写在前面的话
执行规则。昨天,一女孩找到我,要上号,她说:头100块不能收运营费哦,因为她朋友就享受这个优惠,要不然就不挂号了。我说:妹妹,你路过一个超市,门口说搞活动,消费20块钱,送十个鸡蛋,过了三个月,你去那个超市买东西,人家不送鸡蛋了,你就不买东西了吗。女孩:那不一样,那是实物,你这是虚拟的,送不送还不是你一句话。我说:既然制定了规则,就要执行,要不然,我制定它干啥呢,你去别的运营群看看吧。那女孩最终还是上号了,因为她发现我这给的分成多,但有点不开心,像失去了十个亿。我当时有些冲动,想着给她免100得了,人家既然已经说出来了,但想想又不对,这个口子一开,别人再这么提怎么办。再者对其他人也不公平啊,最终按住了心里的冲动,真难受!
[202+100]-------底部有张生活照片(头条号运营:大家想全托管上号的联系我哦,每天让你得个早餐钱,微信号: qhz_toutiao)
【关键词】python、ragflow、提交报错、图片链接获取
一、提交按钮问题(三级)
描述:现在提交问题时,报错,还应该是消息问题,处理一下。
开工:
第一步:复现错误(四级)
20250508周四时间段:15:23-16:00
复现下错误,就是消息没写进去,修改代码如下:
图5a-1
注:再次运行,发现问题得到解决。
第二步:测试
测试还可以,接下来,看下专家诊断是怎么获取图片链接的。
二、专家诊断获取图片链接(三级)
描述:专家诊断能分析图片,只是不精准,看下专家诊断是怎么获取图片链接的。
开工:
第一步:先复现(四级)
20250508周四时间段:16:25-18:00
先看下专家诊断,能不能识别图片,做个实验。
测试用例如下:
def test_expert_diagnosis(client):
log.info("test_expert_diagnosis")
'''
测试专家诊断--主要为了测试es的速度
再加一个联网搜索参数:enable_search False不进行联网搜索 True进行联网搜索
测试下传图片是怎么获取图片链接的
'''
json_data = {
"conversation_id": 'fff19f22fc0111efa7f900e003c42347',
"question": '根据图片分析,我家狗得了什么病吗?',
"enable_search":True,
"doc_ids":["e2c2a2362be611f09758a389844fd9da"]
}
url = f"/v1/conversation/expert_diagnosis"
resp = client.post(
url,
json=json_data,
headers={
"Content-type": "application/json",
"Authorization": "Bearer ragflow-UxOGYzZjUwYjMwOTExZWZiODc0MDI0Mm"
}
)
if not 200 <= resp.status_code < 300:
raise Exception(f"GET {url} status_code {resp.status_code}.")
# received_data = []
for chunk in resp.iter_encoded():
answer = chunk.decode('utf-8').strip()
log.info(f"\n\n answer: {answer} \n\n")
注:跑一下试试。
第二步:跑测试用例(四级)
20250508周四时间段:17:12-18:00
把数据库中历史记录清一下,修改如下:
图5b-1
注:这个请求之后,获取的结果如下:
answer: data:{"retcode": 0, "retmsg": "", "data": {"answer": "\n\n我认为:根据当前知识库内容,无法直接通过图片分析确定狗狗的具体疾病。建议您提供更详细的症状描述(如皮肤病变形态、瘙痒程度、是否伴随脱毛等)或前往专业宠物医院进行皮肤刮片检查和实验室检测以明确诊断。", "reference": {}, "audio_binary": null}} 注:从这个结果来看,是没用到图片链接的,接下来,逐行分析下关键的python方法chat_no_increase
第三步:分析方法chat_no_increase(四级)
20250508周四时间段:18:54-20:00
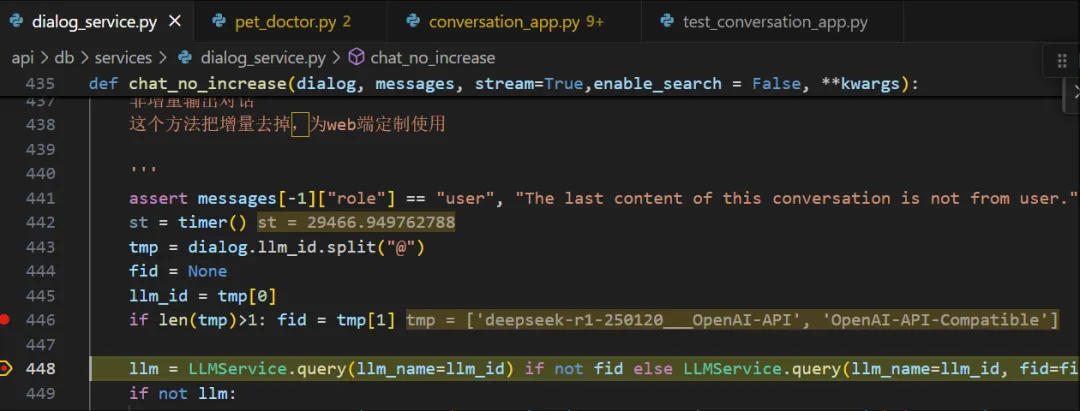
def chat_no_increase(dialog, messages, stream=True, enable_search=False, **kwargs):
'''
非增量输出对话
这个方法把增量去掉,为web端定制使用
'''
方法定义,用于非增量输出对话,专为web端定制
参数:
assert messages[-1]["role"] == "user", "The last content of this conversation is not from user."
注:断言检查最后一条消息必须来自用户
a.分析一
st = timer()
注:开始计时,用于性能统计。
tmp = dialog.llm_id.split("@")
fid = None
llm_id = tmp[0]
if len(tmp)>1: fid = tmp[1]注:
获取到的fid,截图如下:
图5b-2
llm = LLMService.query(llm_name=llm_id) if not fid else LLMService.query(llm_name=llm_id, fid=fid)
注:查询LLM服务,根据是否有fid决定查询方式。
if not llm:
llm = TenantLLMService.query(tenant_id=dialog.tenant_id, llm_name=llm_id) if not fid else \
TenantLLMService.query(tenant_id=dialog.tenant_id, llm_name=llm_id, llm_factory=fid)
if not llm:
raise LookupError("LLM(%s) not found" % dialog.llm_id)
max_tokens = 16384
else:
max_tokens = llm[0].max_tokens
注:
b.分析二(五级)
kbs = KnowledgebaseService.get_by_ids(dialog.kb_ids)
embd_nms = list(set([kb.embd_id for kb in kbs]))
if len(embd_nms) != 1:
yield {"answer": "**ERROR**: Knowledge bases use different embedding models.", "reference": []}
注:
获取知识库并检查所有知识库是否使用相同的嵌入模型
如果不一致,返回错误信息
获取到的知识库如下:
图5b-3
注:这一段的意思是选一个向量模型,转向量用的,ollama.
is_kg = all([kb.parser_id == ParserType.KG or kb.parser_config.get('graphrag',{}).get('use_graphrag') for kb in kbs])
retr = settings.retrievaler if not is_kg else settings.kg_retrievaler注:
检查是否所有知识库都是知识图谱类型
根据结果选择普通检索器或知识图谱检索器
注:parser_config如下:
{
"auto_keywords": 0,
"auto_questions": 0,
"raptor": {
"use_raptor": false
},
"graphrag": {
"use_graphrag": true,
"entity_types": ["PET-SPECIES(宠物种类)", "BREED(品种)", "AGE(年龄)", "GENDER(性别)", "WEIGHT(体重)", "TEMPERATURE(体温)", "DISEASE(疾病)", "SYMPTOM(症状)", "MEDICATION(药物)", "TREATMENT-METHOD(治疗方法)", "DIAGNOSTIC-TEST(诊断测试)", "SIGN(体征)", "ORGAN-OR-SYSTEM(器官或系统)", "VACCINE(疫苗)", "ANIMAL-BEHAVIOR(动物行为)", "ALLERGEN(过敏源)", "PROGNOSIS(预后)", "ENVIRONMENTAL-FACTORS(环境因素)", "NUTRITION(营养)", "FOOD(食物)", "WATER-INTAKE(饮水情况)", "LIFESTYLE(生活习惯)", "ALLERGIC-REACTION(过敏反应)", "LIVING-ENVIRONMENT(居住环境)", "PARASITE(寄生虫)", "RESTRAINT-METHOD(保定法)", "EXAMINATION-METHOD(检查方法)", "EPIDEMIOLOGY(流行病学)", "LESION(病变)", "PREVENTION(预防方法)"],
"method": "general",
"resolution": true,
"community": true
},
"chunk_token_num": 1500,
"delimiter": "\n!?;。;!?",
"layout_recognize": "DeepDOC",
"html4excel": true
}注:kb.parser_config.get('graphrag',{}).get('use_graphrag')这个获取到的是true。
c.分析三(五级)
20250508周四时间段:22:52-00:00
questions = [m["content"] for m in messages if m["role"] == "user"][-30:]
注:提取最近30条用户消息内容
attachments = kwargs["doc_ids"].split(",") if "doc_ids" in kwargs else None
if "doc_ids" in messages[-1]:
attachments = messages[-1]["doc_ids"]
for m in messages[:-1]:
if "doc_ids" in m:
attachments.extend(m["doc_ids"])注:处理附件文档ID,从kwargs或消息中获取,这个是把所有聊天中的文档id对比出来。
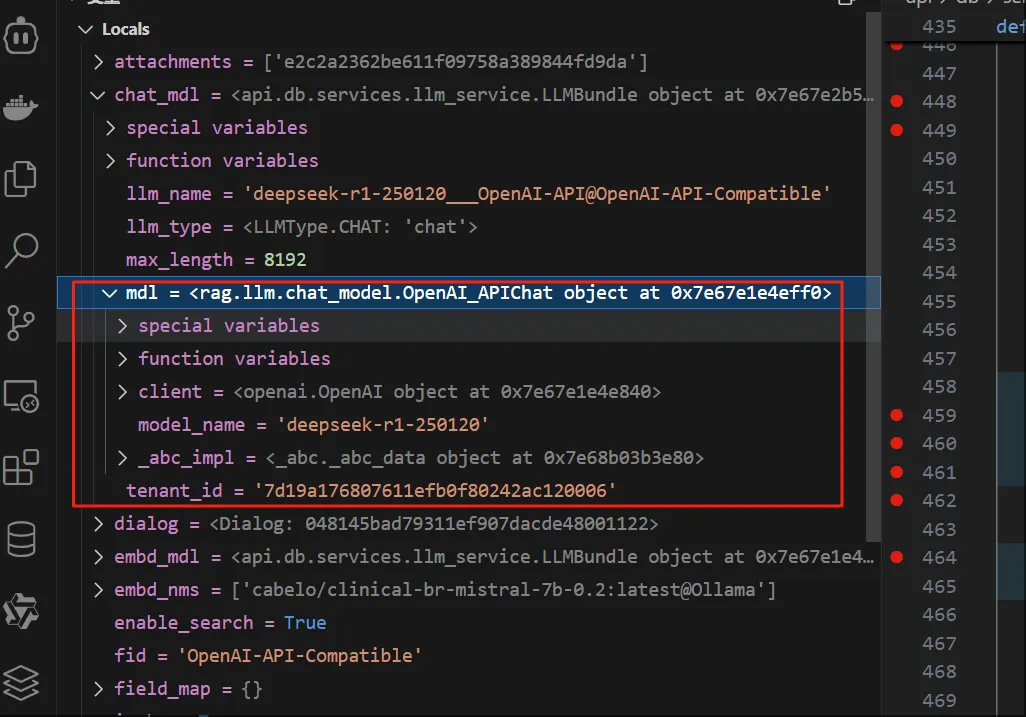
embd_mdl = LLMBundle(dialog.tenant_id, LLMType.EMBEDDING, embd_nms[0])
if llm_id2llm_type(dialog.llm_id) == "image2text":
chat_mdl = LLMBundle(dialog.tenant_id, LLMType.IMAGE2TEXT, dialog.llm_id)
else:
chat_mdl = LLMBundle(dialog.tenant_id, LLMType.CHAT, dialog.llm_id)
注:
这个打日志看一下,截图如下:
图5a-4
注:这个模型还是deepseek。
prompt_config = dialog.prompt_config
field_map = KnowledgebaseService.get_field_map(dialog.kb_ids)
tts_mdl = None
if prompt_config.get("tts"):
tts_mdl = LLMBundle(dialog.tenant_id, LLMType.TTS)
注:
if field_map:
ans = use_sql(questions[-1], field_map, dialog.tenant_id, chat_mdl, prompt_config.get("quote", True))
if ans:
yield ans
return
注:
如果有字段映射,尝试使用SQL查询
如果SQL查询成功返回结果,则直接返回
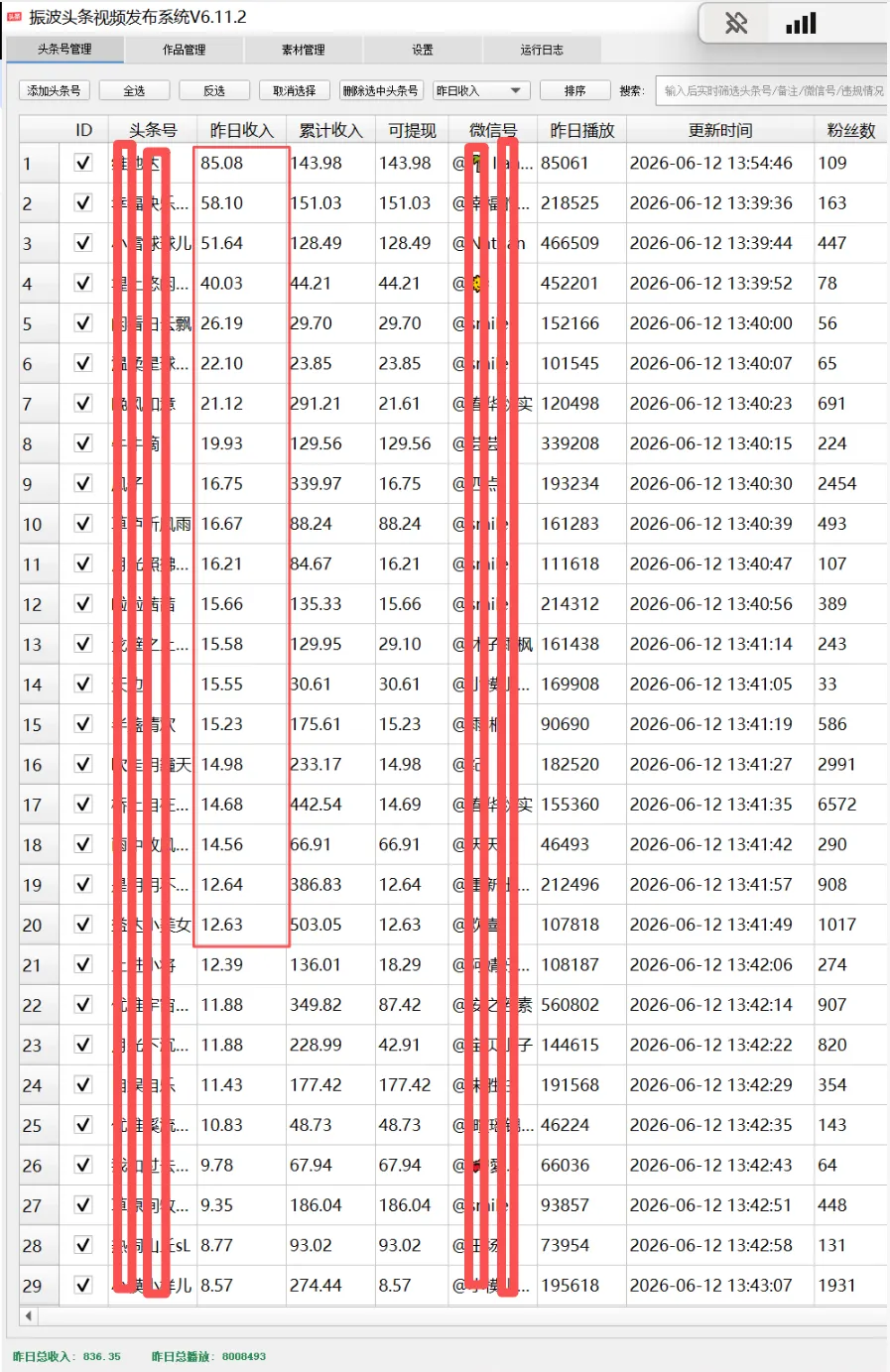
三、头条战果汇报
昨日数据来啦,昨日总收入:836.24,昨日总播放:800.8万,软件截图如下:
图5c-1
注:想要全脱管运营头条号的联系我,你出账号,我来运营,保你天天有钱花,咨询电话: 17701328814(微信同号),也可以加群先了解一下。
图5c-2
注:个人微信如下,欢迎骚扰。
图5c-3
四、生活照片
拍摄于2025年9月30日,20:38:46,带媳妇和二宝去中关村1号玩,当时,二宝三岁。后来,我想了想,那个女孩很傻,她提100免运营费没问题,但她不该威胁我,说不免就不挂了,一下子激起了我的反感,本来就是她的错,就像拿了一张过期的优惠券,让别人减免,说不同意就把店砸了,这谁受的了,如果她借助她的优势,卖了萌啥的,我可能就不管原则不原则,直接给她免了,她是用错了方式啊。要不然,怎么说,不同的人找同一个人办事,有的办成有的办不成呢。这让我想起:高中时,班里组织篮球赛,和别的班比,按照惯例,比赛结束班主任都会请上场的学生吃顿饭,为班争光了,但有个同学特意走到班主任面前,当着其他老师的面,说:老师,这次上场很辛苦,你要请吃饭哦。班主任说:那你别上场了。其他老师哈哈笑,当时我是观众,觉得这哥们脑子进水了吗,就像我去帮别人干一响午活,我说,我给你干活,你要请吃饭啊。这不多此一举吗,帮别人干活了,不给钱的情况下,别人肯定请吃顿饭或喝个饮料。所以,为人处事也是一门学问,慢慢学吧。
图5d-1
《本文完》