用历史数据跑回测,说白了就是验证策略在过去的行情里能不能赚钱、会不会爆仓。但很多人栽在同一个坑里:回测看着很美,一上实盘就变脸。下面把机器学习交易的全流程拆开揉碎,重点说说那些容易让人“虚假繁荣”的偏差。
机器学习驱动交易全流程框架
整个链条从数据开始——拿原始行情、基本面、另类数据,洗干净后挖因子、跑模型出信号,再定交易规则、算仓位,最后扔进回测看绩效,不行就回来调。这中间每个环节都藏着坑。
回测常见陷阱
数据里的猫腻
前瞻偏差:别用未来数据去回测过去。比如复权价、修正后的财报,回测时点根本拿不到。解决方法:给每条数据打时间戳,只取当时真实可见的信息。延迟发布的数据,做最坏打算。
幸存者偏差:只测现在还活着的股票?那胜率肯定虚高。必须把退市、被收购的那些“死掉”的标的也加进去。MT5的历史数据尤其要当心这点。
过度清洗极端值:有人觉得暴涨暴跌是异常值,直接删掉。结果回测岁月静好,实盘碰上闪崩直接穿仓。金融数据天生厚尾,截尾处理要手下留情。
样本单一:只测牛市当然爽。覆盖熊市、震荡市,或者用合成数据补一些极端场景,才扛得住检验。
模拟执行的现实问题
风险指标别只看回测结束时的数字。用滚动窗口算VaR、索提诺比率,看看最坏情况能不能扛住。
佣金、滑点、冲击成本不模拟,回测收益率自动打对折都算乐观。实盘里大单进出能把价格推走,这个也得建模。
用收盘价生成信号,假设立刻成交?太天真。保险做法:信号出来后,用下一根K线的开盘或收盘价成交。
统计上的过度优化
同一个策略,换几个参数来回测几十遍,总能挑出一个好看的。但这一出样本外就露馅。解决办法:策略本身要有经济逻辑,不是纯数据挖出来的;样本外数据必须独立,碰都不能碰。
两种回测路径的选择
Python全自建
用MetaTrader5库拉数据,自己写回测引擎。好处是灵活,想集成scikit-learn、PyTorch随便搞。代价是订单执行、滑点这些细节都得手撸代码。
MQL5+Python混合
MQL5跑EA,Python只做模型导出和结果分析。MT5自带的回测引擎精度能到tick级,但两套代码来回维护很烦,模型导出格式有限(通常转ONNX)。
个人建议:快速验证因子用Python向量化回测,省时间;真要模拟复杂交易细节(比如盘口深度、订单簿),直接上MT5原生。
MT5 Python回测实操方案
用MAS库跑一把
这个库专门为MT5写回测的,从拿数据到出报告一条龙。下面是一段均线交叉的例子(代码略)。支持外汇、黄金、股指、加密货币,跑完直接给你夏普比率、最大回撤、盈亏因子、胜率。
import mas
classMASStrategy(mas):
defreceive_bars(self, symbol, data, is_end):
# 策略逻辑示例:均线交叉
ifself.index % self.ma == 0:
ifnotself.hold:
self.order_id = self.send_order({
"symbol": "EURUSD",
"order_type": "buy",
"volume": 0.1,
"backtest_toggle": self.toggle
})
self.hold = True
else:
self.send_order({
"symbol": "EURUSD",
"order_type": "sell",
"order_id": self.order_id,
"volume": 0.1,
})
self.hold = False
self.index += 1
if is_end:
self.generate_kpi_report() # 输出夏普比率、最大回撤等
self.generate_trade_chart() # 动态可视化
# 运行回测
params = {
"symbol": "EURUSD",
"from": '2020-01-01',
"to": '2024-12-31',
"timeframe": "D1"
}
df = mas_c.subscribe_bars(params)
支持品种:Forex、黄金、股指、加密货币,可生成KPI报告(盈亏因子、胜率、最大回撤等)
ONNX模型灌进MQL5
Python训练好的模型(比如随机森林)转成ONNX格式,MQL5里直接调用。注意:标准化参数(StandardScaler)要一起打包进ONNX图里,这样MQL5端传原始特征值就行。
# Python端:训练并导出模型
from skl2onnx import convert_sklearn
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
# 训练模型(StandardScaler内置于ONNX图)
model = Pipeline([('scaler', StandardScaler()),
('clf', RandomForestClassifier())])
model.fit(X_train, y_train)
# 导出ONNX
onx = convert_sklearn(model, initial_types=[('input', FloatTensorType([None, n_features]))])
withopen("model.onnx", "wb") as f:
f.write(onx.SerializeToString())
MQL5端:EA初始化时加载ONNX模型,每次tick调用OnnxRun()进行推理
注意事项:StandardScaler参数已内置到ONNX图中,MQL5传入原始特征值即可
CPCV交叉验证
这个玩法稍微进阶一点:用组合交叉验证测策略到底有没有统计意义。Python端把时间轴切成N段(比如6折,留2段做测试),每段生成一个掩码文件。MT5的优化器并行跑这些路径,最后汇总看各条路径的夏普分布和PBO。如果中位夏普还行、PBO不高(策略选优不是瞎蒙),心里就有底了。
ML模型和回测怎么搭
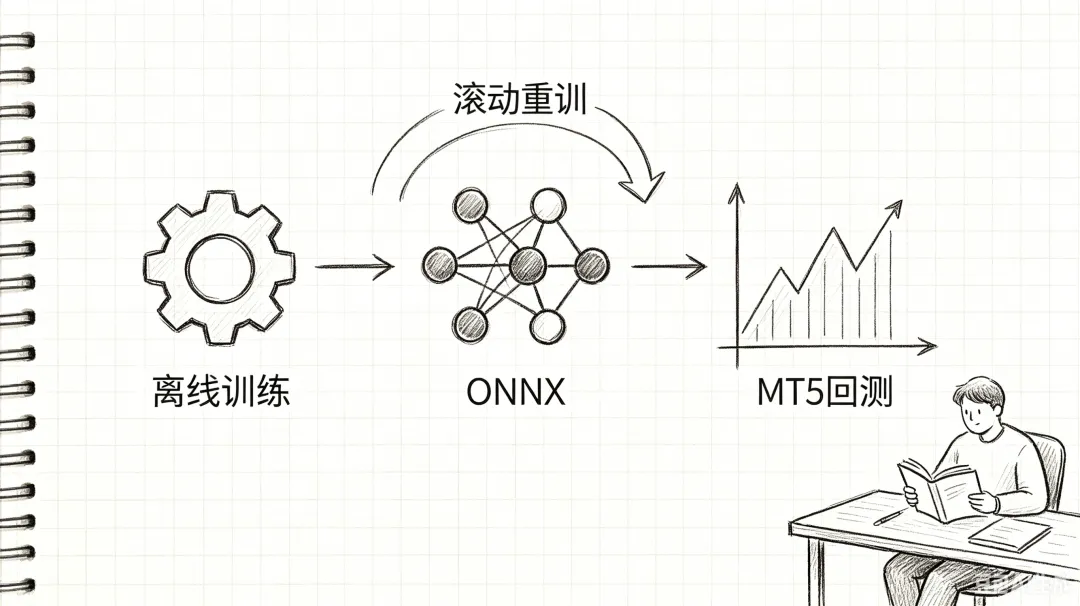
离线训练+在线调用
回测外面把模型训好(Lasso、XGBoost随便),存权重。回测时加载模型,根据因子出信号。适合日线级别、模型不用天天换的策略。
回测内滚动训练
回测过程中每隔一段时间重新训一次模型。比如用SGD预测价格,再用DNN去补SGD的残差,两个模型叠着用。代价是耗时间,而且必须用样本外数据验证每次重训是不是真的有效。
特征重要性别忘看
互信息法能筛出哪些特征有预测能力;递归特征消除可以验证特征集合稳不稳。
绩效评估别只看夏普
基础指标:累计收益、年化收益、波动率、最大回撤、VaR、夏普、索提诺。
进阶想法:
蒙特卡洛模拟:把交易顺序随机打乱几千次,看最大回撤的分布长什么样。
凯利公式:f = (pu - l) / (ul)。p是胜率,u是平均盈利比例,l是平均亏损比例。实盘建议用分数凯利(除以2~4),别算满仓。
MMT5缺的工具,Python补上
MT5原生回测没有蒙特卡洛、前进优化这些统计功能。可以接Python生态:
pyfolio:风险分析、收益拆解
empyrical:各种绩效指标一把算
QuantStats:一键生成漂亮报告

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
