32岁零基础学Python量化第4周(下):Pandas核心知识点 (附泰坦尼克号生还率分析)
- 2026-06-27 14:16:31
Pandas
作为标签库,Pandas 对象在 NumPy 数组基础上给予其行列标签,Pandas 中,所有数组特性仍在,Pandas 的数据以 NumPy 数组的方式存储。本篇依旧是根据B站的爆肝杰哥的Python相关系列课程总结而来,同时分享了自己的踩坑记录,在这里感谢大佬的辛苦付出。
Pandas 知识点归纳
1. 创建及属性:
• 一维创建:pd.Series(value,index = ?) • 二维创建:pd.DataFrame({})/pd.DataFrame(value,index=?,columns=?)字典法: 先创建多个基于同样的index的Series对象,最后在DataFrame()中使用字典里的键值对将多个series对象和他们的列标签关联起来;数组法: 先创建一个numpy数组,然后在pd.DataFrame(value,index=?,columns=?)对Numpy数组的行列标签赋值.
v1 = [ 53, 64, 72, 82 ]i= [ '1 号', '2 号', '3 号', '4 号' ]v2 = [ '女', '男', '男', '女' ]i = [ '1 号', '2 号', '3 号', '4 号' ]sr1 = pd.Series(v1,index = i)sr2 = pd.Series(v2,index = i)df = pd.DataFrame({'年龄':sr1,'性别':sr2}) #字典法创建dfarr1 = np.array([[53,'女'],[64,'男'],[72,'男'],[82,'女']]) #设定value数组 i = [ '1 号', '2 号', '3 号', '4 号' ] #设定行标签c = ['年龄','性别'] #设定列标签df1 = pd.DataFrame(arr1,index = i,columns = c) #数组创建法df1• 属性:df.values,df.index,df.columns
2. 索引:
• 显示索引:pd.loc[行标签,列标签] • 隐式索引:pd.iloc[行位置,列位置] • 切片:iloc:隐式,按位置,左闭右开 [start, end)loc:显式,按标签 / 列名,闭区间 [start, end]
df1.loc[['1 号','3 号'],['性别','年龄']] #显式索引__花式索引df1.iloc[[0,2],[1,0]] #隐式索引__花式索引df1.loc['1 号':'2 号','年龄':'性别'] #显式切片,左右都闭df1.iloc[0:2,0:2] #隐式切片,左闭右开,Pandas切片有自动截断规则,结束下标超过最大索引时,会自动取到末尾3. 对象变形:转置、翻转、重塑、拼接
转置: df.T翻转: df.iloc[:,::-1] 左右翻转 df.iloc[::-1,:] 上下翻转重写:df['列标签']=Series新数据。添加列:df['新列']=Series/列表。添加行:df.loc['新行']=[数据]分离:sr = df['列标签']拼接:pd.concat([df1,df2],axis=1)axis=0:纵向拼接(增加行)。axis=1:横向拼接(增加列)。查重:pd数据.index.is_unique #确认行标签有无重复,返回True代表无重复,返回False代表有重复
# 数组法创建 srv1 = [10,20,30,40]v2 = ['女','男','男','女']v3 = [1,2,3,4]i = [ '1 号', '2 号', '3 号', '4 号' ]sr1 = pd.Series(v1,index = i)sr2 = pd.Series(v2,index = i)sr3 = pd.Series(v3,index = i)df1 = pd.DataFrame({'年龄':sr1,'性别':sr2})df1['牌照'] = sr3 #增加一列df1.loc['5 号'] = [50,'男',5] #使用显示索引增加一行df14. 对象的运算
• 运算机制:
1. 对象与系数运算:广播机制(所有值都加减乘除)。 2. 对象与对象运算:索引对齐。没有匹配索引的位置结果为 NaN(缺失值)。 3. 补充
• 使用 np.abs()、np.cos()、np.exp()、np.log() 等数学函数时,会保留索引; • Pandas 中仍然存在布尔型对象,用法与 NumPy 无异,会保留索引。
5. 对象的缺失值:发现、剔除、填补
• 发现缺失值:df.isnull()返回布尔矩阵,缺失处显示True,不缺为True。(.notnull()方法与之相反等同:.~isnull()) • 剔除缺失值:df.dropna()。默认删除含有NaN的行。how='all':仅当整行/整列都是NaN才删除。 • 填补缺失值:df.fillna(数值),fill意为填满,na意为缺失,即:填满缺失
1. method='ffill':用上一行(前向)的值填充。 2. method='bfill':用下一行(后向)的值填充。
v=[53,None,72,82]sr = pd.Series(v,index=['1 号', '2 号','3 号','4 号'])sr.fillna(0) #None用0填充sr.fillna(np.mean(sr)) #用均值填sr.fillna(method='ffill')#用前值填sr.fillna(method='bfill')#用后值填6. 导入Excel文件:
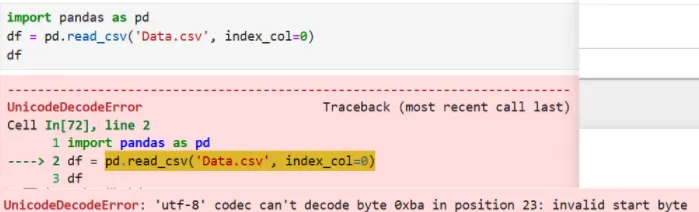
这里出现了错误,问题出在中文系统导出的文件它们默认编码是 GBK,不是 pandas 默认的UTF-8,因此要加encoding参数,并用编码gbk赋值,也可以在 Excel 中另存为 CSV 时,选择 “CSV UTF-8(逗号分隔)(*.csv)”,这样默认就是 UTF-8 编码,
改完以后可以读取csv内容了
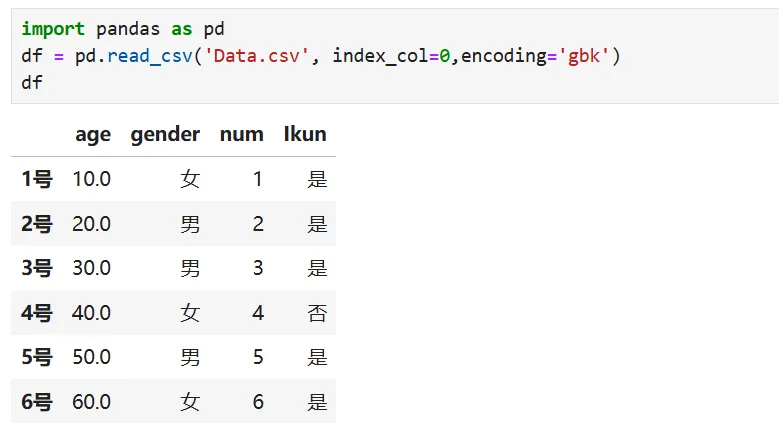
7. 数据的导入,聚合、描述方法,数据透视等
• 查看数据:.head() 查看前5行。 • 聚合方法:df.mean(), df.max(), df.std() 等,默认按列计算,自动忽略NaN(NumPy中所有的聚合函数对 Pandas对象均适用,Pandas 还将这些函数变为对象的方法,可不导入NumPy也可使用) • 描述方法:df.describe(),直接查看所有聚合函数信息:计数、均值、标准差、四个分位数(把数组从小到大排序后,0%、25%、50%、75%、100%五个位置上的数值的取值,50%分位点为中位数)。 • 数据透视表:df.pivot_table(values='目标列', index='分组行', columns='分组列', aggfunc='函数')。以values特征为考察核心,类似神经网络中的输出,研究其他特征(也就是index和columns)与之关系,最后默后aggfunc='mean'
df = pd.read_csv('泰坦尼克.csv',index_col = 0)df.pivot_table('是否生还',index = '性别',columns = '船舱等级')• 处理连续变量:使用pd.cut()(手动划分区间)或pd.qcut()(自动均等划分)对数值列进行分箱,再传入pivot_table的index或columns。
age = pd.cut(df['年龄'],[0,18,120]) #将年龄以18为分水岭进行分割df.pivot_table('是否生还',index = ['性别',age],columns = '船舱等级')fare = pd.qcut(df['费用'],2)df.pivot_table('是否生还',index = ['性别',age],columns = ['船舱等级',fare])Pandas 相关练习题
编程题1
假设有两个 Series:
sr1 = pd.Series([10, 20, 30], index=['A', 'B', 'C'])sr2 = pd.Series([1, 2, 3], index=['B', 'C', 'D'])请问执行 sr1 + sr2 后,结果中索引 A 对应的值是多少?索引 D 对应的值是多少?结果对象的数据类型变成了什么(int还是float)?答题:A值对NaN,D值对应NaN,结果为int解析: 1.pandas按索引标签对齐进行运算,一方有、另一方没有的索引对应数值会变成NaN;2.NaN属于浮点数float,所以整个Series自动升级为float64,上面答错。
编程题2
现有泰坦尼克号数据 df,包含列:是否生还 (0/1)、性别 (女/男)、年龄 (连续数值)、票价 (连续数值)。请使用 pd.cut 和 df.pivot_table 完成以下操作:将“年龄”分为三组:[0, 18] (少年), (18, 60] (青年), (60, 150] (老年),统计不同性别、不同年龄组下的平均生还率。(提示:你需要将 age 分箱后的结果作为 pivot_table 的 index 或 columns)。答题:
age = pd.cut(df['年龄'],[0,18,60,120])df.pivot_table('是否生还',index = '性别',columns = age)解析: 使用 pd.cut 将连续变量变为了分类变量,然后扔进 pivot_table 的 columns 或 index 中聚合,注意需将'年龄'分箱,需增加labels=['少年','青年','老年']
age = pd.cut(df['年龄'],[0,18,60,120])df.pivot_table('是否生还',index = '性别',columns = age)重难点总结
1. 索引器中的显示索引.loc[] 和隐式索引 .iloc[] 一定要分清,是核心内容必须掌握
结语
Pandas是神经网络及金融量化的重要工具,下篇我将更新实战项目来训练学习成果,对于本篇各位同学和前辈有什么心得或建议欢迎留言一起交流。谢谢看完,晚安~
推荐阅读
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- AI 赋能的 3Why 教学法——以 Python 程序设计课程为例
- 教程丨AI赋能Python-GEE遥感云大数据分析、可视化与Satellite Embedding创新
- Python Web开发:WebSocket实时通信
- 远洋课堂—Python AI基础:Matplotlib与Seaborn数据可视化
- 厦大的大佬终于把Python做成了漫画电子书!
- Python16个童年小游戏,新手也能做出属于自己的小游戏
- Python Web开发:缓存与性能优化
- 整理了,1885页 的 Python 从入门到进阶超全资料!
- Python Web开发:文件上传与下载
- 640页高清带书签!Python3从入门到精通!
