工业设备数据采集,真的是个让人头秃的领域。
🔥 从一次凌晨故障说起
凌晨两点,我接到运维的电话——产线上的温度监控系统又崩了。
原因?老样子。串口数据进来,直接写数据库,同时还要推告警、刷 UI 界面。三件事挤在一个线程里,数据库一抖,整条链路全卡死。这种代码,我管它叫「意大利面条式架构」——每根面条都缠着另一根,你动一下,全乱。
那次之后我下定决心,彻底重构这套东西。
最终落地的方案,就是今天要聊的:RabbitMQ Fanout Exchange + 多消费者。一条消息进来,广播给所有人,谁消费谁的事,互不干扰。
😩 单队列模式的三个死穴
在讲方案之前,先说说「之前的代码」到底烂在哪儿。
很多同学做串口数据采集,第一反应是这样的:
1串口读数据 → 塞进一个队列 → 一个消费者全包了
看起来没问题,对吧?但实际跑起来,你会发现——
第一个死穴:强耦合。 UI 渲染慢了,数据库写入也跟着等。告警推送网络抖了,整个消费者堵死。一个环节出问题,全线瘫痪。
第二个死穴:扩展性为零。 哪天产品说「再加个日志归档功能」,你得去改消费者代码。改一行,可能引入三个 bug。
第三个死穴:prefetch 没法调优。 数据库写入适合批量(prefetch=10),告警推送必须即时(prefetch=1)。单队列模式里,这两个需求根本没法同时满足。
🏗️ Fanout Exchange:邮局的广播室
理解 Fanout Exchange,有个特别贴切的比喻。
想象一个邮局的广播室。广播员(Publisher)说一句话,广播室(Exchange)把这句话同时播给所有的收音机(Queue)。每台收音机背后,坐着不同的听众(Consumer)——有人负责记笔记(数据库),有人负责报警(告警系统),有人负责显示在屏幕上(UI)。
广播员根本不关心有几台收音机,也不知道听众在干嘛。他只管播。
这就是 Fanout 的核心:发布者和消费者完全解耦。
1 ┌─────────────────┐2 │ Fanout Exchange │3 │ serial_exchange │4 └────────┬────────┘5 │ 广播6 ┌──────────────┼──────────────┐7 ▼ ▼ ▼8 [queue_ui] [queue_db] [queue_alert]9 │ │ │10 UI消费者 DB消费者 告警消费者11(prefetch=1) (prefetch=10) (prefetch=1)
注意看,三个队列的 prefetch 是不一样的——这是单队列模式永远做不到的事。
💻 核心代码拆解
第一步:声明 Exchange 和绑定队列
python1def setup_exchange_and_queues():2 connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))3 channel = connection.channel()45# fanout 类型,durable=True 保证 RabbitMQ 重启后 Exchange 还在6 channel.exchange_declare(7 exchange="serial_exchange",8 exchange_type="fanout",9 durable=True10 )1112# 三个业务队列,各司其职13 queues = ["queue_ui", "queue_db", "queue_alert"]14for q in queues:15 channel.queue_declare(queue=q, durable=True)16# fanout 模式下,binding 不需要 routing_key17 channel.queue_bind(exchange="serial_exchange", queue=q)1819 connection.close()
这里有个细节很多人忽略:durable=True 要同时加在 Exchange 和 Queue 上。只加一个,RabbitMQ 重启后照样丢数据——我见过不止一个同学在这里踩坑。
第二步:发布消息
python1def publish_to_exchange(data: str):2 connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))3 channel = connection.channel()45 message = json.dumps({6"timestamp": datetime.now().isoformat(),7"raw": data.strip()8 })910 channel.basic_publish(11 exchange="serial_exchange",12 routing_key="", # fanout 模式,路由键留空即可13 body=message,14 properties=pika.BasicProperties(delivery_mode=2) # 消息持久化15 )16 connection.close()
delivery_mode=2 是消息持久化的开关。不加这个,RabbitMQ 宕机后消息全没了。生产环境里,这行代码是命根子。
第三步:消费者示例(以数据库写入为例)
python1def start_db_consumer():2 connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))3 channel = connection.channel()45# 数据库写入适合批量处理,prefetch 调大一些6 channel.basic_qos(prefetch_count=10)78def on_message(ch, method, properties, body):9 data = json.loads(body)10# 替换为你的实际写入逻辑11print(f"[DB] 写入: {data['raw']}")12 ch.basic_ack(delivery_tag=method.delivery_tag)1314 channel.basic_consume(queue="queue_db", on_message_callback=on_message)15 channel.start_consuming()
UI 消费者和告警消费者的结构完全一样,只是队列名和 prefetch 不同。三个消费者跑在独立的线程或进程里,谁挂了不影响其他人。
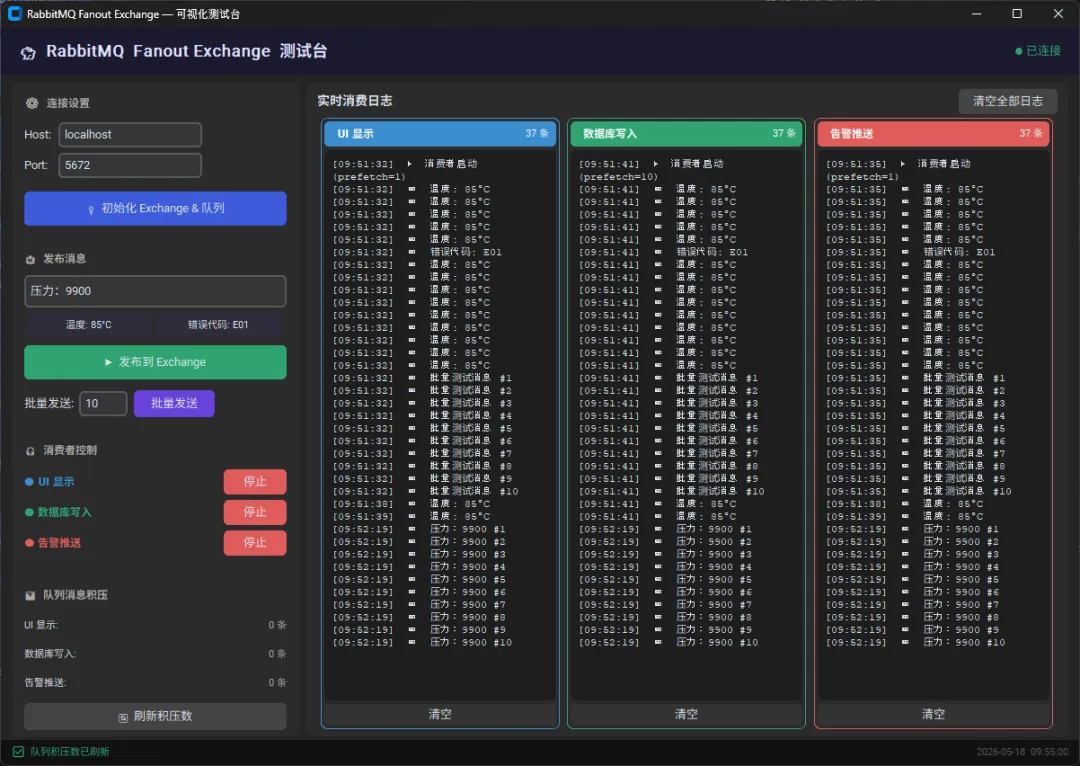
🎛️ 可视化测试台:把架构跑起来看看
光看代码有时候不够直观。我基于这套架构,用 customTkinter 写了一个完整的 GUI 测试台,长这样:
- ▸ 左侧是控制面板:初始化 Exchange、发布消息、启停消费者、查看队列积压数
- ▸ 右侧是三列实时日志:UI消费者、DB消费者、告警消费者各自独立显示
几个关键的工程细节值得单独说一下:
线程隔离。 所有 RabbitMQ 操作都在 daemon 线程里跑,主线程只管 UI 渲染。子线程通过 queue.Queue 往主线程扔日志,主线程用 after(100, ...) 每 100ms 轮询一次。这是 Tkinter 系列处理线程安全的标准姿势,绕不开的。
消费者优雅停止。 每个消费者线程绑定一个 threading.Event。调用 stop_event.set() 后,消费者在下一次 process_data_events(time_limit=0.5) 超时后自然退出,而不是强制 kill。这样正在处理的消息能正常 ACK,不会造成消息重复消费。
RabbitMQBroker 与 UI 完全解耦。 所有 MQ 逻辑封装在一个独立类里,不依赖任何 Tkinter 对象。换掉 UI 框架,或者写单元测试,都不需要动 MQ 层的代码。
📊 这套架构能扛多少?
在我的测试环境(本地 Docker 跑 RabbitMQ,Python 3.11)下,简单压测了一下:
| | |
|---|
| | |
| | |
| Fanout + DB消费者 prefetch=10 | | |
Fanout 本身的广播开销很小,三个队列的总吞吐基本等于单队列的吞吐。性能损耗几乎可以忽略,换来的是架构上的巨大灵活性,这笔账怎么算都划算。
⚠️ 三个必须知道的坑
坑一:Exchange 和 Queue 的 durable 属性要一致。如果你第一次声明时用了 durable=True,后来代码改成 durable=False 再连接,RabbitMQ 会直接报错。这个属性一旦定了就不能改,只能删掉重建。
坑二:fanout 模式下,消费者必须先绑定队列再发消息。如果你先发消息、后绑队列,那条消息就丢了——Exchange 不会帮你存着等消费者上线。生产环境里,初始化顺序很重要。
坑三:不要在回调函数里做耗时操作。on_message 回调里如果有网络请求或者慢 SQL,整个消费者会被卡住。正确的做法是:回调里只做 ACK 和入内存队列,真正的业务逻辑放到另一个线程里处理。
🚀 扩展方向:这套架构还能怎么玩?
方向一:换成 Topic Exchange。 如果设备类型多,可以用 topic 模式,通过路由键(比如 device.temperature.warn)实现更精细的消息分发。不同设备的数据,路由到不同的队列。
方向二:接入死信队列(DLX)。 消费失败的消息自动进死信队列,方便排查问题,也能实现延迟重试。
方向三:上 Prometheus 监控。 RabbitMQ 自带 Management Plugin,可以直接对接 Prometheus + Grafana,把队列积压数、消费速率这些指标可视化出来。
💬 最后说一句
这套架构真正的价值,不在于它有多复杂,而在于它把「变化」隔离开了。
新来的业务需求?加一个队列、绑一下 Exchange、写一个消费者,完事。已有的代码一行都不用动。这才是架构设计应该追求的东西——不是让系统变得更复杂,而是让未来的修改变得更简单。
下次凌晨两点,我希望不是我接那个电话。
#Python#RabbitMQ#消息队列#系统架构#后端开发
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
