用Python做科研级画图——多模型对比(箱线/条形/点图组合)
- 2026-06-27 14:01:52
大家好,我是你们的小帅学长。
做模型评估时,很多人都经历过一个阶段就是前面每张图都会画——真值 vs 预测图会画,误差分布会画,分组误差也会画。可一到真正要“横向比较多个模型”的时候,问题就来了:
图太多,读者看不过来
指标太多,不知道该重点看什么
一个模型 R² 高,另一个模型 RMSE 低,到底谁更好?
有的模型平均表现好,但波动很大;有的模型很平稳,但峰值不够亮眼
这时候你会发现,多模型比较,考验的不是你会不会画图,而是你会不会组织证据。
所以这一篇,我们不再讲“单张图怎么画”,而是讲一个更高阶的问题:多模型对比,为什么要把箱线图、条形图、点图组合起来?
因为它们各自回答的问题根本不一样:
箱线图:看分布与稳定性
条形图:看核心指标汇总
点图:看清爽排序与差距结构
也就是说,真正有说服力的多模型对比,不是靠某一张图,而是靠一组互补的图。
01.为什么单一图形不够?
如果你只用条形图,你会得到很清楚的平均指标,比如 MAE、RMSE、R²。
但你看不到:模型误差分布是否偏态?是否有极端误差?模型稳定性如何?
如果你只用箱线图,你能看到分布结构,但读者又不容易快速抓到 平均水平谁最好、哪个模型整体更优、指标排序是什么样的?
如果你只用点图,排序很清楚,但统计结构又被弱化了。所以最稳的做法不是在一张图里塞满所有信息,而是用不同图形,分别承担不同任务。
02.多模型对比时,这三种图怎么分工?
1)箱线图:回答“稳不稳?”
箱线图非常适合放在多模型对比里,因为它一张图就能展示:中位数、四分位距、异常值、分布离散程度。
所以它最适合展示模型除了平均表现好不好之外,波动大不大?稳定不稳定?
在论文里,这种信息特别重要,因为审稿人不会只关心“最好结果”,也会关心“可重复性”和“鲁棒性”。
2)条形图:回答“平均水平谁最好?”
条形图适合承载那些“摘要性指标”,比如:RMSE、MAE、Bias、R²
它的优势是直接、快速、摘要性强。
一眼就能看出:排名、差距、提升幅度
所以条形图最适合回答,从整体指标上看,哪个模型最好?
3)点图:回答“排序关系清不清楚?”
点图其实特别适合多模型场景,因为它比条形图更轻、更清爽。
当模型很多(5 个以上)时,柱子会越来越重,而点图反而更容易保持版面轻盈。
所以点图最适合回答,如果我只想让读者一眼看到排序和差距,有没有比条形图更干净的方式?
答案就是:点图。
03.一个成熟的多模型对比逻辑是什么?
你可以把它理解成三层证据:
1)条形图
平均指标上,谁更强。
2)箱线图
这个“更强”是不是稳定的。
3)点图
最后用更清爽的方式强化排序与差距。
条形图给结论,箱线图给可信度,点图给排序感。
04.论文里最常见的两种组织方式
1)一张综合多面板图
例如做成 1×3 布局:
左:箱线图;中:RMSE 条形图;右:R² 点图。
优点是整合度高,适合放主文图。缺点是设计要求更高。
2)正文主图 + 补充图
例如:正文放条形图(讲核心结论)、补充材料放箱线图(讲稳定性)、再补一张点图(讲排序)。
05.论文级示例:箱线图 + 条形图 + 点图三联图
下面给你一份完整示例代码,画出一张多模型对比三联图:左:误差箱线图、中:RMSE 条形图、右:R² 点图
import osimport numpy as npimport matplotlib as mplimport matplotlib.pyplot as pltfrom matplotlib import font_manager as fmfrom sklearn.metrics import mean_squared_error, r2_score# =========================# 字体设置:英文 Times New Roman + 中文 SimSun# =========================win_fonts = r"C:\Windows\Fonts"for p in [os.path.join(win_fonts, "times.ttf"),os.path.join(win_fonts, "timesbd.ttf"),os.path.join(win_fonts, "timesi.ttf"),os.path.join(win_fonts, "simsun.ttc"),]:if os.path.exists(p):try:fm.fontManager.addfont(p)except Exception:passmpl.rcParams["font.family"] = ["Times New Roman", "SimSun"]mpl.rcParams["axes.unicode_minus"] = False# =========================# 输出路径# =========================OUT_DIR = r"D:\py_figs"os.makedirs(OUT_DIR, exist_ok=True)# =========================# 构造示例数据# =========================np.random.seed(42)model_names = ["Model A / 模型A", "Model B / 模型B", "Model C / 模型C", "Model D / 模型D"]y_true = np.random.uniform(280, 320, 400)preds = {"ModelA / 模型A": y_true + np.random.normal(0, 1.8, 400),"ModelB / 模型B": y_true + np.random.normal(0, 2.4, 400),"ModelC / 模型C": y_true + np.random.normal(0, 1.5, 400) + 0.4,"ModelD / 模型D": y_true + np.random.normal(0, 2.0, 400) - 0.3,}errors = []rmse_list = []r2_list = []for name in model_names:err = preds[name] - y_trueerrors.append(err)rmse_list.append(np.sqrt(mean_squared_error(y_true, preds[name])))r2_list.append(r2_score(y_true, preds[name]))# =========================# 三联图# =========================fig, axes = plt.subplots(1, 3, figsize=(14, 4.8))# ---------- (1) 箱线图:误差分布 ----------axes[0].boxplot(errors,patch_artist=True,widths=0.55,medianprops=dict(color="black", linewidth=1.5),whiskerprops=dict(color="black", linewidth=1.2),capprops=dict(color="black", linewidth=1.2),boxprops=dict(facecolor="white", edgecolor="black", linewidth=1.2),flierprops=dict(marker='o', markerfacecolor='white', markeredgecolor='black',markersize=4, linestyle='none'))axes[0].axhline(0, color="red", linestyle="--", linewidth=1.2)axes[0].set_xticks(range(1, len(model_names) + 1))axes[0].set_xticklabels(["A", "B", "C", "D"])axes[0].set_title("Error Distribution / 误差分布", fontsize=13)axes[0].set_ylabel("Error (K) / 误差", fontsize=11)# ---------- (2) 条形图:RMSE ----------order_rmse = np.argsort(rmse_list)# 从小到大names_rmse = [model_names[i] for i in order_rmse]vals_rmse = [rmse_list[i] for i in order_rmse]y_rmse = np.arange(len(names_rmse))axes[1].barh(y_rmse, vals_rmse)axes[1].set_yticks(y_rmse)axes[1].set_yticklabels(["A", "B", "C", "D"])axes[1].invert_yaxis()axes[1].set_title("RMSE Ranking / RMSE 排序", fontsize=13)axes[1].set_xlabel("RMSE (K)", fontsize=11)for yi, v in zip(y_rmse, vals_rmse):axes[1].text(v + 0.03, yi, f"{v:.2f}", va="center", fontsize=10)# ---------- (3) 点图:R² ----------order_r2 = np.argsort(r2_list)[::-1]# 从大到小names_r2 = [model_names[i] for i in order_r2]vals_r2 = [r2_list[i] for i in order_r2]y_r2 = np.arange(len(names_r2))axes[2].scatter(vals_r2, y_r2, s=70)for yi, v in zip(y_r2, vals_r2):axes[2].plot([0, v], [yi, yi], linewidth=1.0)axes[2].text(v + 0.002, yi, f"{v:.3f}", va="center", fontsize=10)axes[2].set_yticks(y_r2)axes[2].set_yticklabels(["A", "B", "C", "D"])axes[2].invert_yaxis()axes[2].set_xlim(left=0)axes[2].set_title("R² Ranking / 排序", fontsize=13)axes[2].set_xlabel("R²", fontsize=11)# ---------- 边框优化 ----------for ax in axes:for spine in ax.spines.values():spine.set_linewidth(1.2)fig.suptitle("Multi-model Comparison / 多模型对比", fontsize=15, y=1.02)out_path = os.path.join(OUT_DIR, "multi_model_comparison_suite.jpg")fig.savefig(out_path, dpi=300, bbox_inches="tight", pad_inches=0.05)plt.close(fig)print("Saved:", out_path)
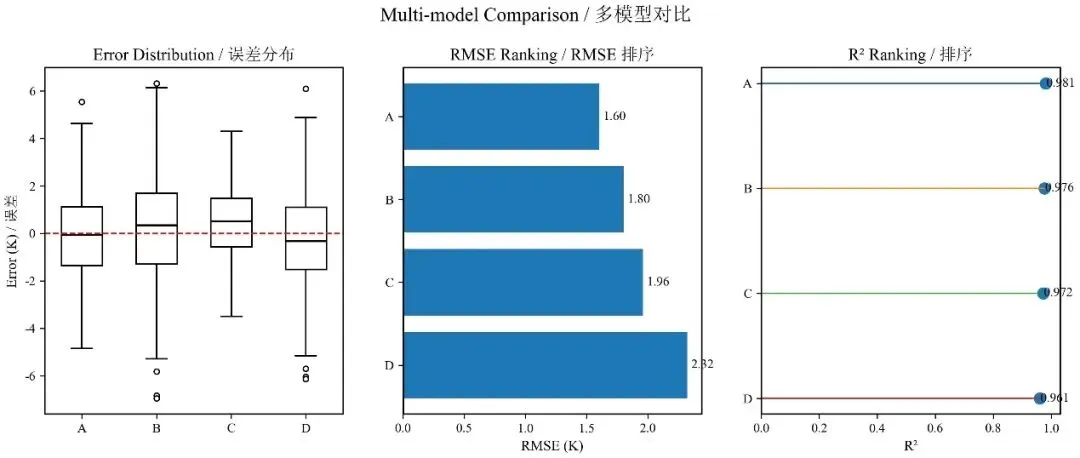
多模型对比不是把几个数字排一排,而是把“平均水平、误差结构、排序差距”同时讲清楚——箱线图看稳定性,条形图看核心指标,点图看清爽排序,这三者组合起来,才是真正有说服力的模型比较。
下一篇我们会把这一整套思路再往前推进一步,进入一个非常实用、也非常适合你后续复用的模块:《一张“评估图套件”模板》。这一篇我会把前面讲过的真值 vs 预测、误差分布、分组误差、多模型对比这些思路,整理成一套可直接复用的模板逻辑,让你以后评估任何模型时,都能一键生成一组“像论文”的完整图件。
——期待你的关注——
往期内容:
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 大一Python期末考端午放心玩反正重复率达90%
- python怎么学不枯燥,用python自带的画图库——用python画一朵樱花树,效果还不错
- Python数据分析机器学习与深度学习实战
- 教程丨最新AI+Python驱动的高光谱遥感全链路解析与典型案例实践
- Python期末考前小抄,附答案,刷完稳拿95+
- 三天Python语言期末95+
- Python爬虫基础概念及理念
- python学习顺序千万别搞反了.
- 职场必备!Python一键自动化生成各类报表,附带可直接运行案例
- Python自动化办公入门——每天10分钟,Excel/Word/PDF批量处理省掉一半加班
