一起读经典 · Linux 内核网络(3):门牌之下——net_device 与设备子系统
- 2026-06-29 23:37:49
一起读经典 · Linux 内核网络(3):门牌之下——net_device 与设备子系统
本文是「一起读经典 · Linux 内核网络」系列第 3 篇。承接上一篇的"水"(sk_buff),本篇讲"管道"(net_device):内核如何把物理网卡、回环、桥、隧道、veth 一视同仁;
netdev_ops虚函数表如何在 C 语言里模拟 OOP;通知链如何把"网卡上下线"广播给协议栈每个角落;以及 6.x 内核对引用计数与命名空间所做的几次关键改造。版本契约:本文以 Linux 6.6 LTS / 6.12 Stable 为基准。凡涉及"经典视角"(Benvenuti 一书、2.6 内核)与"现代实现"有出入处,文中显式标注,文末给出版本契约对照表。
一、一个真实问题:ip link set eth0 up 之后到底发生了什么?
你敲一行命令:
sudo ip link set eth0 up
回车后,屏幕上没有输出。但内核里发生了几十件事:
驱动的 ndo_open被调用,分配 RX/TX ring、申请中断、启动 NAPI。__LINK_STATE_START位被置上,IFF_UP标志拉高,qdisc 被激活(dev_activate)。通知链广播 NETDEV_UP事件:IPv4 子系统启用这个接口的 IP 配置;IPv6 子系统开始生成 link-local 地址,发 RS 等待 RA。如果 eth0 之前被加进了某个 bridge,bridge 推进它的端口状态机。 rtnetlink 把 RTM_NEWLINK消息多播给用户态——另一个终端里开着的ip monitor link会立刻打出一行。linkwatch 开始盯 PHY 的 carrier;等链路真的起来,再广播一次 NETDEV_CHANGE。
这一切的指挥中心,就是 struct net_device。如果你把内核网络栈想象成一座大楼,net_device 就是大楼里每个"网络接口"的统一门牌。你递快递(sk_buff)给某个部门时,只认门牌——不管门后是物理网卡、虚拟网卡、桥、还是回环。
本篇剖析这块门牌的内部结构。
二、本篇坐标:你在哪张地图上
net_device 同时横跨三张地图:
数据面: ndo_start_xmit(发送入口)、NAPI poll(接收驱动)、netdev_ops全套虚函数。控制面: register_netdev/unregister_netdev生命周期、通知链广播、ip link的 Netlink 消息落点。性能面:per-CPU 引用计数( pcpu_refcnt)、多队列(real_num_rx_queues/real_num_tx_queues)、napi_list上挂的多个 NAPI 实例、qdisc 与 TX ring 的边界。
第 02 篇说 sk_buff 是"三张地图的交汇点";net_device 则是三张地图共用的"地基"——水要流,先得有管道。
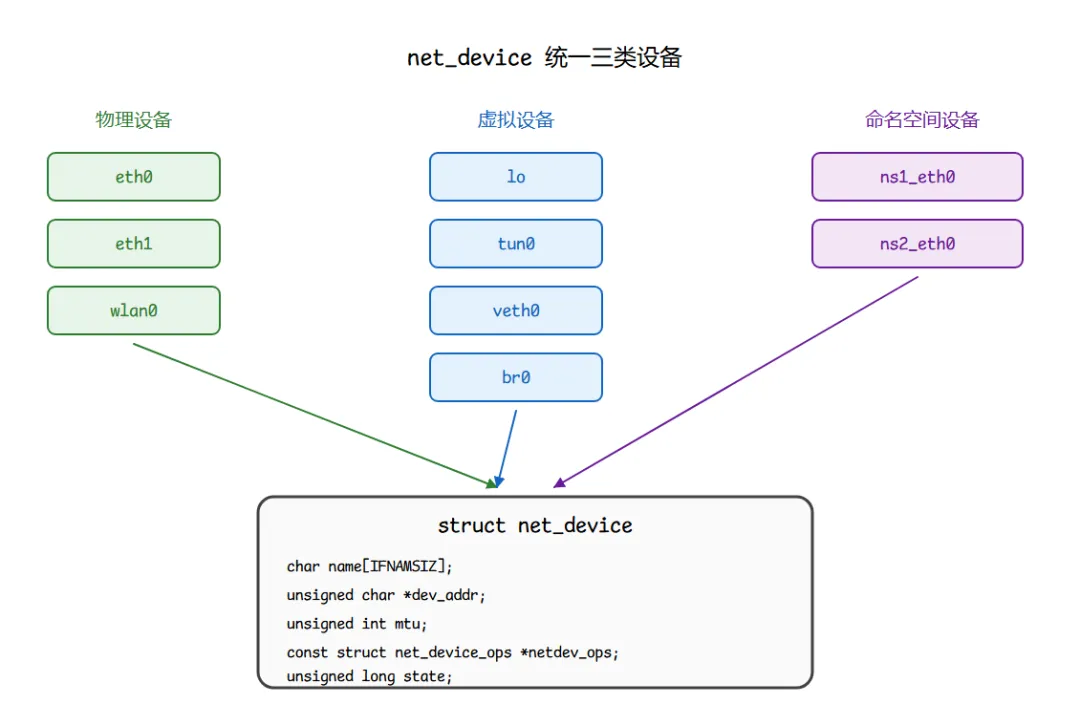
三、统一抽象:eth0、lo、br0、veth0、tun0 都是同一个东西
打开你的机器:
$ ip link show | awk -F': ' '/^[0-9]+/ {print $2}'
lo
eth0
docker0
veth1a2b@if5
br-cni
tun0
wlan0
每一行都是一个 net_device。内核眼里它们是平等的——发包时调用同一套接口、注销时走同一套路径、状态变化时进同一个通知链。
这是一个反直觉的设计:物理网卡是真实硬件,有 PCIe、MSI-X、DMA、PHY chip;回环 lo 是一段纯软件;桥 br0 是一组端口的逻辑聚合;veth 是一对软件管道;tun/tap 是连到用户态进程的管道。它们的"物理形态"差异巨大,但都实现同一个虚函数表:
struct net_device_ops {
int (*ndo_init)(struct net_device *dev);
void (*ndo_uninit)(struct net_device *dev);
int (*ndo_open)(struct net_device *dev);
int (*ndo_stop)(struct net_device *dev);
netdev_tx_t (*ndo_start_xmit)(struct sk_buff *skb, struct net_device *dev);
/* ... 几十个其他回调,大部分都有合理默认 ... */
};
协议栈把 skb 交给 dev_queue_xmit(skb)(出口设备就是 skb->dev)时,根本不知道这个 dev 是真硬件还是软件桥——它最终只看 dev->netdev_ops->ndo_start_xmit 这个函数指针。
类比:公司内部邮件系统。你发邮件,只看收件人和部门门牌;邮件中心不关心市场部办公室在哪一层、用什么打印机。Linux 协议栈对待 net_device,跟邮件中心对待门牌一样:只认接口,不认实体。
这就是为什么:
lo上 ping 通 = 协议栈本身没问题docker0是个桥,你能给它配 IP、抓包、加 iptables 规则,跟物理网卡一样vethpair 一端在容器里、一端在宿主机,容器进程发包跟用物理网卡发包没两样
四、核心字段:第一次只看 8 个
struct net_device 在 6.6 内核上有 200+ 字段(include/linux/netdevice.h),全看会被淹死。第一次只认这 8 个:
name[IFNAMSIZ] | "eth0" | ip link show |
dev_addr | ip link showlink/ether | |
mtu | ip link showmtu | |
state | __LINK_STATE_START、__LINK_STATE_NOCARRIER...) | ip link showstate |
netdev_ops | ndo_start_xmit | |
qdisc | tc 看的根队列规则(入队实际走 per-queue qdisc,见第六节) | tc qdisc show dev eth0 |
napi_list | ||
nd_net | possible_net_t,受 CONFIG_NET_NS 控制) | ip netns exec ns1 ip link |
错误纠正:老资料(2.6.24 之前)里,poll 函数和轮询配额是直接长在
net_device上的(dev->poll、dev->quota、dev->poll_list)——那个年代"设备本身就是 NAPI 实体"。这个模型早已不成立:现代多队列网卡每个 RX/TX queue pair 有自己的 NAPI 实例,通常嵌入在驱动的私有结构(如igb_q_vector或mlx5e_channel)里,通过netif_napi_add()注册到dev->napi_list链表。net_device自己不持有任何napi_struct,只持有一个链表头。
4.1 name 的小陷阱
name 不是单纯字符串,内核按 netns 维护命名表。name 重复(在同一 netns 内)会导致 register_netdev 失败。ip link set eth0 name net0 通过 Netlink RTM_SETLINK 改 name 字段并触发 NETDEV_CHANGENAME 通知。顺带一个版本细节:老内核要求接口先 down 才能改名,6.2 起允许在 up 状态下直接改。
4.2 state 是位图,而 ip link 的输出是"两套状态"
enum {
__LINK_STATE_START, /* 管理 up(ip link set up) */
__LINK_STATE_PRESENT,
__LINK_STATE_NOCARRIER, /* 物理 down(网线没插) */
__LINK_STATE_LINKWATCH_PENDING,
__LINK_STATE_DORMANT,
__LINK_STATE_TESTING,
};
ip link show 一行输出里其实有两套状态,初学者最容易混:
尖括号里的 flags: <NO-CARRIER,BROADCAST,MULTICAST,UP>。其中UP对应管理 up(IFF_UP/__LINK_STATE_START),NO-CARRIER对应__LINK_STATE_NOCARRIER(物理层没起)。state XXX:这是 RFC 2863 定义的 operstate("业务可用性"),由内核 linkwatch 根据 carrier / dormant 推算出来。管理 up + 有 carrier →state UP;管理 up + 无 carrier → 物理设备显示state DOWN(同时 flags 里出现NO-CARRIER);只有堆叠设备(VLAN、某些 bond/上层设备,特征是iflink != ifindex)在下层挂掉时才显示LOWERLAYERDOWN。
这就是为什么 ip link set eth0 up 之后你可能看到 <NO-CARRIER,BROADCAST,MULTICAST,UP> state DOWN——UP 和 DOWN 同时出现在一行里不是 bug,是两套状态各说各话:管理位已经拉高,物理 carrier 还没起。
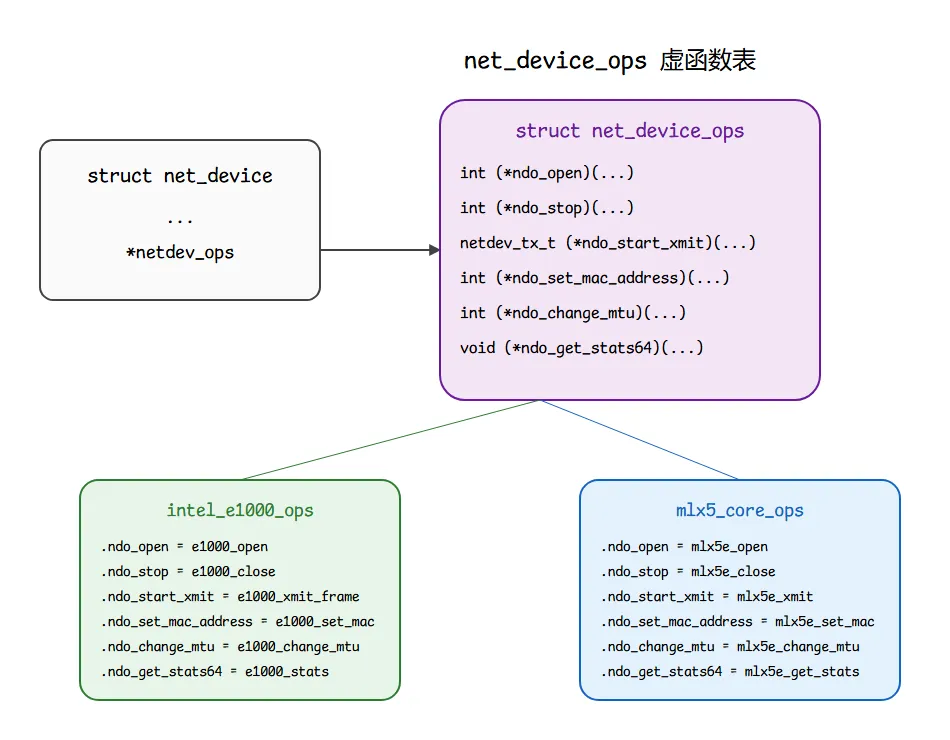
五、netdev_ops:C 语言怎么模拟 OOP
net_device_ops 是一张函数指针表。每个驱动初始化时,填一份自己的实现:
/* drivers/net/ethernet/intel/igb/igb_main.c 的概念化裁剪 */
static const struct net_device_ops igb_netdev_ops = {
.ndo_open = igb_open,
.ndo_stop = igb_close,
.ndo_start_xmit = igb_xmit_frame,
.ndo_set_rx_mode = igb_set_rx_mode,
.ndo_set_mac_address = igb_set_mac,
.ndo_change_mtu = igb_change_mtu,
.ndo_tx_timeout = igb_tx_timeout,
.ndo_validate_addr = eth_validate_addr,
.ndo_get_stats64 = igb_get_stats64,
/* ... */
};
然后:
netdev->netdev_ops = &igb_netdev_ops;
协议栈调用 dev->netdev_ops->ndo_start_xmit(skb, dev) 时,实际进入 igb_xmit_frame。换一张 Mellanox 卡,这条指针指向 mlx5e_xmit。同一段 dev_queue_xmit 代码,跑遍所有网卡——这就是 C 模拟 OOP。
5.1 ndo_start_xmit 的反直觉点
驱动 ndo_start_xmit返回 NETDEV_TX_OK 不等于"包已发到网线"。它只表示"驱动接收了 sk_buff,放进了 TX descriptor ring"。真正的发送完成,通过两条路径之一汇报:
TX 完成中断(老式) NAPI poll 中的 TX 清理逻辑(现代)
这里要破一个老说法:老资料里讲驱动有个标准回调叫 tx_clean,内核 NAPI 框架会调它。没有这个标准回调。驱动通常在自己的 NAPI poll 函数里先清理 TX 完成描述符,再 RX poll——这是驱动内部的逻辑组织,不是 net_device_ops 的标准接口。
清理 TX 完成的概念化代码:
static int igb_poll(struct napi_struct *napi, int budget)
{
struct igb_q_vector *q_vector = container_of(napi, ...);
bool clean_complete = true;
int work_done = 0;
/* 先清 TX 完成描述符 */
if (q_vector->tx.ring)
clean_complete = igb_clean_tx_irq(q_vector, budget);
/* 再做 RX 收包 */
if (q_vector->rx.ring) {
work_done = igb_clean_rx_irq(q_vector, budget);
if (work_done >= budget)
clean_complete = false;
}
if (!clean_complete)
return budget; /* 活没干完,留在 poll 列表里 */
if (likely(napi_complete_done(napi, work_done)))
igb_ring_irq_enable(q_vector); /* 干完了,重新开中断 */
return work_done;
}
清理 TX 时,驱动对每个已完成的描述符调用 napi_consume_skb()(NAPI 上下文的批量释放版本)释放 sk_buff——到这一步,02 篇讲的 users / dataref 两层引用计数才真正开始递减(TCP 重传队列里的 clone 还握着数据区,所以释放的可能只是"驱动这一份")。"sk_buff 什么时候真的可以释放",最终答案不在协议栈,而在驱动的 TX 清理里。
六、qdisc:发送侧的"队列入口"
协议栈发包路径里:
dev_queue_xmit(skb) // 出口设备 = skb->dev
→ __dev_queue_xmit
→ txq = netdev_core_pick_tx(dev, skb, ...) // 先选 TX 队列(XPS/hash,08 篇)
→ q = rcu_dereference_bh(txq->qdisc) // 取这个队列的 qdisc
→ __dev_xmit_skb:q->enqueue() 入队
__qdisc_run() 出队 → ndo_start_xmit
注意一个容易翻车的细节:真正入队、出队的是每个 TX 队列自己的 txq->qdisc,不是 dev->qdisc。dev->qdisc 字段存的是给 tc 展示的 root(多队列设备上就是 mq),而 mq 本身不排一个包——它只是把每个硬件队列下面的子 qdisc 组织起来。
6.1 默认 qdisc 的现代真相
很多老教材会写"Linux 默认队列规则是 pfifo_fast"。这在 4.12 之后已不准确,但要说准,得先回答 01 篇那个条件反射式的问题:是哪一种默认?
内核默认:4.12 起,Kconfig( CONFIG_DEFAULT_NET_SCH)的默认值从pfifo_fast换成fq_codel(理由:对抗 bufferbloat)。发行版默认:不少发行版在内核切换之前就已通过 systemd 的 sysctl 把 net.core.default_qdisc设成了fq_codel。设备类型:多队列设备( real_num_tx_queues > 1)的根 qdisc 是mq,mq底下每个硬件 TX 队列各挂一个fq_codel;而lo、veth、bridge 这些虚拟设备默认是noqueue——不排队,出队逻辑直接同步调用dev_hard_start_xmit。
所以你在容器里 tc qdisc show dev eth0 看到 fq_codel,tc qdisc show dev lo 看到 noqueue——不是配置错了,是设计如此。现代调度器(fq、fq_codel、cake)还与 BQL(Byte Queue Limits)、TSQ(TCP Small Queues)协同工作,这些留到发送路径专题再展开。
观察当前 qdisc:
tc qdisc show dev eth0
# 多队列网卡上常见:
# qdisc mq 0: root
# qdisc fq_codel 0: parent :1 limit 10240p flows 1024 ...
# qdisc fq_codel 0: parent :2 ...
6.2 qdisc 与 TX ring 的边界
很多人把 qdisc 与 hardware TX ring 混为一谈。它们是两层:
qdisc 是内核的软件队列(可被 tc配置),负责调度/限速/分类。ip link里的qlen是tx_queue_len,它是pfifo_fast、pfifo这类 qdisc 取队列深度的默认值;fq_codel有自己的limit(上面输出里的10240p),并不吃tx_queue_len。TX ring 是网卡硬件的 DMA 描述符环,由驱动管理,深度用 ethtool -g eth0查看/设置。
包从 qdisc 出队后,通过 ndo_start_xmit 才进入 TX ring。两层各有"满"法:qdisc 满了按自己的策略丢(尾丢或主动队列管理);TX ring 满了则让 qdisc 暂停出队(netif_tx_stop_queue),等驱动 NAPI poll 清出空位后(netif_tx_wake_queue)继续——丢包和背压,发生在不同的层。
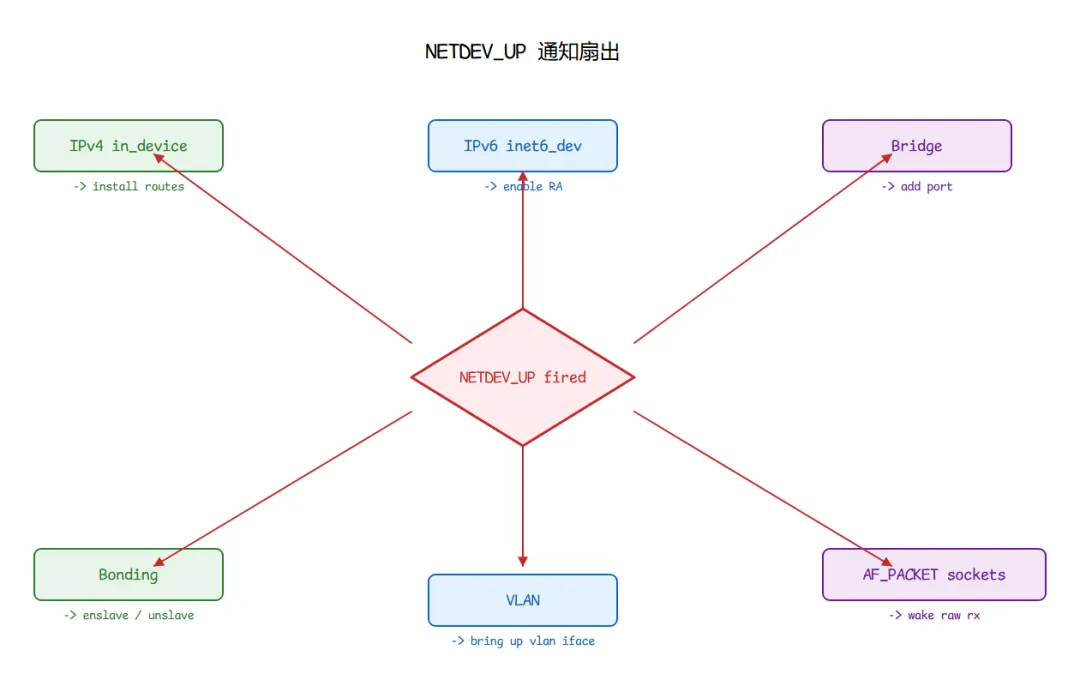
七、通知链:松耦合的"网卡广播"
网卡上下线、地址变更、MTU 变更,需要让 IPv4、IPv6、bridge、bonding、路由、NAT 全部知道。Linux 用通知链实现这种广播,避免每个子系统都把自己的逻辑 hook 进 register_netdev 函数体。
7.1 注册一个监听者
static struct notifier_block my_notifier = {
.notifier_call = my_event_handler,
};
register_netdevice_notifier(&my_notifier);
my_event_handler 会收到所有 NETDEV_* 事件:
/* include/linux/netdevice.h(6.x,节选) */
enum netdev_cmd {
NETDEV_UP = 1, /* 设备已 up */
NETDEV_DOWN,
NETDEV_REBOOT,
NETDEV_CHANGE, /* 状态变化,如 carrier on/off */
NETDEV_REGISTER,
NETDEV_UNREGISTER,
NETDEV_CHANGEMTU,
NETDEV_CHANGEADDR,
NETDEV_PRE_CHANGEADDR,
NETDEV_GOING_DOWN,
NETDEV_CHANGENAME,
/* ... */
NETDEV_PRE_UP,
/* ... */
};
版本细节:老内核里这是一组
#define十六进制宏,现代内核已改成enum netdev_cmd,取值也重排过——读老代码、老博客时别去背十六进制值,以 enum 名字为准。
一个容易忽略但很贴心的设计:register_netdevice_notifier() 注册时,内核会对系统里已存在的每个设备给你补发 NETDEV_REGISTER(已 up 的设备再补一个 NETDEV_UP)。晚加载的模块不需要自己遍历设备"追状态",通知链帮你回放历史。
7.2 现代版本的 netns 感知
老教材上的 register_netdevice_notifier() 已经不是唯一选择。现代内核(5.5+)区分:
register_netdevice_notifier():所有 netns 的事件都收,大多数内核子系统仍用它register_netdevice_notifier_net(net, nb):只接收某个 netns 的事件,容器场景下避免被全局事件轰炸register_netdevice_notifier_dev_net(dev, nb, extack):绑定到特定 netdev
实现上,全局的 netdev_chain 之外,每个 netns 还有自己的 net->netdev_chain。这种"全局 + per-netns 双层"结构,反映了容器化时代的现实需求:每个容器只关心自己 netns 里的设备变化。
7.3 一个具体例子:ip link set eth0 up 的完整时序
ip link set eth0 up
→ NETDEV_PRE_UP 通知(监听者此时还能否决 up)
→ __LINK_STATE_START 置位
→ 驱动 ndo_open():分配 ring、申请中断、napi_enable
→ IFF_UP 置位,dev_activate() 激活 qdisc
→ call_netdevice_notifiers(NETDEV_UP, dev)
→ IPv4(devinet):启用接口的 IP 配置(lo 还会自动配上 127.0.0.1)
→ IPv6(addrconf):生成 link-local 地址,开始 RS/RA 流程
→ bridge:若是桥端口,推进端口状态机
→ bonding/vlan/macvlan:级联更新上层设备状态
→ rtnetlink 多播 RTM_NEWLINK,用户态 `ip monitor link` 看到事件
整个过程不是 if-else 堆叠出来的,而是通知链按注册顺序逐个回调。这是 Linux 内核"松耦合事件广播"模式的典范。反方向同理:接口 down 时先发 NETDEV_GOING_DOWN(预告),再 ndo_stop,最后 NETDEV_DOWN——NAT 的 MASQUERADE 模块就靠监听 down 事件,清掉绑在这个接口上的连接跟踪项。
7.4 通知链的纪律
这里纠正一个流传很广的说法:"通知链回调里禁止睡眠"。对 netdev 通知链来说,这是错的。 它的回调在持有 RTNL 锁(rtnl_lock,一把全局 mutex)的上下文里执行,可以睡眠——IPv4 的回调里就有 GFP_KERNEL 分配。
真正的纪律是:可以睡,但不能久留。RTNL 是整台机器网络配置的全局锁,你在回调里多耗一秒,所有 ip / tc 命令、容器网络的创建删除都跟着卡一秒。USB 网卡热插拔注销慢、K8s 节点批量建 veth 慢,排查到最后常常是"某个 notifier 回调拖住了 RTNL"。这也是社区近年推动 RTNL 细粒度化(per-netns RTNL)的动机之一。
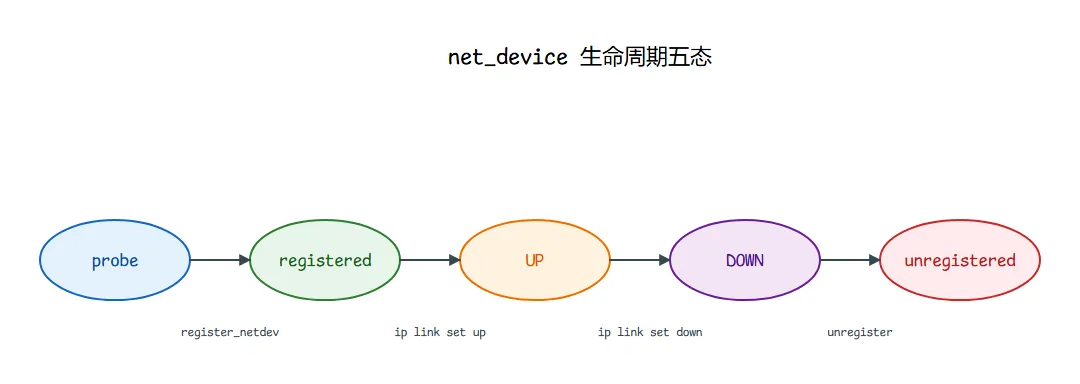
八、设备生命周期:probe → register → up → down → unregister
物理网卡:
PCI/USB enumeration
→ driver probe() # 探测到设备
→ alloc_etherdev_mq() # 分配多队列 net_device
→ register_netdev() # 注册进所在 netns 的设备表,分配 ifindex,触发 NETDEV_REGISTER
→ ip link set ... up # 用户操作
→ ndo_open()
→ NETDEV_UP 通知
... 服务期 ...
→ ip link set ... down
→ NETDEV_GOING_DOWN → ndo_stop() → NETDEV_DOWN
→ 热插拔/驱动卸载
→ unregister_netdev() # 触发 NETDEV_UNREGISTER
→ free_netdev()
虚拟设备(veth/tun/bridge)走 rtnl_link_ops(Netlink 链路操作),由用户态 ip link add 触发 newlink 操作,直接进入 register_netdev,跳过 PCI 探测部分。但 NETDEV_REGISTER / NETDEV_UP 的通知链流程完全一样——再次说明"统一抽象"。
8.1 引用计数,与那条著名的报错
老教材里 net_device 有个字段 atomic_t refcnt,所有引用增减用 dev_hold / dev_put。现代(5.13+,CONFIG_PCPU_DEV_REFCNT,SMP 下默认开启)不是这样:引用计数改成了 per-CPU 数组,另配一个 ref_tracker 用于追踪"谁拿了引用":
/* include/linux/netdevice.h 概念化裁剪 */
struct net_device {
/* ... */
int __percpu *pcpu_refcnt;
struct ref_tracker_dir refcnt_tracker;
/* ... */
};
static inline void dev_hold(struct net_device *dev)
{
this_cpu_inc(*dev->pcpu_refcnt);
}
unregister_netdev 会等所有 per-CPU 计数之和归零(netdev_wait_allrefs_any),才真正 free_netdev。这就是那条著名 dmesg 的来源——
unregister_netdevice: waiting for eth0 to become free. Usage count = 1
某个引用没有被正确释放,设备注销流程就会一直等。早年 Docker 用户在删容器时大面积撞过这条消息,根因多是内核某处 netns/路由缓存持有引用未放。为什么改 per-CPU、ref_tracker 怎么救命,留到第十节"现代演进"。
8.2 命名空间字段
struct net_device {
/* ... */
possible_net_t nd_net; /* 不是 struct net *,是 possible_net_t */
/* ... */
};
possible_net_t 是一个条件封装:CONFIG_NET_NS=y 时内含指针,否则是空 struct(零字节)。访问统一走 dev_net(dev) 宏:
struct net *net = dev_net(dev);
把网卡迁移到另一个 netns:
ip link set eth0 netns ns1
底层是 dev_change_net_namespace():先在老 netns 里走一遍 NETDEV_UNREGISTER,再到新 netns 里走 NETDEV_REGISTER——对监听者来说,"搬家"看起来就像"旧设备消失 + 新设备出现"。
九、反直觉点:lo 是个真正的 net_device,不是"假"接口
很多人以为 lo 是协议栈的"短路"——发到 127.0.0.1 直接绕过 net_device 逻辑。不是。
lo 是一个完整的 net_device,有 netdev_ops、ndo_start_xmit(loopback_xmit)、统计计数,可以挂 qdisc(虽然默认 noqueue),可以抓包(tcpdump -i lo),可以加 iptables 规则。它的 ndo_start_xmit 实现(6.6 概念化裁剪,统计等细节从略):
static netdev_tx_t loopback_xmit(struct sk_buff *skb, struct net_device *dev)
{
skb_tx_timestamp(skb);
skb_clear_tstamp(skb); /* 清掉发送侧时戳,别骗到接收路径 */
skb_orphan(skb); /* 与发送 socket 的内存配额脱钩(02 篇 truesize 记账) */
skb_dst_force(skb);
skb->protocol = eth_type_trans(skb, dev); /* 视角切回"刚收到一个帧" */
__netif_rx(skb); /* 把包喂回接收路径 */
return NETDEV_TX_OK;
}
包刚"发出去",就被 __netif_rx 喂回接收路径——这就是 lo 工作的本质。所以 ping 127.0.0.1 的延迟不是零,而是协议栈完整走两遍(一遍发送、一遍接收)的开销,几微秒到几十微秒,看 CPU。顺带一提,lo 的 MTU 默认是 65536——反正不过物理介质,把"帧"做大可以减少本机大流量的分段开销。
这是 Linux 统一抽象设计的一个完美例证:lo 不是特殊处理出来的"假"接口,它是同一个抽象的另一个实现。
十、现代演进:per-CPU 引用计数、设备查找、PHC 时间戳
经典 net_device 的几个字段,在 6.x 内核已经被翻新一遍。这些改动不是"美化",而是被容器密度、100G+ PPS、PTP 这些真实负载逼出来的。
10.1 per-CPU 引用计数:对抗 cache line bouncing
老的 atomic_t refcnt 在 1G/10G 时代没问题,到 100G 网卡跨核收发时,这个原子计数就是 cache line bouncing 的灾难现场——每秒上千万次发包都要 atomic_inc/atomic_dec 同一个字段,CPU0 刚把 cacheline 写脏,CPU1 又要 invalidate,一个 refcount 字段就能吃掉百分之几的 CPU。
5.13 起(CONFIG_PCPU_DEV_REFCNT),dev_hold 变成 this_cpu_inc——只动本 CPU 的计数,没有跨核竞争。代价是 unregister_netdev 要遍历所有 CPU 求和判零(netdev_refcnt_read),但 unregister 是冷路径,慢一点无所谓。这是内核里常见的权衡:热路径零竞争,冷路径多干活。
5.17 配套引入 ref_tracker:每次 netdev_hold 可以登记一个 tracker,记下调用栈。再遇到 waiting for eth0 to become free,不用再瞪着代码猜"谁没放引用",直接把欠账名单打出来——排查引用泄漏从"通宵"变成"十分钟"。
10.2 possible_net_t nd_net:netns 时代的产物
先把时间线摆正:Benvenuti 写书时根本没有网络命名空间——netns 是 2.6.24 才进入内核的,net_device 从那时起多了"我属于哪个 netns"的指针,早期就是裸的 struct net *。
4.1 起改成 possible_net_t,动机有两个:一是 CONFIG_NET_NS=n 的内核(嵌入式场景)不必为用不到的指针付内存;二是强制所有访问走 dev_net(dev) / read_pnet(),把"直接解引用"的错误用法挡在编译期。配合 7.2 节的 per-netns 通知链,容器密度上来之后,每个 netns 才能只听自己的事件、查自己的设备表。
10.3 设备查找:从"全局两张 hash 表"到 per-netns + altname + xarray
再纠正一个流传很广的说法:"经典内核用 for_each_netdev 线性扫描找设备,现代才换成 hash 表"。不对。 Benvenuti 书里就画了 dev_base 链表加 dev_name_head / dev_index_head 两张 hash 表——按名字、按 ifindex 查找,2.6 时代就已经是 hash 了;链表只负责"遍历所有设备"这一种场景。
真正的现代演进是三件事:
per-netns 化:hash 表从全局搬进 struct net。查找天然被 netns 隔离——这是容器宿主机上几千个 veth、br-*、CNI 接口互不拖慢的前提。altname(5.5+): ip link property add dev eth0 altname uplink-rack3,一个设备可以有多个名字,查名走netdev_name_node节点。背景是IFNAMSIZ=16字节装不下现代命名需求(交换机端口风格、PCI 路径风格的长名字)。ifindex 查找进 xarray(6.5+): net->dev_by_index从 hash 链表改为 xarray,RCU 查找路径更短更平。
对运行 Kubernetes 的宿主机,这一组演进直接决定了"CNI 频繁建删 veth"时控制面的响应速度。
10.4 PHC 硬件时间戳:纳秒精度进入主流
PTP / IEEE 1588 的需求来自高频交易、5G 前传、分布式存储——精度要求从微秒推进到纳秒。内核的回应是 PHC(PTP Hardware Clock)框架:驱动通过 ptp_clock_register() 把网卡上的硬件时钟注册成 /dev/ptp*;它和某个 netdev 的关联通过 ethtool_ops->get_ts_info 暴露——ethtool -T eth0 能直接看到 PHC index。收发包时,硬件时戳填进 skb_shared_info 的 hwtstamps(又是 02 篇那本"总账"),应用用 SO_TIMESTAMPING 取走。
经典的 SO_TIMESTAMP 只能拿内核软件时戳,中断和调度会带来微秒级抖动;PHC 时戳由 MAC/PHY 在报文出入的瞬间打上,抖动可以低到几十纳秒量级(具体看硬件)。这是经典 net_device 时代完全没有的能力。
十一、版本契约
dev->polldev->quota 直接长在 net_device 上,设备即 NAPI 实体 | netif_napi_add() 挂入 dev->napi_list | |
atomic_t refcntdev_hold/dev_put | pcpu_refcnt(5.13+)+ ref_tracker(5.17+) | |
possible_net_t nd_net | ||
pfifo_fast | fq_codel(4.12+);多队列设备根 qdisc 是 mq,虚拟设备 noqueue——记得问"哪一种默认" | |
txq->qdisc),dev->qdisc 只是给 tc 看的 root | ||
tx_clean 回调 | napi_consume_skb 释放 | |
#define | enum netdev_cmd | |
netdev_chain | ||
dev_base 链表 + 全局 name/index hash(hash 早已存在) | ||
SO_TIMESTAMP | SO_TIMESTAMPING/dev/ptp*) | |
ptype_all / ptype_base | tcpdump -i eth0 只挂设备链,不拖慢其他设备——06 篇详谈 |
读源码时核对:include/linux/netdevice.h、net/core/dev.c、net/core/link_watch.c、net/sched/sch_generic.c。
十二、可观察命令(一分钟实验)
1. 看你机器上所有 net_device 的状态、MTU、MAC:
ip -d link show
-d 会多显示设备的 kind(veth/bridge/vlan...)、numtxqueues / numrxqueues、GSO 上限、promiscuity 等详细信息——区分"这是哪种 net_device 实现"全靠它。
2. 看默认 qdisc 与 TX ring 的实际深度:
tc qdisc show dev eth0
ethtool -g eth0
sysctl net.core.default_qdisc
第一行告诉你这台设备实际用了什么调度器(以及是否被 mq 包装),第二行告诉你硬件环深度,第三行告诉你新设备会拿到什么叶子 qdisc。
3. 看一个 netdev 上有多少队列(≈ NAPI 实例数):
ls /sys/class/net/eth0/queues/
# rx-0 rx-1 ... rx-N tx-0 tx-1 ... tx-N
ethtool -l eth0
# 多队列网卡:Combined N
多数现代驱动一个 channel 配一个 NAPI 实例,所以 ethtool -l 的 Combined 数基本就是 NAPI 实例数;更精确的 per-NAPI 观测接口(netdev netlink),留到第 05 篇。
十三、思考与预告
思考题:一台没跑容器的机器上,ip link show docker0 显示 <NO-CARRIER,BROADCAST,MULTICAST,UP> state DOWN——但你仍然能 ping 172.17.0.1(docker0 自己的 IP)。operstate 都 DOWN 了,这个地址为什么还能通?提示:回头看 4.2 节的"两套状态",再想想 ping 本机地址的包到底要不要从 docker0 走出去——ip route show table local 会出卖答案。
下篇预告:第 04 篇,我们从"抽象门牌"下到"真实硬件"。一块物理网卡是怎么把比特流变成 sk_buff 的?DMA 描述符环、PCIe MSI-X 中断、硬件 RSS 哈希,这些东西怎么协作?为什么 100G 网卡的驱动比 1G 网卡多了 10 倍的代码量?我们从 Intel ice 驱动的 RX 流程开始,把"光纤到内存"这条最难的路打通。
延伸阅读
内核源码: include/linux/netdevice.h、net/core/dev.c、net/core/link_watch.c内核文档:https://docs.kernel.org/networking/netdev-FAQ.html 关键 commit(按标题在 git log 里搜索): net: add CONFIG_PCPU_DEV_REFCNT(5.13)、net: Introduce possible_net_t(4.1)、net: store netdevs in an xarray(6.5)iproute2 man page: man 8 ip-link
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 这些Linux面试题没搞懂 还想拿大厂offer?快进来背!
- 002 Linux command not found 错误最全解决方法
- 《Python 从入门到精通》083|自定义模块与包:你的代码也可以被别人导入
- 如果让你从头学Linux,你有更高效的方法吗?
- Linux 内核小技巧:将错误码编码到指针中返回
- Python基础:序列、字典和集合的区别,一张表搞懂三大核心数据结构
- 为什么学 Python 的人越来越少?从一个会计身上,我们就能找到答案
- 配置了下Codex+Python,实现办公自动化~
- 觉得Python异常处理只会try except?设计一个分层异常体系,线上报错立刻知道打谁的电话
- Linux 常用网络工具大全:如何查看指定 IP 端口的数据收发
