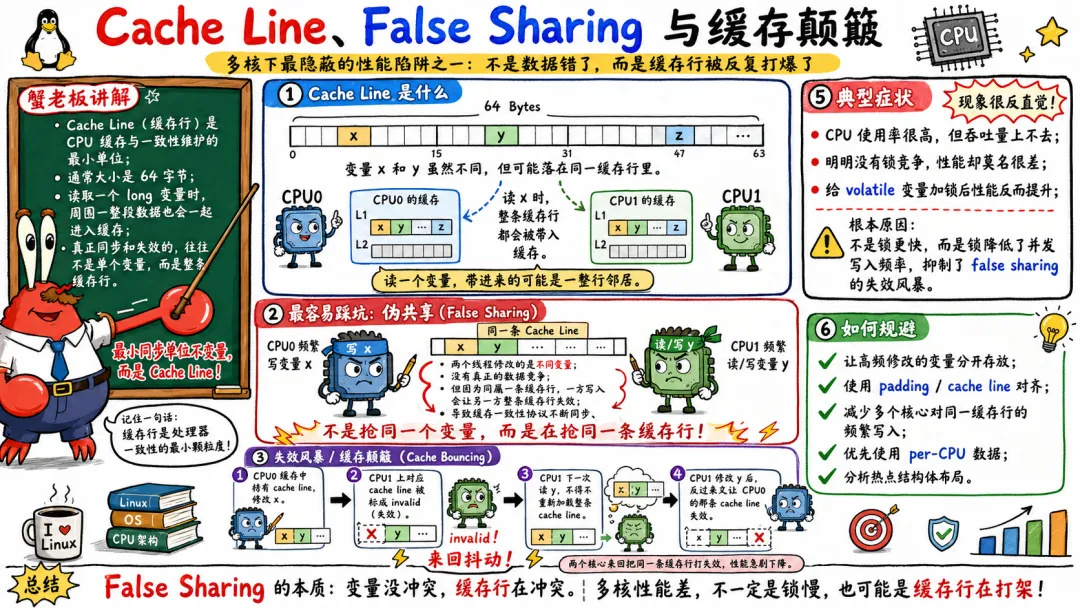
4.2 Cache Line False Sharing 与缓存颠簸
缓存不是按字节管理的。
它通常按 Cache Line,也就是缓存行,来搬运和维护。常见缓存行大小是 64 字节。
这意味着什么?
你访问一个 int,CPU 可能把它所在的 64 字节整行都加载进缓存。
这本来是好事。空间局部性嘛。
但在多核下,缓存行也是一致性协议的基本单位。两个变量只要落在同一个缓存行,即使它们逻辑上毫无关系,也可能互相影响。
这就是 False Sharing,伪共享。
看一段代码。
#include <pthread.h>#include <stdint.h>#include <stdio.h>struct counters { volatile long a; volatile long b;};struct counters c;void *worker1(void *arg){ for (long i = 0; i < 100000000; i++) { c.a++; } return NULL;}void *worker2(void *arg){ for (long i = 0; i < 100000000; i++) { c.b++; } return NULL;}
两个线程分别更新 a 和 b。
看起来没共享数据,对吧?
但如果 a 和 b 在同一个缓存行里,CPU0 更新 a,会让这个缓存行在 CPU0 上变成独占或修改状态。CPU1 更新 b,又要把同一缓存行抢过去。
两个 CPU 没有争同一个变量,却在争同一个缓存行。
这就叫伪共享。
优化方式也简单粗暴,把它们隔开。
#define CACHELINE_SIZE 64struct counters { volatile long a; char pad1[CACHELINE_SIZE - sizeof(long)]; volatile long b; char pad2[CACHELINE_SIZE - sizeof(long)];};
当然,真实项目里别这么野蛮硬写,最好结合编译器对齐属性。
struct counter { volatile long value;} __attribute__((aligned(64)));struct counters {struct counter a;struct counter b;};
Linux 内核里也经常看到缓存行对齐相关的宏,比如 ____cacheline_aligned。
这不是洁癖。
这是性能问题。
我有次排查一个内存队列性能问题,锁也拆了,线程也绑了,还是不稳。后来用 perf 看 cache miss,再看结构体布局,发现生产者和消费者分别写的字段挤在同一个缓存行里。改完以后,性能曲线立刻平了不少。
当时心情很复杂。一方面爽,一方面想骂自己。就这?就这玩意儿折腾我两天?真的绝了。
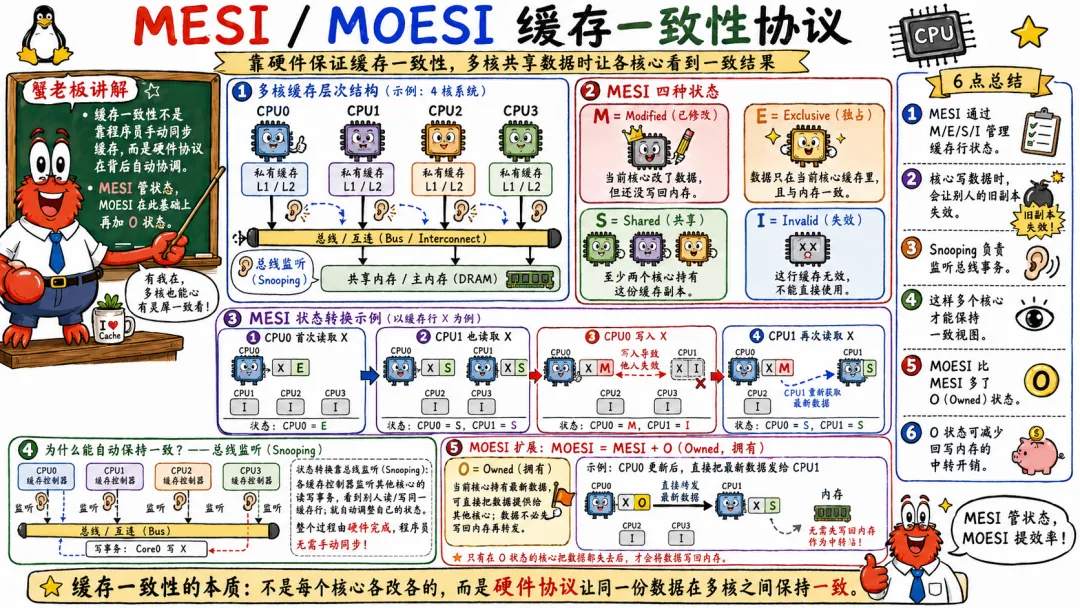
4.3 MESI 和 MOESI 缓存一致性协议
缓存一致性协议有很多种,最常见的入门模型是 MESI。
MESI 四个字母分别表示四种状态。
Modified 表示缓存行被当前 CPU 修改过,和内存不一致,其他 CPU 没有有效副本。
Exclusive 表示缓存行只在当前 CPU 缓存中,和内存一致。
Shared 表示缓存行可能被多个 CPU 共享,和内存一致。
Invalid 表示缓存行无效,不能直接使用。
举个简单例子。
CPU0 读 x,发现没人缓存这个数据,于是拿到 Exclusive 状态。
CPU1 也读 x,CPU0 和 CPU1 的缓存行都变成 Shared。
CPU0 想写 x,它必须先让其他 CPU 的副本失效,然后自己变成 Modified。
CPU1 再想读 x,发现自己的缓存行 Invalid,需要重新获取最新数据。
这背后会发生总线嗅探、目录协议、无效化消息、缓存行转移等动作。不同架构实现不一样,但核心矛盾一样。
写共享数据很贵。
尤其是多个 CPU 频繁写同一个缓存行时,非常贵。
MOESI 比 MESI 多了一个 Owned 状态,用来优化某些共享修改场景。Owned 表示当前缓存持有最新数据,但内存可能是旧的,其他 CPU 可以有共享副本。它允许缓存之间直接提供数据,减少一些写回内存的成本。
你不一定要把状态机背下来。除非你搞硬件或写非常底层的性能分析。
但你必须记住几句话。
读共享数据相对便宜。
多 CPU 写同一个缓存行很贵。
写会导致其他 CPU 缓存失效。
缓存行在 CPU 之间来回迁移,会造成缓存颠簸。
False Sharing 的本质是不同变量误伤同一缓存行。
这些比背 MESI 状态更有用。
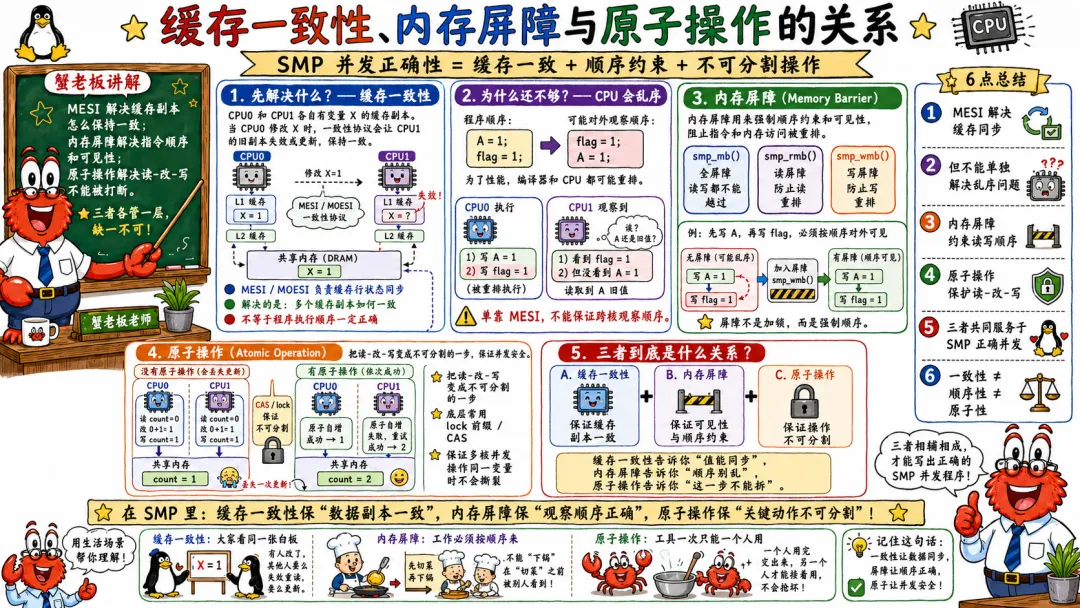
4.4 缓存一致性 内存屏障与原子操作的关系
很多人把缓存一致性和内存屏障混在一起。
这块必须掰开讲。
缓存一致性保证同一个内存位置的多个缓存副本不会永久矛盾。比如 CPU0 写了 x,CPU1 以后读 x,不能永远读旧值。
但它不保证你的多个内存操作按照源代码顺序被其他 CPU 观察到。
比如。
data = 42;flag = 1;
你希望别的 CPU 看到 flag == 1 时,一定能看到 data == 42。
这需要内存顺序保证。
编译器可能重排。CPU 也可能通过 store buffer、乱序执行等机制改变对外可见顺序。不同架构内存模型强弱不一样,x86 相对强,ARM 更弱。
内存屏障就是用来约束顺序的。
在 Linux 内核里,常见屏障包括。
smp_mb(); // 读写全屏障smp_rmb(); // 读屏障smp_wmb(); // 写屏障
还有配合原子变量使用的 acquire/release 语义。
用户态 C/C++ 里则可以用 C11 原子。
#include <stdatomic.h>atomic_int ready;int data;void writer(void){ data = 42; atomic_store_explicit(&ready, 1, memory_order_release);}void reader(void){ while (atomic_load_explicit(&ready, memory_order_acquire) == 0) ; printf("%d\n", data);}
release 保证它前面的写,在语义上不会跑到它后面。
acquire 保证它后面的读写,不会跑到它前面。
这对“发布数据,然后通知别人”这种模式很重要。
原子操作解决的是另一个问题。
比如 atomic_fetch_add() 可以保证多个 CPU 同时加同一个计数器时,不丢更新。硬件上通常会涉及锁总线、缓存锁定或者基于缓存一致性协议的原子读改写。
atomic_long counter;void inc(void){ atomic_fetch_add_explicit(&counter, 1, memory_order_relaxed);}
这里用了 memory_order_relaxed,意思是只需要原子性,不需要额外顺序保证。
这个细节挺关键。
不是所有原子操作都必须带强内存序。强内存序更安全,也可能更贵。你要表达真实需求,不要瞎上最重的锤子。
在 Linux 内核里也是同理。原子操作、锁、屏障、RCU,各自解决的问题不同。
自旋锁通常既提供互斥,也提供必要的内存顺序语义。
RCU 让读路径低成本,但更新和回收需要严格规则。
屏障不提供互斥,它只是约束顺序。
缓存一致性是硬件地基,不是并发万能药。
你看,绕一圈又回来了。
SMP 并发难,就难在这些东西都缠在一起。
4.5 缓存一致性带来的性能损耗
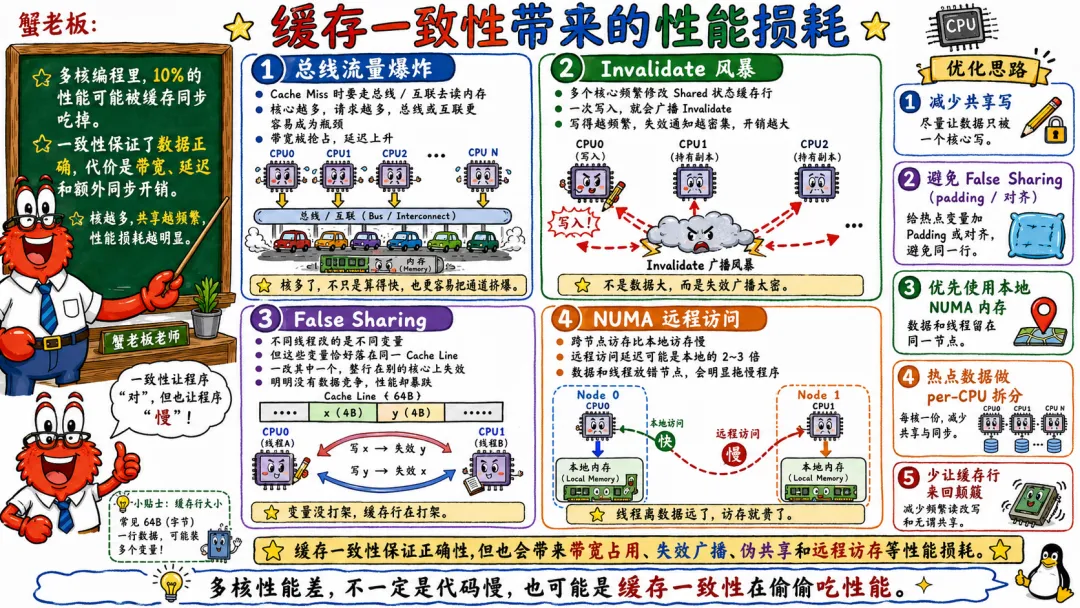
缓存一致性不是免费的,多核编程里10%的性能可能被缓存同步吃掉。
它需要 CPU 之间传递一致性消息,需要让缓存行失效,需要等待其他核心响应,需要处理缓存行迁移。
当共享写很多时,这些成本会非常明显。
最典型的几个场景。
多个线程更新同一个全局计数器。
多个 CPU 竞争同一把自旋锁。
生产者消费者频繁写同一个队列头尾字段,且字段布局不好。
多个线程写相邻变量导致 false sharing。
频繁唤醒、迁移任务,缓存局部性被打碎。
全局引用计数过热。
性能表现可能是 CPU 使用率很高,但业务吞吐不涨。perf 里 cache miss、LLC load miss、remote HITM 一类指标很难看。锁竞争统计也可能很高。
有时你看代码,感觉每一步都没问题。
但 CPU 实际在干什么?
它在等缓存行。
它在抢所有权。
它在处理一致性消息。
它在多核之间搬来搬去。
这也是为什么高性能系统喜欢减少共享写。
能分片就分片。
能本地化就本地化。
能批量就批量。
能 per-CPU 就 per-CPU。
能读多写少走 RCU,就别一上来全局大锁。
别迷信“多线程一定更快”。多线程是把刀,不是许愿池。
五、Linux 内核如何支持 SMP
Linux 支持 SMP,不是简单把单核内核复制几份。
它在启动、CPU 拓扑、调度、中断、同步、内存管理里都做了大量工作。
这一章节是整篇文章的硬菜,也是面试高频、线上调优核心,把理论转化为落地能力的关键。
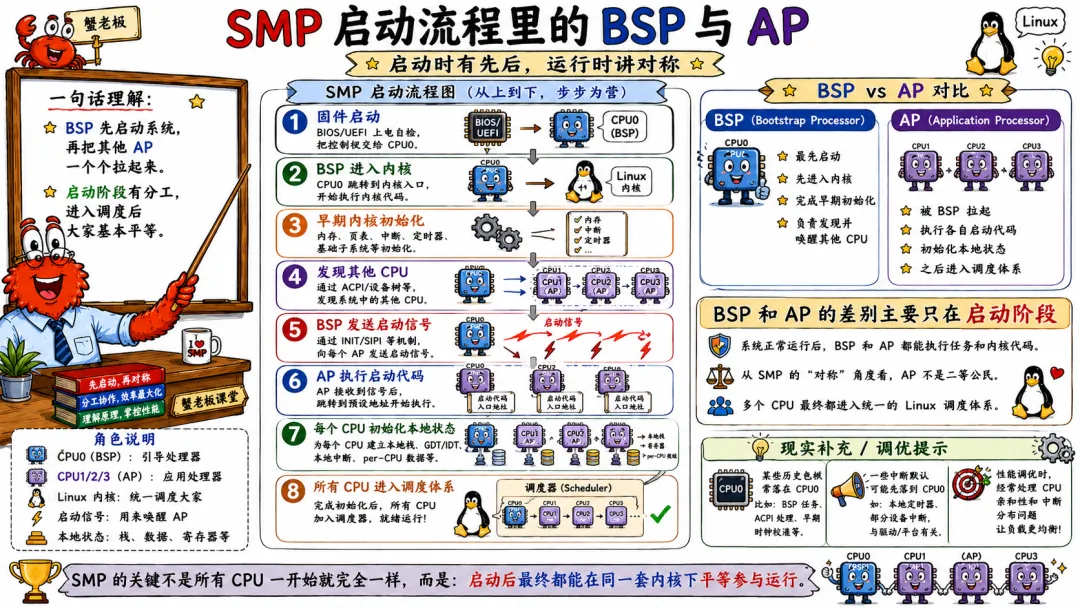
5.1 SMP 启动流程里的 BSP 与 AP
在 x86 这类平台上,系统启动时通常有一个 CPU 先启动。这个 CPU 叫 BSP,Bootstrap Processor。
其他 CPU 叫 AP,Application Processor。
名字有点古早,但很好理解。
BSP 先醒,负责早期初始化。比如进入内核、初始化内存管理、建立页表、初始化中断、解析硬件信息。
然后 BSP 会把其他 AP 一个个拉起来。
AP 启动后,也要完成自己的 CPU 本地初始化,比如设置寄存器、加载 GDT/IDT、初始化本地 APIC、设置 per-CPU 数据、进入调度循环。
大概流程可以想象成这样。
固件启动 ↓BSP 进入内核 ↓早期内核初始化 ↓发现其他 CPU ↓BSP 发送启动信号 ↓AP 执行启动代码 ↓每个 CPU 初始化本地状态 ↓所有 CPU 进入调度体系
BSP 和 AP 的差别主要在启动阶段。系统正常运行后,它们都可以执行任务和内核代码。从 SMP 的“对称”角度看,AP 不是什么二等公民。
当然,现实里有些特殊职责可能仍然偏向某些 CPU,比如 CPU0 上有更多历史包袱,一些中断默认也可能先落在 CPU0。调优时经常会处理这类问题。
你如果看 /proc/cpuinfo,看到一堆 processor 编号,其实背后就是这些逻辑 CPU 被内核发现、初始化、纳入调度系统的结果。
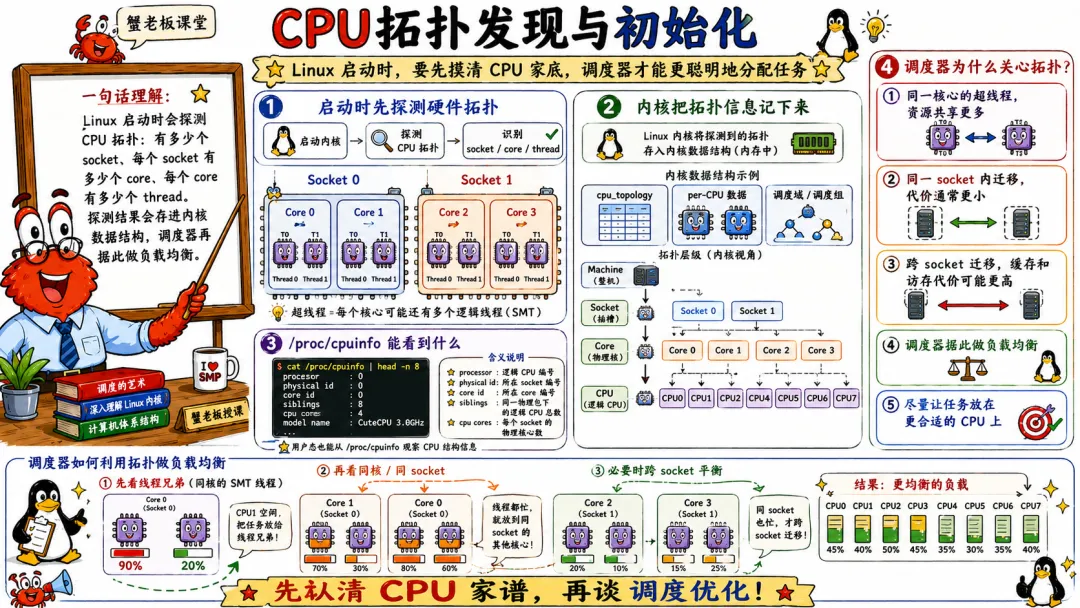
5.2 CPU 拓扑发现与初始化
Linux 不能只知道“我有 64 个 CPU”。
它还得知道这些 CPU 之间的关系。
哪些逻辑 CPU 是同一个物理核心上的超线程。
哪些核心在同一个 socket。
哪些 CPU 共享 L2。
哪些 CPU 共享 L3。
哪些 CPU 属于同一个 NUMA 节点。
这些信息会影响调度、负载均衡、中断分配、内存分配。
你可以通过一些命令观察。
lscpu -ecat /sys/devices/system/cpu/cpu0/topology/thread_siblings_listcat /sys/devices/system/cpu/cpu0/topology/core_siblings_listnumactl --hardware
调度器会根据拓扑建立调度域。简单说,就是负载均衡不是在所有 CPU 之间胡乱搬任务,而是分层次。
同核心的 SMT 兄弟之间怎么分配。
同一个 LLC 共享组内怎么平衡。
同一个 NUMA 节点内怎么平衡。
跨 NUMA 节点迁移要不要谨慎。
为什么要这么麻烦?
因为任务迁移有成本。
线程从 CPU0 跑到 CPU1,如果它们共享 L3,缓存损失可能还小一点。
如果从一个 NUMA 节点迁到另一个 NUMA 节点,原来热乎的数据可能都在远端内存或远端缓存附近,性能就难受了。
调度器不是只看谁闲。
它还要看亲和性、缓存、拓扑、负载、唤醒关系、NUMA 位置。这里面的策略非常复杂,而且不同内核版本一直在优化。
所以线上调优时,不要一看到 CPU 不均就粗暴绑核。绑核有用,但绑错了更离谱。
我见过有人把所有工作线程绑在同一个 NUMA 节点的几个 CPU 上,想着“减少迁移”。结果内存分配跑到另一个节点,远程访问多到飞起。你说它没调优吧,它确实调了。你说它调对了吧,也挺难评。
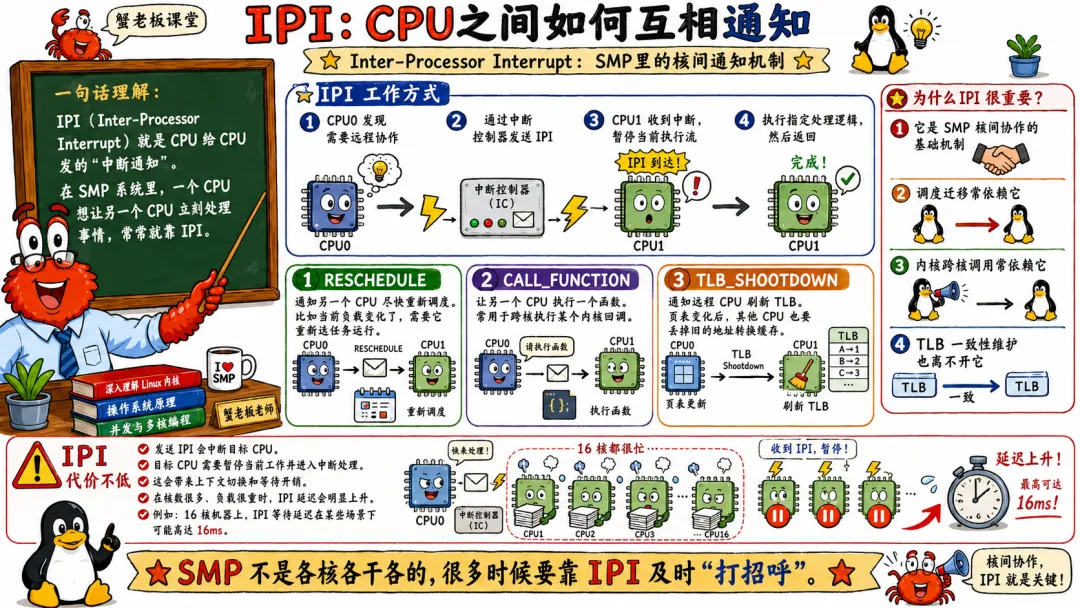
5.3 IPI 让 CPU 之间可以互相通知
IPI 是 Inter-Processor Interrupt,处理器间中断。
它是 SMP 系统里非常关键的机制。
一个 CPU 想让另一个 CPU 做点事,怎么通知?
不能靠喊。
靠 IPI。
比如 CPU0 需要 CPU3 重新调度,可以给 CPU3 发一个 reschedule IPI。
比如 CPU0 修改了页表,需要其他运行该地址空间的 CPU 刷新 TLB,可以给它们发 TLB shootdown IPI。
比如某些函数调用需要在指定 CPU 上执行,也可能通过 IPI 机制完成。
IPI 本质上是中断,但来源不是外设,而是其他 CPU。
你可以把它理解成 CPU 之间的“拍肩膀”。
CPU0 说,兄弟,你该重新看看调度了。
CPU2 说,哥几个,这个页表映射变了,把旧 TLB 扔掉。
这东西很有用,也有成本。
IPI 多了,系统会抖。因为被打断的 CPU 要停下当前执行流,进入中断处理。TLB shootdown 频繁时尤其明显。
在多核机器上,某些看似普通的内存操作,比如频繁 mmap/munmap、大量页表修改、进程地址空间频繁变化,都可能引出 TLB shootdown 的成本。
这事儿刚开始听有点远。线上真遇到过就不远了。
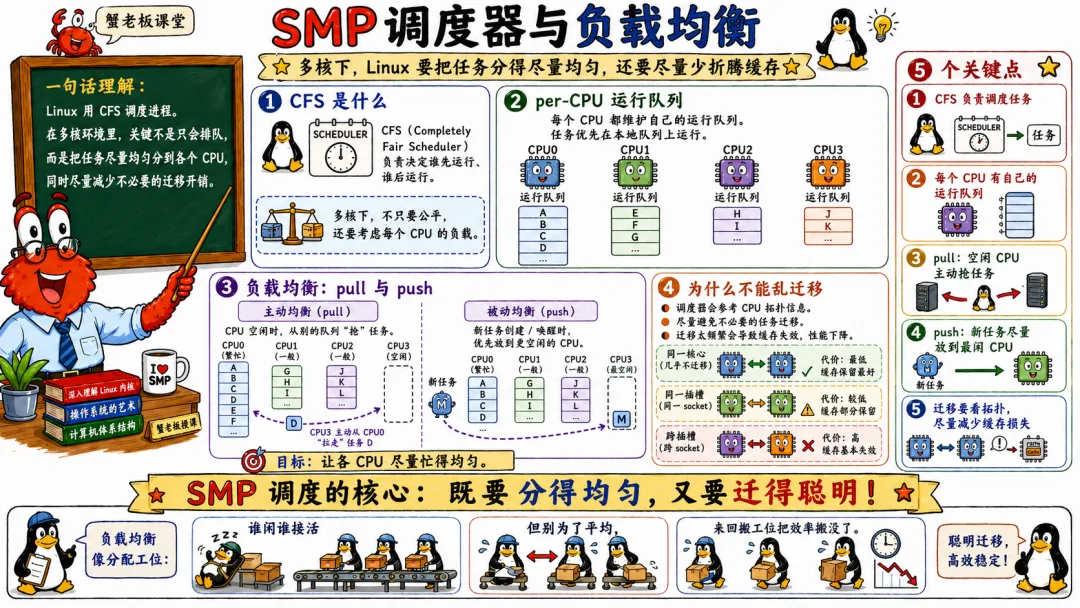
5.4 SMP 调度器与负载均衡
Linux 调度器在 SMP 下要解决一个大问题。
任务到底放在哪个 CPU 上跑?
单核只需要决定下一个跑谁。
SMP 还要决定在哪跑。
每个 CPU 通常有自己的运行队列。这样可以减少全局锁竞争。调度器在本地 CPU 上选择任务,必要时做负载均衡。
CFS 时代,调度器会用虚拟运行时间等机制追求公平。到了 SMP,还要考虑 CPU 拓扑和负载。
常见调度动作包括。
任务唤醒时选择一个 CPU。
周期性负载均衡。
空闲 CPU 主动拉任务。
繁忙 CPU 被动迁移任务。
NUMA balancing 尝试让任务靠近它使用的内存。
这里有个很容易被忽略的点。
负载均衡不是越积极越好。
迁移任务可以让 CPU 使用率更均匀,但会破坏缓存局部性。一个线程刚在 CPU0 上跑热,L1/L2/L3 里有它的数据。你把它迁到 CPU5,很多缓存优势没了。
所以调度器要在公平、吞吐、延迟、缓存局部性之间折中。
你看 top 里 CPU0 90%,CPU1 40%,就想“赶紧搬啊”。但内核可能有自己的判断。它可能觉得这个任务刚被唤醒,跟某个 CPU 有缓存亲和性,或者迁移成本不划算。
当然,调度器也不是神。
有些业务模型,内核默认策略就是不如你手工设计亲和性好。比如网络多队列收包、用户态 poller、DPDK、数据库 worker、低延迟交易系统。这些场景经常需要更明确的绑核和 NUMA 策略。
但普通服务别乱搞。先观测,再动手。
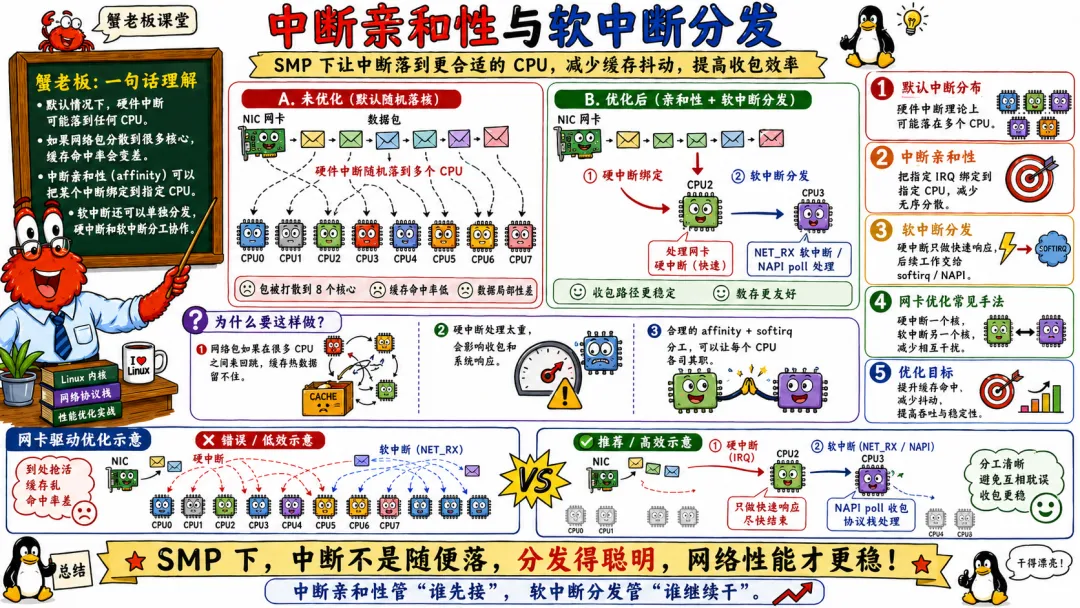
5.5 中断亲和性与软中断分发
中断是 SMP 调优里很常见的坑。
网卡、磁盘、定时器等设备会产生中断。中断落在哪个 CPU,会影响后续处理路径。
你可以看 /proc/interrupts。
cat /proc/interrupts
你会看到每个中断号在各个 CPU 上的计数。
如果某个网卡队列的中断几乎全打到 CPU0,CPU0 被打爆,其他 CPU 闲着,吞吐就可能上不去。
中断亲和性可以通过 /proc/irq/<irq>/smp_affinity 控制。
cat /proc/irq/123/smp_affinityecho 4 > /proc/irq/123/smp_affinity
这里的值是位掩码。实际操作要小心,别随便复制命令到生产上哈。
还有 irqbalance 服务会自动平衡中断,但它不是所有场景都完美。高性能网络场景里,经常会手动设置网卡多队列中断,把不同队列分散到不同 CPU,并让应用线程尽量跑在对应 CPU 上。
中断来了以后,硬中断处理要尽量短。很多工作会推迟到软中断,比如网络收包常见的 NET_RX softirq。
软中断在哪个 CPU 跑,也很重要。
如果收包中断在 CPU3,软中断也在 CPU3 处理,应用线程却在 CPU12 消费数据,中间可能跨 CPU 传递数据,缓存局部性变差。
所以网络性能调优里常说 RSS、RPS、XPS、IRQ affinity、CPU affinity 要一起看。
别只调一个旋钮。
这几个东西像一组齿轮。你只拧一个,可能会卡得更响。
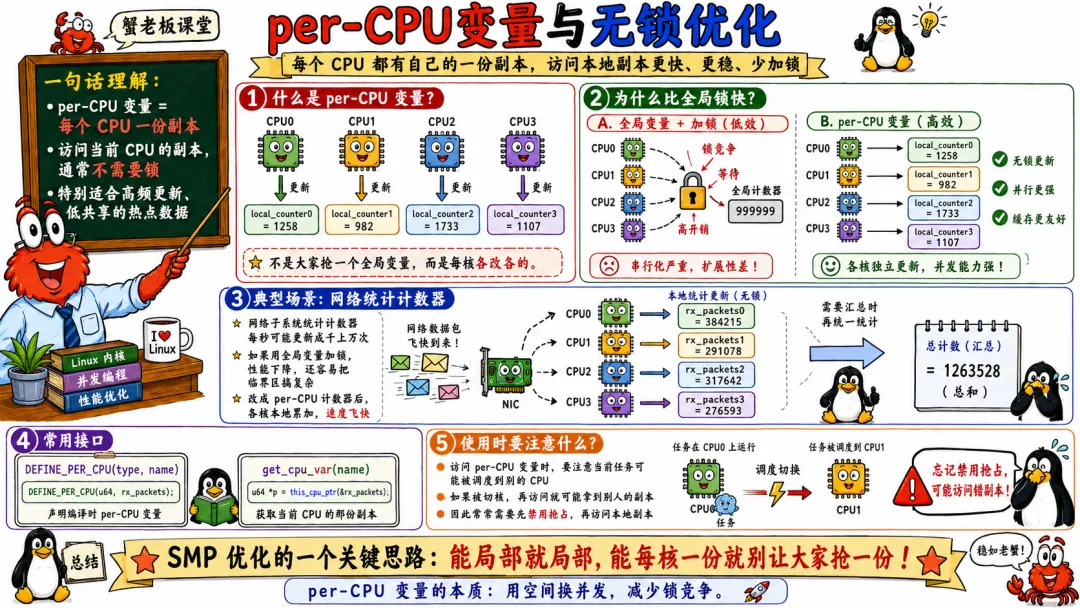
5.6 per-CPU 变量与无锁优化
per-CPU 是 Linux 内核在 SMP 下非常漂亮的设计。
思路很简单。
既然全局共享数据会造成竞争,那能不能给每个 CPU 一份自己的数据?
比如计数器。
如果每个 CPU 都去更新同一个全局计数器,缓存行会疯狂争用。
那就让每个 CPU 更新自己的计数器。读取总数时再把所有 CPU 的计数加起来。
这就是 per-CPU 思路。
CPU0 -> counter[0]CPU1 -> counter[1]CPU2 -> counter[2]CPU3 -> counter[3]
每个 CPU 写自己的那份,避免写共享缓存行。
Linux 内核里 per-CPU 变量用得非常多,比如统计计数、内存分配缓存、网络统计、调度器数据等。
你在内核代码里会看到类似接口。
DEFINE_PER_CPU(long, my_counter);void inc_counter(void){ this_cpu_inc(my_counter);}
this_cpu_inc() 的意思是操作当前 CPU 的那份变量。
per-CPU 的好处很明显。
减少锁。
减少缓存行争用。
提升缓存局部性。
让高频路径更轻。
但它也有代价。
读取全局值要汇总。
CPU 热插拔时要处理数据迁移。
如果任务被抢占或迁移,访问当前 CPU 数据要注意上下文。
内核里很多 per-CPU 操作需要禁抢占,或者保证当前执行不会被迁移到别的 CPU。否则你刚拿到 CPU0 的指针,下一刻任务跑到 CPU1,再操作就错了。
所以 per-CPU 不是免费午餐。
但在 SMP 性能优化里,它真的有点东西。
5.7 自旋锁 原子操作 RCU 在 SMP 下的实现
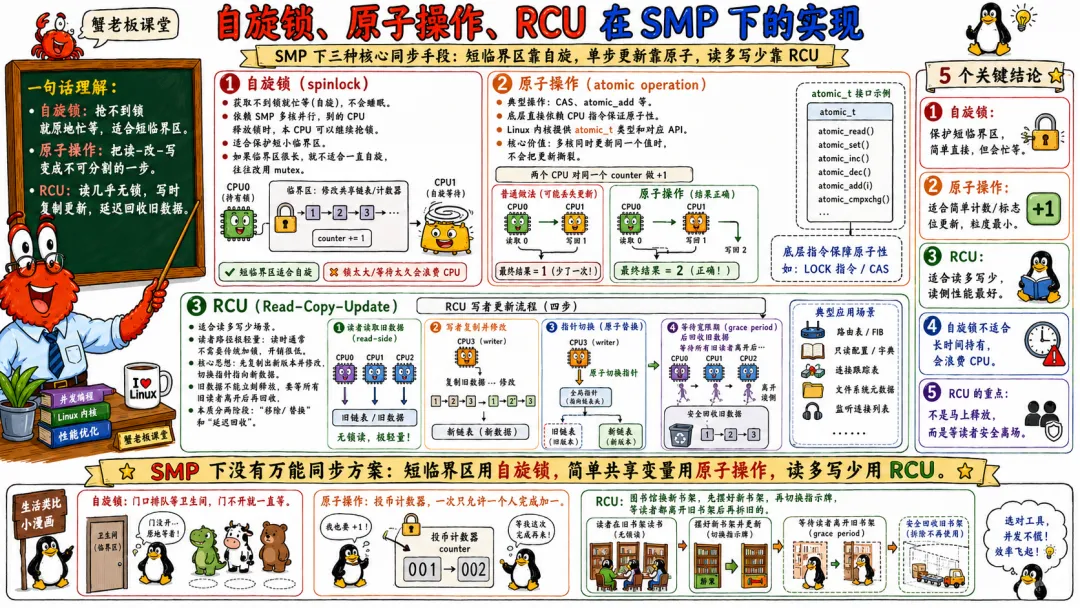
自旋锁是内核里最典型的 SMP 同步原语之一。
自旋锁的特点是拿不到锁时不睡眠,而是在 CPU 上循环等待。
spin_lock(&lock);/* 临界区 */spin_unlock(&lock);
在单核非抢占场景,自旋锁可以简化成关抢占或关中断一类操作。但在 SMP 下,它必须真的防止其他 CPU 同时进入临界区。
自旋锁适合临界区很短、不能睡眠的场景,比如中断上下文、调度器、底层数据结构保护。
但自旋锁用错了很惨。
临界区太长,其他 CPU 就一直空转烧 CPU。
锁竞争太激烈,缓存行在 CPU 之间疯狂迁移。
持锁期间睡眠,直接大事故。
原子操作则适合简单计数、状态位切换、引用计数等场景。
atomic_t refcnt = ATOMIC_INIT(1);atomic_inc(&refcnt);if (atomic_dec_and_test(&refcnt)) { release_object(obj);}
但原子操作不是锁的平替。
它适合简单操作。多个字段需要保持一致时,还是需要锁或其他同步机制。
RCU 是 Linux 内核里非常重要的一套机制。它特别适合读多写少的数据结构。
RCU 的核心味道是读路径几乎不加锁,写路径复制或更新指针,然后等待所有旧读者离开临界区,再释放旧对象。
读路径大概像这样。
rcu_read_lock();p = rcu_dereference(global_ptr);do_something(p);rcu_read_unlock();
更新路径大概是。
new = kmalloc(...);init_new_object(new);old = rcu_dereference_protected(global_ptr, lockdep_is_held(&mutex));rcu_assign_pointer(global_ptr, new);synchronize_rcu();kfree(old);
这里 synchronize_rcu() 会等待一个 grace period,确保之前可能看到旧指针的读者都结束了。
RCU 在 SMP 下很强,因为它避免了读路径频繁争锁。网络协议栈、文件系统、调度、内存管理里都大量用它。
但 RCU 也不是魔法。
它要求读者不能在 RCU 读临界区里随便睡眠,具体规则还要看 RCU 类型。它还要求对象生命周期管理非常谨慎。用错了,问题会很隐蔽。
我第一次看 RCU 代码时,脑子里就一句话。
这玩意儿是人能想出来的?
后来被锁竞争毒打几次,就理解了。高并发读路径里,RCU 简直救命。
5.8 SMP 下的内存管理与 TLB Shootdown
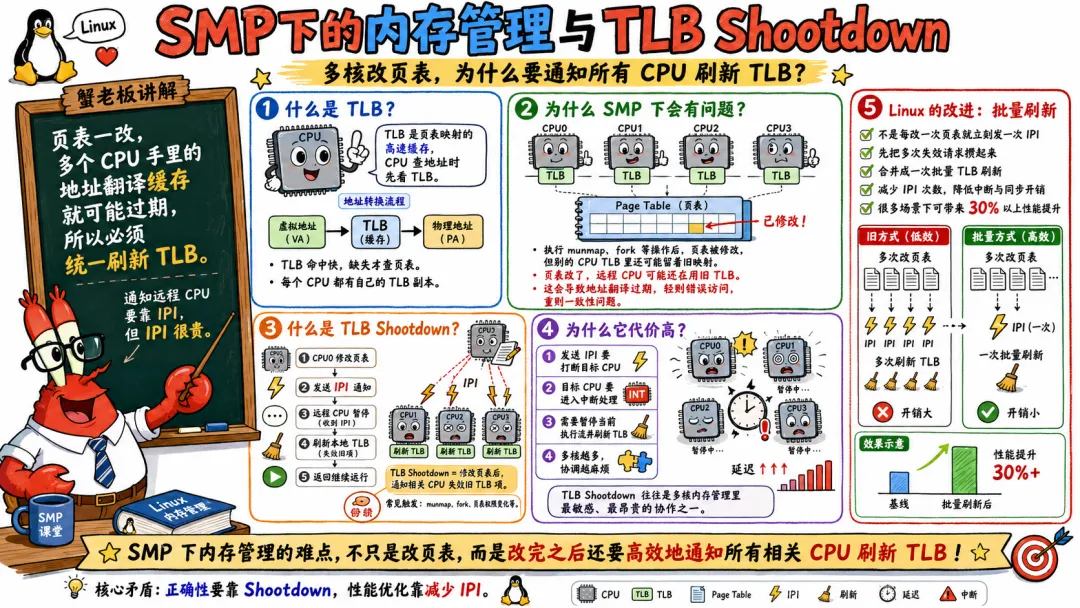
TLB 是 Translation Lookaside Buffer,用来缓存虚拟地址到物理地址的转换结果。
没有 TLB,CPU 每次访问内存都要查页表,慢得离谱。
在 SMP 系统里,每个 CPU 都有自己的 TLB。
问题来了。
如果某个进程的页表被修改了,比如 unmap 掉一段内存,其他 CPU 的 TLB 里可能还缓存着旧映射。
那怎么办?
必须让相关 CPU 刷掉旧 TLB 项。
这就是 TLB Shootdown。
通常做法是当前 CPU 修改页表后,向其他相关 CPU 发送 IPI,让它们执行 TLB 刷新。
CPU0 修改页表 ↓CPU0 找到哪些 CPU 可能持有旧 TLB ↓CPU0 发送 IPI ↓CPU1/CPU2/CPU3 收到 IPI ↓它们刷新对应 TLB ↓CPU0 等待确认
这个过程有成本。
CPU 数量越多,影响可能越大。
频繁修改页表的程序,比如大量 mmap/munmap、频繁创建销毁映射、某些 GC 行为、内存分配模式不合理,都可能引发额外开销。
这也是为什么大页 HugeTLB、THP、内存池、减少频繁映射操作,在某些场景下会明显影响性能。
TLB Shootdown 也是一个典型例子。
你以为自己只是释放了一段内存。
内核背后可能让一堆 CPU 停下来刷 TLB。
多核时代,任何“全局可见”的变化都可能很贵。
六 SMP 性能问题与调优实战
讲完机制,不落到排查上就没意思。
SMP 性能问题经常有个特点。
现象很像 CPU 不够,根因却不是 CPU 算力不够。
CPU 可能忙着抢锁。
忙着等缓存行。
忙着处理中断。
忙着跨 NUMA 访问内存。
忙着被 IPI 打断。
你要拆开看。
6.1 CPU 负载不均问题排查
最常见现象是某几个 CPU 很忙,其他 CPU 很闲。
先看整体。
tophtopmpstat -P ALL 1
mpstat -P ALL 1 很实用,可以按 CPU 看用户态、内核态、软中断、硬中断、iowait 等比例。
如果某个 CPU 的 %soft 很高,可能是软中断集中。
如果 %sys 很高,可能内核路径很重,锁、中断、网络、系统调用都要怀疑。
如果某个业务进程线程集中在少数 CPU 上,看看是不是绑核了。
taskset -cp <pid>ps -eLo pid,tid,psr,comm | grep <process>
psr 可以看到线程最近运行在哪个 CPU。
如果线程分布很不均,要结合业务模型看。线程池是不是太小?是否有单线程瓶颈?是否有锁导致只有一个线程真正干活?是否因为 CPU affinity 限制了可运行 CPU?
再看中断。
cat /proc/interrupts
如果网卡中断集中在一个 CPU,上来就要怀疑 RSS 队列、中断亲和性、irqbalance 配置。
别一看到负载不均就强行绑核。先搞清楚谁在忙。
忙的是用户线程?
内核?
软中断?
硬中断?
还是 kworker?
方向完全不一样。
6.2 锁竞争过高问题排查
锁竞争高,表现通常是 CPU 使用率高但吞吐不涨,线程数越多越差,延迟抖动明显。
用户态可以用 perf 看热点。
perf top -p <pid>perf record -g -p <pid> -- sleep 30perf report
如果热点里有大量 futex,说明用户态锁竞争或条件变量等待可能很重。
futex_waitfutex_wakepthread_mutex_lock
内核态锁竞争,可以看 perf lock。
perf lock record -- sleep 10perf lock report
不过生产环境使用要谨慎,开销和权限都要考虑。
还有一种很朴素但有效的方法,在业务锁上做统计。比如记录等待时间、持锁时间、竞争次数。
代码别太花。
uint64_t start = now_ns();pthread_mutex_lock(&lock);uint64_t waited = now_ns() - start;uint64_t hold_start = now_ns();/* 临界区 */uint64_t hold_time = now_ns() - hold_start;pthread_mutex_unlock(&lock);
当然,统计本身也可能带来开销,别在高频路径里胡乱打日志。可以采样。
优化方向通常是几个。
缩短临界区。
拆锁。
读写分离。
分片。
批量处理。
用无锁队列或 RCU。
用 per-thread 或 per-CPU 本地数据,定期聚合。
但别上来就无锁。
无锁写不好就是隐藏 bug 生产机巡演。我也知道这么说太绝对,但很多所谓 lock-free 代码,最后不如一把写清楚的锁可靠。
6.3 False Sharing 与缓存行颠簸排查
False Sharing 是 SMP 性能里的阴间问题。
代码看着没有共享变量,CPU 却争得很凶。
排查它需要一点经验。
现象通常是线程数增加后性能反而下降,CPU 利用率高,锁竞争不明显,但 cache miss、cache-to-cache 传输很高。
可以用 perf 看缓存相关事件。不同 CPU 和内核支持的事件名不一样,命令也会有差异。
perf stat -e cache-references,cache-misses,cycles,instructions -p <pid> -- sleep 10
在一些平台上,可以看更细的 c2c。
perf c2c record -p <pid> -- sleep 10perf c2c report
perf c2c 可以帮助定位 cache line 争用,尤其是 HITM 相关问题。
定位到结构体后,重点看多个线程分别写哪些字段,这些字段是不是落在同一个缓存行。
用 pahole 看结构体布局也很有用。
pahole your_binary
优化方式包括。
给高频写字段做缓存行对齐。
把读多写少字段和频繁写字段分开。
每线程或每 CPU 拆分计数器。
避免生产者和消费者写同一个缓存行。
结构体布局上,把热字段和冷字段分离。
例如一个队列结构。
struct queue { volatile uint64_t head; volatile uint64_t tail; void *items[1024];};
如果生产者更新 tail,消费者更新 head,而 head 和 tail 在同一个缓存行,性能就可能很难看。
可以拆开。
struct queue { volatile uint64_t head; char pad1[64 - sizeof(uint64_t)]; volatile uint64_t tail; char pad2[64 - sizeof(uint64_t)]; void *items[1024];};
真实工程里要考虑可移植性和结构体大小,不要到处手写 padding 写到自己都看不懂。可以封装宏。
6.4 中断亲和性调优
网络服务性能差,别忘了看中断。
先看网卡队列。
ls /sys/class/net/eth0/queues/
看中断分布。
cat /proc/interrupts | grep eth0
如果多队列网卡只有一个队列在忙,或者所有中断集中到少数 CPU,吞吐很可能上不去。
可以看和调整 combined queue 数量。
ethtool -l eth0ethtool -L eth0 combined 8
也可以调整 RSS hash。
ethtool -x eth0
中断亲和性可以手动写 /proc/irq/<irq>/smp_affinity。但这个位掩码容易写错,生产上要用脚本谨慎生成。
很多发行版会跑 irqbalance。普通场景让它自动平衡就行。高性能场景可能要关闭或精细配置,避免它把你手动调好的亲和性改掉。
网络路径上还要考虑 RPS 和 XPS。
RPS 让接收包的软中断可以分发到其他 CPU。
XPS 控制发送队列选择,让发送路径更贴近应用线程所在 CPU。
这些东西不是越开越好。
如果网卡硬件 RSS 已经很好,乱开 RPS 可能增加跨 CPU 开销。要看机器、网卡、内核版本、业务模型。
调优这事儿,最怕“听说”。
听说某参数有用,就全开。
听说绑核能提升,就全绑。
听说 irqbalance 不好,就全关。
然后线上抖成电风扇。
6.5 调度参数与 CPU 亲和性调优
CPU 亲和性可以控制进程或线程在哪些 CPU 上运行。
常用工具是 taskset。
taskset -c 0-7 ./servertaskset -cp 0-7 <pid>
程序里也可以用 sched_setaffinity()。
#define _GNU_SOURCE#include <sched.h>#include <unistd.h>void bind_to_cpu(int cpu){ cpu_set_t set; CPU_ZERO(&set); CPU_SET(cpu, &set); sched_setaffinity(0, sizeof(set), &set);}
绑核适合什么场景?
低延迟服务。
网络 poller。
用户态驱动。
数据库 worker。
明确知道线程角色和数据归属的系统。
不适合什么?
普通 Web 服务一上来乱绑。
线程池任务不固定却强行绑死。
跨 NUMA 内存不管不顾。
把所有线程绑到超线程兄弟上,然后以为自己用了两个完整核心。
绑核时要看拓扑。
lscpu -e=CPU,CORE,SOCKET,NODE
不要把两个高负载线程绑到同一个物理核心的两个超线程上,还以为是两个完整核心。超线程共享执行资源,很多计算密集任务放一起会互相抢。
也不要忽略 NUMA。
numactl --hardwarenumastat -p <pid>
如果进程跑在 node0 的 CPU 上,却大量访问 node1 的内存,延迟和带宽都会受影响。
6.6 内存带宽 互联瓶颈与 NUMA 远程访问问题
SMP 扩展到多 socket 后,内存访问就变得很现实。
CPU 访问本地内存快。
访问远程内存慢。
远程访问还会占用 CPU 间互联带宽。
有些业务 CPU 看着没满,但内存带宽满了。再加线程也没用,因为瓶颈在内存。
可以用 numastat 看 NUMA 访问情况。
numastatnumastat -p <pid>
可以用 numactl 控制 CPU 和内存绑定。
numactl --cpunodebind=0 --membind=0 ./server
这表示进程尽量跑在 NUMA node0 的 CPU 上,并从 node0 分配内存。
还有一种策略是 interleave,让内存交错分布到多个节点。
numactl --interleave=all ./server
适合不容易绑定到单个节点、但希望利用多个节点内存带宽的场景。
NUMA 调优没有固定答案。
如果是分片服务,最好让每个分片的线程和内存靠近同一个 NUMA 节点。
如果是共享大内存读多场景,可能 interleave 更合适。
如果是网络服务,还要看网卡挂在哪个 NUMA 节点。网卡中断、应用线程、内存分配最好尽量靠近。否则数据从网卡 DMA 到一个节点,CPU 在另一个节点处理,绕一圈,白白浪费。
这类问题排查很磨人。
不是一个参数能救。要把 CPU、内存、网卡、中断、线程模型一起看。
七、实战案例:Linux 内核中的 SMP 机制
这一节我们把前面的东西串起来,打通底层逻辑。
7.1 一个线程如何被调度到不同 CPU 上
假设一个线程从睡眠中被唤醒。
比如它在等网络数据。数据来了,内核唤醒它。
唤醒发生时,内核需要选择一个 CPU,把这个线程放到对应运行队列。
选择 CPU 时,会考虑很多因素。
它上次在哪个 CPU 跑。
那个 CPU 现在忙不忙。
唤醒它的 CPU 是哪个。
任务的 CPU affinity 是否允许。
调度域和 NUMA 拓扑如何。
是否应该利用缓存热度。
如果目标 CPU 不是当前 CPU,内核可能需要通知目标 CPU 重新调度。这时就可能发 reschedule IPI。
于是流程大概是。
网络数据到达 ↓软中断或内核路径唤醒等待线程 ↓调度器选择目标 CPU ↓线程加入目标 CPU 的运行队列 ↓必要时发送 IPI 通知目标 CPU ↓目标 CPU 调度时选中该线程 ↓线程开始运行
如果这个线程频繁在 CPU 之间迁移,缓存命中率可能下降。
所以调度器会尽量兼顾迁移成本。但如果负载不均严重,它也会迁。
你在线上看到线程 psr 一直变,不一定是坏事。要结合性能指标看。
如果低延迟场景不希望迁移,可以绑核。但绑核后你就接管了一部分调度责任,别指望内核完全替你兜底。
7.2 一个中断如何被分发到指定 CPU
以网卡收包为例。
网卡收到数据包,通过 DMA 写入内存里的接收队列。
然后网卡触发 MSI-X 中断。
中断控制器根据配置,把这个中断投递到某个 CPU。
CPU 进入硬中断处理。驱动处理必要工作,通常不会在硬中断里做太多事,而是触发 NAPI,把后续收包工作放到软中断上下文。
软中断处理收包,进入协议栈,最终唤醒等待 socket 数据的进程。
简化流程是。
网卡收到包 ↓DMA 写内存 ↓触发中断 ↓中断投递到某个 CPU ↓驱动硬中断处理 ↓NAPI poll / NET_RX softirq ↓协议栈处理 ↓数据进入 socket 队列 ↓唤醒用户线程
这里每一步都可能涉及 SMP 调优。
中断在哪个 CPU。
软中断在哪个 CPU。
socket 属于哪个应用线程。
应用线程在哪个 CPU。
数据结构在哪个 NUMA 节点。
如果这些都不匹配,包就在系统里跨 CPU、跨 NUMA 来回跑。吞吐和延迟都难看。
所以高性能网络不是只会 epoll。epoll 是用户态接口,真正性能还要看中断、队列、调度、缓存、NUMA。
说白了,包要少搬家。
数据和处理它的 CPU 越近越好。
7.3 一把自旋锁在多核下如何保护临界区
假设内核里有一个共享链表,需要用自旋锁保护。
CPU0 要插入节点。
CPU1 也要删除节点。
它们都会先拿锁。
spin_lock(&list_lock);list_add(&node, &head);spin_unlock(&list_lock);
当 CPU0 拿到锁后,锁变量所在缓存行会被 CPU0 持有。CPU1 尝试拿锁时,会循环检查锁状态。这个过程可能不断读取同一个缓存行。
CPU0 解锁时写锁变量,CPU1 看到变化后尝试获取。缓存行所有权在 CPU 之间转移。
如果锁竞争轻,临界区短,这没问题。
如果很多 CPU 都抢同一把锁,就会发生严重争用。
自旋锁竞争时,浪费的不只是等待时间,还有缓存一致性开销。锁变量本身就是一个热点缓存行。大家抢它,缓存行就在核心之间乱飞。
这也是为什么内核不断优化锁实现。
早期简单 test-and-set 自旋锁,在多 CPU 下会造成大量缓存流量。
后来的 ticket lock 保证公平,但在大规模多核下也有问题。
再后来的 qspinlock 试图在空间和性能之间折中。
你不一定要深入每种锁的实现,但要知道一件事。
锁不是一个抽象符号。它落在硬件上,就是缓存行、原子指令、内存屏障、一致性消息。
所以“加锁就安全”只说了一半。
另一半是“加锁也可能慢死”。
7.4 一次 TLB Shootdown 如何触发 IPI
假设进程 P 有多个线程,分别在 CPU0、CPU1、CPU2 上运行。
现在 CPU0 上的线程调用 munmap(),取消一段虚拟内存映射。
内核会修改进程 P 的页表。
但 CPU1 和 CPU2 的 TLB 里可能还缓存着这段地址的旧映射。
如果不处理,它们可能继续通过旧映射访问内存。这肯定不行。
于是 CPU0 必须让 CPU1 和 CPU2 刷新相关 TLB。
流程是。
CPU0 执行 munmap ↓内核修改页表 ↓找出正在使用该 mm 的其他 CPU ↓向这些 CPU 发送 IPI ↓CPU1/CPU2 进入 IPI handler ↓刷新 TLB ↓CPU0 等待完成
这里最烦的是等待。
CPU0 不能只发个通知就不管。它必须确保旧映射不会继续被使用。
CPU 越多,这类同步成本越明显。
所以频繁页表修改在大核数机器上可能很贵。
你看,SMP 下很多成本都是“广播式”的。一个 CPU 做了全局变化,其他 CPU 都要知道。机器核数越多,这种全局同步越要命。
这也是为什么内核里有很多优化,尽量减少 shootdown 范围,批量处理 TLB flush,避免不必要的全局同步。
7.5 一个 False Sharing 问题如何定位和优化
我们写一个简化例子。
struct stats { uint64_t rx_packets; uint64_t tx_packets;};struct stats s;
线程 A 专门收包,更新 rx_packets。
线程 B 专门发包,更新 tx_packets。
它们没有写同一个变量。看起来没锁也没事。
但两个字段很可能在同一个 64 字节缓存行里。
结果就是 CPU0 更新 rx,CPU1 更新 tx,两个 CPU 反复争同一个缓存行。
压测表现可能是线程数增加后吞吐不涨,甚至下降。
优化方式是拆缓存行。
struct stats { uint64_t rx_packets; char pad1[64 - sizeof(uint64_t)]; uint64_t tx_packets; char pad2[64 - sizeof(uint64_t)];};
更好的方式是每 CPU 统计。
struct cpu_stats { uint64_t rx_packets; uint64_t tx_packets;} __attribute__((aligned(64)));struct cpu_stats stats[MAX_CPU];
每个 CPU 更新自己的统计。
读取总数时再聚合。
uint64_t total_rx = 0;for (int i = 0; i < nr_cpu; i++) { total_rx += stats[i].rx_packets;}
这类优化在高频统计里非常常见。
不要小看统计计数器。很多系统的性能问题,就是被“顺手加的统计”搞出来的。线上业务一热,统计也热,缓存行也热,然后大家一起炸。
我就干过这种蠢事。为了看一个请求路径的命中次数,加了几个全局 atomic counter。压测时性能掉了一截。后来改成线程本地计数,定时汇总,才恢复。
那天我给自己倒了杯咖啡,坐工位上想了半天。
人类写 bug 的创造力,真强。
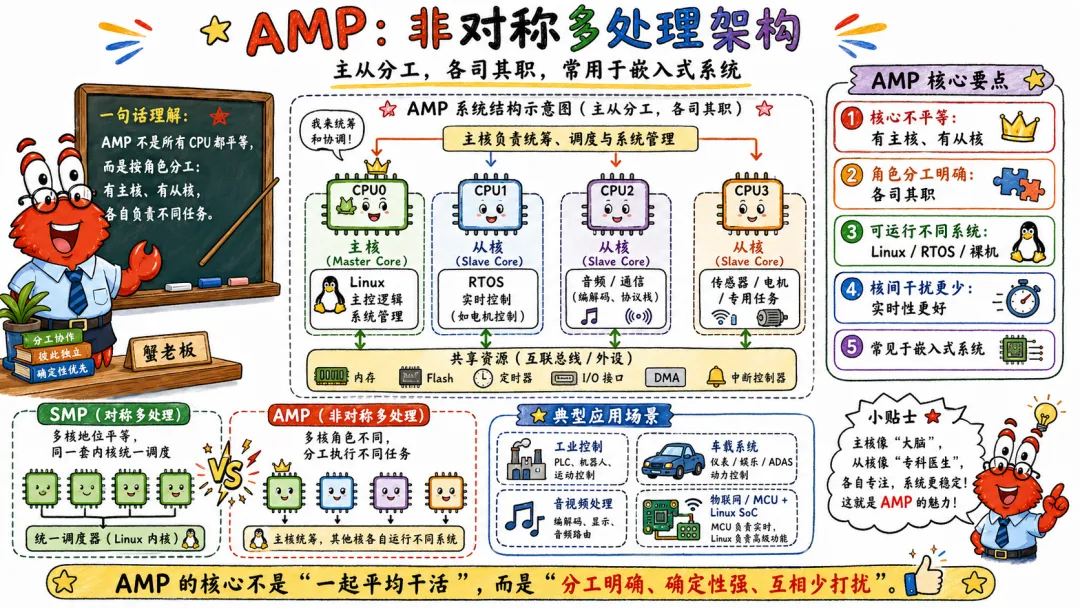
八、SMP AMP NUMA 的关系与对比
文章写到这儿,咱们得站在更高的高度上,看看整个多处理架构的江山全景。
8.1 AMP 是非对称多处理架构
AMP 是 Asymmetric Multiprocessing,非对称多处理。
AMP 里多个处理器不一定地位相同,也不一定由同一个操作系统统一调度。
典型场景是嵌入式和异构系统。
比如一个芯片里有 Cortex-A 跑 Linux,另一个 Cortex-M 跑实时任务。
Linux 负责复杂应用和网络。
RTOS 负责电机控制、音频处理、通信协议等实时逻辑。
两个处理器可能通过共享内存、mailbox、中断等方式通信。
这种架构下,不同 CPU 的角色是分工明确的,不是“大家平等跑同一个内核”。
AMP 的好处是隔离强,实时性好,适合异构任务。
坏处是编程模型复杂,资源共享和通信需要额外设计。
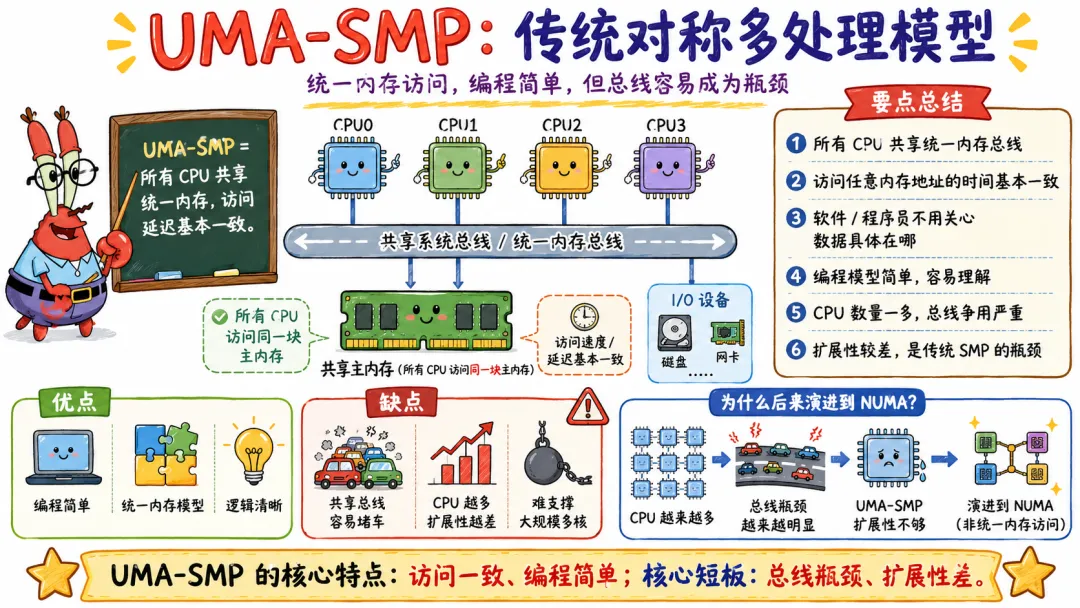
8.2 UMA-SMP 是传统对称多处理模型
UMA-SMP 是最经典的 SMP 模型。
多个 CPU 共享同一套内存,访问任意内存位置的成本大致一致。
同一个操作系统管理所有 CPU。
所有 CPU 都可以运行内核和用户任务。
这套模型很适合理解 Linux SMP 的基础。
但它在大规模扩展上有瓶颈。
因为 CPU 越多,共享总线、共享内存控制器、缓存一致性流量都会越来越重。想靠一个完全均匀的共享内存模型扩展到很多 CPU,很难。
所以现代系统逐渐走向 NUMA。
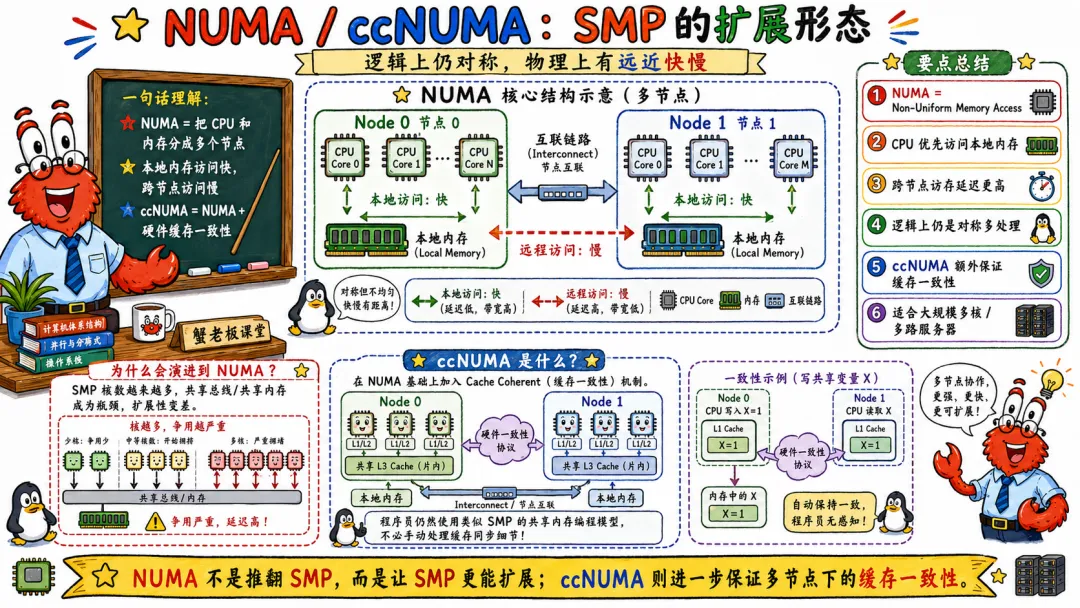
8.3 NUMA 和 ccNUMA 是 SMP 的扩展形态
NUMA 是 Non-Uniform Memory Access,非统一内存访问。
CPU 访问本地内存快,访问远程内存慢。
ccNUMA 则是在 NUMA 基础上保证缓存一致性。现代多路服务器通常是这种形态。
这就形成一个有点绕但很重要的结论。
NUMA 系统仍然可以运行一个 SMP 风格的 Linux。
所有 CPU 仍然由一个内核管理。
所有进程仍然看到统一虚拟地址空间。
但内存访问成本不均匀。
这意味着 Linux 内核既要维持 SMP 的统一调度和共享内存语义,又要尽量利用 NUMA 的局部性。
这就更难了。
任务最好跑在靠近它内存的 CPU 上。
内存最好分配在使用它的 CPU 所在节点。
中断最好落在靠近设备和处理线程的 CPU 上。
跨节点访问要减少。
跨节点锁竞争更要少。
所以很多高性能服务在双路服务器上反而不如单路机器稳。不是双路弱,而是你没处理好 NUMA。数据跨 socket 飞来飞去,互联带宽和延迟把你按住了。
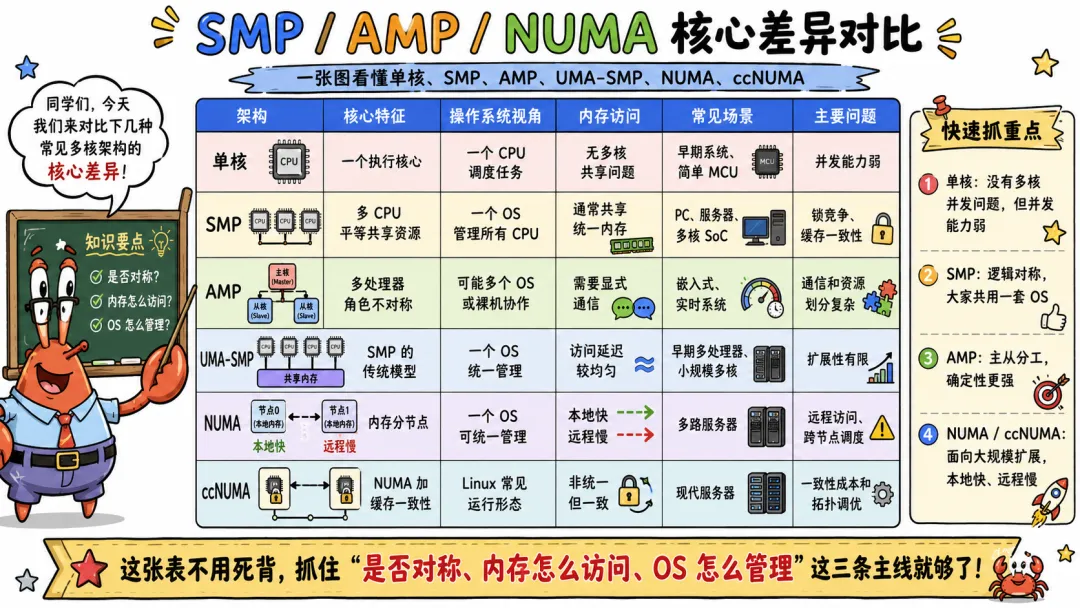
这张表不用死背,你只要抓住几个关键词。
SMP 讲的是 CPU 地位对称和共享操作系统。
AMP 讲的是 CPU 角色不对称和分工。
NUMA 讲的是内存访问有远近。
ccNUMA 讲的是内存非统一,但缓存仍保持一致。
现代 Linux 并发,经常是在 ccNUMA 机器上跑 SMP 风格的软件。
这句话有点拗,但很关键。
九 理解 SMP 后 Linux 并发底层就通了
学 Linux 并发,很多人卡在一个地方。
概念全背了,但串不起来。
知道自旋锁,但不知道它为什么忙等。
知道原子操作,但不知道它背后要抢缓存行所有权。
知道内存屏障,但不知道它和缓存一致性不是一回事。
知道调度器,但不知道任务迁移会破坏缓存局部性。
知道中断亲和性,但不知道软中断和应用线程也要一起考虑。
知道 NUMA,但只会跑 numactl --hardware 看个热闹。
这就像手里有一堆零件,却不知道机器怎么转。
SMP 是把这些零件串起来的底层主线。
多个 CPU 共享一套内核,所以需要同步。
多个 CPU 各自有缓存,所以需要缓存一致性。
缓存一致性不保证程序顺序,所以需要内存屏障。
共享数据写得太频繁,所以要 per-CPU、分片、RCU。
任务可以在多个 CPU 上跑,所以需要 SMP 调度和负载均衡。
外设中断可以打到不同 CPU,所以要中断亲和性和软中断分发。
页表变化影响多个 CPU,所以要 TLB Shootdown 和 IPI。
机器变成多 socket,所以要考虑 NUMA 远程访问。
你看,Linux 并发底层不是一堆孤立知识点。
它是一张网。
SMP 是这张网的骨架。
以后你再看到 spin_lock(),脑子里不该只有“加锁保护临界区”。
你还应该想到锁变量所在缓存行会被多个 CPU 争用。
看到 atomic_inc(),不该只觉得它比普通加法安全。
你还要想到高频 atomic counter 可能成为缓存行热点。
看到线程迁移,不该只看 CPU 使用率均不均。
你还要想到缓存热度、NUMA 本地性、唤醒路径。
看到 /proc/interrupts,不该只觉得是一堆数字。
你要知道每个数字背后都是外设和 CPU 的协作关系。
看到 munmap(),也别以为只是释放虚拟地址。
在多核下,它可能牵出页表修改、TLB 刷新、IPI 通知。
这才是 Linux 并发真正迷人的地方,也是真的折磨人。
现实里 CPU 有缓存,缓存有行,行会失效,失效要通信。线程会迁移,迁移会丢缓存。内存有远近,远程访问会慢。中断会倾斜,软中断会打爆单核。锁能保护正确性,也能毁掉扩展性。
所以啊,吃透 SMP,不是为了面试时背几句定义。
是为了你看到 Linux 并发问题时,脑子里终于有一张底图。
这张图能告诉你,问题可能在哪一层。
是锁?
是缓存行?
是中断?
是调度?
是 NUMA?
是 TLB?
还是你写了个全局计数器,然后把 64 核机器干成了单核排队?
所以如果你想真正理解 Linux 并发底层,SMP 这关绕不过去。