第一章 Page Cache 在 Linux 存储栈中的位置1.1 为什么需要 Page Cache
对于 Linux 而言,磁盘始终是远慢于内存的设备。即使在 NVMe SSD 普及之后,单次内存访问延迟仍然只有几十纳秒,而 NVMe 访问延迟通常在几十微秒以上,两者仍然存在数百倍差距。如果应用程序每次 read() 或 write() 都直接访问磁盘,那么 CPU 大量时间都会消耗在等待 I/O 完成上。因此 Linux 在文件系统与块设备之间引入了 Page Cache,将热点数据缓存在内存中,大部分读请求可以直接从缓存返回,从而显著降低磁盘访问次数。
Page Cache 本质上是文件数据在内存中的镜像。对于文件系统来说,磁盘上的每个逻辑块都可能对应一个缓存页,当应用程序读取文件时,内核优先查询缓存页是否存在;如果命中,则直接返回数据;如果未命中,则从块设备读取对应数据并建立缓存页。随着访问次数增加,热点文件逐渐驻留在内存中,大量读请求最终转化为内存访问,这也是 Linux 文件系统能够获得高性能的重要原因。
1.2 Page Cache 在存储架构中的位置
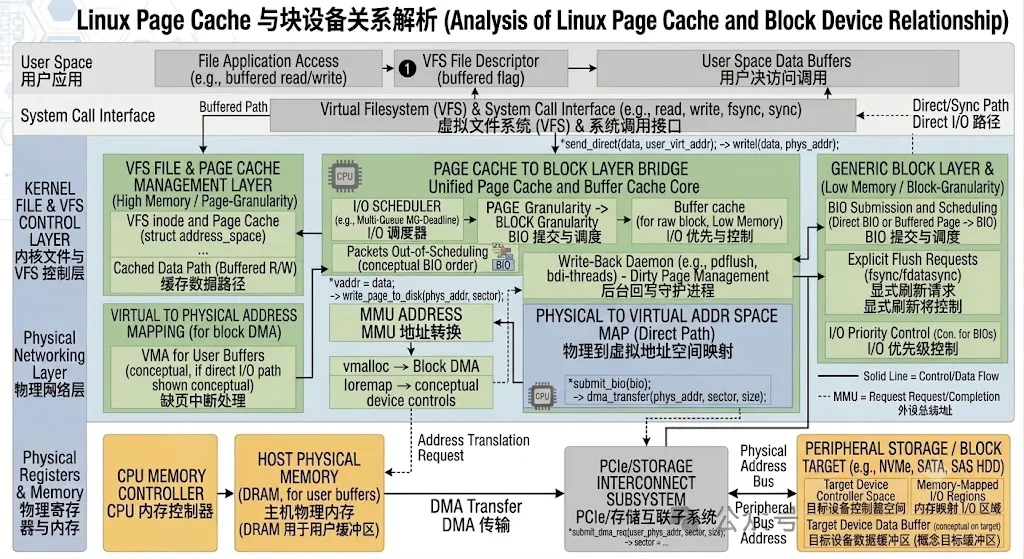
很多开发人员容易将文件系统和块设备直接关联起来,但实际上 Linux 文件访问路径中间隔着一层 Page Cache。应用程序执行 read() 或 write() 时,请求首先进入 VFS,然后定位 inode 对应的 address_space,接着访问 Page Cache,只有缓存未命中或者脏页回写时才会访问块设备,整个存储栈结构如下:
Userspace │ ▼read/write │ ▼VFS │ ▼Page Cache │ ▼Filesystem │ ▼BIO │ ▼Block Layer │ ▼Disk
从这个结构可以看出,Page Cache 实际上位于文件系统和块设备之间。文件系统负责维护文件逻辑结构,而块设备负责数据存储,Page Cache 则承担数据缓冲和性能优化职责。对于绝大多数文件访问而言,Page Cache 才是真正的第一访问目标,而不是磁盘本身。
第二章 Page Cache 如何管理文件数据
2.1 inode 与 address_space
Linux 中每个文件对应一个 inode,而 inode 内部维护着一个非常重要的结构体 address_space。Page Cache 并不是全局散乱存在的,而是通过 address_space 与具体文件建立关联。一个文件有多少缓存页、这些缓存页位于哪些位置、是否为脏页,全部通过 address_space 统一管理,内核源码中可以看到如下成员:
struct inode { struct address_space i_data;};
而 address_space 内部又维护着页缓存索引结构。早期 Linux 使用 radix tree 管理缓存页,较新版本已经迁移到 XArray。无论采用哪种实现,本质目标都是根据文件偏移快速定位缓存页。例如读取文件第 64KB 数据时,内核可以直接通过 address_space 找到对应缓存页,而无需遍历整个缓存链表。
2.2 struct page 如何描述缓存页
Page Cache 的最小管理单位是页(Page),通常大小为 4KB。Linux 使用 struct page 描述每个物理页面,而文件缓存页本质上也是普通 struct page 的一种使用方式。当文件被读取到内存后,数据最终保存在这些缓存页中,典型结构如下:
struct page { unsigned long flags; atomic_t _refcount; struct address_space *mapping;};
其中 mapping 指向所属 address_space,因此缓存页能够与具体文件关联。当应用程序访问文件时,实际上访问的是 struct page 中保存的数据内容。对于 Page Cache 而言,核心关系可以简单表示为:
inode │ ▼address_space │ ▼XArray │ ▼struct page
整个 Linux 文件缓存体系正是建立在这一层层映射关系之上。
第三章 Page Cache 与块设备的数据读取流程
3.1 缓存命中的情况
当应用程序执行 read() 时,内核首先不会访问磁盘,而是查询 Page Cache。如果目标数据已经存在于缓存页中,那么整个过程完全在内存完成,典型调用链:
read() └─ vfs_read() └─ filemap_read() └─ page cache lookup
此时 filemap_read() 会根据文件偏移查找 address_space 中对应缓存页。如果缓存页存在,则直接通过 copy_to_user() 将数据返回给用户空间。整个过程中不会产生任何块设备访问,也不会构造 BIO 请求。从应用程序角度看是在读取文件,实际上读到的是内存中的缓存数据。
3.2 缓存未命中的情况
如果缓存页不存在,则发生 Page Cache Miss。此时内核需要向块设备发起读取请求,将数据加载到缓存后再返回给应用程序,调用流程如下:
filemap_read() │ ▼page cache miss │ ▼readpage() │ ▼submit_bio() │ ▼block device
磁盘返回数据后,内核会分配新的缓存页,将读取结果保存到 Page Cache,并挂接到对应 address_space。后续相同位置的数据再次访问时即可直接命中缓存。因此 Page Cache 不仅是缓存机制,同时也是磁盘数据进入内存的统一入口。
第四章 Page Cache 与块设备的数据写入流程
4.1 Dirty Page 的产生
与读取不同,写操作通常不会立即访问块设备。当应用程序执行 write() 时,Linux 首先将数据复制到 Page Cache,然后将缓存页标记为 Dirty Page,典型调用链:
write() └─ generic_perform_write() └─ copy_page_from_iter() └─ set_page_dirty()
此时 write() 已经返回成功,但数据实际上仍然位于内存中。Linux 采用这种延迟写入机制能够把多个小写请求合并成大块顺序写请求,从而提高磁盘利用率。这也是为什么突然断电时可能丢失最近写入数据的原因,因为这些数据可能尚未真正落盘。
4.2 脏页如何写回块设备
Dirty Page 不会永久停留在内存中。Linux 后台回写线程会周期性扫描脏页,并将其刷新到块设备,主要流程:
Dirty Page │ ▼writeback │ ▼writepages() │ ▼BIO │ ▼Block Layer │ ▼Disk
在这个过程中,文件系统负责确定脏页对应的磁盘块位置,随后构建 BIO 请求提交到块层。块层再根据设备特性进行调度并最终写入磁盘。因此块设备并不会直接看到 write() 请求,而是看到经过 Page Cache 聚合后的 BIO 请求。
第五章 Page Cache 与块层的连接机制
5.1 BIO 如何连接缓存页与磁盘
无论读请求还是写请求,Page Cache 最终都需要通过 BIO 与块设备交互。BIO 可以理解为块层的数据载体,它负责描述哪些页面需要读取或写入,以及对应的磁盘扇区位置。
BIO 内部最关键的数据结构是 bio_vec:
struct bio_vec { struct page *bv_page; unsigned int bv_len; unsigned int bv_offset;};
对于 Buffered I/O 而言,bv_page 指向的正是 Page Cache 中的缓存页。块层并不关心这些页面属于哪个文件,它只关心对应物理页和磁盘扇区。因此 BIO 成为文件系统与块设备之间最重要的数据桥梁。
5.2 块层为什么看不到文件
很多人认为磁盘在处理文件,其实这是错误的理解。块设备完全不知道文件概念,它只认识逻辑块地址(LBA)。文件系统负责将文件偏移转换成磁盘块号,然后构造 BIO 提交给块层,例如:
File Offset 128KB │ ▼Logical Block 32 │ ▼Physical Block 10000 │ ▼BIO │ ▼Disk
对于块设备来说,它看到的只是“向第 10000 号块读写数据”,并不知道这些数据属于哪个文件。因此文件系统、Page Cache 和块设备实际上处于完全不同的抽象层次。
第六章 Page Cache 与块设备的性能关系
6.1 Page Cache 带来的性能收益
Page Cache 最大价值在于减少磁盘访问次数。对于热点数据,大量读请求能够直接命中内存缓存,访问延迟从毫秒级降低到纳秒级。同时写请求可以在内存中聚合,形成更大的顺序写,从而减少随机 I/O 对磁盘性能的影响。
例如一个 Web 服务频繁读取相同静态文件,如果没有 Page Cache,每次请求都需要访问磁盘;而有了 Page Cache 后,文件首次加载进入内存,后续访问全部变成内存读取。对于现代服务器而言,大部分文件读取实际上都发生在 Page Cache 中,而不是磁盘上。
6.2 为什么数据库经常绕过 Page Cache
虽然 Page Cache 非常高效,但数据库往往更倾向于使用 O_DIRECT。原因在于数据库自身已经维护了 Buffer Pool,如果 Linux 再建立一份 Page Cache,就会形成双缓存问题。大量内存被重复占用,同时缓存淘汰策略也变得不可控,因此 MySQL、Oracle 等数据库通常采用如下路径:
Userspace Buffer │ ▼Direct I/O │ ▼BIO │ ▼Block Layer │ ▼Disk
而普通应用则更多采用:
Userspace │ ▼Page Cache │ ▼Block Device
两种模式没有绝对优劣,核心区别在于谁来负责缓存管理。Page Cache 适合通用场景,而 Direct I/O 更适合数据库和存储系统等需要完全掌控缓存策略的应用。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
