工业Python调试技巧:从print到专业调试器
- 2026-06-21 06:57:47
🔥 你是不是也这样调试代码的?
凌晨两点。生产环境报警。
你盯着屏幕,手指悬在键盘上,脑子里只有一个念头:这个bug到底藏在哪?
然后,肌肉记忆接管了一切——你开始疯狂地往代码里插print()。
python1print("到这里了")2print("变量值:", some_var)3print("=====分割线=====")说实话,我在工业自动化项目里摸爬滚打了这么多年,见过太多这种场景了。不光是新手,就连工作了七八年的老鸟,紧张起来也照样靠print救场。这没什么丢人的——但问题是,这种方式在复杂系统里会把你坑得很惨。
一个工业控制系统,往往同时跑着十几个线程,设备通信、数据采集、状态机、告警逻辑全搅在一起。你插的那几行print,在高频循环里瞬间刷屏,有用的信息全淹没了;更糟的是,print本身有I/O延迟,在时序敏感的场景下,它甚至会改变bug出现的时机——你以为修好了,其实只是让问题藏得更深。
这篇文章,咱们就从实战角度,聊聊怎么从"print工程师"升级成真正会用调试工具的开发者。Windows环境下,Python调试这件事,其实可以做得很优雅。
🧩 第一关:认清print调试的真实代价
先不急着介绍工具,得把问题说清楚。
print调试最大的问题不是"不专业",而是信息密度太低、干扰太多、无法持久化。想象一下,你在一个设备采集程序里,每隔50毫秒触发一次数据读取,如果你在循环体里加了print,控制台每秒刷20条信息。三分钟后,你的终端历史里有3600条输出——你怎么找?
更要命的是Heisenbug现象(借用量子力学里的不确定性原理):某些bug只在特定时序下出现,一旦你加了print引入了额外耗时,bug就消失了。等你把print删掉,它又回来了。这种情况在串口通信、Modbus轮询这类对时序敏感的工业场景里,简直是家常便饭。
python1# 这段代码,加了print之后可能永远复现不了bug2while True:3 data = serial_port.read(64)4print(f"收到数据: {data}") # 这行I/O耗时可能打破原有时序5process_data(data)认清了这一点,我们才能真正理解后面的工具为什么值得学。
🛠️ 第二关:logging模块——print的成年版
别小看标准库里的logging,很多人用了好几年Python都没真正用好它。
基础配置,但要配对
python1import logging2import sys3from pathlib import Path456def setup_logger(name: str, log_file: str = None, level: int = logging.DEBUG):7"""8 工业项目推荐的 logger 配置方式9 同时输出到控制台和文件,方便事后分析10 """ logger = logging.getLogger(name)11 logger.setLevel(level)12 logger.propagate = False # 避免重复向 root logger 传递1314# 防止重复添加 handler15if logger.handlers:16return logger1718 formatter = logging.Formatter(19 fmt='%(asctime)s.%(msecs)03d | %(levelname)-8s | %(name)s | %(funcName)s:%(lineno)d | %(message)s',20 datefmt='%Y-%m-%d %H:%M:%S'21 )2223# 控制台 handler24 console_handler = logging.StreamHandler(sys.stdout)25 console_handler.setFormatter(formatter)26 console_handler.setLevel(logging.INFO) # 控制台只看 INFO 以上27 logger.addHandler(console_handler)2829# 文件 handler,DEBUG 级别全记录30if log_file:31 log_path = Path(log_file)32if log_path.parent and str(log_path.parent) != '.':33 log_path.parent.mkdir(parents=True, exist_ok=True)3435 file_handler = logging.FileHandler(log_path, encoding='utf-8')36 file_handler.setFormatter(formatter)37 file_handler.setLevel(logging.DEBUG)38 logger.addHandler(file_handler)3940return logger414243if __name__ == "__main__":44 logger = setup_logger('device_controller', 'device.log')4546 raw_value = 0x123447 logger.info("设备连接成功")48 logger.debug(f"寄存器原始值: {raw_value:#06x}")49 logger.warning("通信重试次数超过阈值")50 logger.error("设备响应超时,进入保护模式")
注意这个时间格式里有毫秒(%(msecs)03d)——在工业调试里,毫秒级时间戳是刚需,不是可选项。两个事件差了80毫秒还是800毫秒,结论可能完全不同。
日志分级,这才是精髓
很多人把logging当print用,全部塞INFO级别。正确的做法是:
▸ DEBUG:变量中间值、函数进出、协议帧内容——只在开发时开启▸ INFO:正常业务流程节点,比如"设备上线"、"任务开始"▸ WARNING:异常但可恢复的情况,比如"重试第2次"▸ ERROR:需要人工介入的问题▸ CRITICAL:系统级故障,可能需要停机
生产环境把根logger设成WARNING,开发时设成DEBUG。一行配置的事,但能让你的日志文件从几GB缩减到几MB。
🔬 第三关:pdb——命令行调试器,别怕它
很多Windows开发者对pdb有一种莫名的抵触,觉得这是Linux老头儿用的东西,"我有IDE为什么要用命令行"。
这种想法,在某些场景下会让你付出代价。
比如你的程序是作为Windows服务运行的,没有GUI;比如你需要在远程服务器上调试;比如你的IDE在某个奇怪的多进程场景下断点就是不触发——这时候pdb是你唯一的朋友。
三种进入pdb的方式
python1# 方式一:硬编码断点(Python 3.7+推荐)2# 直接在代码里插入,比import pdb; pdb.set_trace()更简洁3breakpoint()45# 方式二:命令行启动6# python -m pdb your_script.py78# 方式三:异常后进入(事后分析神器)9# python -m pdb -c continue your_script.py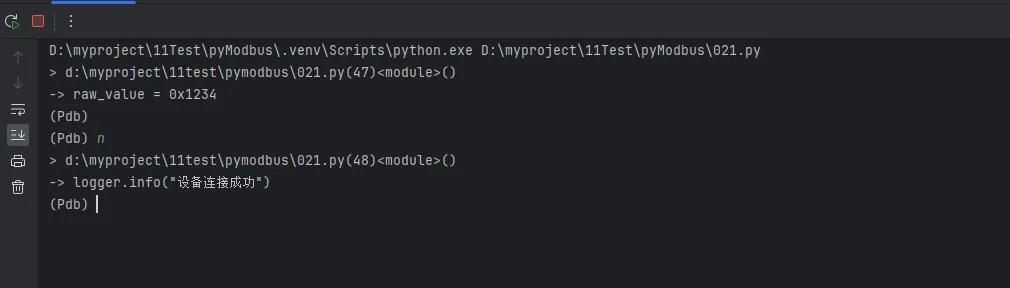
breakpoint()这个内置函数是Python 3.7加的,可以通过环境变量PYTHONBREAKPOINT控制行为——设成0就全局禁用所有断点,不用一个个删,上线前跑一条命令的事。
pdb核心命令,记住这几个就够用
n | |
s | |
c | |
l | |
p 变量名 | |
pp 变量名 | |
w | |
b 行号 | |
q |
实战技巧:进入pdb后,直接输入Python表达式就能执行。p [x for x in device_list if x.status == 'error']——这种交互式查询,比你在代码里写临时print强多了。
🚀 第四关:VS Code调试器——Windows开发者的主战场
好,回到我们熟悉的图形界面。VS Code的Python调试器,很多人只会点"Run and Debug"然后F5,其实它能做的事远不止这些。
launch.json,必须手写的配置
项目根目录下.vscode/launch.json,这个文件是调试的灵魂:
json1{2"version": "0.2.0",3"configurations": [4 {5"name": "调试主程序",6"type": "python",7"request": "launch",8"program": "${workspaceFolder}/main.py",9"console": "integratedTerminal",10"justMyCode": false,11"env": {12"PYTHONBREAKPOINT": "0",13"LOG_LEVEL": "DEBUG"14 },15"args": ["--config", "dev_config.yaml"]16 },17 {18"name": "附加到运行中的进程",19"type": "python",20"request": "attach",21"connect": {22"host": "localhost",23"port": 567824 },25"justMyCode": false26 }27 ]28}注意"justMyCode": false这一项——默认是true,意味着调试器会跳过第三方库的代码。但在工业项目里,你有时候就是需要进到pyserial或者pymodbus里面看看到底发生了什么。把它关掉,你才能看到完整的调用链。
条件断点——这个功能用好了能省一半时间
右键点击断点,选"Edit Breakpoint",可以设置触发条件:
1# 只在第500次循环时触发2loop_count == 50034# 只在特定设备出问题时暂停5device_id == 'PLC_003' and response_time > 20067# 只在数据异常时停下来8len(data_buffer) > 1024 or checksum_error == True这玩意儿在调试偶发性问题时简直是救命稻草。你不需要让程序跑到第500次再手动暂停,条件断点帮你守着。
监视表达式,实时追踪状态
调试面板左侧有个"WATCH"区域,可以添加任意Python表达式,程序暂停时自动求值:
python1# 可以添加这类表达式到Watch面板2len(message_queue)3[d.name for d in devices if d.connected]4time.time() - last_heartbeat_time比你每次暂停都手动在Debug Console里输入要方便得多。
🔍 第五关:py-spy——不停机的性能诊断
前面说的都是功能性bug的调试。但工业项目里还有另一类问题:程序跑着跑着就慢了,CPU占用莫名升高,但没有明显报错。
这时候需要的不是断点调试,而是性能剖析(Profiling)。
py-spy是Windows上最好用的Python性能分析工具之一,它的绝技是可以附加到正在运行的进程,不需要重启,不需要修改代码:
bash1# 安装2pip install py-spy34# 查看正在运行的Python进程的实时调用栈5py-spy top --pid 1234567# 生成火焰图(SVG格式,浏览器直接打开)8py-spy record -o profile.svg --pid 12345 --duration 30生成的火焰图,横轴表示时间占比,纵轴是调用栈深度。哪个函数占的面积最大,就是你的性能瓶颈所在。我在一个数据采集项目里,用这个工具三分钟就定位到了一个隐藏在数据解析函数里的正则表达式——那个正则每次都重新编译,白白吃掉了40%的CPU。
🧵 第六关:多线程调试的特殊技巧
工业软件几乎不可避免地要用多线程。而多线程调试,是让很多开发者头疼的硬骨头。
给每个线程命名,这是基本素养
python1import threading23# 不要用默认的Thread-1, Thread-2这种名字4comm_thread = threading.Thread(5 target=communication_worker,6 name="Modbus通信线程", # 这个名字会出现在日志和调试器里7 daemon=True8)910# 在日志里记录线程信息11logger.debug(f"[{threading.current_thread().name}] 开始读取寄存器")线程安全的日志记录
logging模块本身是线程安全的,但你的自定义处理逻辑不一定是。如果多个线程同时写状态变量,要用锁:
python1import threading23class DeviceStateManager:4def __init__(self):5 self._lock = threading.RLock() # 用RLock而不是Lock,支持同一线程重入6 self._states = {}78def update_state(self, device_id: str, state: dict):9with self._lock:10 self._states[device_id] = state11 logger.debug(f"状态更新: {device_id} -> {state}")1213def get_state(self, device_id: str):14with self._lock:15return self._states.get(device_id, {})死锁检测:一个实用的小技巧
遇到程序卡死怀疑死锁?在Windows下,对运行中的Python进程发送信号不太方便,但可以用这个方法:
python1import faulthandler2import signal34# 在程序启动时加上这两行5faulthandler.enable() # 崩溃时自动打印所有线程的调用栈67# 或者定时转储线程状态到文件8faulthandler.dump_traceback_later(timeout=30, repeat=True, file=open('thread_dump.txt', 'w'))程序卡住的时候,thread_dump.txt里会有所有线程当前在做什么——死锁的线程通常会卡在acquire()调用上,一眼就能看出来。
📊 实战案例:一次完整的调试流程
让我把上面说的东西串起来,演示一个真实场景。
问题描述:一个Modbus数据采集程序,运行约两小时后开始出现数据丢失,但没有任何报错。
第一步:加上结构化日志,记录每次读取的时间戳和数据量:
python1logger.debug(f"读取完成 | 寄存器:{start_addr}-{start_addr+count} | 耗时:{elapsed_ms:.1f}ms | 数据量:{len(result)}字节")第二步:用py-spy top观察两小时后的CPU状态,发现一个叫_cleanup_buffer的函数占用异常高。
第三步:在VS Code里对_cleanup_buffer设置条件断点,条件是len(self.buffer) > 10000,等待触发。
第四步:断点触发后,在Watch面板里查看self.buffer的内容,发现缓冲区里积压了大量未处理的历史数据——原来是清理逻辑有个边界条件错误,在特定数据包大小下会跳过清理。
整个过程,从问题定位到根因确认,不到40分钟。如果靠print硬撑,两小时的运行日志里翻找,可能一天都找不到。
🎯 调试工具选择指南
不同场景用不同工具,这才是老手的思维方式:
▸ 快速验证逻辑: logging.debug(),比print多不了几个字,但信息量翻倍▸ 复杂逻辑单步追踪:VS Code调试器 + 条件断点 ▸ 没有GUI的环境: pdb+breakpoint()▸ 性能瓶颈定位: py-spy record生成火焰图▸ 多线程死锁排查: faulthandler+ 线程转储▸ 生产环境事后分析:结构化日志文件 + 日志分析工具
写在最后
调试能力,是区分"能写代码"和"能驾驭代码"的分水岭。
工业项目的复杂度不是普通业务系统可以比的——设备通信、实时性要求、多线程并发、长时间稳定运行,这些因素叠加在一起,让每一个bug都可能变成一场持久战。
掌握专业调试工具,不是为了显得高级,而是真的能在关键时刻少掉几根头发。从今天开始,试着把项目里的print调试替换成logging,在VS Code里配一个像样的launch.json——这两步,就能让你的调试效率有肉眼可见的提升。
剩下的,交给时间和实践。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 新装Linux系统网络不通?老司机手把手教你从诊断到修复,一篇全搞定
- Oracle Enterprise Linux 7.9单机安装Oracle 19c数据库
- 2026年权威发布:嵌入式linux开发板厂家怎么选?此文深度解析+避坑指南分享
- Python 零基础100天—Day32 综合练习
- Linux禁ping,一文学会!
- 科研必备|电力系统优化调度原创算法【附python代码】均未发表!
- 【第40期】21天养成编程习惯:Python刷题第08天
- Python学习【179】:从零构建 Apache Doris 单节点集群:FE与BE核心概念及 Docker 实战指南
- AI CAE 仿真进化论 02|从 Python 脚本到 AI Agent,Abaqus 如何变成可调用的工程环境?
- 一个注重隐私的 CircuitPython IDE
