【粉丝真实需求】外贸办公 Python 自动化・提单水印批量实战 2/6
- 2026-06-21 06:56:29
【粉丝真实需求】外贸办公 Python 自动化・提单水印批量实战 2/6点击上方“Python爬虫与数据挖掘”,进行关注 上一篇文章我们已经知悉了客户的真实业务需求,大概是将.doc文件中的艺术字体中的艺术字替换为另外一个单词,保证颜色、字体、艺术字体等全部不变的情况下,仅仅需要修改文字即可。这一篇文章我们来讲解下具体的实战部分。 实战部分的代码都是我找豆包用AI写的,然后不断的去给他调整,最后优化后得到的,下面具体看下具体的实现过程。 
实战中,我根据AI提示,把文件转为了.docx格式,其中核心库python-docx需要提前安装,打开电脑的cmd,输入安装的命令如下: 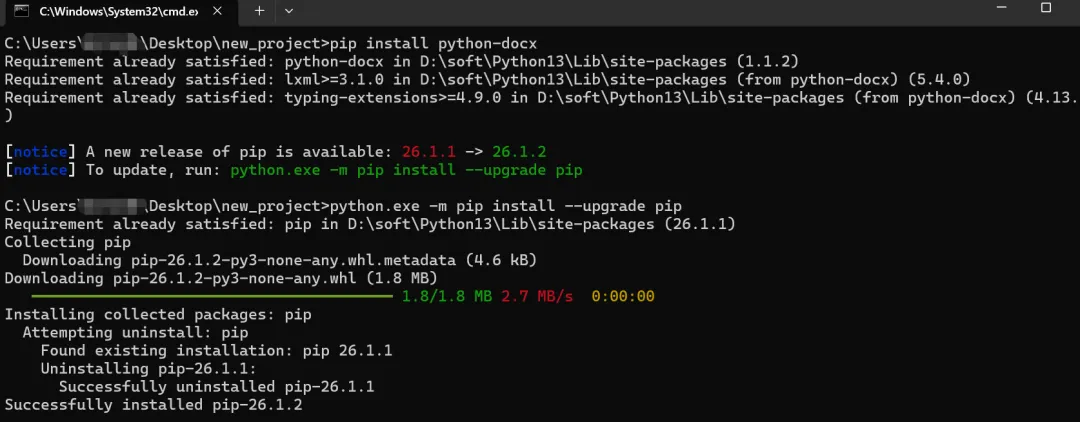
然后让豆包给我写了第一份代码,代码如下: 让我意外的是代码竟然能够顺利运行,相当于一把过! 
正当我欣喜交加的时候,打脸瞬间而来。虽然程序能跑,但是跑出来的结果不合人意。压根儿就没有完成替换,替换的地方肯定不对,不满足客户的需求。于是乎,重新让AI返工。 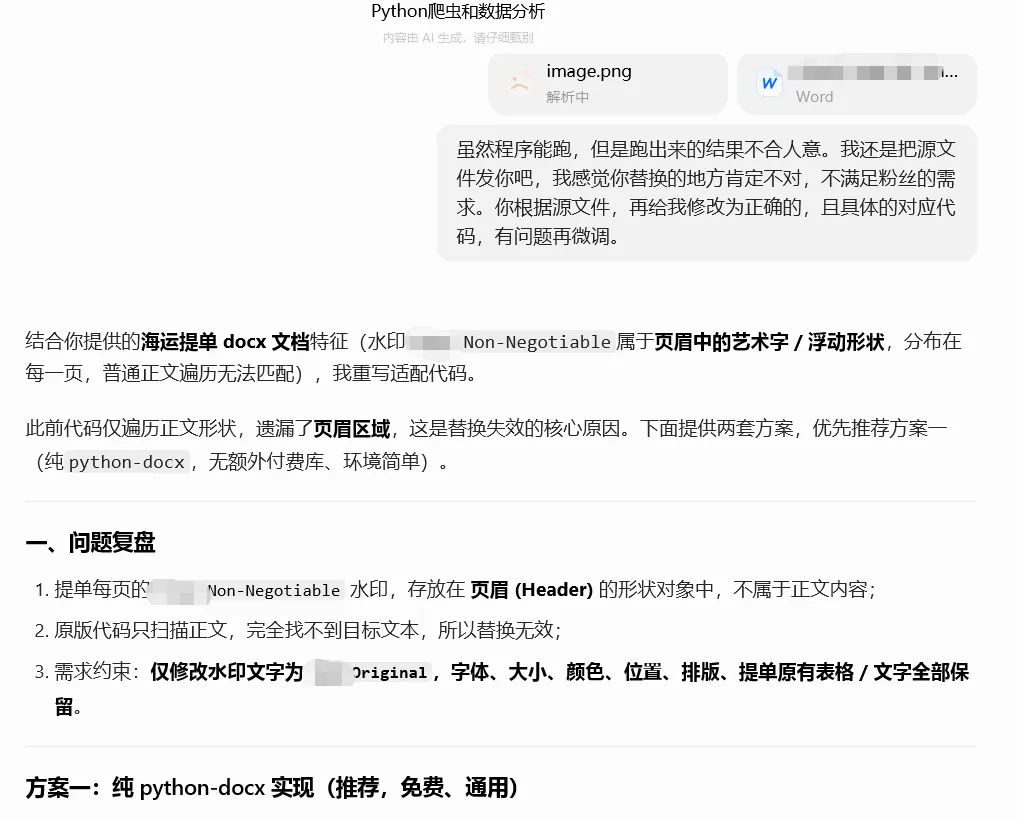
这里代码就不贴了,反正运行后也是继续报错,直接贴报错截图。 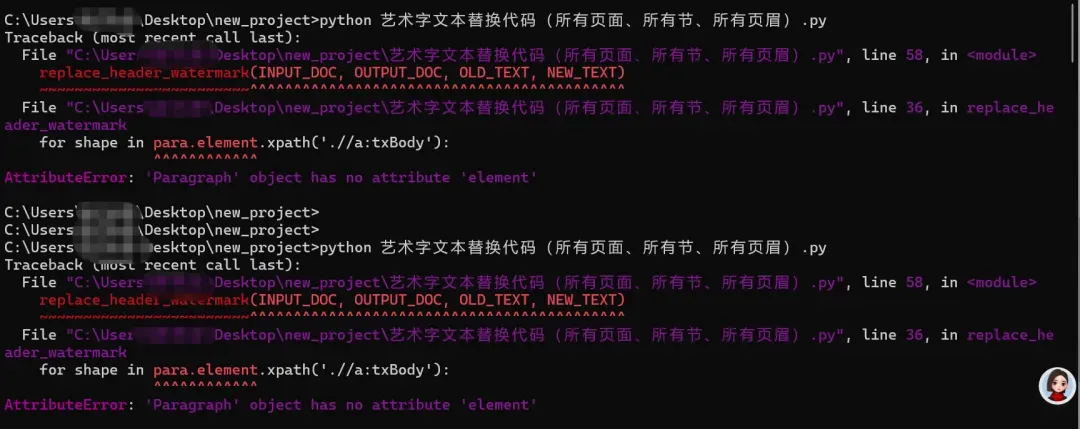
AI给出了解答:结合你反馈的报错以及提单文档特征(水印属于页眉浮动艺术字 / 文本框,python-docx 对这类复杂形状兼容性差),我提供两套可稳定运行的修复方案,优先推荐 Windows + Word 环境下的 pywin32 方案(适配办公类 Word 艺术字、页眉、文本框,成功率几乎 100%),同时保留兜底 XML 方案。 我这里继续采用了pywin32 方案,安装pywin32库后,执行代码,发现能运行成功。 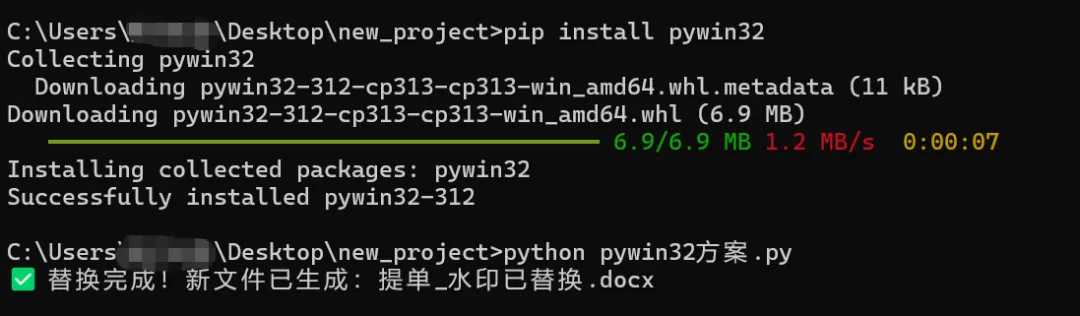
然后跑去打开生成的新文件验证结果。发现仍然不尽人意,压根儿就没完成替换。 
它又给了我一份新代码,微调了下,于是乎我再去跑。 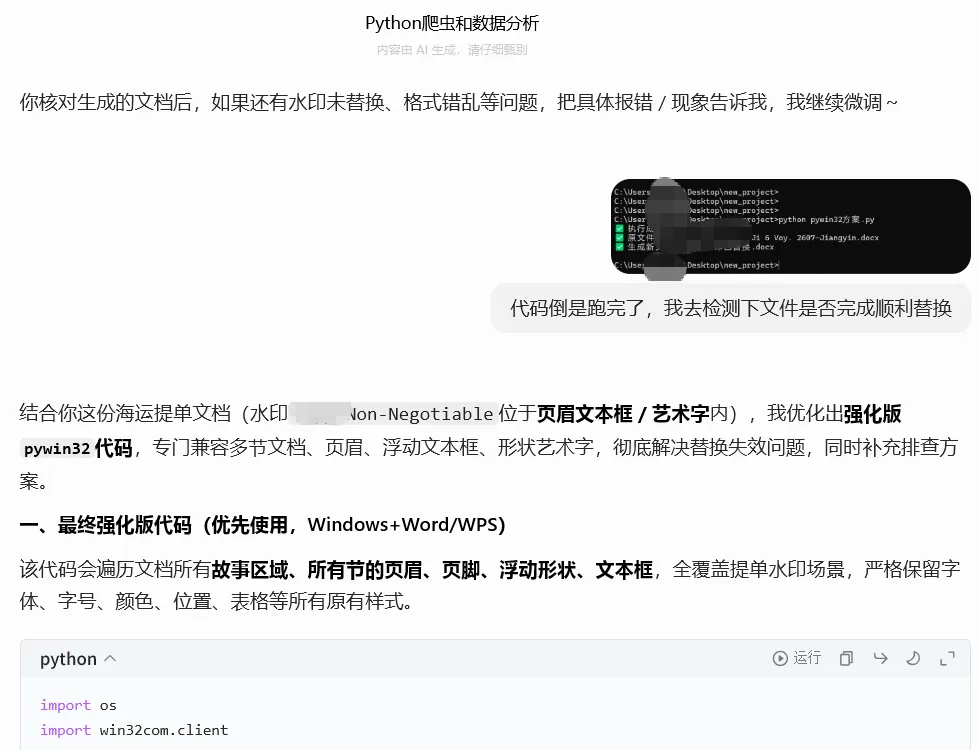
wish today啊!实在是有些遭不住了,看上去并没有完成替换,原来的艺术字体仍然存在。 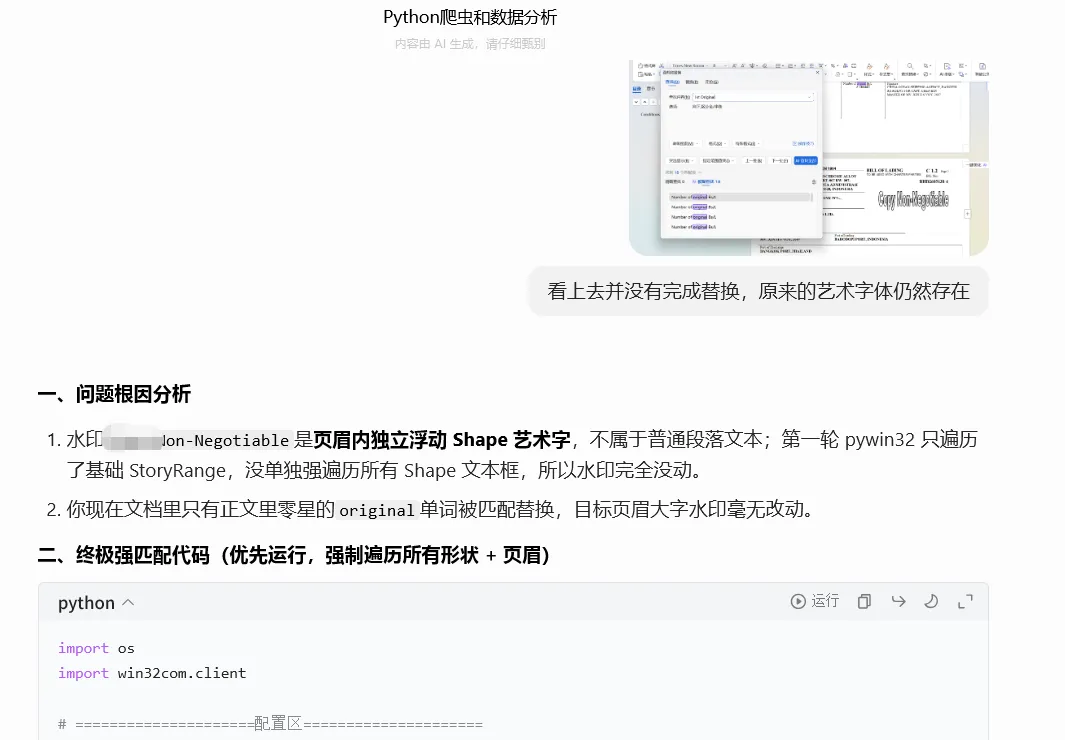
上面它又给出了一份代码,我执行后,虽然能执行成功,但是发现仍然无效。与此同时,我也发现一个奇怪的现象,就是我打开源文件,直接搜关键词Non-Negotiable,但是提示找不到。可是明明我肉眼就看得到它。 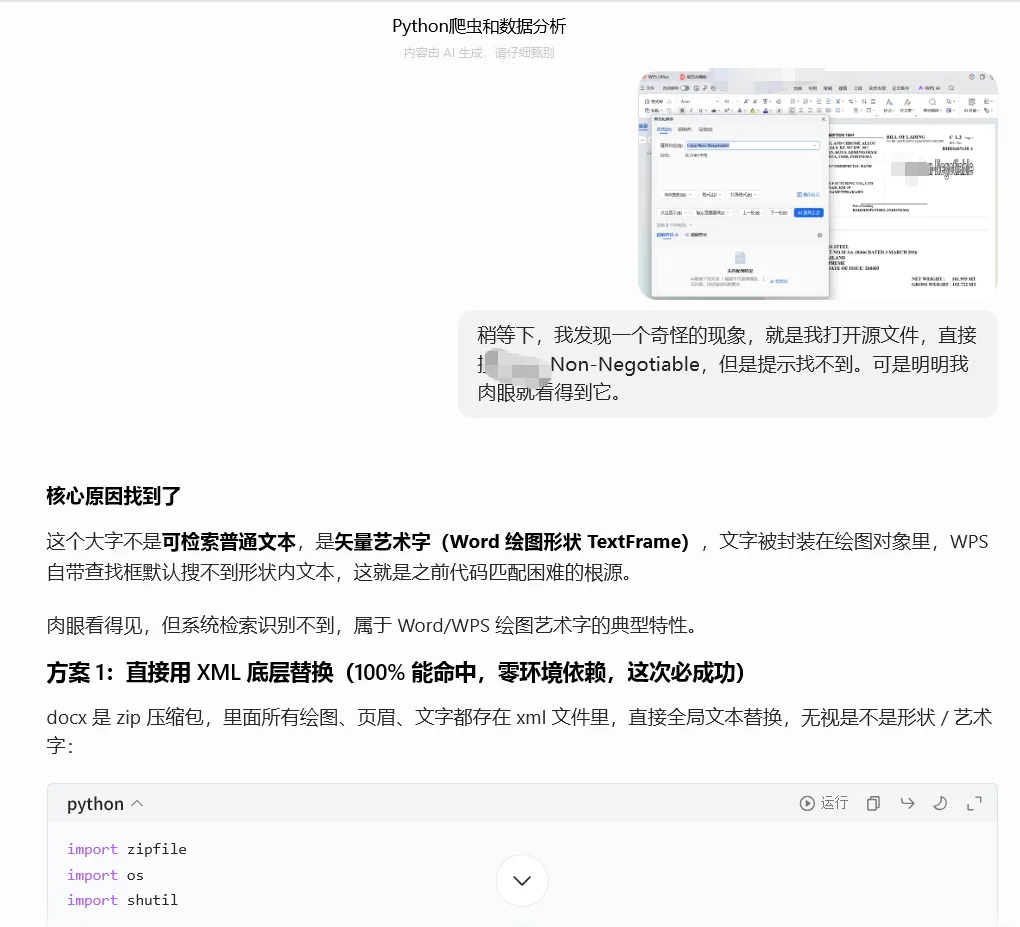
执行代码后,报了一个编码错误。 
继续找豆包帮忙微调了下,最终的代码如下: 这把代码执行后顺利运行,而且得到的新文件内容也确实符合预期。 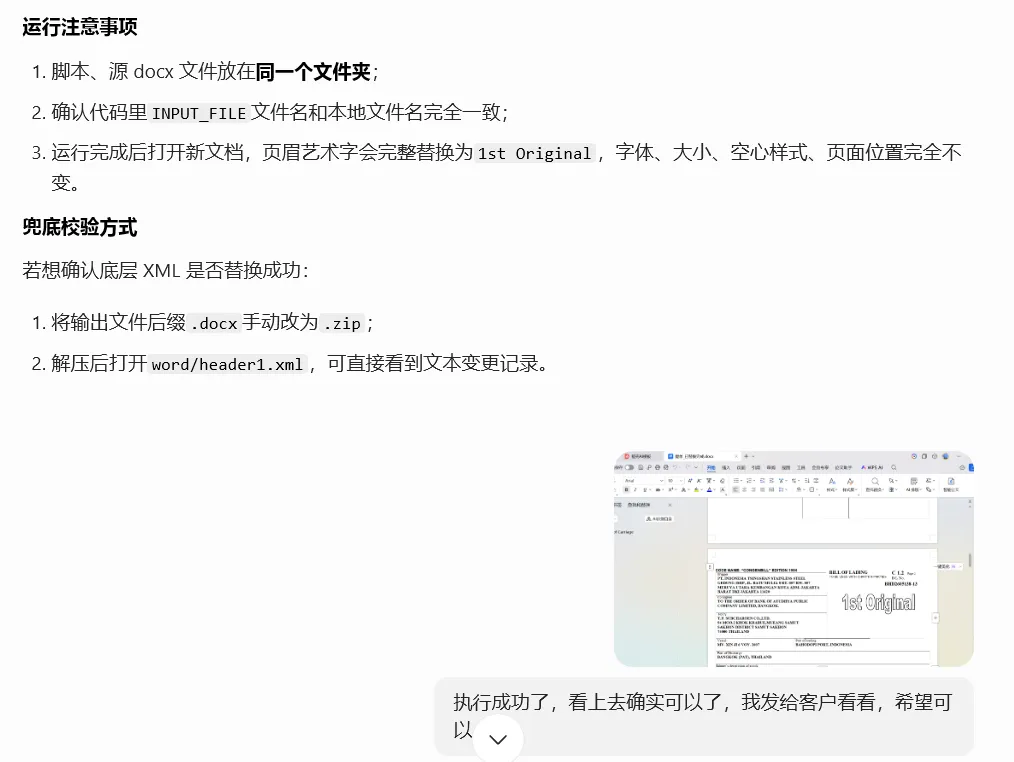
你以为就结束了?NO!这一篇文章,我们记录了依次踩坑 1|doc≠docx!直接 zip 解压代码第一波报错翻车、踩坑 2|win32com 遍历文档 Shape,页眉艺术字完全抓取不到(匹配数始终 0)、踩坑 3|WPS 兼容大坑:访问页眉 Shapes 直接抛 <unknown>.Shapes 属性错误等等。虽然踩坑多多,但是总算是雏形已成。下一篇文章我将带大家进入客户需求调整篇,敬请期待,咱们下期见,不见不散。 
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
春风又绿江南岸,明月何时照我还。
前一阵子针对近期爆火的《给阿嬷的情书》电影写了一篇Python网络爬虫+数据分析文章,基于 Python 的《给阿嬷的情书》豆瓣短评文本挖掘与情感分析(附数据分析代码),当前阅读量已经突破1.2w了,是今年迄今为止本公众号阅读量最高的一篇文章。正是因为这篇文章的贡献,也让许多粉丝慕名前来,加上了好友。部分粉丝在工作和学习中,遇到了一些难题,提了一些自己的需求,我把需求也及时同步发布到我的接单群了。
pip install python-docxfrom docx import Documentfrom docx.oxml import parse_xml# ======================配置区,按需修改文件名======================source_file = "Original.docx" # 你的源docx文件名output_file = "修改后_提单Original.docx" # 输出新文件名称old_text = "Non-Negotiable"new_text = "xxx Original"# =================================================================def replace_shape_text(doc_path, out_path, target_old, target_new):doc = Document(doc_path)# 遍历文档每一节、每一页所有形状for section in doc.sections:# 1. 遍历正文内所有浮动Shape(提单里大字水印属于浮动形状)for shape in doc.element.xpath('.//a:blip/../..//a:txBody'):# 获取文本段落text_body = shape.find('.//a:p')if text_body is None:continuefull_text = ""run_list = []# 提取所有文字片段for r in text_body.xpath('.//a:r'):t_node = r.find('.//a:t')if t_node is not None and t_node.text:full_text += t_node.textrun_list.append((r, t_node))# 匹配目标旧文字if full_text.strip() == target_old.strip():# 只替换文字内容,完全复用原有字体、大小、颜色、位置、轮廓# 清空原有文字节点for r, t in run_list:t.text = ""# 写入新文字到第一个文字节点,继承全部样式属性if run_list:first_t = run_list[0][1]first_t.text = target_new# 多余空run删除,避免空白占位for idx in range(1, len(run_list)):run_list[idx][0].getparent().remove(run_list[idx][0])# 保存修改后的文档doc.save(out_path)print(f"✅ 替换完成!新文件已生成:{out_path}")# 执行替换replace_shape_text(source_file, output_file, old_text, new_text)
import zipfileimport osimport shutil# 配置区INPUT_FILE = "Original.docx"OUTPUT_FILE = "提单_已替换完成.docx"OLD_STR = "xxx Non-Negotiable"NEW_STR = "xxx Original"TEMP_FOLDER = "temp_unzip_cache"# 清理旧临时文件夹if os.path.exists(TEMP_FOLDER):shutil.rmtree(TEMP_FOLDER)os.mkdir(TEMP_FOLDER)# 1. 解压docx(移除多余encoding参数)with zipfile.ZipFile(INPUT_FILE, "r") as zip_ref:zip_ref.extractall(TEMP_FOLDER)# 2. 遍历全部XML文件,全局替换文本for root, _, files in os.walk(TEMP_FOLDER):for filename in files:if filename.endswith(".xml"):full_path = os.path.join(root, filename)with open(full_path, "r", encoding="utf-8") as f:xml_content = f.read()if OLD_STR in xml_content:xml_content = xml_content.replace(OLD_STR, NEW_STR)with open(full_path, "w", encoding="utf-8") as f:f.write(xml_content)# 3. 重新打包生成新docxwith zipfile.ZipFile(OUTPUT_FILE, "w", zipfile.ZIP_DEFLATED) as new_zip:for root, _, files in os.walk(TEMP_FOLDER):for filename in files:full_path = os.path.join(root, filename)relative_path = os.path.relpath(full_path, TEMP_FOLDER)new_zip.write(full_path, relative_path)# 删除临时缓存目录shutil.rmtree(TEMP_FOLDER)print(f"✅ 处理结束,输出文件:{OUTPUT_FILE}")
-----------------------------------
今日鸡汤分享:愿你披星戴月走过的路开遍繁花,愿每个破浪乘风的梦,都得偿所愿,加油!
说明:我平时有正式工作,只做兼职副业,只接合理、合法、正规用途的需求,不接违法、违规、恶意攻击类项目。有需要的朋友可以直接留言。加了我微信后,我会自动发送一些自动回复,如有打扰,请忽略即可。那个都是我的微信,绝对是真人,你给我正常发消息即可,必回!
大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的vx:2584914241),应粉丝要求,我创建了一些高质量的Python学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群。
------------------- End -------------------
往期精彩文章推荐:
欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python全栈系统课程:从入门到项目实战,当年花3W学的值得一看
- 第四课:Python 速成 —— 看懂 Agent 代码的最小必备
- CCF GESP 2026 年 3 月 Python 一级认证 | 完整真题 + 答案 + 超详解析
- 逼自己练完这40个项目,你的Python自动化办公就很牛了...
- 中篇Python(ODOO)篇 第四章 ODOO项目优化部分(四)预约模块增强 共用函数等
- 进阶AI数据分析:AI+Python搭建数据分析智能体
- 16种Python 常见数据分析算法(含代码)
- Python 虚拟环境终极指南:从 venv 到 uv,包管理从未如此丝滑
- 目前学Python进步最快的方法(个人觉得)
- 简历写了精通Python却心虚?吃透这20个常见面试题,面试绝对不抖
