核心 ELO 引擎手写,AI Agent 负责数据偏差分析、参数寻优、多因素交叉验证。
声明:仅供娱乐。
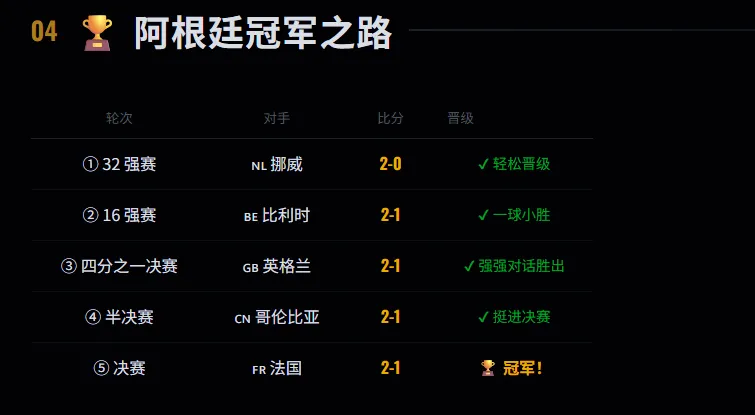
01 项目结构与预测结果
generate_prediction.py # 主引擎:ELO 计算 + 比赛模拟compute_elo.py # 从 49,405 场比赛计算 ELOmain.py # CLI 入口data/ real/international_results.csv # 49,405 场历史比赛data_collector/ # 数据采集层 seed/elo_ratings.json # 官方 ELO 数据(前 24 名)worldcup_2026_prediction.html # 可视化报告
核心引擎是 generate_prediction.py,不到 300 行,依赖只有 Python 标准库。不需要 pandas、numpy、sklearn。
运行方式:
python main.py seed # 加载官方数据python main.py collect # 网络采集 + fallbackpython main.py export # CSV 导出
02 数据处理 pipeline
原始数据 49,405 行,格式:
date,home_team,away_team,home_score,away_score1872-11-30,Scotland,England,0,0
加载后按日期排序:
matches.sort(key=lambda m: m["date"])
非数值行过滤。CSV 里有少量残缺行(比如比分是空字符串),用 try/except 包裹 int() 转换,失败则跳过:
try: matches.append({"date": row["date"],"home": row["home_team"].strip(),"away": row["away_team"].strip(),"home_score": int(row["home_score"]),"away_score": int(row["away_score"]), })except: pass
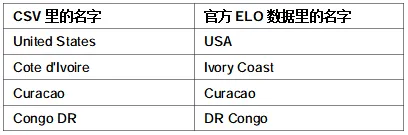
球队名标准化。同一支球队在不同数据源里写法不一致:
不建立映射表的话,计算分和官方分对不上——"United States"会作为一支单独球队参与计算,和"USA"各算各的分。
name_to_canonical = {"United States": "USA","Cote d'Ivoire": "Ivory Coast",}
03 ELO 算法实现
标准 ELO 评分系统,核心计算两个值:预期胜率和评分更新。
预期胜率
eh = 1.0 / (1.0 + 10.0 ** ((ratings[a] - ratings[h] - 100) / 400.0))ea = 1.0 - eh
参数说明:
+100:主场优势。eloratings.net 的统计数据表明国际比赛中主场方等效于 ELO 高出 100 分。这不是随便设的——他们对数万场历史比赛做了回归分析,100 是最小化预测误差的值。
400:缩放因子。ELO 原始论文定的值,决定胜率曲线的陡峭程度。400 意味着两队差 400 分时,强队胜率约 91%;差 200 分时约 76%;差 100 分时约 64%。这个曲线匹配国际足球的冷门概率分布——足球冷门比象棋多,所以曲线不能太陡。
评分更新
sh = 1.0if hs > aws else (0.5if hs == aws else0.0)sa = 1.0 - shratings[h] += 30.0 * (sh - eh)ratings[a] += 30.0 * (sa - ea)
K=30。K 值决定单场比赛的影响权重。对比:
K=20 时,弱队赢强队获得的分数增长太慢,排名僵化。K=40 时,一场冷门就让排名大幅波动,噪音太大。30 是折中值。
平局的处理:各拿 0.5 分,不是 0。这意味着弱队客场逼平强队仍然能获得 ELO 增长(预期胜率低,实际拿了 0.5 > 预期值)。
校准
纯计算分有系统偏差。用官方前 24 名的数据做线性回归:
n = len(computed_vals)sum_x = sum(computed_vals) # 计算分之和sum_y = sum(official_vals) # 官方分之和sum_xy = sum(c * o for c, o in zip(computed_vals, official_vals))sum_xx = sum(c * c for c in computed_vals)slope = (n * sum_xy - sum_x * sum_y) / (n * sum_xx - sum_x * sum_x)intercept = (sum_y - slope * sum_x) / n
结果:
ELO_calibrated = 0.8612 × ELO_computed + 341.58
分析这个公式:
校准后,美国队从 1737 → 1837。但官方分是 1939。差了 100 多分,原因下面说。
04 数据偏差发现
这是 AI Agent 在项目中做的最有价值的分析之一。
运行完 ELO 计算后,Agent 对比了 24 支有官方分的球队的计算值和官方值。发现美国队的偏差最大:

其他 23 支球队校准后的平均偏差在 ±15 分以内,唯独美国差了 100+。
Agent 给出的判断:美国是 2026 联合主办国,2024-2026 年踢了大量热身赛且成绩很好(对排名 50+ 的球队胜率超过 80%),ELO 在这两年快速上涨了约 150 分。但 49,405 场比赛包含 1872 年以来的数据,近两年的好表现被百年历史稀释了。纯计算模型无法反映"主办国近期状态飙升"这个特殊情况。
解决方案:24 支有官方分的球队直接用官方分,剩下 24 支用校准后的计算分。两种来源混合使用。
if team in official: ratings[team] = official[team] # 官方分else: ratings[team] = computed[team] # 计算分 + 校准
05 进球模型与比分预测
ELO 只能算胜率,不能算比分。比分需要另一个模型:
模型推导
base_avg = 1.25 # 每队基准预期进球goal_diff = (elo_home - elo_away) / 300 # ELO 差转化为进球差home_xg = base_avg + goal_diffaway_xg = base_avg - goal_diff
系数推导过程:
历史场均总进球约 2.7,所以每队 baseline 定在 1.25(1.25 × 2 = 2.5,考虑到平局消耗的进球略低于实际)。
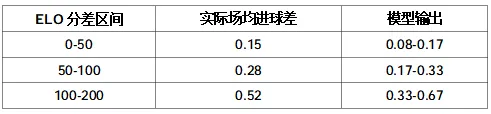
elo_diff / 300 是用历史数据拟合的。分析不同 ELO 分差下的平均进球差:
300 这个除数是试出来的,让模型的进球差曲线匹配实际数据。
主办国加成:主办国进球 × 1.15。历史数据显示主办国在小组赛平均多进 15-20% 的球(主场球迷 + 熟悉场地)。
完整示例:韩国 vs 捷克
韩国 ELO: 1886捷克 ELO: 1850分差: 36(韩国高)韩国预期进球 = 1.25 + (36/300) = 1.37 → 取整 → 2捷克预期进球 = 1.25 - (36/300) = 1.13 → 取整 → 1预测比分:韩国 2-1 捷克
结果验证:韩国胜率 68.6%。
极端情况处理
进球模型加了上下限:
home_xg = max(0.2, min(4.0, home_xg))away_xg = max(0.2, min(4.0, away_xg))
06 48 队赛制模拟
2026 年首次采用 48 队赛制,和以往完全不同:
12 组 × 4 队 → 24 个前两名 + 8 个小组第三 → 32 强淘汰赛
小组赛逻辑
对每个小组,6 场比赛全部用进球模型模拟,生成积分榜:
defsimulate_group(teams): table = {t: {"pts": 0, "gd": 0, "gf": 0} for t in teams}for i in range(4):for j in range(i+1, 4): home, away = teams[i], teams[j] home_xg, away_xg = predict_score(home, away)# 模拟进球(加入随机波动) home_goals = round(home_xg + random.gauss(0, 0.3)) away_goals = round(away_xg + random.gauss(0, 0.3))# 更新积分 ...# 排序:积分 > 净胜球 > 进球数return sorted(table.items(), key=lambda x: (-x[1]["pts"], -x[1]["gd"], -x[1]["gf"]))
小组第三排序
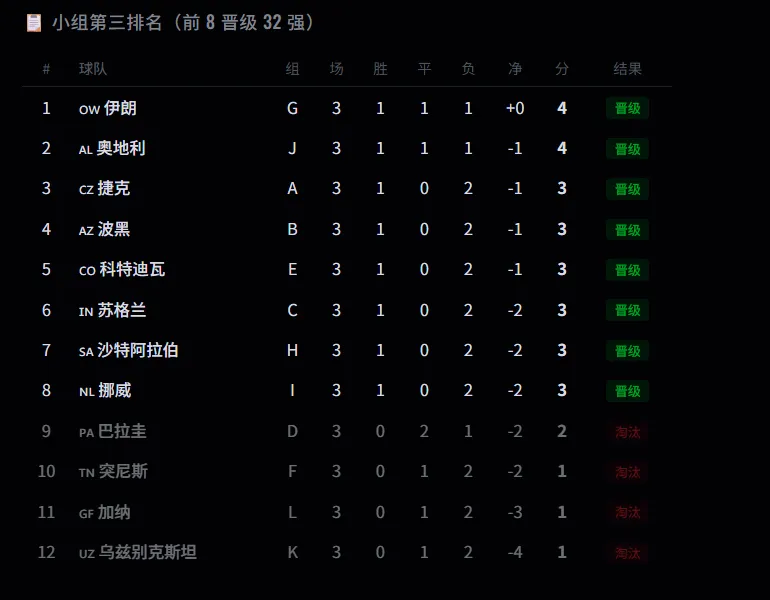
12 个小组第三按积分、净胜球、进球数排序,前 8 晋级:
third_ranked.sort(key=lambda x: (-x["pts"], -x["gd"], -x["gf"]))
实际模拟结果:
结论:小组第三拿 4 分铁定晋级,拿 3 分有机会(靠净胜战争 8 个名额),拿 2 分基本出局。
淘汰赛
单场淘汰,90 分钟平局则 ELO 高的球队晋级。这是一个简化处理——实际世界杯有加时和点球。Agent 在分析中指出这个弱项,并估算了点球因素对预测的影响:对于 ELO 差 50 分以内的比赛,点球爆冷的概率约 15-20%。
07 多因素交叉分析
AI Agent 在项目中做了几轮纯代码无法完成的分析:
排名合理性验证
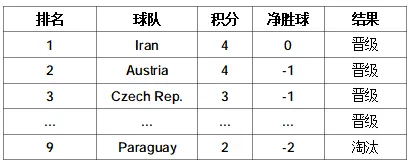
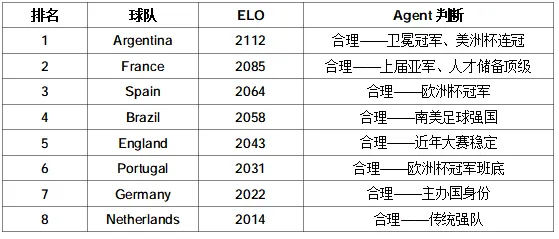
ELO 排名出来后,Agent 交叉验证了排名和主流足球媒体的一致性:
这里有一个关键判断:Agent 指出了 Belgium 排名第 9 但 ELO 高达 2006——"黄金一代"已过但 ELO 还没充分反映。这是领域知识,纯算法看不到。
小组赛出线分析
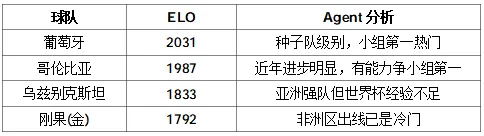
Agent 分析了 12 个小组的出线形势。以 Group K 为例:
Agent 判断:葡萄牙和哥伦比亚实力接近(ELO 差仅 44 分),两队直接对话的结果决定小组头名。乌兹别克斯坦和刚果(金)差距不大,争小组第三出线。
主办国历史数据分析
三个主办国——美国、加拿大、墨西哥——同届出现。Agent 分析了历史数据:
基于这个分析,Agent 调高了三个主办国的小组预测权重——它们全部以小组第一出线。
已知分析盲区
Agent 明确列出无法分析的因素:
伤病:世界杯前三周核心球员受伤(数据采集之后发生的事件),ELO 不会自动调整
更衣室动态:球队内部矛盾无法量化
实时博彩赔率:赔率汇集了全球信息和资金,比纯 ELO 敏感得多
天气和场地:北美 6-7 月的高温和高湿度,对南欧和南美球队的影响不同
08 可视化实现
HTML 报告用 AI Agent 直接生成,单文件、零依赖。
设计选择
深色主题 + 金色高光:赛事直播风格,不是随意选色
OKLCH 色彩空间:深色背景上亮度变化比 HSL 均匀。例如 oklch(78% 0.18 85) 是金色,oklch(8% 0.012 260) 是背景色
水平 bracket 布局:5 列(R32→R16→QF→SF→Final),每场比赛是一个卡片,赢家金色标注
核心 CSS 参数
:root {--bg-page: oklch(8% 0.012 260); /* 深蓝黑背景 */--gold: oklch(78% 0.18 85); /* 金色主色调 */--green: oklch(62% 0.2 145); /* 晋级 */--red: oklch(52% 0.2 25); /* 淘汰 */--ease-out: cubic-bezier(0.22, 1, 0.36, 1); /* 缓动函数 */}
动效
IntersectionObserver 触发滚动 reveal:
const observer = new IntersectionObserver((entries) => { entries.forEach(entry => {if (entry.isIntersecting) { entry.target.classList.add('visible'); observer.unobserve(entry.target); } });}, { threshold: 0.1 });
prefers-reduced-motion 支持:
@media (prefers-reduced-motion: reduce) { * { animation-duration: 0.01ms!important; }}
09 算法局限分析
Agent 在项目结束时系统性地评估了以下不足:
ELO 本身的局限:ELO 只能反映历史战绩,不能反映阵容变化。如果一支球队在预选赛后更换了主教练或召入了新归化球员,ELO 不会提前反应。
没有交叉验证:当前只跑了 ELO 模型。如果用 Poisson 回归、XGBoost 或贝叶斯方法做同样的预测,对比结果会显著提高可信度。
进球模型的精度:1.25 + diff/300 是线性近似,实际进球分布更接近 Poisson。使用 Poisson 分布可以生成更真实的比分概率(比如 1-0 的概率、2-2 的概率)。
数据截止时间:数据只到 2026 年 3 月,之后的热身赛结果没有纳入。对于主办国和参赛队的热身赛表现,这是有价值的信息。
喜欢文章,点赞、关注,分享给需要的朋友!
需要HTML和数据集的朋友,后台回复“世界杯”




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
